python sklearn 梯度下降法_凸优化|笔记整理(4)——次梯度案例,加速梯度法,随机梯度下降法,近端梯度法引入...
上一节笔记:
学弱猹:凸优化|笔记整理(3)——梯度与次梯度:方法,性质与比较zhuanlan.zhihu.com
————————————————————————————————————————
大家好!
这一节我们开始把我们之前与梯度法和次梯度法有关的,但是还没有说完的部分说完。还有篇幅的话,就再谈一谈随机梯度下降方法。
那么我们开始吧。
目录
- 梯度方法,次梯度方法的加速
- 动量方法
- 波利亚重球法
- 加速梯度方法
- Nesterov加速梯度法
- 动量方法
- 次梯度方法的案例分析
- 随机梯度下降法
- 大规模问题下的随机梯度下降方法使用技巧
- 近端梯度方法引入
Source
- Hung-yi Lee, Machine Learning (videos on Bilibili)
- CMU 10-725, Convex Optimization
- Amir Beck (2017), FIrst-order Methods in Optimization
- Michael W. Mahoney, et al. The Mathematics of Data
- Boyd, Vandenberghe, Convex Optimization
- L. Vandenberghe, Lecture notes for EE 236C, UCLA, Spring 2011-2012
- D. Bersekas (2010), Incremental gradient, subgradient, and proximal methods for convex optimization: a survey
- A. Nemirovski and A. Juditsky and G. Lan and A. Shapiro (2009), Robust stochastic optimization approach to stochastic programming
- Ryan Tibshirani (2015), A general framework for fast stagewise algorithms
- B. Polyak (1987), Introduction to optimization Chapter 5
- Dekel et al. (2012), Optimal distributed online prediction using mini-batches
梯度方法,次梯度方法的加速
看到这个主题,你可能第一眼会觉得,我们是要谈一谈方法的加速。但是实际上我们要先泼一盆冷水:我们不会提次梯度方法的加速。明明不会提,为什么要起这个标题?我们后面讲到这里大家就明白了。
我们先提一些梯度方法的延伸,也就是它们的一些可能的加速策略。
动量方法
我们要提到的梯度的加速方法都不可避免的和动量(momentum)这个概念相关,我们后面会解释这个概念。
波利亚重球法
