新一代自动出价范式:在线强化学习SORL框架
丨目录:
· 摘要
· 动机:在离线不一致问题
· 问题建模
· 方法:SORL框架
· 实验结果
· 总结
· 关于我们
· 参考文献
▐ 摘要
近年来,自动出价已成为广告主提升投放效果的重要方式,在真实广告系统(RAS)中,常见的自动出价策略是利用强化学习算法在复杂多变的竞价环境下进行实时调整。考虑到线上探索的成本和安全性,强化学习模型的训练通常是在一个模拟广告系统(VAS)中进行。由于RAS和VAS之间存在明显差距,导致强化学习在VAS中的训练存在在离线不一致问题。在本文中,我们正式地定义了在离线不一致问题,并系统地分析了其成因和影响;其次,我们提出了可持续在线强化学习(SORL)框架,该框架首次直接以与RAS交互的方式训练自动出价策略,从而较好解决了在离线不一致问题。SORL框架包含探索和训练两部分算法,具体而言,我们基于Q函数的Lipschitz光滑特性设计了探索的安全域,并提出了一个安全高效的探索算法用于在线收集数据;另外提出了V-CQL算法用于利用收集到的数据进行离线训练,V-CQL算法通过优化训练过程中Q函数的形态,减小不同随机种子下训练策略表现的方差,从而提高了训练的稳定性。大量的仿真和线上实验验证了SORL算法在效果上优于已有自动出价算法。基于该项工作整理的论文已发表在NeurIPS 2022,欢迎阅读交流。
论 文:Sustainable Online Reinforcement Learning for Auto-bidding
下 载:https://openreview.net/forum?id=zyrBT58h_J
仿真实验代码:https://github.com/nobodymx/SORL-for-Auto-bidding
1. 动机:在离线不一致问题
自动出价是根据广告主的需求(如优化目标、预算设置,成本约束等),针对每个流量进行实时出价,以最大化广告主投放效果的技术。当前业界领先的自动出价策略是由强化学习(reinforcement learning,RL)训练得到[1],出于安全等因素的考虑,业界普遍认为不能直接与实际在线广告系统(real-world advertising system,RAS)进行交互训练,常用的解决方案是基于历史竞价日志(通常是精竞日志)构建一个离线的模拟竞价环境(virtual advertising system,VAS)用于交互训练[1,2,3]。然而,由于RAS复杂多变的特点,难以构建能够精确模拟RAS的VAS,常用的VAS一般是简化版的RAS[1,2,3],其与RAS之间存在诸多不一致,主要包括:
竞价阶段不一致:RAS一般为多阶段竞价,而常用的VAS中只有单阶段竞价;
拍卖机制不一致:RAS拍卖机制复杂,而常用的VAS使用简单的GSP拍卖机制;
其余广告主影响不一致:RAS中其余广告主会适时调整出价带来市场价波动,而VAS中市场价不变。
因此,在VAS中精心训练的自动出价策略不一定在RAS中表现出色(如表1所示),更难以达到出价策略性能的“天花板”。我们称为这种问题为在离线不一致问题。
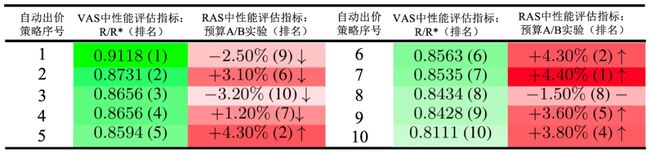 表1: 十个不同的自动出价策略在RAS和VAS中的表现对比。其中R/R*和预算A/B实验越大代表策略在相应的环境中表现越好。可以看到在VAS中表现优异(排名靠前)的出价策略在RAS中表现不一定好(排名可能靠后)
表1: 十个不同的自动出价策略在RAS和VAS中的表现对比。其中R/R*和预算A/B实验越大代表策略在相应的环境中表现越好。可以看到在VAS中表现优异(排名靠前)的出价策略在RAS中表现不一定好(排名可能靠后)
本文中,我们设计了可直接与RAS交互训练的可持续在线强化学习框架(sustainable online RL,SORL),抛弃了在VAS中训练的模式,从而较好解决了在离线不一致问题,提升了策略性能。
2. 问题建模
