【动手学PaddlePaddle2.0系列】目标检测理论与YOLOv4详解
对计算机而言,能够“看到”的是图像被编码之后的数字,所以它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置,如 图1 所示。

图1:图像分类和目标检测示意图
- 图1(a)是图像分类任务,只需识别出这是一张斑马的图片。
- 图1(b)是目标检测任务,不仅要识别出这是一张斑马的图片,还要标出图中斑马的位置。
目标检测发展历程
在上一次训练营中我们学习了图像分类处理基本流程,先使用卷积神经网络提取图像特征,然后再用这些特征预测分类概率,根据训练样本标签建立起分类损失函数,开启端到端的训练,如 图2 所示。

图2:图像分类流程示意图
但对于目标检测问题,按照 图2 的流程则行不通。因为在图像分类任务中,对整张图提取特征的过程中没能体现出不同目标之间的区别,最终也就没法分别标示出每个物体所在的位置。
为了解决这个问题,结合图片分类任务取得的成功经验,我们可以将目标检测任务进行拆分。假设我们现在有某种方式可以在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域,在一张图上可以生成很多个候选区域。然后对每个候选区域,可以把它单独当成一幅图像来看待,使用图像分类模型对它进行分类,看它属于哪个类别或者背景(即不包含任何物体的类别)。
上一节我们学过如何解决图像分类任务,使用卷积神经网络对一幅图像进行分类不再是一件困难的事情。那么,现在问题的关键就是如何产生候选区域?比如我们可以使用穷举法来产生候选区域,如图3所示。

图3:候选区域
A为图像上的某个像素点,B为A右下方另外一个像素点,A、B两点可以确定一个矩形框,记作AB。
- 如图3(a)所示:A在图片左上角位置,B遍历除A之外的所有位置,生成矩形框A1B1, …, A1Bn, …
- 如图3(b)所示:A在图片中间某个位置,B遍历A右下方所有位置,生成矩形框AkB1, …, AkBn, …
当A遍历图像上所有像素点,B则遍历它右下方所有的像素点,最终生成的矩形框集合{AiBj}将会包含图像上所有可以选择的区域。
只要我们对每个候选区域的分类足够的准确,则一定能找到跟实际物体足够接近的区域来。穷举法也许能得到正确的预测结果,但其计算量也是非常巨大的,其所生成的总候选区域数目约为 W 2 H 2 4 \frac{W^2 H^2}{4} 4W2H2,假设 H = W = 100 H=W=100 H=W=100,总数将会达到 2.5 × 1 0 7 2.5 \times 10^{7} 2.5×107个,如此多的候选区域使得这种方法几乎没有什么实用性。但是通过这种方式,我们可以看出,假设分类任务完成的足够完美,从理论上来讲检测任务也是可以解决的,亟待解决的问题是如何设计出合适的方法来产生候选区域。
科学家们开始思考,是否可以应用传统图像算法先产生候选区域,然后再用卷积神经网络对这些区域进行分类?
2014 年的 RCNN 算是使用深度学习实现物体
检测的经典之作,从此拉开了深度学习做物体检测的序幕。
在 RCNN 基础上,2015 年的 Fast RCNN 实现了端到端的检测与卷积共享,Faster RCNN 提
出了 Anchor 这一划时代的思想,将物体检测推向第一个高峰。在 2016 年,YOLO v1 实现
了 Anchor-free 的一阶检测,SSD 实现了多特征图的一阶检测。在 2017 年,FPN 利用特征
金字塔实现了更优秀的特征提取网络,Mask RCNN 则在实现了实例分割的同时,也提升了
网络性能。进入 2018 年后,物体检测的算法更为多样,如使用角点做检测的 CornerNet、
使用多个感受野分支的 TridentNet、使用中心点做检测的 CenterNet 等。
如下图所示,以2014年为分水岭,目标检测在过去的二十年中可大致分为两个时期:2014年前的“基于传统图像算法的目标检测期”及之后的“基于深度学习的目标检测期”。

图4:目标检测发展里程碑
R-CNN的系列算法分成两个阶段,先在图像上产生候选区域,再对候选区域进行分类并预测目标物体位置,它们通常被叫做两阶段检测算法。SSD和YOLO算法则只使用一个网络同时产生候选区域并预测出物体的类别和位置,所以它们通常被叫做单阶段检测算法。基于深度学习的目标检测算法发展历程如下:

