CV attention | PSA:极化自注意力,助力语义分割/姿态估计涨点!
导读
注意力机制是一个被广泛应用在各种CV任务中的方法。注意力机制根据施加的维度大致可以分为两类:通道注意力和空间注意力。
- 对于通道注意力机制,代表性的工作有SENet[2]、ECANet[3];
- 对于空间注意力机制,代表性的工作有Self-Attention[4]。
- 空间和通道两个维度的双重注意力机制也被提出,代表工作有CBAM[1],DANet[5]。
基于双重注意力机制,本文针对Pixel-wise regression的任务,提出了一种更加精细的双重注意力机制——极化自注意力。作为一个即插即用的模块,在人体姿态估计和语义分割任务上,作者将它用在了以前的SOTA模型上,并达到了新的SOTA性能,霸榜COCO人体姿态估计和Cityscapes语义分割。
1. 论文和代码地址
 论文链接:https://arxiv.org/pdf/2107.00782.pdf
论文链接:https://arxiv.org/pdf/2107.00782.pdf
官网代码:https://github.com/DeLightCMU/PSA (暂未开源)
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/PolarizedSelfAttention.py
2. Motivation
细粒度的像素级任务(比如语义分割)一直都是计算机视觉中非常重要的任务。不同于分类或者检测,细粒度的像素级任务要求模型在低计算开销下,能够建模高分辨率输入/输出特征的长距离依赖关系,进而来估计高度非线性的像素语义。CNN中的注意力机制能够捕获长距离的依赖关系,但是这种方式比较复杂并且是对噪声比较敏感的。
对于这类任务,通常采用的是**encoder-decoder的结构**,encoder(e.g.,ResNet)用来降低空间维度、提高通道维度;decoder通常是转置卷积或者上采样,用来提高空间的维度、降低通道的维度。因此连接encoder和decoder的tensor通常在空间维度上比较小,虽然这对于计算和显存的使用比较友好,但是对于像实例分割这样的细粒度像素级任务,这种结构显然会造成性能上的损失。
基于此,作者提出了一个即插即用的模块——极化自注意力机制( Polarized Self-Attention(PSA)),用于解决像素级的回归任务,相比于其他注意力机制,极化自注意力机制主要有两个设计上的亮点:
- 极化滤波( Polarized filtering):在通道和空间维度保持比较高的resolution(在通道上保持C/2的维度,在空间上保持[H,W]的维度),这一步能够减少降维度造成的信息损失;
- 增强(Enhancement):采用细粒度回归输出分布的非线性函数。
3. 方法
3.1. Overview
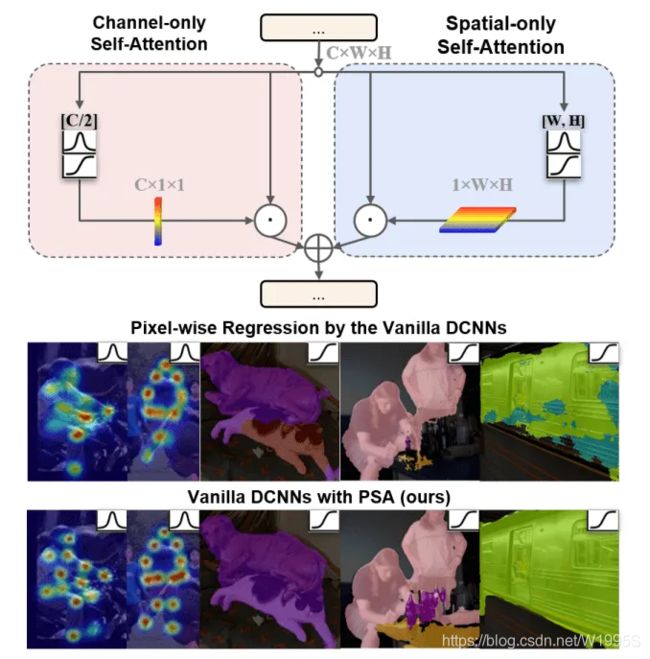
本文提出极化自注意力结构如上图所示,分为两个分支,一个分支做通道维度的自注意力机制,另一个分支做空间维度的自注意力机制,最后将这两个的分支的结果进行融合,得到极化自注意力结构的输出。
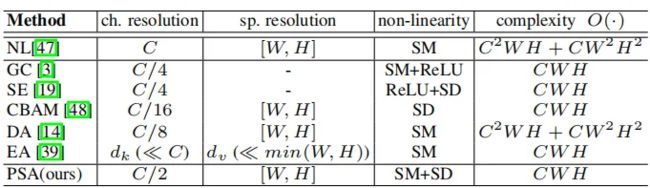
如上表所示,相比于其他注意力的方法,本文在空间维度和通道维度都没有进行很大程度的压缩(在空间维度上保持[H,W]的大小,在通道维度上使用了C/2的大小),并将复杂度也保持在了一个比较小的水平(CWH)。
个人觉得,极化自注意力机制能够在细粒度的像素级任务上保持比较好的性能,很大程度上依赖于它在空间和通道维度上都没有进行很大程度的压缩,使得信息损失比较小。
除此之外,以前的attention方法采用非线性函数进行概率估计时,通常只采用Softmax或者Sigmoid。为了能够拟合出细粒度回归结果的输出分布,极化自注意力机制在通道和空间分支都在采用了Softmax和Sigmoid相结合的函数。
3.2. Polarized Self-Attention (PSA) Block
为了解决同时对空间和通道建模时,如果不进行维度缩减,就会导致计算量、显存爆炸的问题。作者在PSA中采用了一种极化滤波(polarized filtering)的机制。类似于光学透镜过滤光一样,每个SA的作用都是用于增强或者削弱特征。(在摄影时,所有横向的光都会进行反射和折射。极化滤波的作用就是只允许正交于横向方向的光通过,以此来提高照片的对比度。 由于在滤波过程中,总强度会损失,所以滤波后的光通常动态范围较小,因此需要额外的提升,用来以恢复原始场景的详细信息。)
基于上面的思想,作者提出了Polarized Self-Attention (PSA)机制,同上面的思想一样,作者也是现在一个方向上对特征进行压缩,然后对损失的强度范围进行提升,具体可分为两个结构:
1)滤波(Filtering):使得一个维度的特征(比如通道维度)完全坍塌,同时让正交方向的维度(比如空间维度)保持高分辨率。
2)High Dynamic Range(HDR):首先在attention模块中最小的tensor上用Softmax函数来增加注意力的范围,然后再用Sigmoid函数进行动态的映射。
3.3. Channel-only branch