单个广告主视角下的自动出价问题可被看成一个具有个时间步长的周期任务。令到时刻之间的流量数为,用和分别表示第个流量的价值和市场价,其中和分别表示流量价值和市场价的上界,。我们考虑广告主的需求为预算约束,并设广告主的总预算为,则自动出价问题可以建模为Constraint MDP(CMDP)模型,其中为时刻的状态,可由剩余时间、剩余预算、预算消耗速率等元素组成,动作为时刻的出价,其中分别为出价的上界和下界,奖励函数和约束函数分别为到时刻之间竞得流量的总价值和相应的花费,表示状态转移规则,为折扣因子。用表示自动出价策略,则预算约束下的自动出价问题可以形式化为:
其中,RAS一般利用预算花完提前结束竞价的方式来满足(1)式中的限制条件。业界一般VAS中训练得到SOTA的自动出价策略[1],其中预算约束以与RAS中同样的方式被满足。然而,如前所述,这种训练模式存在在离线不一致问题。下面介绍所提出的可直接与RAS交互训练的SORL框架。
3. 方法:SORL框架
SORL框架主要由两部分算法构成,包括用于在线探索和数据收集的Safe and Efficient ExploRation (SER) 策略,以及用于离线训练自动出价策略的Variance suppressed-Conservative Q learning (V-CQL)算法。SORL框架采用迭代式工作方式,在线数据收集和离线策略训练交替进行。
3.1 在线探索:SER策略
在线探索策略需要同时满足两个基本要求,包括:
安全性:在线探索策略首先要满足安全性,即客户效果不能太差,否则会引起客诉,甚至导致系统不稳定。令表示在线探索策略,我们定义如果满足:,则是安全的,其中为一个RAS上正在运行的安全策略(在这里我们使用RL在VAS中训练得到的策略),为一个常数。其含义为的性能与的性能之间相差不超过一个阈值。
高效性:RL本质是一个Trail-and-Error的算法,需要收集到当前训练策略输出动作附近的数据(无论是on-policy还是off-policy模式),通过数据的反馈来进一步更新当前训练策略。因此,不能只保证安全,还要能够在离线训练策略出价的附近进行出价尝试,根据离线训练策略变化而变化,从而收集到能够带来新反馈的数据。我们称此要求为在线探索策略的高效性要求。
为此我们提出了SER策略,下面介绍其基本思路。
保证探索安全:基于Q函数Lipschitz特性设计安全域
基本思路: 在出价的邻域内构造可以探索的安全域,其中为邻域的范围,该想法的理论基础是我们对于自动出价问题中Q函数Lipschitz光滑特性的证明(见论文),其Lipschitz常数我们记为。具体而言,由于Q函数的含义为后续累计奖励的期望,则Q函数是-Lipschitz光滑的表明:当前出价动作偏移一点,后续累计奖励的期望的下降率不会超过。因此我们可以设计出价附近的一个小邻域为安全域。基于安全域,我们可设计在线探索策略为:在的连续时间内在安全域中采样出价动作,在剩余的时间内遵循,即:
其中0≤ < ≤ , ,且。此外,在下面定理中,我们给出了(2)中在线探索策略的性能与的性能之差的上界,证明过程见论文附录E.3。
定理(上界):(2)式中探索策略的性能与的性能之差满足:
为满足安全性要求,我们进一步设计安全域的范围为。
提高探索效率:设计高效采样方法
基本思路: 有了安全性保障,我们进一步设计(2)式中在线探索策略的采样方式来增加探索的效率,我们用来表示其采样分布。一种朴素的采样方法是按照(截断)高斯分布在安全域中采样,其中方差为超参数。为了与区别,我们用来表示,用来表示对应的在线探索策略。虽然更加安全,但是它不会随当前正在训练策略的改变而变化,不能给予充分反馈。因此,为了增加收集到数据的反馈信息,我们将向当前训练策略出价方向进行偏移,并限制与之间的距离不超过阈值,其中表示当前正在训练策略的Q函数。这可以形式化为一个泛函极值问题:
利用Euler方程,我们可以求解为:
其中为归一化系数,为拉格朗日系数(这里我们设置为超参数)。完整的推导见论文附录F.1.1。可以看出表达式物理意义明显,其中进一步保证了安全,而项保证了高效(使得在线探索策略可在当前训练策略出价附近进行探索,并根据其变化而变化)。在论文附录F.1.2中我们给出了根据采样的代码实现方式。
完整SER策略
至此,完整的SER策略为:
此外,我们可以通过调整中超参数和来控制的激进程度,具体而言,越小越大采样越激进(即极值对应出价越贴近),反之则越保守。不同超参数值下性能的变化见论文附录G.2.2。我们利用SER策略在RAS中收集状态转移数据集用于后续离线策略的训练,其中。
3.2 离线训练:V-CQL算法
利用传统RL方法基于收集的数据进行离线训练面临两个挑战,包括:
无效性:由于安全域的限制,收集的数据存在数据缺失,可能导致Q函数在缺失的出价动作(out-of-distribution,OOD)上高估[5],造成训练无效;
不稳定性:由于当前训练策略会影响,且一般不同随机种子下利用RL训练得到策略的性能方差较大(此外自动出价问题的离线策略评估(off-policy evaluation,OPE)准确度不高(见论文附录B)),因此容易由较差策略的Q函数构成从而带来客户效果上不必要的损失。
为解决上述挑战,我们提出了V-CQL算法。其中,V-CQL算法的核心在于提出了一种Q函数的损失函数,该损失函数在传统TD误差项的基础上加入正则化项和,分别用于解决上述两个挑战。
缓解无效性:Offline RL抑制OOD高估项
基本思路: Offline RL是近年来研究火热的RL技术之一[4,5,6],其目标是基于固定数据集训练高性能的策略,它解决的主要挑战是由于数据缺失造成的外推误差(extrapolation error)问题,其中对OOD动作的高估是外推误差问题的主要表现。因此,我们可以利用offline RL技术来解决无效性挑战。具体而言,我们采用offline RL技术中CQL[4]的方法,在Q函数的损失函数中加入了正则化项:
其中为常数,为均匀分布函数。上式中第一项为对所有出价动作进行惩罚,第二项为对数据集中存在的(in distribution,ID,即非OOD)出价动作进行奖励,二者整体上降低了OOD出价动作Q函数值,从而避免高估。
增强稳定性:二次型形态约束项
基本思路: 为了增加训练稳定性,减少对OPE的依赖,我们设计了正则化项。具体而言,如图1所示,我们观测到和“最优”策略(“最优”指离线实验中的最优,见论文章节5中的实验设置)对应的Q函数在不同状态下相对出价动作均具有二次型函数形态,故我们认为最优策略的Q函数也应该具有二次型函数的形态。
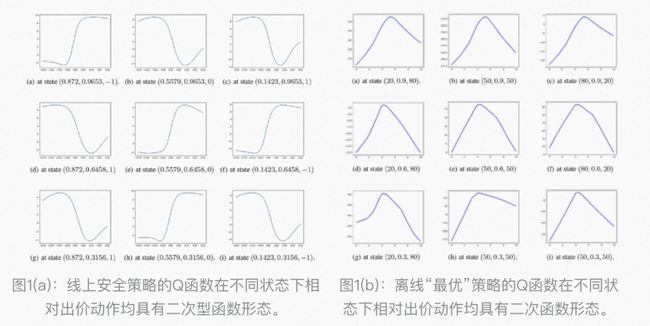
因此,我们希望通过限制训练过程中Q函数形态来减少策略性能的方差,设计的正则化项为:
其中,为常数,为具有二次型的Q函数(在这里我们使用的Q函数),为KL散度。如图2所示,加入后Q函数训练中保持了二次型的形态。
图2: 加入限制形态的正则化项后Q函数训练中保持二次函数形态完整V-CQL损失函数
至此,完整的V-CQL损失函数为:
其中,为TD误差项,表示Bellman算子,为目标Q函数。
3.3 迭代式更新结构
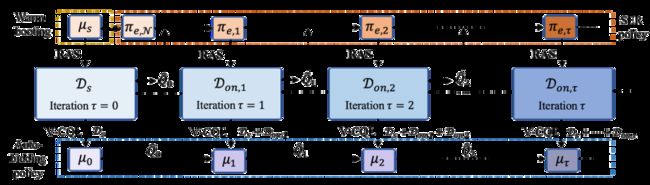 图3: SORL迭代工作框架
图3: SORL迭代工作框架
如图3所示,SORL框架采用迭代式工作方式。具体而言,首先利用安全策略在RAS上进行数据收集,构成数据集,实现“热启动”。其次利用V-CQL基于训练自动出价策略及其Q函数。此后,利用SER策略的在线探索和利用V-CQL的离线训练交替进行,我们分别用和表示在轮迭代时的SER策略和训练的自动出价策略,为的Q函数,。我们设计中的采样函数为:
,其中,为归一化参数。值得注意的是,由于都满足(2)式,只是采样函数不同,故他们都满足安全性要求。此外,在在轮离线训练时,我们将(8)式中的替换为,V-CQL算法训练的结果作为新策略的Q函数。整体SORL的算法总结如下:
4. 实验结果
我们同时利用了在线实验和仿真实验来验证我们方法的有效性。实验主要回答了以下三个问题:(1)SORL的整体效果怎么样?在迭代过程中SER策略能否一直保持安全,是否比更为高效?V-CQL训练的自动出价策略能否超过其余offline RL算法训练的策略和现有SOTA的策略?(2)SER策略在不同的Q函数下是否依旧能够保证安全?(3)V-CQL是否减少了不同随机种子下训练策略的方差?