由于篇幅所限,本章将重点介绍YOLOv4算法,并使用PP-YOLO完成林业病虫害检测任务,主要涵盖如下内容:
- 图像检测基础概念:介绍与目标检测相关的基本概念,包括边界框、锚框和交并比等。
- 林业病虫害数据集:介绍目标检测常见数据集结构及数据预处理方法。
- YOLOv4论文详细解读:目标检测中
- PP-YOLO目标检测模型:介绍算法原理,及如何应用林业病虫害数据集进行模型训练和测试。
目标检测基础概念
在介绍目标检测算法之前,先介绍一些跟检测相关的基本概念,包括边界框、锚框和交并比等。
边界框(bounding box)
检测任务需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念。通常使用边界框(bounding box,bbox)来表示物体的位置,边界框是正好能包含物体的矩形框,如 图5 所示,图中3个人分别对应3个边界框。

图5:边界框
通常有两种格式来表示边界框的位置:
- x y x y xyxy xyxy,即 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2),其中 ( x 1 , y 1 ) (x_1, y_1) (x1,y1)是矩形框左上角的坐标, ( x 2 , y 2 ) (x_2, y_2) (x2,y2)是矩形框右下角的坐标。图4中3个红色矩形框用 x y x y xyxy xyxy格式表示如下:
- 左: ( 40.93 , 141.1 , 226.99 , 515.73 ) (40.93, 141.1, 226.99, 515.73) (40.93,141.1,226.99,515.73)。
- 中: ( 214.29 , 325.03 , 399.82 , 631.37 ) (214.29, 325.03, 399.82, 631.37) (214.29,325.03,399.82,631.37)。
- 右: ( 247.2 , 131.62 , 480.0 , 639.32 ) (247.2, 131.62, 480.0, 639.32) (247.2,131.62,480.0,639.32)。
- x y w h xywh xywh,即 ( x , y , w , h ) (x, y, w, h) (x,y,w,h),其中 ( x , y ) (x, y) (x,y)是矩形框中心点的坐标, w w w是矩形框的宽度, h h h是矩形框的高度。
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2),这样的边界框也被称为真实框(ground truth box),如 图5 所示,图中画出了3个人像所对应的真实框。模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。
注意:
- 在阅读代码时,请注意使用的是哪一种格式的表示方式。
- 图片坐标的原点在左上角, x x x轴向右为正方向, y y y轴向下为正方向。
要完成一项检测任务,我们通常希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: [ L , P , x 1 , y 1 , x 2 , y 2 ] [L, P, x_1, y_1, x_2, y_2] [L,P,x1,y1,x2,y2],其中 L L L是类别标签, P P P是物体属于该类别的概率。一张输入图片可能会产生多个预测框,接下来让我们一起学习如何完成这项任务。
锚框(Anchor box)
锚框与物体边界框不同,是由人们假想出来的一种框。先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。在下图中,以像素点[300, 500]为中心可以使用下面的程序生成3个框,如图中蓝色框所示,其中锚框A1跟人像区域非常接近。
# 画图展示如何绘制边界框和锚框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math
# 定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):
# currentAxis,坐标轴,通过plt.gca()获取
# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]
# edgecolor,边框线条颜色
# facecolor,填充颜色
# fill, 是否填充
# linestype,边框线型
# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数
rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,
edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)
currentAxis.add_patch(rect)
plt.figure(figsize=(10, 10))
filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)
# 使用xyxy格式表示物体真实框
bbox1 = [214.29, 325.03, 399.82, 631.37]
bbox2 = [40.93, 141.1, 226.99, 515.73]
bbox3 = [247.2, 131.62, 480.0, 639.32]
currentAxis=plt.gca()
draw_rectangle(currentAxis, bbox1, edgecolor='r')
draw_rectangle(currentAxis, bbox2, edgecolor='r')
draw_rectangle(currentAxis, bbox3,edgecolor='r')