如上图所示,PSA分为两个分支,通道分支和空间分支,通道分支的权重计算公式如下:

可以看出,作者先用了1x1的卷积将输入的特征X转换成了Q和V,其中Q的通道被完全压缩,而V的通道维度依旧保持在一个比较高的水平(也就是C/2)。因为Q的通道维度被压缩,如上面所说的那样,就需要通过HDR进行信息的增强,因此作者用Softmax对Q的信息进行了增强。然后将Q和K进行矩阵乘法,并在后面接上1x1卷积、LN将通道上C/2的维度升为C。最后用Sigmoid函数使得所有的参数都保持在0-1之间。代码如下:
class Spatial_only_branch(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(x) #bs,c//2,h,w
spatial_wq=self.sp_wq(x) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*x
return out
(完整代码见https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/PolarizedSelfAttention.py,如有任何代码欢迎在issue中指出。)
3.5. Composition
对于两个分支的结果,作者提出了两种融合的方式:并联和串联(先进行通道上的注意力,再进行空间上的注意力):
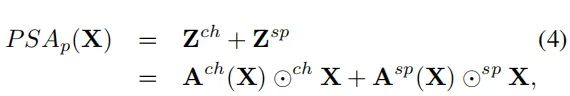
从组合方式上看,这篇文章的处理比较简单,只是对通道分支和空间分支的结果进行了串联或者并联,这一点和CBAM[1]一样。
不同的是CBAM等双重注意力的结构,大多都是用全连接层、卷积层来获取注意力权重,所以在挖掘信息的时候可能不是非常有效。而本文采用的是Self-Attention来获取注意力权重,充分了利用了Self-Attention结构的建模能力,并且作者对Q也进行了特征降维,所以在保证计算量的情况下,实现了一种非常有效的长距离建模。
4.实验
对于baseline网络,作者在3x3的卷积后面接上了PSA模块,来检验PSA带来的性能提升。
4.1. PSA vs Baselines
4.1.1. Top-Down 2D Human Pose Estimation
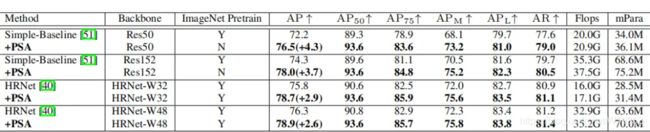
在人体姿态估计任务上,通过少量计算开销和参数数量,PSA在所有baseline网络上能够增加2.6到4.3 AP。
4.1.2. Semantic Segmentation
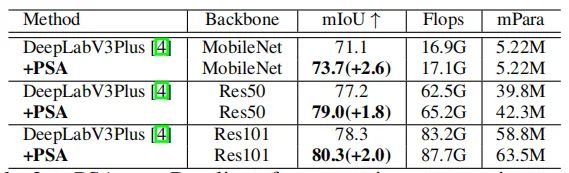
在语义分割任务上,通过少量计算开销和参数数量,PSA在所有baseline网络上能够增加1.8到2.6 mIoU。
4.2. Comparing with State-of-the Arts
4.2.1. Top-Down 2D Human Pose Estimation