实验设定: 我们在阿里妈妈万相台广告平台开展线上实验。仿真实验是在一个人工构建离线RAS和相应的VAS中完成的,仿真实验平台的构建见论文附录A.2。我们利用SOTA的自动出价策略USCB[1],进行热启动和安全区域的构建。设定安全阈值为。
性能评价指标: 广告主竞得流量总价值作为评估自动出价策略性能的主要指标,我们称为BuyCnt。此外,我们还利用另外三个指标作为辅助指标,包括ROI、转化成本(CPA)和广告主总消耗(ConBdg)。其中,BuyCnt、ROI和ConBdg越大,CPA越小表明自动出价策略的性能越好。
Baselines: 我们将所提算法与SOTA的自动出价策略,USCB[1],进行对比。此外,我们将V-CQL算法与现有的offline RL算法,BCQ[5]和CQL[4],进行对比。由于很多safe RL的算法不适用于自动出价问题,我们将SER策略与高斯采样的探索策略进行对比,来验证其高效性。
4.1 主要实验
为回答问题(1): 图4展示了仿真实验结果,从图4(a)可以看出,SER策略的BuyCnt下降都小于5%,验证了其安全性。此外,SER策略的BuyCnt随迭代增加而增加,且始终高于,这表明SER策略效率更高。从图4(b)可以看出,V-CQL训练的自动出价策略的BuyCnt高于BCQ、CQL和USCB,验证了V-CQL的有效性。此外,BuyCnt随迭代次数的增加而增加,在第5次迭代时收敛到最优BuyCnt,这表明了V-CQL方法的有效性以及SORL框架的优越性。
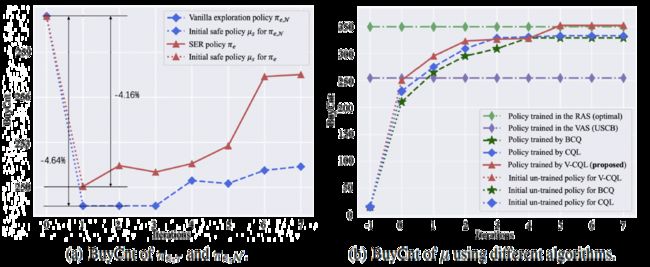 图4: 仿真实验中SORL框架实验结果
图4: 仿真实验中SORL框架实验结果
在线实验中,我们利用基于SER策略从RAS中收集数据,并进行预算A/B实验,比较4次迭代中自动出价策略的性能,结果如表2所示。我们可以看到,随着迭代的进行,自动出价策略的性能越来越好,并超过了USCB,这验证了整个SORL框架的优越性。
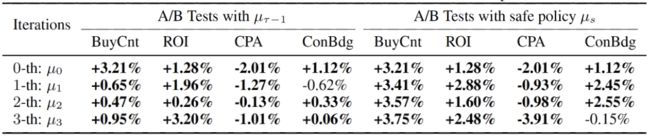 表2: 在线实验中SORL框架实验结果
表2: 在线实验中SORL框架实验结果
4.2 消融实验
为回答问题(2): 我们使用具有不同性能的自动出价策略的Q函数来充分检查SER策略的安全性。具体而言,在仿真实验中,我们利用7个不同版本的自动出价策略对应的Q函数构造7个的SER策略,其中,。我们还构造了一个高斯探索策略进行比较。所有探索策略的超参数均为。我们将和7个SER策略应用到仿真RAS中,探测策略的BuyCnt如图5所示。我们可以看到,SER策略的BuyCnt随着自动出价策略的性能水平而上升。SER策略的最差BuyCnt比下降约3.52%,满足安全性要求。
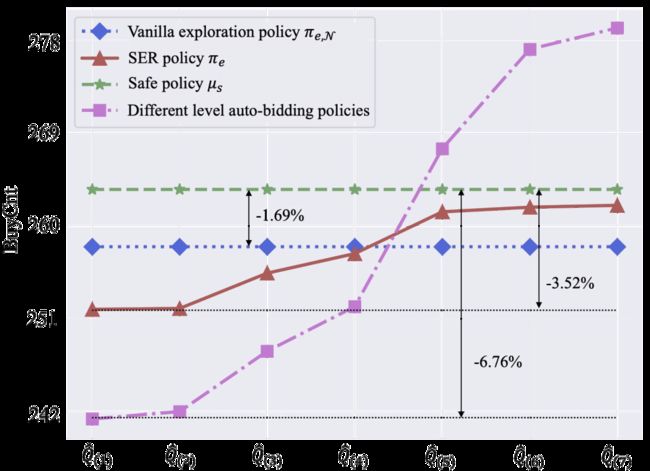 图5: 仿真实验中不同性能策略的Q函数下SER策略的安全性检验
图5: 仿真实验中不同性能策略的Q函数下SER策略的安全性检验