# 绘制锚框
def draw_anchor_box(center, length, scales, ratios, img_height, img_width):
"""
以center为中心,产生一系列锚框
其中length指定了一个基准的长度
scales是包含多种尺寸比例的list
ratios是包含多种长宽比的list
img_height和img_width是图片的尺寸,生成的锚框范围不能超出图片尺寸之外
"""
bboxes = []
for scale in scales:
for ratio in ratios:
h = length*scale*math.sqrt(ratio)
w = length*scale/math.sqrt(ratio)
x1 = max(center[0] - w/2., 0.)
y1 = max(center[1] - h/2., 0.)
x2 = min(center[0] + w/2. - 1.0, img_width - 1.0)
y2 = min(center[1] + h/2. - 1.0, img_height - 1.0)
print(center[0], center[1], w, h)
bboxes.append([x1, y1, x2, y2])
for bbox in bboxes:
draw_rectangle(currentAxis, bbox, edgecolor = 'b')
img_height = im.shape[0]
img_width = im.shape[1]
draw_anchor_box([300., 500.], 100., [2.0], [0.5, 1.0, 2.0], img_height, img_width)
################# 以下为添加文字说明和箭头###############################
plt.text(285, 285, 'G1', color='red', fontsize=20)
plt.arrow(300, 288, 30, 40, color='red', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(190, 320, 'A1', color='blue', fontsize=20)
plt.arrow(200, 320, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(160, 370, 'A2', color='blue', fontsize=20)
plt.arrow(170, 370, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
plt.text(115, 420, 'A3', color='blue', fontsize=20)
plt.arrow(127, 420, 30, 40, color='blue', width=0.001, length_includes_head=True, \
head_width=5, head_length=10, shape='full')
#draw_anchor_box([200., 200.], 100., [2.0], [0.5, 1.0, 2.0])
plt.show()
300.0 500.0 282.84271247461896 141.4213562373095
300.0 500.0 200.0 200.0
300.0 500.0 141.42135623730948 282.842712474619
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4v7N7bX8-1618988144383)(output_4_1.png)]
在目标检测任务中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度。在训练过程中,模型通过学习不断的调整参数,最终能学会如何判别出锚框所代表的候选区域是否包含物体,如果包含物体的话,物体属于哪个类别,以及物体边界框相对于锚框位置需要调整的幅度。
不同的模型往往有着不同的生成锚框的方式,在后面的内容中,会详细介绍YOLOv3算法里面产生锚框的规则,理解了它的设计方案,也很容易类推到其它模型上。
交并比
上面我们画出了以点 ( 300 , 500 ) (300, 500) (300,500)为中心,生成的三个锚框,我们可以看到锚框A1 与真实框 G1的重合度比较好。那么如何衡量这三个锚框跟真实框之间的关系呢?在检测任务中,使用交并比(Intersection of Union,IoU)作为衡量指标。这一概念来源于数学中的集合,用来描述两个集合 A A A和 B B B之间的关系,它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数,具体计算公式如下:
I o U = A ∩ B A ∪ B IoU = \frac{A\cap B}{A \cup B} IoU=A∪BA∩B
我们将用这个概念来描述两个框之间的重合度。两个框可以看成是两个像素的集合,它们的交并比等于两个框重合部分的面积除以它们合并起来的面积。下图“交集”中青色区域是两个框的重合面积,图“并集”中蓝色区域是两个框的相并面积。用这两个面积相除即可得到它们之间的交并比,如 图6 所示。
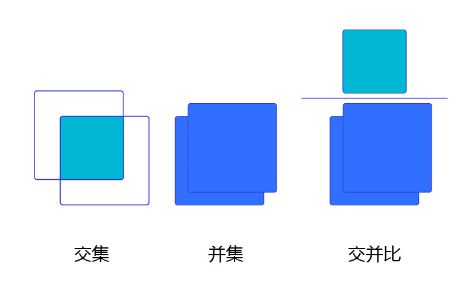
图6:交并比
假设两个矩形框A和B的位置分别为:
A : [ x a 1 , y a 1 , x a 2 , y a 2 ] A: [x_{a1}, y_{a1}, x_{a2}, y_{a2}] A:[xa1,ya1,xa2,ya2]
B : [ x b 1 , y b 1 , x b 2 , y b 2 ] B: [x_{b1}, y_{b1}, x_{b2}, y_{b2}] B:[xb1,yb1,xb2,yb2]
假如位置关系如 图7 所示:

图7:计算交并比
如果二者有相交部分,则相交部分左上角坐标为:
x 1 = m a x ( x a 1 , x b 1 ) , y 1 = m a x ( y a 1 , y b 1 ) x_1 = max(x_{a1}, x_{b1}), \ \ \ \ \ y_1 = max(y_{a1}, y_{b1}) x1=max(xa1,xb1), y1=max(ya1,yb1)
相交部分右下角坐标为:
x 2 = m i n ( x a 2 , x b 2 ) , y 2 = m i n ( y a 2 , y b 2 ) x_2 = min(x_{a2}, x_{b2}), \ \ \ \ \ y_2 = min(y_{a2}, y_{b2}) x2=min(xa2,xb2), y2=min(ya2,yb2)
计算先交部分面积:
i n t e r s e c t i o n = m a x ( x 2 − x 1 + 1.0 , 0 ) ⋅ m a x ( y 2 − y 1 + 1.0 , 0 ) intersection = max(x_2 - x_1 + 1.0, 0) \cdot max(y_2 - y_1 + 1.0, 0) intersection=max(x2−x1+1.0,0)⋅max(y2−y1+1.0,0)
矩形框A和B的面积分别是:
S A = ( x a 2 − x a 1 + 1.0 ) ⋅ ( y a 2 − y a 1 + 1.0 ) S_A = (x_{a2} - x_{a1} + 1.0) \cdot (y_{a2} - y_{a1} + 1.0) SA=(xa2−xa1+1.0)⋅(ya2−ya1+1.0)
S B = ( x b 2 − x b 1 + 1.0 ) ⋅ ( y b 2 − y b 1 + 1.0 ) S_B = (x_{b2} - x_{b1} + 1.0) \cdot (y_{b2} - y_{b1} + 1.0) SB=(xb2−xb1+1.0)⋅(yb2−yb1+1.0)
计算相并部分面积:
u n i o n = S A + S B − i n t e r s e c t i o n union = S_A + S_B - intersection union=SA+SB−intersection
计算交并比:
I o U = i n t e r s e c t i o n u n i o n IoU = \frac{intersection}{union} IoU=unionintersection
思考:
两个矩形框之间的相对位置关系,除了上面的示意图之外,还有哪些可能,上面的公式能否覆盖所有的情形?
交并比计算程序如下:
# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
bbox1 = [100., 100., 200., 200.]
bbox2 = [120., 120., 220., 220.]
iou = box_iou_xyxy(bbox1, bbox2)
print('IoU is {}'.format(iou))
IoU is 0.47402644317607107
# 计算IoU,矩形框的坐标形式为xywh
def box_iou_xywh(box1, box2):
x1min, y1min = box1[0] - box1[2]/2.0, box1[1] - box1[3]/2.0
x1max, y1max = box1[0] + box1[2]/2.0, box1[1] + box1[3]/2.0
s1 = box1[2] * box1[3]
x2min, y2min = box2[0] - box2[2]/2.0, box2[1] - box2[3]/2.0
x2max, y2max = box2[0] + box2[2]/2.0, box2[1] + box2[3]/2.0
s2 = box2[2] * box2[3]
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
inter_h = np.maximum(ymax - ymin, 0.)
inter_w = np.maximum(xmax - xmin, 0.)
intersection = inter_h * inter_w
union = s1 + s2 - intersection
iou = intersection / union
return iou
bbox1 = [100., 100., 200., 200.]
bbox2 = [120., 120., 220., 220.]
iou = box_iou_xywh(bbox1, bbox2)
print('IoU is {}'.format(iou))
IoU is 0.6902485659655831
为了直观的展示交并比的大小跟重合程度之间的关系,图8 示意了不同交并比下两个框之间的相对位置关系,从 IoU = 0.95 到 IoU = 0.

图8:不同交并比下两个框之间相对位置示意图
问题:
- 什么情况下两个矩形框的IoU等于1?
- 什么情况下两个矩形框的IoU等于0?
前置知识
YOLO系列算法模型设计思想
YOLO系列算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLO系列算法训练过程的流程图如图所示:

YOLO系列算法训练流程图
- 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的 1 32 \frac{1}{32} 321。
- 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是 32 × 32 32 \times 32 32×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
加了珍珠波霸糯米布丁芋圆的奶茶之YOLOV4详解
YOLOv4的主要贡献
-
开发了一个高效、强大的目标检测模型。它使每个人都可以使用1080 Ti或2080 TiGPU来训练一个超级快速和准确的目标探测器。
-
验证了在检测器训练过程中,最先进的Bag-of-Freebies和Bag-of-Specials 的目标检测方法的影响。
-
修改了最先进的方法,使其更有效,更适合于单GPU训练,包括CBN、PAN、SAM等。
通用目标检测器的结构如下图所示:通常可以分为Input、Backbone、Neck、Head四个部分。