在MS-COCO keypoint数据集上,PSA基于UDP-Pose结构,提升了1.7个点的性能,达到了79.5 AP的新SOTA性能。
4.2.2. Semantic Segmentation

在Cityscapes语义分割数据集上,PSA基于HRNet-OCR结构,达到了86.95 mIoU的新SOTA性能。
4.3. Ablation Study

从消融实验中,可以看出PSA相比于其他attention模块,具有非常明显的优越性。
4.4. 可视化
从可视化结果中可以看出,在关键点检测和分割任务上,PSA的结果比其他baseline结果更加精准。
5. 总结
这篇文章提出了一种极化自注意力机制,通过在空间和通道维度内部保持比较高的resolution,并采用了Softmax-Sigmoid联合的非线性函数,使得带有极化自注意力机制的模型,能够在pixel-wise的任务上获得更好的性能。
个人觉得,本质上这篇文章的结构还是和Self-Attention比较相似,但是如果直接用Self-Attention进行通道和空间维度上的建模,就会导致计算量非常大。所以作者提出了Filtering和HDR两种设计方式,使得这个结构在比较合理的计算复杂度下,也能达到比较高的准确率。
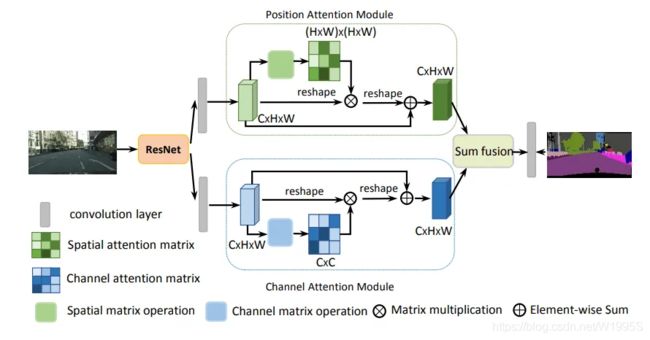
另外[5]这篇文章也是借鉴了Self-Attention的结构(网络结构如下图所示),也是在空间和通道两个维度上建模,也是用在分割任务上,有兴趣的同学也可以比较一下两篇文章的异同点。
参考文献
[1]. Woo, Sanghyun, et al. “Cbam: Convolutional block attention module.” Proceedings of the European conference on computer vision (ECCV) . 2018.
[2]. Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition . 2018.
[3]. Wang, Qilong, et al. “ECA-Net: efficient channel attention for deep convolutional neural networks, 2020 IEEE.” CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE . 2020.
[4]. Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems . 2017.
[5]. Fu, Jun, et al. “Dual attention network for scene segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2019.
本文亮点总结
1.相比于其他注意力机制,极化自注意力机制主要有两个设计上的亮点:
(1)极化滤波( Polarized filtering):在通道和空间维度保持比较高的resolution(在通道上保持C/2的维度,在空间上保持[H,W]的维度 ),这一步能够减少降维度造成的信息损失;
(2)增强(Enhancement):采用细粒度回归输出分布的非线性函数。
2.本文采用的是Self-Attention来获取注意力权重,充分了利用了Self-Attention结构的建模能力,并且作者对Q也进行了特征降维,所以在保证计算量的时候,实现了一种非常有效的长距离建模。