在线实验中,我们在RAS中对部分实验数据应用和,并在预算A/B实验中与相比,结果如表3所示。我们可以看到的ConBdg和BuyCnt的变化都在5%,并且优于,这说明SER策略的安全性。
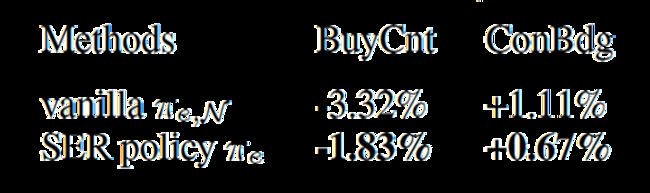 表3: 在线实验中SER策略和高斯探索策略分别与原有安全策略的预算A/B实验
表3: 在线实验中SER策略和高斯探索策略分别与原有安全策略的预算A/B实验
为回答问题(3): 仿真实验中,我们利用V-CQL、CQL、BCQ和USCB训练100个不同随机种子下的自动出价策略,结果如图6所示。可以看到V-CQL的训练策略的性能方差比其他算法小得多,同时,V-CQL训练策略的的平均性能可以保持在一个较高的水平,验证了V-CQL算法的稳定性。
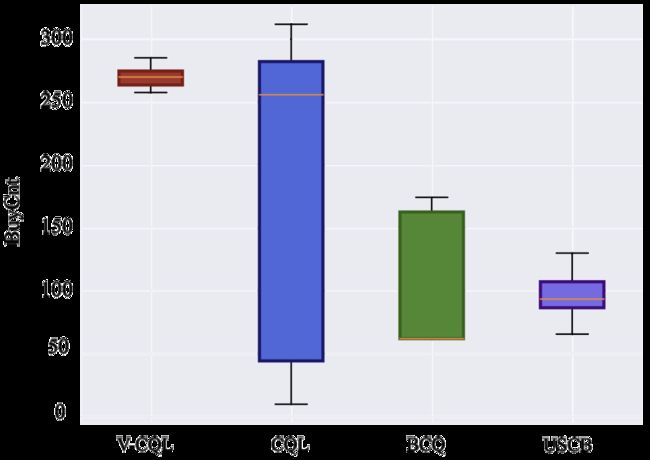 图6: 仿真实验中V-CQL函数的稳定性验证
图6: 仿真实验中V-CQL函数的稳定性验证
在线实验中,我们将V-CQL和USCB训练的自动出价策略应用于部分实验数据进行为期7天的预算A/B实验,各项指标的平均值显示在表4中。可以看到V-CQL在几乎所有指标上都优于USCB方法。此外,我们在表5中给出了不同随机种子下的预算A/B实验结果。我们可以看到V-CQL在大部分随机种子下都优于USCB,在其余随机种子下相差不多。这表明V-CQL确实有助于减少训练策略性能的方差,同时保持其平均性能维持在一个较高水平。
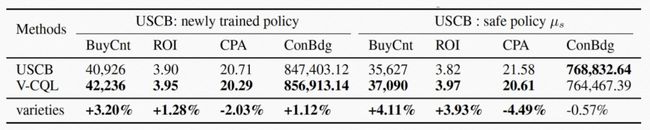 表4: 在线实验中V-CQL和USCB算法进行预算A/B实验对比
表4: 在线实验中V-CQL和USCB算法进行预算A/B实验对比
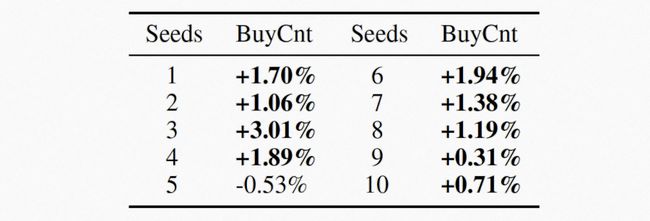
表5: 在线实验中10个随机种子下V-CQL训练自动出价策略效果(与USCB进行预算A/B实验对比)
5. 总结
本文主要从单广告主视角研究了在线广告中的自动出价问题。首先,我们提出了现有RL出价算法面临的竞价环境在离线不一致问题,并系统分析了其成因和影响。然后,为解决在离线不一致问题,我们提出了能够直接与RAS进行交互学习的SORL框架,开启了强化学习训练自动出价策略的新范式。SORL框架主要由两个算法构成,包括安全且高效的SER在线探索策略、有效稳定的V-CQL离线训练算法。整个SORL框架以迭代的方式工作,在线探索和离线训练交替进行。仿真和在线实验都验证了整个SORL框架优于现有的自动出价算法。消融研究表明,即使在性能较差的自动出价策略指导下,SER策略也能保证探索的安全性。同时消融研究也验证了V-CQL算法在不同随机种子下的稳定性。
▐ 关于我们
阿里妈妈智能广告平台算团队主要负责建设阿里妈妈万相台广告产品的算法体系和阿里妈妈机制策略平台,我们紧密围绕淘系电商商家的不同营销需求,利用最先进的算法技术帮助商家获得最极致的广告投放效果和体验,主要涉及强化学习、深度学习、运筹优化等前沿技术,团队发表过多篇NeurIPS、ICML、KDD等顶会论文。我们始终相信并且一直践行着通过技术创新来提升效率、变革商业、普惠商家。