- Bag of freebies
是指在离线训练阶段为了提升精度而广泛使用的调优手段,而这种技巧并不在推断中使用,不会增加推断时间。
- 数据类:
数据增强(random erase/CutOut/hide-and-seek/grid mask/MixUp/CutMix/GAN)
数据分布:two-stage的有难例挖掘,one-stage的有focal loss。
- 特征图类:
DropOut/DropConnect/DropBlock
- Bounding Box目标函数类:
MSE/ IoU loss/l1、l2 loss/GIoU loss/DIoU loss/CIoU loss
- Bag of specials
是指在推断过程中增加的些许成本但能换来较大精度提升的技巧。
- 增大感受野类:
SPP/ASPP/RFB
- 注意力类:
Squeeze-and-Excitation (SE)/Spa-tial Attention Module (SAM)
- 特征集成类:
SFAM/ASFF/BiFPN
- 激活函数类:
ReLu/LReLU/PReLU/ReLU6/Scaled ExponentialLinear Unit (SELU)/Swish/hard-Swish/Mish
- 后处理类:
soft NMS/DIoU NMS
在YOLOv4的论文中,作者进行了大量的实验,对当时提出来的目标检测提升技巧进行了大量对比。最终在YOLOv4中选取的技巧将在下面进行介绍。
Input 阶段
知识点 Data Augmentation
这里介绍8种常用的数据增广方案。包括图像变换类、图像裁剪类以及图像混叠类。经过实验验证,ResNet50模型在ImageNet数据集上, 与标准变换相比,采用数据增广,识别准确率最高可以提升1%。

- 图像变换类:图像变换类是在随机裁剪与翻转之间进行的操作,也可以认为是在原图上做的操作。主要方式包括AutoAugment和RandAugment,基于一定的策略,包括锐化、亮度变化、直方图均衡化等,对图像进行处理。这样网络在训练时就已经见过这些情况了,之后在实际预测时,即使遇到了光照变换、旋转这些很棘手的情况,网络也可以从容应对了。
- 图像裁剪类:图像裁剪类主要是在生成的在通道转换之后,在图像上设置掩码,随机遮挡,从而使得网络去学习一些非显著性的特征。否则网络一直学习很重要的显著性区域,之后在预测有遮挡的图片时,泛化能力会很差。主要方式包括:CutOut、RandErasing、HideAndSeek、GridMask。这里需要注意的是,在通道转换前后去做图像裁剪,其实是没有区别的。因为通道转换这个操作不会修改图像的像素值。
- 图像混叠类:组完batch之后,图像与图像、标签与标签之间进行混合,形成新的batch数据,然后送进网络进行训练。这也就是图像混叠类数据增广方式,主要的有Mixup与Cutmix两种方式。
Mosaic
Mosaic数据增强是在YOLOv4中提出来的,该方法参考了CutMix数据增强方式,CutMix数据增强方式利用两张图片进行拼接,而Mosaic数据增强利用了四张图片进行拼接。YOLOv4论文中提到Mosaic使得网络可以检测正常环境外部的物体,并且在BN计算的时候一下子会计算四张图片的数据,极大地减少了对于论文中提到的large mini-batch size的需求。

