java编程基础总结——25.HashMap的结构及源码解析
一、HashMap结构:
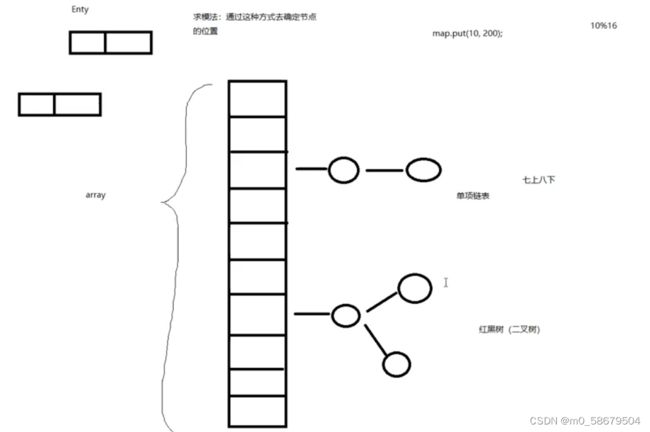
七上八下:jdk7以前是头插法,jdk7以后是尾插法
二、HashMap源码解析

1. 属性
1) static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;

1 << 4 = 1 * 2 ^ 4 = 16
不直接写16原有==原因:默认初始化容量必须是2的幂次方
2)static final int MAXIMUM_CAPACITY = 1 << 30;
最大容量2 ^ 30,整数的最大值是2 ^ 31 - 1,接近整数的最大值
3)static final float DEFAULT_LOAD_FACTOR = 0.75f;
默认加载因子,根据泊松分布,算出来0.75更合适,哈希碰撞最少
4)static final int TREEIFY_THRESHOLD = 8;
当链表长度 > 8,同时数组长度大于64时,会将链表转成红黑树
5)static final int UNTREEIFY_THRESHOLD = 6;
链表长度 < 6时,将红黑树转化成链表。链表转成红黑树的原因:二叉树,查询效率高,但是数量少的时候就不用了
6)static final int MIN_TREEIFY_CAPACITY = 64;
数组长度 > 64,链表长度 > 8时,链表转成红黑树
静态内部类:
2. 构造方法:
1)无参构造
默认容量16,加载因子默认为0.75

2)有参构造
会调用有两个参数的构造方法
传的容量小于0,抛异常,
容量大于最大值,则默认容量是最大值
加载因子如果小于等于0,并且是数字的话,抛异常
其他的容量,会以当前值最近的2的幂次方倍的值存储



3. put()方法


![]()
hash() 计算当前key的hashCode值
如果key = null ,返回0,否则做高低位异或运算
如果直接获取hashcode值,之后模(%)十六,则只有低位参加运算,高位不会参加运算
模十六最终只由最后两位决定,容易触发hash碰撞。而且例如结果都插在了第三个结点,会导致出现链表结构(不会扩容,不能转化成红黑树,就会形成单链表,效率差)
为了能让高低位都参与进来,做了高低位运算,让结果更加散列化

putVal():

HashMap的结构及源码解析总结:
1、HashMap结构
JDK7及其以前版本,HashMap:整体结构是一个"数组 + 链表" 结构
JDK8之后,HashMap:整体结构是一个"数组 + 链表 + 红黑树" 结构,
加红黑树目的:加快查询
2、什么时候链表转换为红黑树:
当链表长度大于8,同时数组长度大于64时,将从链表转换为红黑树
当链表长度小于6时,如果该链表之前是红黑树,则重新还原为链表结构
3、HashMap默认数组的容量是16,每次扩容必须保证为2的幂次方倍。
准确来说,是原有容量的2倍。
4、HashMap默认的负载因子是0.75,是因为泊松分布。
5、构造HashMap:
如果在构造时,所有参数默认,则容量是16,负载因子是0.75
如果在构造时,自己传递参数,容量必须保证为2的幂次方倍
6、put方法解析(如何添加元素)
1、首先会将key进行hash运算,如果为null,则hash值为0,否则
返回key的hashcode()的值(注意:该值会进行高低位异或运算)
目的是key的高低位二进制数据都参与到运算中来,是的key的
hash值足够散列(不要让key都插入到一个节点中)
2、添加节点:
如果数组没有初始化同时长度为0
如果是第一次添加节点,则容量是16,负载因子是0.75,触发扩容的阈值:12。
3、插入时,求插入key的下标
获取hashcode值,求模元素
(hash % length <===> (length - 1) & hash )
4、
ConcurrentHashMap:
jdk5诞生了并发的HashMap,采用的分段加锁的方式,所以效率被Hashtable 高至少16倍
如果出现高并发场景,建议使用ConcurrentHashMap;
ConcurrentHashMap在jdk8做了一次优化,加锁方式进行优化
引入了偏向锁(无锁)和自旋锁。