编译原理lab1-利用FLEX构造C-Minus-f词法分析器
Lab1 实验报告-利用FLEX构造C-Minus-f词法分析器
LAB1实验文档
⼀、实验目的
学习和掌握词法分析程序的逻辑原理与构造方法。
通过 FLEX 进行实践, 构造 C-Minus-f 词法分析器。
二、实验任务
-
学习 C-Minus-f 的词法规则
-
学习 FLEX 工具使用方法
-
使用 FLEX 生成 C-Minus-f 的词法分析器, 并进行验证
三、实验内容
详细的实验项目文档为Documentations/lab1/README.md · ConchL/cminus_compiler-2022-fall - Gitee.com
1、学习C-Ninus-f的词法规则
C-Minus 是 C 语言的⼀个子集,而 C-Minus-f 则是在 C-Minus 上追加了浮点操作。
1.关键字
else if int return void while float
2.专用符号
+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */
3.标识符ID和整数NUM,通过下列正则表达式定义
letter = a|...|z|A|...|Z
digit = 0|...|9
ID = letter+
INTEGER = digit+
FLOAT = (digit+. | digit*.digit+)
4.注释用/*...*/表示,可以超过一行。注释不能嵌套
/*...*/
注: [ , ] 和 [] 是三种不同的 token 。
[] 用于声明数组类型, [] 中间不得有空格
a [] 应被识别为两个 token: a , []
a [1] 应被识别为四个 token: a , [ , 1 , ]
2、学习FLEX工具使用方法
FLEX简介
Lex是LEXical compiler的缩写,是Unix环境下非常著名的工具,主要功能是生成一个词法分析器(scanner)的C源码,描述规则采用正则表达式(regular expression)。描述词法分析器的文件*.l,经过lex编译后,生成一个lex.yy.c 的文件,然后由C编译器编译生成一个词法分析器。
词法分析器,简单来说,其任务就是将输入的各种符号,转化成相应的标识符(token),转化后的标识符很容易被后续阶段处理。
流程如下图:

首先,FLEX从输入文件*.flex或者stdin读取词法扫描器的规范,从而生成C代码源文件lex.yy.c。然后,编译lex.yy.c并与-lfl库链接,以生成可执行的a.out。最后,a.out分析其输入流,将其转换为一系列token。
我们以一个简单的单词数量统计的程序wc.l为例:
%{
//在%{和%}中的代码会被原样照抄到生成的lex.yy.c文件的开头,您可以在这里书写声明与定义
#include 使用Flex生成lex.yy.c
[TA@TA example]$ flex wc.l
[TA@TA example]$ gcc lex.yy.c -lfl
[TA@TA example]$ ./a.out
hello world
^D
look, I find 2 words of 10 chars
[TA@TA example]$
注: 在以stdin为输入时,需要按下ctrl+D以退出
至此,你已经成功使用Flex完成了一个简单的分析器!
检验:

3.使用FLEX生成C-Minus-f的词法分析器,并进行验证
本次实验需要各位同学根据cminux-f的词法补全lexical_analyer.l文件,完成词法分析器,能够输出识别出的token,type ,line(刚出现的行数),pos_start(该行开始位置),pos_end(结束的位置,不包含)。如:
文本输入:
int a;
则识别结果应为:
int 280 1 2 5
a 285 1 6 7
; 270 1 7 8
具体的需识别token参考lexical_analyzer.h
特别说明对于部分token,我们只需要进行过滤,即只需被识别,但是不应该被输出到分析结果中。因为这些token对程序运行不起到任何作用。
注意,你所需修改的文件应仅有[lexical_analyer.l]…/…/src/lexer/lexical_analyzer.l)。关于
FLEX用法上文已经进行简短的介绍,更高阶的用法请参考百度、谷歌和官方说明。
3.1 目录结构
整个repo的结构如下
.
├── CMakeLists.txt
├── Documentations
│ └── lab1
│ └── README.md <- lab1实验文档说明
├── README.md
├── Reports
│ └── lab1
│ └── report.md <- lab1所需提交的实验报告(你需要在此提交实验报告)
├── include <- 实验所需的头文件
│ └── lexical_analyzer.h
├── src <- 源代码
│ └── lexer
│ ├── CMakeLists.txt
│ └── lexical_analyzer.l <- flex文件,lab1所需完善的文件
└── tests <- 测试文件
└── lab1
├── CMakeLists.txt
├── main.c <- lab1的main文件
├── test_lexer.py
├── testcase <- 助教提供的测试样例
└── TA_token <- 助教提供的关于测试样例的词法分析结果
3.2 编译、运行和验证
lab1的代码大部分由C和python构成,使用cmake进行编译。
-
编译
# 进入workspace $ cd cminus_compiler-2022-fall # 创建build文件夹,配置编译环境 $ mkdir build $ cd build $ cmake ../ # 开始编译 # 如果你只需要编译lab 1,请使用 make lexer $ make编译成功将在
${WORKSPACE}/build/下生成lexer命令 -
运行
$ cd cminus_compiler-2022-fall # 运行lexer命令 $ ./build/lexer usage: lexer input_file output_file # 我们可以简单运行下 lexer命令,但是由于此时未完成实验,当然输出错误结果 $ ./build/lexer ./tests/lab1/testcase/1.cminus out [START]: Read from: ./tests/lab1/testcase/1.cminus [ERR]: unable to analysize i at 1 line, from 1 to 1 ...... ...... $ head -n 5 out [ERR]: unable to analysize i at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize n at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize t at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize g at 1 line, from 1 to 1 258 1 1 1我们提供了
./tests/lab1/test_lexer.pypython脚本用于调用lexer批量完成分析任务。# test_lexer.py脚本将自动分析./tests/lab1/testcase下所有文件后缀为.cminus的文件,并将输出结果保存在./tests/lab1/token文件下下 $ python3 ./tests/lab1/test_lexer.py ··· ··· ··· #上诉指令将在./tests/lab1/token文件夹下产生对应的分析结果 $ ls ./tests/lab1/token 1.tokens 2.tokens 3.tokens 4.tokens 5.tokens 6.tokens -
验证
我们使用
diff指令进行验证。将自己的生成结果和助教提供的TA_token进行比较。$ diff ./tests/lab1/token ./tests/lab1/TA_token # 如果结果完全正确,则没有任何输出结果 # 如果有不一致,则会汇报具体哪个文件哪部分不一致请注意助教提供的
testcase并不能涵盖全部的测试情况,完成此部分仅能拿到基础分,请自行设计自己的testcase进行测试。
实验要求
本次实验需要各位同学根据cminux-f的词法补全lexical_analyer.l文件,完成词法分析器,能够输出识别出的token,type ,line(刚出现的行数),pos_start(该行开始位置),pos_end(结束的位置,不包含)。如:
文本输入:
int a;
则识别结果应为:
int 280 1 2 5
a 285 1 6 7
; 270 1 7 8
具体的需识别token参考lexical_analyzer.h
实验难点
1.gitee。之前对相关git操作的使用接触不多,根据文档编译原理实验gitee平台指南.md · ConchL/cminus_compiler-2022-fall - Gitee.com简单学了。
2.实验环境的搭建以及配置。之前虚拟机上下载的ubuntu20.04打不开了,根据https://iceyblacktea.vercel.app/blog/install-wsl2和搜索引擎学了WSL2的安装和基本用法。(查看文章需要科学上网,下载安装配置环境的时候不用)以及后续flex/g++等环境的安装,缺漏了一个都不行。
3.学习cminux-f的词法规则,并掌握用正则表达式表达它。
4.学会FLEX工具的使用。
实验设计
1、先通过示例文件tokens,并参考网上资料,找到各Token符号对应的字符
参考资料:
正则表达式手册 (oschina.net)
正则表达式在线测试 | 菜鸟工具 (runoob.com)
//运算
ADD = 259, 加号:+
SUB = 260, 减号:-
MUL = 261, 乘号:*
DIV = 262, 除法:/
LT = 263, 小于:<
LTE = 264, 小于等于:<=
GT = 265, 大于:>
GTE = 266, 大于等于:>=
EQ = 267, 相等:==
NEQ = 268, 不相等:!=
ASSIN = 269,单个等于号:=
//符号
SEMICOLON = 270, 分号:;
COMMA = 271, 逗号:,
LPARENTHESE = 272, 左括号:(
RPARENTHESE = 273, 右括号:)
LBRACKET = 274, 左中括号:[
RBRACKET = 275, 右中括号:]
LBRACE = 276, 左大括号:{
RBRACE = 277, 右大括号:}
//关键字
ELSE = 278, else
IF = 279, if
INT = 280, int
FLOAT = 281, float
RETURN = 282, return
VOID = 283, void
WHILE = 284, while
//ID和NUM
IDENTIFIER = 285, 变量名,例如a,low,high
INTEGER = 286, 整数,例如10,1
FLOATPOINT = 287, 浮点数,例如11.1
ARRAY = 288, 数组,例如[]
LETTER = 289, 单个字母,例如a,z
//others
EOL = 290, 换行符,\n或\0
COMMENT = 291, 注释
BLANK = 292, 空格
ERROR = 258 错误
2、写出对应的正则表达式
学习lex的字符规定:来自《编译原理及实践》