对,就是那个上一节提到的波利亚(Polyak)。
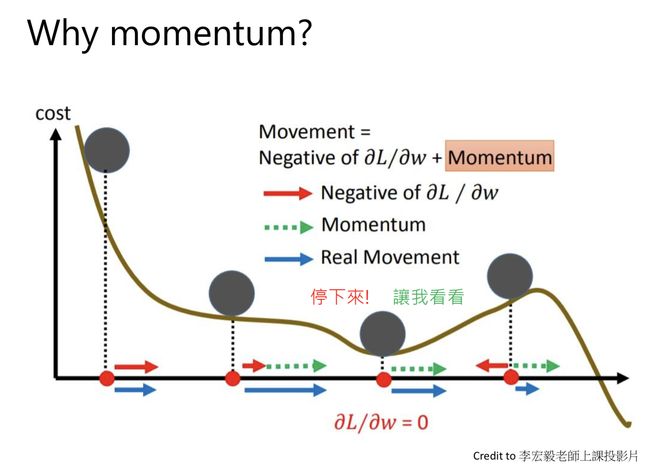
波利亚重球法(Polyak Heavy-Ball Method)严格来说不是一个加速方法,但可以帮助我们很好的理解动量这样的概念。回顾一下梯度方法的迭代公式
那么对于重球法来说其实就是这么一个迭代公式
你会发现,这个公式就多了一项,这一项是
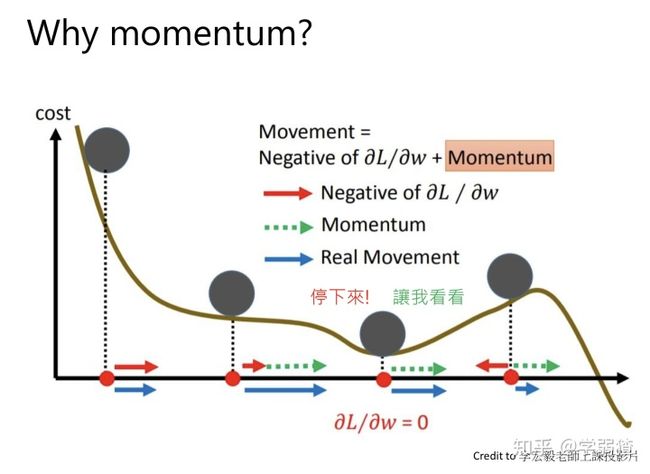
可以看出,如果只有梯度的话,球到达一个局部极小值点,就会停下来。但是对于这张图而言,其实球可以往下再走一点,“越过”这个山坡,然后到达更小的值。那么动量的作用就相当于认为球”不应该停留在那个局部极小值“,所以就完成了这个任务。
所以说重球法其实目的是希望函数迭代到更小的值,和加速没什么关系。但是我们到后面提到的方法,其实都和这个动量的概念有关。
加速梯度方法
好的,现在我们进入正题了。我们先说一句:共轭梯度法(Conjugate Gradient)本身也算是一种加速优化方法。列出它的原因在于共轭梯度法也只使用了一阶信息,但是因为没有直接使用梯度,所以它不属于加速梯度方法。这里我们贴出《数值优化》第3和4节的链接,大家可以点进去了解共轭梯度法。
学弱猹:数值优化|笔记整理(3)——线搜索中的步长选取方法,线性共轭梯度法zhuanlan.zhihu.com
Nesterov加速梯度法
加速梯度法最有名的就是Nesterov加速梯度法,但必须要承认它的原理是非常难以理解的,这也是我们不会在这里详细证明它的性质的原因(没啥必要……)。
对于Nesterov加速方法,它的迭代公式为
还有一种拆分而连贯的写法是
然后设初值
这一个公式的关键变化就在于梯度内添加了一个动量项
Theorem 1:
设凸,
Lipschitz连续,且Lipschitz常数为
,那么如果设
,那么有
,其中
是迭代步数,
为最小值。
通过这个上界就可以得到收敛速率的结论。
一个自然的问题就是:如果有强凸,加速梯度法有没有作用?事实上也是一样,可以从次线性收敛速度推到线性收敛速度。当然具体的原因就不解释了,我也解释不明白这玩意。
为什么说这一个方法之后就不再继续说了呢?一方面当然是因为其他方法没有特别有名,另一方面,也是因为这是一阶方法能够达到的极限。换句话说,如果完全不考虑问题的特性,希望一个万金油的方法,那么最好的收敛速度也就是
Proposition 1:
对任意,任意出发点
,都存在一个函数
,使得任何一阶方法都有
,这里
表示数据的维数
不过这个定理严格来说不是很严谨,有的人可能会问
当然了这里为了严谨,多说一句,一阶方法的严格定义就是每一步迭代,值都落在
这个线性空间内。
最后我们再简单多说几句与次梯度方法相关的加速情况。我们上一节说对于次梯度方法,它的收敛速度一般是
Proposition 2:
对任意和出发点
,存在一个
,使得任何一个非光滑(梯度不存在)的一阶方法,都有
![]()
如果你忘记了
好的,关于两种不同的方法的延伸和一些与加速有关的核心性质,我们这里就介绍完了。
次梯度方法的案例分析
