FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据
通用视频分析工具:Mediainfo、Elecard StreamEye(视频编码分析工具);
视频封装格式:
********************MP4******************
MP4:https://blog.csdn.net/qq_25333681/article/details/93144167、https://www.cnblogs.com/ranson7zop/p/7889272.html
还有以mp4为基础进行的扩展或者是缩水版本的格式,包括:M4V, 3GP, F4V
解析工具:mp4info(只有windows版)、mp4box(https://www.videohelp.com/software/MP4Box)、Elecard HEVC Analyzer(除了MP4外还能分析许多其他格式)、在先解析MP4的网站http://download.tsi.telecom-paristech.fr/gpac/mp4box.js/;
MP4总体结构列表:下面表格中的左边六列都是box的类型。
| Box类型 | 必须 | 描述 | |||||
|---|---|---|---|---|---|---|---|
| ftyp | √ | file type and compatibility 文件类型-----在文件的开始位置,描述的文件的版本、兼容协议等 | |||||
| pdin | progressive download information 下载进度 | ||||||
| moov | √ | container for all the metadata 音视频数据的metadata信息------用来存放媒体的metadata信息 | |||||
| mvhd | √ | movie header, overall declarations 电影文件头-----用来存放文件的总体信息,如时长和创建时间等。它是独立于媒体的并且与整个播放相关 | |||||
| trak | √ | container for an individual track or stream 流的track-------trak中的一系列子box描述了每个媒体轨道的具体信息 | |||||
| tkhd | √ | track header, overall information about the track 流信息的track头----包含了该track的特性和总体信息,如时长,宽高等 | |||||
| tref | track reference container track参考容器 | ||||||
| edts | edit list container edit list容器 |
||||||
| elst | an edit list edit list元素 | ||||||
| mdia | √ | container for the media information in a track track里面的media信息-----包含类整个track的媒体信息,比如媒体类型和sample信息 | |||||
| mdhd | √ | media header, overall information about the media media信息头-----包含了了该track的总体信息,mdhd 和 tkhd 内容大致都是一样的。 tkhd 通常是对指定的 track 设定相关属性和内容,而 mdhd 是针对于独立的 media 来设置的,一般情况下二者相同 |
|||||
| hdlr | √ | handler, declares the media (handler) type media信息的句柄----解释了媒体的播放过程信息,该box也可以被包含在meta box(meta)中 | |||||
| minf | √ | media information container media信息容器 | |||||
| vmhd | video media header, overall information (video track only) 视频meida头(只存在于视频的track中)----用在视频track中,包含当前track的视频描述信息(如视频编码等信息) | ||||||
| smhd | sound media header, overall information (sound track only) 音频meida头(只存在于音频的track中) | ||||||
| hmhd | hint media header, overall information (hint track only) 提示meida头(只存在于提示的track中) | ||||||
| nmhd | Null media header, overall information (some tracks only) 空meida头(其他的track中) | ||||||
| dinf | √ | data information box, container 数据信息容器 | |||||
| dref | √ | data reference box, declares source(s) of media data in track 数据参考容器,track中media的参考信息----track可以被分成若干段, 每一段都可以根据“url”或“urn”指向的地址来获取数据,sample描述中会用这些片段的序号将这些片段组成一个完整的track。 一般情况下,当数据被完全包含在文件中时,“url”或“urn”中的定位字符串是空的 |
|||||
| stbl | √ | sample table box, container for the time/space map 采样表容器,容器做时间与数据所在位置的描述------包含了关于track中sample所有时间和位置的信息, 以及sample的编解码等信息 |
|||||
| stsd | √ | sample descriptions (codec types, initialization etc.) 采样描述(cdec类型和初始化信息) | |||||
| stts | √ | (decoding) time-to-sample (decoding)采样时间 | |||||
| ctts | (composition) time to sample (composition)采样时间 | ||||||
| stsc | √ | sample-to-chunk, partial data-offsetinformation chunk采样,数据片段信息 | |||||
| stsz | sample sizes (framing) 采样大小 | ||||||
| stz2 | compact sample sizes (framing) 采样大小的详细描述 | ||||||
| stco | √ | chunk offset, partial data-offset information chunk偏移信息,数据偏移信息 | |||||