Mosaic数据增强的过程共分为三步:
- 取出四张图片并进行之前提到的普通数据增强,比如改变宽高比、放大/ 缩小、反转、改变HSV等操作;
- 将四张图片分别按照四个方向位置摆好;
- 将四张图片组合到一张图片中,并筛除掉一些没用的框;
Class label smoothing
类标签平滑(LSR)
在分类问题中,一般最后一层是全连接层,然后对应one-hot编码,这种编码方式和通过降低交叉熵损失来调整参数的方式结合起来,会有一些问题。这种方式鼓励模型对不同类别的输出分数差异非常大,或者说模型过分相信他的判断,但是由于人工标注信息可能会出现一些错误。模型对标签的过分相信会导致过拟合。
标签平滑可以有效解决该问题,它的具体思想是降低我们对于标签的信任,例如我们可以将损失的目标值从1稍微降到0.9,或者将从0稍微升到0.1。总的来说,标签平滑是一种通过在标签y中加入噪声,实现对模型约束,降低模型过拟合程度的一种正则化方法。
论文地址 飞桨2.0API地址
y k ~ = ( 1 − ϵ ) ∗ y k + ϵ ∗ μ k \tilde{y_k} = (1 - \epsilon) * y_k + \epsilon * \mu_k yk~=(1−ϵ)∗yk+ϵ∗μk
其中 1−ϵ 和 ϵ 分别是权重, y k ~ \tilde{y_k} yk~是平滑后的标签,通常 μ 使用均匀分布。
BackBone(骨干网络)
骨干网络是Object Detection, Scene Parsing, OCR等任务的前导性任务。通过backbone网络提取到图像的特征。下图为二者之间的对比图。


Cross Stage Partial(CSP)
核心思想就是将输入切分。其目的在于提出一种新的特征融合方式(降低计算量的同时保证精度)。

Backbone: CSPDarknet53
在Darknet53中应用CSP结构

CSPNet提出主要解决了以下三个问题:
-
增强CNN的学习能力,能够在轻量化的同时保持准确性。
-
降低计算瓶颈。
-
降低内存成本。
DropBlock
dropout被广泛地用作全连接层的正则化技术,但是对于卷积层,通常不太有效。dropout在卷积层不work的原因可能是由于卷积层的特征图中相邻位置元素在空间上共享语义信息,所以尽管某个单元被dropout掉,但与其相邻的元素依然可以保有该位置的语义信息,信息仍然可以在卷积网络中流通。因此,针对卷积网络,我们需要一种结构形式的dropout来正则化,即按块来丢弃。在本文中,我们引入DropBlock,这是一种结构化的dropout形式,它将feature map相邻区域中的单元放在一起drop掉。
dropout的主要缺点是它随机drop特征。虽然这对于全连接层是有效的,但是对于卷积层则是无效的,因为卷积层的特征在空间上是相关的。当这些特性相互关联时,即使有dropout,有关输入的信息仍然可以发送到下一层,这会导致网络overfit。

Mish Activation

无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
最后,可能也是最重要的,目前的想法是,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
这种通过Mish激活曲线平滑性来推送信息的能力如下图所示,在一个简单测试中,越来越多的层被添加到一个测试神经网络中,而没有一个统一的函数。随着层深的增加,ReLU精度迅速下降,其次是Swish。相比之下,Mish能更好地保持准确性,这可能是因为它能更好地传播信息:

Multi-input weighted residual connection
多输入加权残差连接这个方法来自于EfficientDet,也就是EfficientDet中说的带权重特征融合(Weighted Feature Fusion)。在 EfficientDet 论文中,观察到不同的输入特征在不同的分辨率下对输出特征的贡献是不相等的。之前从FPN 开始普遍采用的,一个特征先 Resize ,再和另一层的特征相加的方式不合理。因为这样假设这两层的特征有了相同的权重。从更复杂的建模角度出发,应该每一个 feature 在相加的时候都要乘一个自己的权重。

Neck
SPP(Spatial Pyramid Pooling)
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪(crop)和拉伸(warp)。如下图所示。但是这种方法对于图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。

而Kaiming He在这里提出了一个SPP(Spatial Pyramid Pooling)层能很好的解决这样的问题, 但SPP通常连接在最后一层卷基层。
- SPP的特点
- 不管输入尺寸是怎样,SPP 可以产生固定大小的输出
- 使用多个窗口(pooling window)
- SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
- 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
- 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
- SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
- 不仅可以用于图像分类而且可以用来目标检测

PAN
如图所示,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
自底向上增强。
如上图中所示,FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而本文就是针对这一点,在FPN的后面添加一个自底向上的金字塔,可以说是很皮了。这样的操作是对FPN的补充,将低层的强定位特征传递上去,个人称之为”双塔战术“。

知识点 concat和add的不同
concatenate操作是网络结构设计中很重要的一种操作,经常用于将特征联合,多个卷积特征提取框架提取的特征融合或者是将输出层的信息进行融合,而add层更像是信息之间的叠加。大家可以这样理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
因此add相当于加了一种prior,当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。因此add相当于加了一种先验,当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。