这一部分事实上就是上一节跳过的,与次梯度有关的一些部分。因为和梯度不太一样的事,次梯度在分析上其实难度是大很多的,实际的应用场景也广泛很多,所以值得多提一些相关的案例。
首先我们来看一下机器学习里面非常有名的LASSO。
Example 1: LASSO(Source:CMU)
考虑问题,观察优化问题
,
的最优性条件。
注意到
对光滑项计算次微分没什么好说的,因为就是简单的向量求导,《数值优化》第1节(https://zhuanlan.zhihu.com/p/118443321)有说。所以我们可以算出
向量一范数的次梯度不难求,我们留给读者,这里直接给出结论为
其中
,
![]()
再结合一下做一个化简归类,就能得到
这个东西的好处就是可以看出,对于LASSO来说,什么时候
第二个例子其实还是LASSO,我们提它,只是因为之后的一些问题中可能会用到这个工具。
Example 2:Soft-thresholding(Source:CMU)
考虑问题的最优性条件。
这个就是
其中
,
![]()
你懂了Example 1,相信就能自己算出Example 2为什么是这个结果。这里要多说一句,
接下来再说一个非常有意思的优化问题。
Example 3: Intersection of sets(Source:CMU)
考虑问题,
,考虑优化问题
![]()
这个问题其实就是一个寻找某一个属于一系列集合的交的元素的问题。我们可以看出,如果找到了一个点
我们注意到
其中
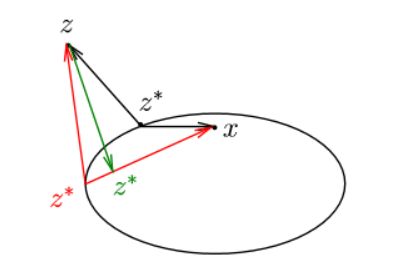
注意区分一下标记,《数值优化》中的标记有所不同。
这个结论不是特别容易,我们首先要说明的是,如果有
考虑一个单独的距离函数,是因为我们的目标函数是求一系列距离函数的最大值。这里牵涉到了下面一个性质。
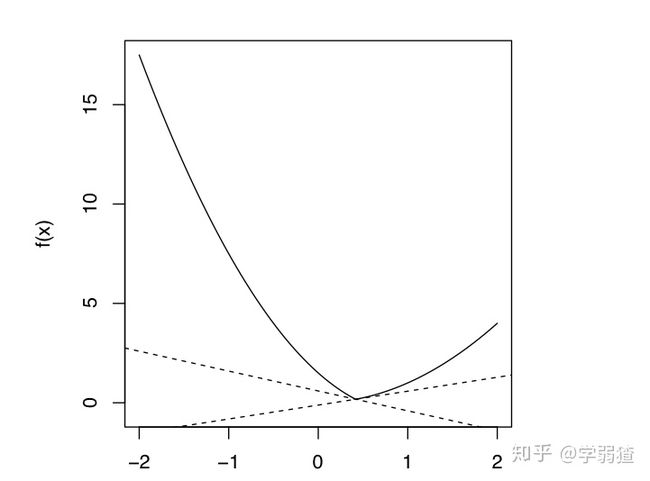
Lemma 1:
若,那么
。
这个乍一看可能不是特别好理解,但假如说我们考虑平面上的两个线性函数的最大值,画一张图来看,这个含义还是很清晰的。
那么这个性质就告诉我们:只要
对于次梯度方法,我们这里使用波利亚步长(见《凸优化》第3节),这是因为波利亚步长计算简单,可以直接得到
简单到不可思议,当然这里的
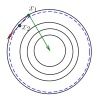
下面一张图就是当集合只有2个的时候模型的结果。可以看出模型就是不停的在两个集合间去“跳转”,最终收敛到一个点,这个点属于两个集合的交集。这一个方法也有自己的名字,叫作交替投影法(Alternating Projections Algorithm)。

那么关于次梯度方法的几个案例,我们就说这么多。
随机梯度下降法
随机梯度下降法(Stochastic Gradient Descent,SGD)也是一个非常有名的机器学习和深度学习中的优化算法。它的名字带有“随机”二字,也正是因为它利用到了统计中的一些知识和概念。
随机梯度下降法一般是解决问题
如果我们使用一般的梯度下降法,可以得到迭代公式
可以发现,如果
这个