/******** 运算 ********/
/* ADD */
\+
/* SUB */
\-
/* MUL */
\*
/* DIV */
\/
/* LT,less */
\<
/* LTE,less and equal */
"<="
/* GT,greater */
\>
/* GTE,greater and qual */
">="
/* EQ,equal */
"=="
/* NEQ,not equal */
"!="
/* ASSIN,= */
\=
/******** 符号 ********/
/* SEMICOLON,; */
\;
/* COMMA */
\,
/* LPARENTHESE */
\(
/* RPARENTHESE */
\)
/* LBRACKET */
\[
/* RBRACKET */
\]
/* LBRACE */
\{
/* RBRACE */
\}
/******** 关键字 ********/
/* ELSE */
else
/* IF */
if
/* INT */
int
/* FLOAT */
float
/* RETURN */
return
/* VOID */
void
/* WHILE */
while
/******** ID和NUM ********/
/* IDENTIFIER */
[a-zA-Z]+
/* INTEGER */
[0-9]+
/* FLOATPOINT */
[0-9]+\.|[0-9]*\.[0-9]+
/* ARRAY */
\[\]
/* LETTER */
[a-zA-Z]
/******** others ********/
/* EOL */
[\n]
/* COMMENT */
\/\*([*]*(([^*/])+([/])*)*)*\*\/
/* BLANK */
[ \f\n\r\t\v]
/* ERROR */
.
3、写出指定模式匹配时对应的动作
动作分为两步,一步是更新lines、pos_start、pos_end等参数,另一步是将当前识别的结果进行返回,即return。
pos_start表示当前识别的词的起始位置,pos_end表示结束位置,lines表示对应的行数,return则会将token进行返回。
因此,代码编写如下:
/****请在此补全所有flex的模式与动作 start******/
//STUDENT TO DO
\+ {pos_start=pos_end;pos_end=pos_start+1;return ADD;}
\- {pos_start=pos_end;pos_end=pos_start+1;return SUB;}
\* {pos_start=pos_end;pos_end=pos_start+1;return MUL;}
\/ {pos_start=pos_end;pos_end=pos_start+1;return DIV;}
\< {pos_start=pos_end;pos_end=pos_start+1;return LT;}
"<=" {pos_start=pos_end;pos_end=pos_start+2;return LTE;}
\> {pos_start=pos_end;pos_end=pos_start+1;return GT;}
">=" {pos_start=pos_end;pos_end=pos_start+2;return GTE;}
"==" {pos_start=pos_end;pos_end=pos_start+2;return EQ;}
"!=" {pos_start=pos_end;pos_end=pos_start+2;return NEQ;}
\= {pos_start=pos_end;pos_end=pos_start+1;return ASSIN;}
\; {pos_start=pos_end;pos_end=pos_start+1;return SEMICOLON;}
\, {pos_start=pos_end;pos_end=pos_start+1;return COMMA;}
\( {pos_start=pos_end;pos_end=pos_start+1;return LPARENTHESE;}
\) {pos_start=pos_end;pos_end=pos_start+1;return RPARENTHESE;}
\[ {pos_start=pos_end;pos_end=pos_start+1;return LBRACKET;}
\] {pos_start=pos_end;pos_end=pos_start+1;return RBRACKET;}
\{ {pos_start=pos_end;pos_end=pos_start+1;return LBRACE;}
\} {pos_start=pos_end;pos_end=pos_start+1;return RBRACE;}
else {pos_start=pos_end;pos_end=pos_start+4;return ELSE;}
if {pos_start=pos_end;pos_end=pos_start+2;return IF;}
int {pos_start=pos_end;pos_end=pos_start+3;return INT;}
float {pos_start=pos_end;pos_end=pos_start+5;return FLOAT;}
return {pos_start=pos_end;pos_end=pos_start+6;return RETURN;}
void {pos_start=pos_end;pos_end=pos_start+4;return VOID;}
while {pos_start=pos_end;pos_end=pos_start+5;return WHILE;}
[a-zA-Z]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return IDENTIFIER;}
[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return INTEGER;}
[0-9]*\.[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return FLOATPOINT;}
"[]" {pos_start=pos_end;pos_end=pos_start+2;return ARRAY;}
[a-zA-Z] {pos_start=pos_end;pos_end=pos_start+1;return LETTER;}
[0-9]+\. {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return FLOATPOINT;}
\n {return EOL;}
\/\*([^\*]|(\*)*[^\*\/])*(\*)*\*\/ {return COMMENT;}
" " {return BLANK;}
\t {return BLANK;}
. {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return ERROR;}
/****请在此补全所有flex的模式与动作 end******/
4.补充C语言对应的代码
由于注释可以分为多行,故需要在识别到注释时,进行额外分析,分析其内所含的换行符\n。识别到换行符,则将lines加1,重置pos_end。
因此,代码编写如下:
case COMMENT:
//STUDENT TO DO
{
pos_start=pos_end;
pos_end=pos_start+2;
int i=2;
while(yytext[i]!='*' || yytext[i+1]!='/')
{
if(yytext[i]=='\n')
{
lines=lines+1;
pos_end=1;
}
else
pos_end=pos_end+1;
i=i+1;
}
pos_end=pos_end+2;
break;
}
case BLANK:
//STUDENT TO DO
{
pos_start=pos_end;
pos_end=pos_start+1;
break;
}
case EOL:
//STUDENT TO DO
{
lines+=1;
pos_end=1;
break;
}
实验结果验证
1、编译:

成功编译。
2、运行:
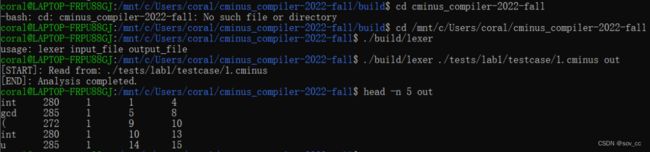
使用了./tests/lab1/test_lexer.py python脚本用于调用lexer批量完成分析任务,生成我们想要的答案。

3、基础测试:
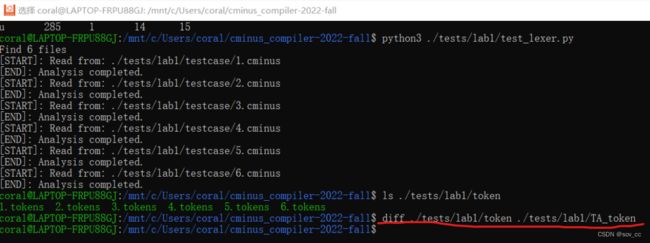
结果和助教给的正确结果对应上了。
4、自定义测试:

使用指令./build/lexer ./tests/lab1/testcase/mytest.cminus out,得到如下输出:

正确。
实验反馈
1、首先是gitee的使用。之前因为项目需要知道了github上的git操作,没接触过gitee,但是发现两者其实用法差不多,知道几个基本操作之后就可以使用了。
2、然后就到了环境配置,环境配置意外卡了好久。上学期做操作系统的ucore实验下了虚拟机上的ubuntu20.04,本来想着直接沿用就行,结果发现四个月没碰不知道为什么打不开了。原来的iso文件找不到了,重新配置比较麻烦,于是选择了助教推荐的WSL2方法,跟着博文配好了。
3、在ubuntu20.04环境时,flex和bison下好之后我以为就配好了,开始学各个符号对应的正则表达式还有c-minus-f。结果写完到最后的编译的时候总是报错(如下图)
![]()
真的卡了一个晚上+一个上午,网络上各种方法试了也不行,结果最后发现是我看漏了cmake../,也没装gcc和g++环境就直接make lexer。被自己无语到了,幸好最后看到了。
4、关于Tokens、正则表达式和Lex的语法。学习了同学推荐的《编译原理及实践》p58及往后几页。
5、在学习C-minus-f的时候,发现它和C还是有所差别的。==比如//并不算注释,只有/**/才算。==这个是后面我用自定义案例(不是现在实验报告里写的这版)测试的时候发现的。


参考链接
https://blog.csdn.net/m0_51975364/article/details/123237531
https://blog.csdn.net/qq_45890970/article/details/123740300
https://blog.csdn.net/qq_45795586/article/details/122309981
https://iceyblacktea.vercel.app/blog/install-wsl2(需要智慧上网)