PYTHON3 基于SVM的经典鸢尾花数据集分类 2021-6
PYTHON3 基于SVM的经典鸢尾花数据集分类
#处理其中2个target,并用plt可视化
#python3 基于SVM的经典鸢尾花数据集分类,取其二两个target方便plt画图
#修改时间:2021.6.20
import numpy as np
from matplotlib import pyplot as plt
from sklearn.svm import SVC# 从sklearn中导入svm中的SVC
from sklearn.datasets import load_iris# 导入sklearn的数据案例中的鸢尾花数据集
from sklearn.model_selection import train_test_split
# 读取数据,不需要写路径
data = load_iris()
#data和target是数据集写的
X = data['data']
y = data['target']
# 数据提取(target有0,1,2;!=A,就是舍去target=A的数据)
A=2;#A可以是0,1,2
X = X[y!= A,0:2]
y = y[y!= A]
#Z-score标准化方法:(x-平均数)/标准差
#手动实现Z-score标准化
X -= np.mean(X,axis=0)
X /= np.std(X,axis=0,ddof=1)
m = len(X)
# 数据切割
n=0.3#测试集占比为n,训练集占比(1-n)
print('数据切割 训练集:测试集=',(1-n),':',n)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=n, random_state=0)#由于数据是有序得,所以要随机选取
# 创建SVM模型
model_svm = SVC(C=1,kernel='rbf')
# 调用fit函数训练模型
model_svm.fit(X_train,y_train)
# 查看准确率
ss = model_svm.score(X_test,y_test)
print('测试集的准确率是:',ss)
# 调用训练好的模型获得预测的值
X_train_h = model_svm.predict(X_train)
X_test_h = model_svm.predict(X_test)
# 开始画图部分
# 确定画图的范围
x1_min,x1_max,x2_min,x2_max = np.min(X[:,0]),np.max(X[:,0]),np.min(X[:,1]),np.max(X[:,1])
# 将画布切割成200*200
x1,x2 = np.mgrid[x1_min:x1_max:200j,x2_min:x2_max:200j]
# 计算点到超平面的距离
# 首先对数据进行拼接
x1x2 = np.c_[x1.ravel(),x2.ravel()]
z = model_svm.decision_function(x1x2)
z = z.reshape(x1.shape)
# 画出所有的样本点
plt.scatter(X[:,0],X[:,1],c=y,zorder=10)
# 画出测试集的样本点
plt.scatter(X_train[:,0],X_train[:,1],s=100,facecolor='none',zorder=10,edgecolors='k')
# 画等值面
# plt.cm中cm全称表示colormap,
# paired表示两个两个相近色彩输出,比如浅蓝、深蓝;浅红、深红;浅绿,深绿这种。
plt.contourf(x1,x2,z>=0,cmap=plt.cm.Paired)
# 画等值线
plt.contour(x1,x2,z,levels=[-1,0,1])
plt.title('svm,not target %d'%A)
plt.show()
A=0时
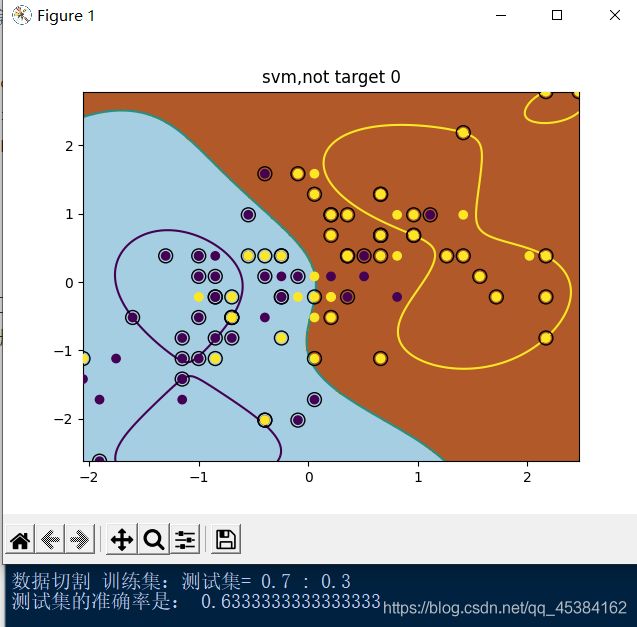
A=1
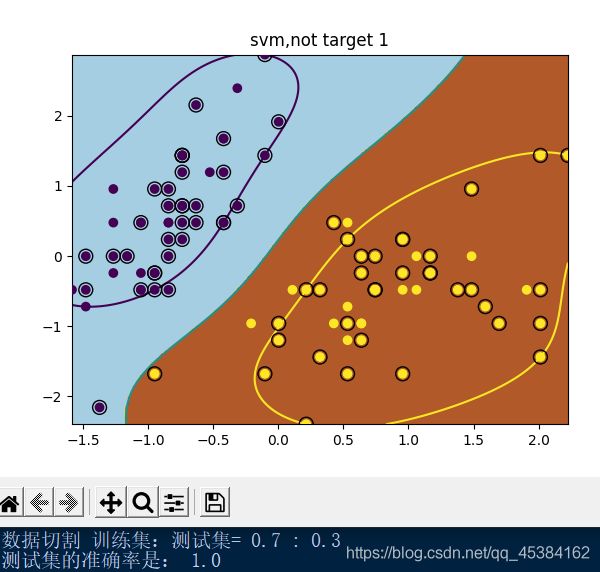
A=2

#处理3个target
在这里插入代码片
借鉴了其他博主的代码,也结合自己的需求进行了必要的修改。如有雷同,私信即删。