那么关于随机梯度下降方法的步长,就没有固定步长的说法了,一般来说都考虑下降步长序列(见《凸优化》第3节)。为什么?假如说我们考虑随机梯度下降和梯度下降法,并且使用固定步长,就会得到下面两个迭代公式
如果快收敛了,这两个迭代点应该不会差距太大。然而右边的差距是
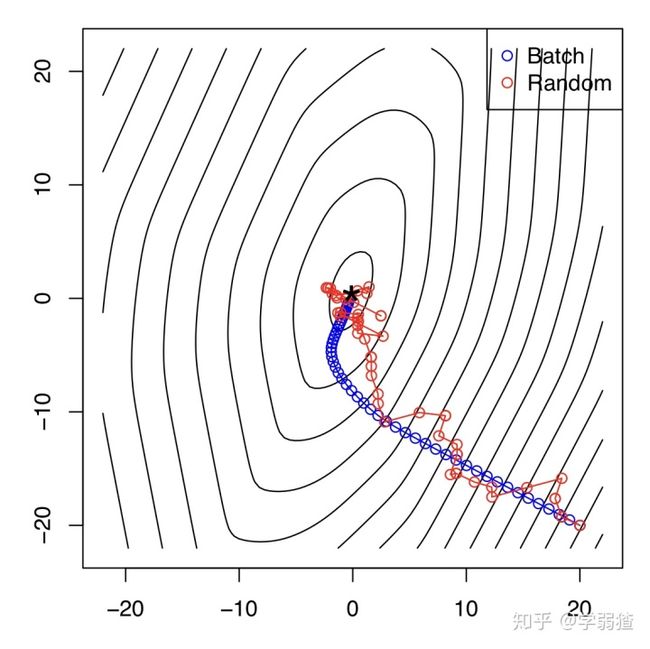
步长说完了,我们来看看它的一些收敛性结果。在我录制的b站视频
https://www.bilibili.com/video/BV1ZK4y1b7Xt/www.bilibili.com中,有对次梯度方法的收敛性给出证明,大体上来说,如果函数
当然了,对于这个方法本身,也有可以考虑优化的点。比方说小批量下降方法(Mini-batch Gradient Descent),它的思路是随机选取一个小批量的指标
同样的,我们希望期望就是
这个方法相比较随机梯度下降方法,因为多抽了几个梯度的方法,所以不稳定性会有减弱(在靠近极小值的时候不会反复横跳的特别厉害hhh)最好的一个收敛速率是
下面这两张图是比较了不同的情况下的收敛速度,其中Full就表示正常的梯度下降法。第一张图的横坐标就是迭代步数,可以看出,在相同的迭代步数下,每一步使用到的信息越多,下降的速度就越快。但是真正的速度其实要对着第二张图看,因为第二张图暴露说,在相同的浮点运算次数下,其实反而是随机梯度下降方法最好,这潜在也说明了,其实保证随机梯度是一个原始梯度的无偏估计,在效率上还是有所保证的,毕竟浮点运算次数才是真正体现了计算机内部运算的复杂性,不然的话随机梯度下降方法明明怎么看收敛速度都不如梯度下降法,为什么反而在大规模问题中是主流算法呢?

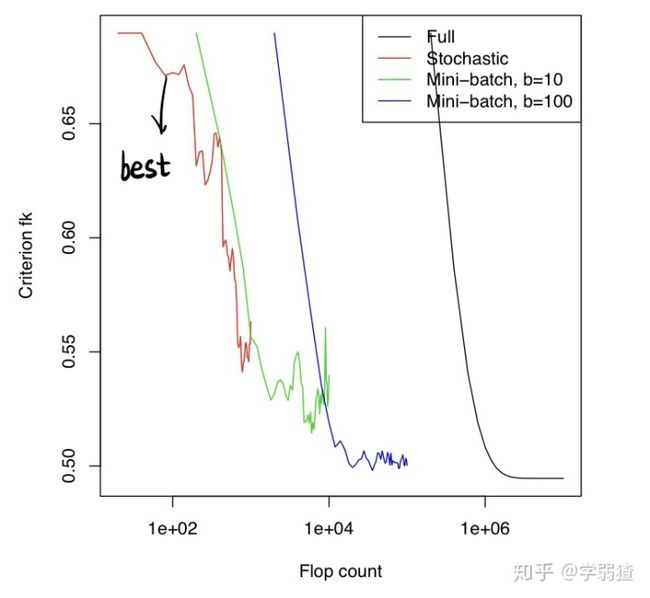
再下一张图是观察次梯度方法与梯度方法在迭代进行过程中的极小值精度。我们上一节(也就是这一节反复出现过的《凸优化》第3节)有提到说,次梯度方法在精度上其实是比较一般的。而在随机梯度下降方法中,这个现象也得到了传承,并且可以看出,信息越多,差距越小。不过这也只是经验性的判断,不能完全的当成一个准则。
大规模问题下的随机梯度下降方法使用技巧
这一部分会非常的不数学,因为有非常多的依赖经验的技巧。这些技巧多见于机器学习,深度学习中。虽说不够数学,但它们都有一些相对比较合理的解释,所以倒也不算是空穴来风。
先说一个比较次要的。
Trick 1:
在使用随机梯度下降进行大规模数据的训练时,可以先在一个小范围的数据集内训练,实验,调参。
这一句话看似是一个废话,但是也是有很多可以说的点。因为实际的数据集之大,往往是撑不住一次训练的时间成本的,所以我们要考虑随机筛选一部分足够泛化的数据。这主要还是为了参数的选取,因为如果我们选的泛化性很好,那么在真正的大规模的数据集下,就没有必要再考虑调参这一步了。
Trick 2:
若使用优化算法解决机器学习中的优化问题,那么一般使用固定步长。
