决策树算法:原理与python实现案例
文章目录
- 决策树算法浅析
-
- 决策树的介绍
- 决策树最佳划分的度量问题
- 决策树python案例
决策树算法浅析
决策树的介绍
决策树的定义: 决策树是一种逼近离散值目标函数的方法,学习到的函数使用树结构进行表示,完成决策任务。这里决策树可以是分类树,也可以是回归树。
树结构的使用: 一个决策树一般由根节点、若干内部节点、若干叶子节点构成。叶子节点就是决策结果;每个内部节点对应一个属性测试,每个内部节点包含的样本集合,根据属性测试结构进一步划分,进入该内部节点的子节点;根节点包含全部的训练样本,从根节点到每个叶子节点,对应了一条决策规则。

决策过程的理解:
先以一个简单的动物分类任务为例,如何区分鸡和鸭两类动物。我们决策过程应该是思考,鸡和鸭两种动物较为明显的区分特征。例如,嘴部结构特征,根据该特征(属性)制定决策过程,如果尖嘴就是鸡,如果是扁形嘴就是鸭。
再拓展到复杂的动物分类任务,从多个动物样本数据中,区分哺乳动物和非哺乳动物。观察表格样本数据,明显发现仅使用一个特征无法正确完成分类任务。此时,我们可以同时考虑其他特征,增加决策规则。
另一个角度去理解,决策树构建的过程,类似与使用python语言编写了若干if-else分支去解决问题。
| 动物 | 饮食习性 | 胎生动物 | 水生动物 | 会飞 | 哺乳动物 |
|---|---|---|---|---|---|
| 人类 | 杂食动物 | 是 | 否 | 否 | 是 |
| 野猪 | 杂食动物 | 是 | 否 | 否 | 是 |
| 狮子 | 肉食动物 | 是 | 否 | 否 | 是 |
| 苍鹰 | 肉食动物 | 否 | 否 | 是 | 否 |
| 鳄鱼 | 肉食动物 | 否 | 是 | 否 | 否 |
| 巨蜥 | 肉食动物 | 否 | 否 | 否 | 否 |
| 蝙蝠 | 杂食动物 | 是 | 否 | 是 | 是 |
| 野牛 | 草食动物 | 是 | 否 | 否 | 是 |
| 麻雀 | 杂食动物 | 否 | 否 | 是 | 否 |
| 鲨鱼 | 肉食动物 | 否 | 是 | 否 | 否 |
| 海豚 | 肉食动物 | 是 | 是 | 否 | 是 |
| 鸭嘴兽 | 肉食动物 | 否 | 否 | 否 | 是 |
| 袋鼠 | 草食动物 | 是 | 否 | 否 | 是 |
| 蟒蛇 | 肉食动物 | 否 | 否 | 否 | 否 |
不断寻找特征,增加规则的过程,实际上就是构建决策树的过程,我们总能得到一个决策树可以较好的完成分类任务。
这里我们需要思考以下内容:
- 1.数据方面,使用的是离散化数据特征,连续数值类型需要进行离散化。
- 2.过拟合问题,可能存在数据样本需要复杂的属性测试,制定很多规则才能完成分类,导致过拟合的产生。
- 3.建模方面,尽可能构建简单的决策树,少进行属性测试。这也是决策树算法的关键问题。
决策树最佳划分的度量问题
我们总想先找到关键特征,根据关键特征进行属性测试,将无序数据变得更加有序,或者说将划分后的数据样本的“不纯度”不断降低。
如何对节点进行不纯度的度量?可以使用以下方式度量:
- 熵:无序化程度的度量,熵越大则表示越混乱。
- 误分类率:错误分类概率
- 基尼指数:表示在样本集合中一个随机选中的样本被分错的概率。
有了度量标准后,我们就可以寻找,从父节点到子节点属性测试时,熵减最大、误分类率降低最大或基尼指数减最大的特征,循环该过程使得决策树不断生长。

大家可以尝试根据上述表格中的数据进行度量计算。
决策树python案例
wine葡萄酒数据集
- 数据记录178条
- 数据特征13个’酒精’,‘苹果酸’,‘灰’,‘灰的碱性’,‘镁’,‘总酚’,‘类黄酮’,‘非黄烷类酚类’,‘花青素’,‘颜色强度’,‘色调’,‘od280/od315稀释葡萄酒’,‘脯氨酸’
- 目标类别3类:‘琴酒’,‘雪莉’,‘贝尔摩德’
决策树结构可视化
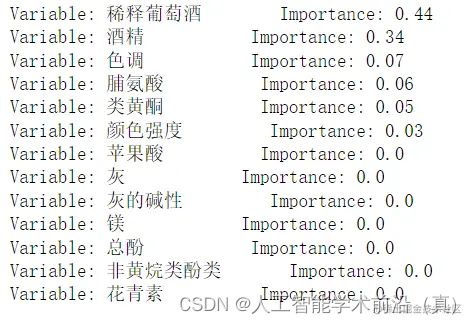
 特征贡献的排序可视化
特征贡献的排序可视化

# 导入所需要的模块
import matplotlib.pyplot as plt
import pandas as pd #读取数据
from sklearn import tree #树的模块
from sklearn.datasets import load_wine #导入红酒数据集
from sklearn.model_selection import train_test_split # 划分数据集的模块
plt.rcParams['font.sans-serif']=['SimHei']
# 探索数据
wine = load_wine()
# 数据有178个样本,13个特征
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
# 划分数据为训练集和测试集,test_size标示测试集数据占的百分比
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
# 建立模型
clf = tree.DecisionTreeClassifier(criterion="entropy")# 实例化模型,添加criterion参数
clf = clf.fit(Xtrain, Ytrain)# 使用实例化好的模型进行拟合操作
score = clf.score(Xtest, Ytest) #返回预测的准确度
#对数结构进行可视化
tree.plot_tree(clf)
# 对特征重要度数据进行可视化
importances = list(clf.feature_importances_) #辛烷值RON影响因素的重要性
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_name,importances)] #将相关变量名称与重要性对应
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True) #排序
print(*feature_importances)
feature_importances_df =pd.DataFrame(feature_importances)
print(df)
[print('Variable: {:12} Importance: {}'.format(*pair)) for pair in feature_importances] #输出特征影响程度详细数据
#绘图
f,ax = plt.subplots(figsize = (13,8)) #设置图片大小
x_values = list(range(len(importances)))
plt.bar(x_values,feature_importances_df[1], orientation = 'vertical', color = 'r',edgecolor = 'k',linewidth =0.2) #绘制柱形图
# Tick labels for x axis
plt.xticks(x_values, feature_importances_df[0], rotation='vertical',fontsize=8)
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
#特征重要性
print(clf.feature_importances_)# 查看每一个特征对分类的贡献率
print([*zip(feature_name,clf.feature_importances_)])
tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
print(score)