Spatial Attention Module (SAM)
注意力机制在 DL 设计中被广泛采用。在SAM中,最大值池化和平均池化分别用于输入feature map,创建两组feature map。结果被输入到一个卷积层,接着是一个 Sigmoid 函数来创建空间注意力。将SAM从空间注意力机制修改为点上的注意力机制,并将PAN的相加模块改为级联。


- 知识点:注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
下图形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。

CmBN
原始批次归一化收集一个小批次内样本的均值和方差,以白化输入层。然而,如果小批量尺寸是小的,这些估计将是有噪声的。一个解决方案是在许多小批量中估算它们。然而,随着权重在每次迭代中变化,在这些权重下收集的统计信息在新的权重下可能会变得不准确。一个天真的平均数将是错误的。幸运的是,重量是逐渐变化的。在交叉迭代批处理归一化(CBM)中,它通过下面的调整从前k次迭代中估计这些统计信息。CmBN是一个修改后的选项,它只收集单个批内的小批之间的统计信息。


CIoU
损失函数给出了如何调整权重以降低成本的信号。所以在我们做出错误预测的情况下,我们期望它能给我们指明前进的方向。但如果使用IoU,并且ground truth box和预测没有重叠,就不会发生这种情况。考虑两个预测都不与地面真相重叠,IoU损失函数不能告诉哪一个是更好的,甚至一个可能比另一个更接近GT。

Generalized IoU (GIoU) 通过将损失细化为:

但是这个损失函数倾向于首先扩展预测的边界框,直到它与 ground truth重叠。然后它收缩增加IoU。这个过程需要比理论上更多的迭代。
首先,引入 Distance-IoU Loss (DIoU) 如下:

它引入了一个新的目标来减少两个框之间的中心点分离。
最后,引入Complete IoU Loss (CIoU) :
增加ground truth框与预测框的重叠区域,
使它们的中心点距离最小
保持框的高宽比的一致性。
这是最后的定义:

DIoU-NMS
NMS过滤掉预测相同对象的其他边界框,并保留具有最高可信度的边界框。DIoU(前面讨论过的) 被用作非最大值抑制(NMS)的一个因素。该方法在抑制冗余框的同时,采用IoU和两个边界盒中心点之间的距离。这使得它在有遮挡的情况下更加健壮。

- 知识点:NMS
通过非极大值抑制(non-maximum suppression, nms)来消除冗余框。基本思想是,如果有多个预测框都对应同一个物体,则只选出得分最高的那个预测框,剩下的预测框被丢弃掉。

Head
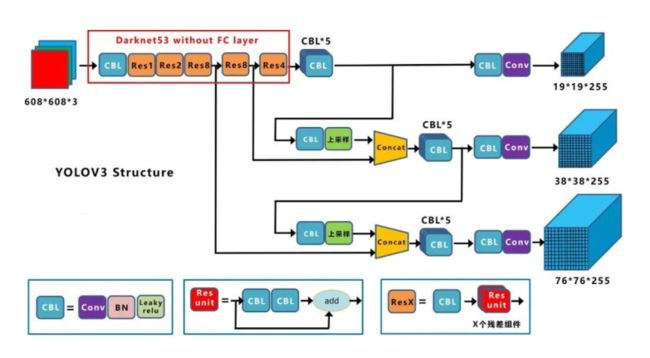
YOLOv3 Head
YOLOv4的一些细节
- Eliminate grid sensitivity

- Self-Adversarial Training
SAT为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
- Using multiple anchors for a single ground truth
如果IoU(ground truth, anchor) > IoU阈值,为一个ground truth使用多个anchor。
- Cosine annealing scheduler
余弦退火
- Optimal hyper parameters
Genetic algorithms, 遗传算法。该算法遵循的是适者生存的概念。例如,我们随机选择100组超参数。然后,我们用它们来训练100个模型。之后,我们选择了前10个执行模型。对于每个选择的模型,我们根据其原始创建10个微小差异的超参数。我们用新的超参数重新训练模型,并再次选择最佳模型。当我们保持迭代时,我们应该找到最佳的超参数集。或者,我们可以从默认的超参数开始,然后开始突变。
- Random training shapes
许多单阶段目标检测器是在固定的输入图像形状下训练的。为了提高泛化效果,我们可以对不同图像大小的模型进行训练。(在YOLO中进行多尺度训练)