这个要看情况来说,比方说SGD就是一个反例。但如果说去掉SGD,为什么其他方法推荐用固定步长呢?这是因为,对于机器学习来说,它更关心最优解带来的性质,那么这个最优解误差0.01,和误差0.000001,有什么本质区别呢?其实是没有的。这也是为什么次梯度方法虽然有精度的劣势,但是在机器学习中会被应用的原因。
Trick 3:
优化方法无处不在,建议积攒一些调参经验。
emmmm……这个我相信搞深度学习的会很有感触。比方说深度学习中有相当多的优化器,比如说Adam,比如说SVRG,当然SGD自己就是一个被广为使用的优化器。但是究竟对于各种问题中,什么样的形式是效果最好的,这是一个很难回答的问题,可以说没有什么定数,全看命了。
Trick 4:
对于一些带约束的优化问题,提前终止是一个好的方法。
这个可能有点难理解,我们拿逻辑回归来举例子。考虑带罚项的逻辑回归问题
根据优化问题对偶性,这个和带罚项的问题的解是一致的。关于对偶性会在《凸优化》之后的章节重点提到,这里大家知道这个结论就可以了。
事实上,我们可以忽略这个约束,只对目标函数进行一个优化,然后提前终止。这个阴间操作真的能行吗?答案可能会有些出乎意料,因为下面这张图确确实实说明了,两种方法对应的得到的不同的参数的解是非常相近的。图中纵坐标就是分量值,横坐标在这个问题中就是约束值
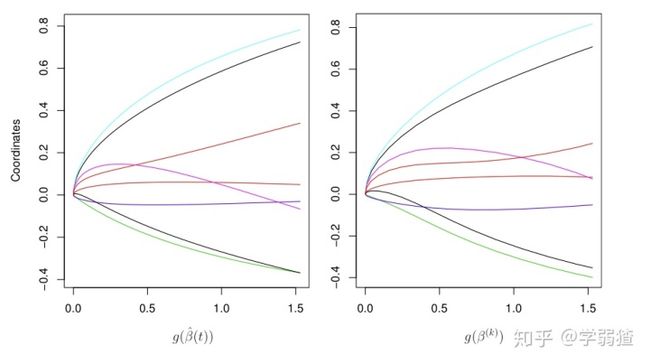
所以我们在实际操作的时候,我们可以观察我们函数值
那么到此为止,关于梯度方法,我们就算说完了。
近端梯度方法引入
你以为到此就结束了?8太可能的,我这字数的kpi还没到呢……还剩一点字数,我们简单说一下近端梯度方法(Proximal Gradient Method)的设计原理。
在这一节我们提到说,对于次梯度方法,它的最好的收敛速度也只是
这里只要求
近端梯度方法的思路其实也来源于梯度下降法。注意到梯度下降法的更新公式为
但是它同时也有表达式
如果我们设
然后考虑变换
注意到变换中,我们只需要求一个关于
所以说现在我们将这个式子拆分成为了两个部分。第一个部分是
那么至于如何解决呢?我们就放到下一节再继续说吧。
小结
这一节我们走马观花的介绍了很多算法的延伸和一些经验性的实操技巧。它们都或多或少的与机器学习,深度学习等等有些关系。当然了这些技巧和实战经验都有一些还算合理的解释和实操方案,了解这些也会对各种有趣的优化算法有更加深层次的理解。
在下一节我们会继续介绍近端梯度方法。如果篇幅允许,我们会开始再回到理论,介绍运筹学中的一些对偶理论。
——————————————————————————————————————

本专栏为我的个人专栏,也是我学习笔记的主要生产地。任何笔记都具有著作权,不可随意转载和剽窃。
个人微信公众号:cha-diary,你可以通过它来获得最新文章更新的通知。
《一个大学生的日常笔记》专栏目录:笔记专栏|目录
《GetDataWet》专栏目录:GetDataWet|目录
想要更多方面的知识分享吗?可以关注专栏:一个大学生的日常笔记。你既可以在那里找到通俗易懂的数学,也可以找到一些杂谈和闲聊。也可以关注专栏:GetDataWet,看看在大数据的世界中,一个人的心路历程。我鼓励和我相似的同志们投稿于此,增加专栏的多元性,让更多相似的求知者受益~