▐ 参考文献
[1] Y. He, X. Chen, D. Wu, et al., A unified solution to constrained bidding in online display advertising, in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Aug. 2021.
[2] X. Hao, Z. Peng, Y. Ma, et al., Dynamic knapsack optimization towards efficient multi-channel sequential advertising, in Proceedings of the 37th International Conference on Machine Learning, Nov. 2020.
[3] D. Wu, X. Chen, X. Yang, et al., Budget constrained bidding by model-free reinforcement learning in display advertising, in Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Oct. 2018.
[4] A. Kumar, A. Zhou, G. Tucker, and S. Levine, Conservative q-learning for offline reinforcement learning, in Advances in Neural Information Processing Systems 33, 2020.
[5] S. Fujimoto, D. Meger, and D. Precup, Off-policy deep reinforcement learning without exploration, in Proceedings of 36th International Conference on Machine Learning, May. 2019.
[6] R. Qin, S. Gao, X. Zhang, et al. NeoRL: A near real-world benchmark for offline reinforcement learning, arXiv preprint arXiv:2102.00714, 2021.
END

也许你还想看
丨GBA:面向搜推广模型的同步和异步自由切换的训练范式
丨APG:面向CTR预估的自适应参数生成网络
丨CBRL:面向ROI约束竞价问题的课程引导贝叶斯强化学习框架
丨USCB:展示广告约束出价问题的通用解决方案

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