网络模型—VGG16
一、发展历程
VGG网络由牛津大学在2014年ImageNet挑战赛本地和分类追踪分别获得了第一名和第二名。研究卷积网络深度对其影响在大规模图像识别设置中的准确性,主要贡献是全面评估网络的深度,使用3*3卷积滤波器来提取特征。解决了Alexnet容易忽略小部分的特征。
二、特点
通过堆叠多个3*3的卷积核来代替大尺度卷积核(减少所需参数)
可以通过堆叠两个3*3的卷积核替代5*5的卷积核,堆叠三个3*3的卷积核替代7*7的卷积核(拥有相同的感受野)
三、网络模型


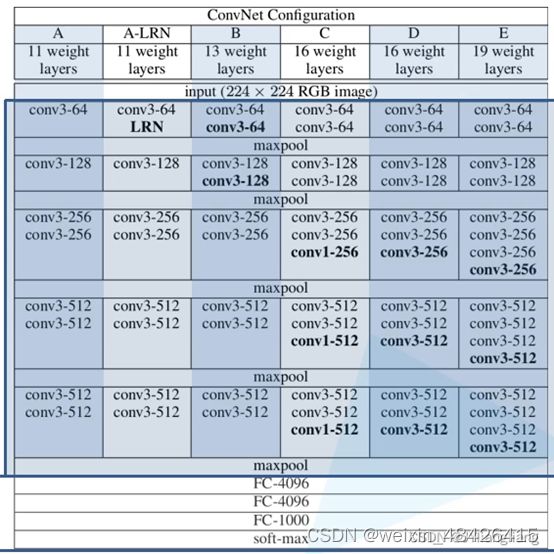
VGG16 是看D这个配置
四、步骤理解
下面算一下每一层的像素值计算:
输入:224 * 224 * 3
conv3-64(卷积核的数量)----------------------------------------kernel size:3 stride:1 padding:1
像素:(224 + 2 * 1 – 1 * (3 - 1)- 1 )/ 1 + 1=224 ---------------------输出尺寸:224 * 224 * 64
参数: (3 * 3 * 3)* 64 =1728
conv3-64-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (224 + 2 * 1 – 2 - 1)/ 1 + 1=224 ---------------------输出尺寸:224 * 224 * 64
参数: (3 * 3 * 64) * 64 =36864
pool2 ----------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (224 - 2)/ 2 = 112 ----------------------------------输出尺寸:112 * 112 * 64
参数: 0
conv3-128(卷积核的数量)--------------------------------------------kernel size:3 stride:1 padding:1
像素: (112 + 2 * 1 - 2 - 1) / 1 + 1 = 112 -------------------输出尺寸:112 * 112 * 128
参数: (3 * 3 * 64) * 128 =73728
conv3-128------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (112 + 2 * 1 -2 - 1) / 1 + 1 = 112 ---------------------输出尺寸:112 * 112 * 128
参数: (3 * 3 * 128) * 128 =147456
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (112 - 2) / 2 + 1=56 ----------------------------------输出尺寸:56 * 56 * 128
参数:0
conv3-256(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1)/ 1+1=56 -----------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3* 128)*256=294912
conv3-256-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1) / 1 + 1=56 --------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3 * 256) * 256=589824
conv3-256------------------------------------------------------------ kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1) / 1 + 1=56 -----------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3 * 256)*256=589824
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素:(56 - 2) / 2 + 1 = 28-------------------------------------输出尺寸: 28 * 28 * 256
参数:0
conv3-512(卷积核的数量)------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 256) * 512 = 1179648
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 512) * 512 = 2359296
pool2------------------------------------------------------------------ kernel size:2 stride:2 padding:0
像素:(28 - 2) / 2 + 1=14 -------------------------------------输出尺寸:14 * 14 * 512
参数: 0
conv3-512(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素:(14 - 2) / 2 + 1=7 ----------------------------------------输出尺寸:7 * 7 * 512
参数:0
FC------------------------------------------------------------------------ 4096 neurons
像素:1 * 1 * 4096
参数:7 * 7 * 512 * 4096 = 102760448
FC------------------------------------------------------------------------ 4096 neurons
像素:1 * 1 * 4096
参数:4096 * 4096 = 16777216
FC------------------------------------------------------------------------ 1000 neurons
像素:1 * 1 * 1000
参数:4096 * 1000=4096000
五、卷积计算公式
(输入大小与输出大小,可用来计算卷积的stride和padding)
Fsize:卷积核大小
P:padding大小
S:stride步长
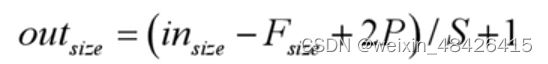
六、池化计算公式

n:输入尺寸大小
f:池化核大小
s:步长
通过一个3*3的卷积核进行卷积之后,它的输入输出的特征矩阵的高度和宽度保持不变。
七、感受野计算公式

在VGG网络中,提到三个3*3的卷积核可以替代一个7*7的卷积核。计算如下:

采用三层3*3的卷积核大小和采用7*7的卷积核大小所得到的感受野是相同的。
八、代码
VGGNet.py:
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
'''分类网络结构'''
class VGG(nn.Module):
def __init__(self, feature, class_num=1000, init_weights=False): # feature为下边的提取特征网络结构,class_num=所需要分类的类别个数, init_weights=是否需要对网络进行权重初始化
super(VGG, self).__init__()
self.feature = feature
self.classifier = nn.Sequential(
# nn.Dropout(p=0.5), # 以百分之五十比例随机失活神经元 减少过拟合
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, class_num)
)
if init_weights:
self._initialize_weights() # 初始化权重函数
def forward(self, x):
# N × 3 × 224 × 224 N:batch_size
x = self.feature(x)
# N × 512 × 7 × 7
x = torch.flatten(x, start_dim=1) # 展平处理,因为第0个维度为batch_size,所以按照第一个维度展平
# N × 512*7*7 = N × 4096
x = self.classifier(x)
return x
def _initialize_weights(self): # 初始化权重函数
for m in self.modules(): # self.modules() Returns an iterator over all modules in the network_vgg.
if isinstance(m, nn.Conv2d): # 如果 m 是 nn.Conv2d 则返回True
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) # 初始化卷积核权重
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 将偏置初始化为0
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
'''提取特征网络结构'''
def make_feature(cfg: list):
layers = [] # 用来存放我们所创建的每一层结构
in_channels = 3 # 输入通道数(因为输入图片是RGB图像)
for v in cfg:
if v == 'M': # 表示该层是最大池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # 创建一个最大池化下采样层
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers) # 非关键字参数传入
cfgs = { # 64 表示64个卷积核个数,M表示池化
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
# 实例化VGG模型
def vgg(model_name="vgg16", **kwargs): # **kwargs 允许将不定长的键值对,作为参数传递给一个函数,许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
try:
cfg = cfgs[model_name]
except:
print("warning: model number {} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_feature(cfg), **kwargs)
return model
vgg16_train.py:
import torch
import torchvision
import os
import json
import sys
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torch.utils.data.dataloader
from VGGNet import vgg
from tqdm import tqdm # python进度条
def main():
data_transform = {
"train": transforms.Compose([ # 训练
transforms.RandomResizedCrop(224), # 随机裁剪 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为指定的大小224*224
transforms.RandomHorizontalFlip(), # 随机水平翻转 以给定的概率随机水平旋转给定的PIL的图像,默认为0.5
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # mean = 期望,std=
]),
"val": transforms.Compose([ # 测试验证集
transforms.Resize((224, 224)), # cannot 224, must (224,224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
}
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(DEVICE)
data_root = os.path.abspath(os.path.join(os.getcwd(), "")) # get data root path os.path.abspath(path)返回path的绝对路径 os.getcwd() 返回当前进程的工作目录。
print(os.getcwd())
print("data_root:",data_root)
image_path = data_root + "/data_set/flower_data/" # flower data set path
print("image_path:",image_path)
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(image_path, "train"), #图片存储的根目录,即各类别文件夹所在目录的上一级目录。
transform=data_transform["train"])
print("train_dataset:",train_dataset)
train_num = len(train_dataset)
print("train_num:",train_num)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
print("flower_list:",flower_list)
# cla_dict: {0: 'daisy', 1: 'dandelion', 2: 'roses', 3: 'sunflowers', 4: 'tulips'}
cla_dict = dict((val, key) for key, val in flower_list.items()) #遍历分类索引的字典,然后将key value反过来 变成 0 daisy
print("cla_dict:",cla_dict)
# write dict into json file
json_str = json.dumps(cla_dict, indent=4) # 将python对象编码成Json字符串 indent参数根据数据格式缩进显示,读起来更加清晰, indent的值,代表缩进空格式
with open('class_indices.json', 'w') as json_file: # w 表示写入文件
json_file.write(json_str)
batch_size = 2
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
# 测试数据集
validate_dataset = torchvision.datasets.ImageFolder(root=image_path + "val", transform=data_transform["val"])
val_num = len(validate_dataset)
print("val_num:",val_num)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, class_num=5, init_weights=True) #class_num=所需分类的类别个数 init_weights 初始化权重
net.to(DEVICE)
loss_function = nn.CrossEntropyLoss()
loss_function.to(DEVICE)
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout) #tqdm是 Python 进度条库,可以在 Python长循环中添加一个进度提示信息
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(DEVICE))
# print("labels:",labels)
loss = loss_function(outputs, labels.to(DEVICE))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(DEVICE))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(DEVICE)).sum().item()
val_accurate = acc / val_num # 正确率
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
vgg16_test.py:
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from VGGNet import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "roses.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img) # 热图
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0) # torch.unsqueeze()这个函数主要是对数据维度进行扩充。给指定位置加上维数为一的维度
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file) # json.load(f)之后,返回的对象是python的字典对象
print("class_indict:",class_indict)
# create model
model = vgg(model_name="vgg16", class_num=5).to(device)
# load model weights
weights_path = "./vgg16Net.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
print("output:", output)
predict = torch.softmax(output, dim=0)
print("predict:",predict)
predict_cla = torch.argmax(predict).item()
print("predict_cla:",predict_cla)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].item())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].item()))
plt.show()
if __name__ == '__main__':
main()
视频讲解链接