| co64 | 64-bit chunk offset 64位的chunk偏移信息 | ||||||
| stss | sync sample table (random access points) 同步采样表 | ||||||
| stsh | shadow sync sample table 采样同步表 | ||||||
| padb | sample padding bits 采样间隔 | ||||||
| stdp | sample degradation priority 采样退化优先描述 | ||||||
| sdtp | independent and disposable samples 独立于可支配采样描述 | ||||||
| sbgp | sample-to-group 采样组 | ||||||
| sgpd | sample group description 采样组描述 | ||||||
| subs | sub-sample information 子采样组描述 | ||||||
| mvex | movie extends box 视频扩展容器 | ||||||
| mehd | movie extends header box 视频扩展容器头 | ||||||
| trex | √ | track extends defaults track扩展信息 | |||||
| ipmc | IPMP Control Box IPMP控制容器 | ||||||
| moof | movie fragment 视频分片-----这个box是视频分片的描述信息。并不是MP4文件必须的部分, 但在我们常见的可在线播放的MP4格式文件中确是重中之重。 |
||||||
| mfhd | √ | movie fragment header 视频分片头 | |||||
| traf | track fragment track分片 | ||||||
| tfhd | √ | track fragment header track分片头 | |||||
| trun | track fragment run track分片run信息 | ||||||
| sdtp | independent and disposable samples 独立和可支配的采样 | ||||||
| sbgp | sample-to-group 采样组 | ||||||
| subs | sub-sample information 子采样组 | ||||||
| mfra | movie fragment random access 视频分片访问控制信息-------一般在文件末尾,媒体的索引文件,可通过查询直接定位所需时间点的媒体数据。 | ||||||
| tfra | track fragment random access track分片访问控制信息 | ||||||
| mfro | √ | movie fragment random access offset 视频分片访问控制偏移量 | |||||
| mdat | media data container media数据容器----用来存储媒体数据,我们最终解码播放的数据都在这里面 | ||||||
| free | free space 空闲区域 | ||||||
| skip | free space 空闲区域 | ||||||
| udta | user-data 用户数据 | ||||||
| cprt | copyright etc. copyright信息 | ||||||
| meta | metadata 元数据 | ||||||
| hdlr | √ | handler, declares the metadata (handler) type 定义元数据的句柄 | |||||
| dinf | data information box, container 数据信息容器 | ||||||
| dref | data reference box, declares source(s) of metadata items 元数据的源参考信息 | ||||||
| ipmc | IPMP Control Box IPMP控制容器 | ||||||
| iloc | item location 所在位置信息容器 | ||||||
| ipro | item protection 样本保护容器 | ||||||
| sinf | protection scheme information box 计划信息保护容器 | ||||||
| frma | original format box 原格式容器 | ||||||
| imif | IPMP Information box IPMP信息容器 | ||||||
| schm | scheme type box 计划类型容器 | ||||||
| schi | scheme information box 计划信息容器 | ||||||
| iinf | item information 容器所在项目信息 | ||||||
| xml | XML container XML容器 | ||||||
| bxml | binary XML container binary XML容器 | ||||||
| pitm | primary item reference 主要参考容器 | ||||||
| fiin | file delivery item information 文件发送信息 | ||||||
| paen | partition entry partition入口 | ||||||
| fpar | file partition 文件片段容器 | ||||||
| fecr | FEC reservoir | ||||||
| segr | file delivery session group 文件发送session组信息 | ||||||
| gitn | group id to name 组id转名称信息 | ||||||
| tsel | track selection track选择信息 | ||||||
| meco | additional metadata container 追加的metadata信息 | ||||||
| mere | metabox relation metabox关系 |
moov和mdat的存放位置前后没有强制要求,在互联网视频点播中,如果希望MP4文件被快速打开,需要将moov放在mdat前面,如果放在后面则需要将MP4文件下载完才能进行播放。
- box:由唯一类型标识符和长度定义的面向对象的构件
- container box:用来容纳一组相关box的box,container box通常都不是fullbox
- chunk:同一轨道的一组连续的采样
- hint track:不包含媒体数据,但包含了将一个或多个轨打包到流频道的指示
- media data box:用来容纳实体数据的box
- movie box:子box定义了元数据(metadata)的容器box
- sample:是媒体数据的存储单元,与单个时间戳相关联的所有数据,video sample即为一帧视频,或一组连续视频帧,audio sample即为一段连续的压缩音频
- sample description:定义和描述轨中的采样的格式的结构
- sample table:指明sampe时序和物理布局的表
- track:按时间排序的相关的采样,对于媒体数据来说,track表示一个视频或音频序列
1.MP4文件由一系列的Box对象组成或者FullBox组成(FullBox是Box的扩展,在Box结构的基础上,在Header中增加了8位的version标志和24位的flags标志),所有的数据都包含在这些box中,除了box之外,无其他数据。Mp4文件中,有且仅有一个FileTypeBox, 类型是ftyp。
track(sample序列或者多个chunk)-》chunk(几个sample)-》sample(一帧视频或一段音频)
2.每一个Box都由Header和Data两部分组成。
3.Box Header包含了size(Box大小)和type(Box 类型)。先是4个字节表示Box大小,后面跟着4个字节表示Box类型,如“ftyp”、“moov”等,这些box type都是已经预定义好的,分别表示固定的意义。如果是“uuid”,表示该box为用户扩展类型。如果box type是未定义的,应该将其忽略。size大小包括Header在内的整个Box占用的大小。在size指定的空间中,除了Box header占用的空间外,其它空间由真实的数据(BoxData)数据占据。这些数据,可能包括其它子Box、也可能是媒体数据。大多数标准的Box使用的都是32位(4个字节)的size和32位type,只有包含了媒体数据的Box需要使用64位size。
size有两种特殊的情形:实际上只有“mdat”类型的box才有可能用出现下面两种情况。
- 当size为1时,BoxHeader中将多出一个64位的largesize,此时Box的大小由largesize决定。
- 当size为0时,表示当前Box是文件中最后一个Box,并且从该Box的Header开始直到文件末尾都是该Box的数据(通常用于保存Media Data)。
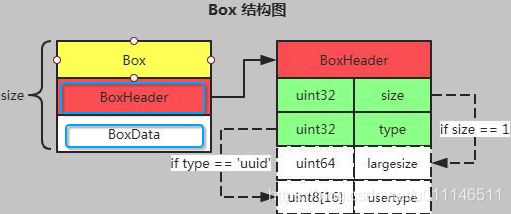

- version字段:version是一个整数值(int),用于表示该Box的版本。
- flags字段: 是一个map类型的标志。
- 如果无法识别的
version应该被忽略或者跳过不处理。
4.常用的Box:
File Type Box:具有兼容性,纯粹的ftyp类型的Box很少见。---在文件的开始位置,描述的文件的版本、兼容协议等;
Box类型:‘ftyp’;容器: 文件;是否强制:是;数量: 1个。
该box有且只有1个,并且只能被包含在文件层,而不能被其他box包含。该box应该被放在文件的最开始,指示该MP4文件应用的相关信息,也不包含其它的Box。

Movie Box
Box类型:‘moov’;容器: 文件;是否强制:是;数量: 1个。
是一个containerbox,用于展示的媒体数据,都包含在moov中,包括音频、视频,同时也包含metedata数据。该Box一般紧跟在ftyp后面,moov占用了大部分的文件空间。'moov’类型的Box主要功能是包含其它类型的Box。该box有且只有一个,且只被包含在文件层。“moov”中会包含1个“mvhd”和若干个“trak”。“mvhd”(Movie Header Box)一般作为“moov”的第一个子box出现。
moov中至少要包含以下三种Box的其中一种:
mvhd:Movie Header Atom,存放未压缩过的影片信息的头容器;
cmov:Compressed Movie Atom,压缩过的电影信息容器,不常用;
rmra:Reference Movie Atom ,参考电影信息容器,不常用;
另外还可以包含其他的容器,如影片剪辑信息clipping(clip)、一个或多个Trak、一个Color Tab(ctab)、一个User Data(udta)。
Movie Header Box-------记录了创建时间、修改时间、时间度量标尺、可播放时长等信息
Box类型:'mvhd ’;容器: Movie Box (‘moov’);是否强制:是;数量: 1个。
该Box定了与媒体数据无关,与媒体文件相关的整体信息。
| 字段 |
字节数 |
意义 |
| box size尺寸 |
4 |
box大小 |
| box type类型 |
4 |
box类型 |
| version版本 |
1 |
Box的版本,在FullBox中定义,0或1,一般为0。(以下字节数均按version=0) |
| flags标志 |
3 |
|
| creation time 生成时间 |
4 |
用于表示图像的创建时间,单位是秒(相对于UTC时间1904-01-01零点的秒数) |
| modification time 修改时间 |
4 |
整数,表示图像最近的修改时间,单位是秒(相对于UTC时间1904-01-01零点的秒数) |
| time scale
|
4 |
整数,文件媒体在1秒时间内的刻度值,指定整体图像文件的时间尺度,表示一秒钟的时间单位数。例如时间坐标轴上,一秒钟分为60个单位,那么时间尺度为60。该值与duration一起计算媒体播放时长。 |
| duration |
4 |
整数,申明媒体持续时长(在指定的时间尺度下),该值和最长的track持续时间的值保持一致。如果无法确定,值将被设置为1s。实际播放时间计算公式:duration/timescale秒。比如audio track的time scale = 8000, duration = 560128,时长为70.016,video track的time scale = 600, duration = 42000,时长为70 |
| rate 播放速度 |
4 |
播放速度,通常为1.0,高16位和低16位分别为小数点整数部分和小数部分,即[16.16] 格式,该值为1.0(0x00010000)表示正常前向播放 |
| volume 音量 |
2 |
播放音量与rate类似,[8.8] 格式,1.0(0x0100)表示最大音量 |
| reserved 保留 |
10 |
保留位 |
| matrix 矩阵结构 |
36 |
视频变换矩阵,两个空间坐标的映射关系 |
| pre-defined 预览时间 |
24 |
预览duration |
| Poster Time | 4 | Poster的时间值 |
| Selection time | 4 | 当前选择时间的开始值 |
| Selection duration | 4 | 当前选择时间的计算后的时间值 |
| 当前时间 | 4 | 当前时间 |
| next track id |
4 |
非零整数,用于表示继续往文件中追加track时使用的id值。下一个track使用的id号,该值肯定比已有trackID大 |
Track Box ------trak中的一系列子box描述了每个媒体轨道的具体信息。
Box类型:'trak ’;容器: Movie Box (‘moov’);是否强制:是;数量: 1个或多个
是一个containerbox,包含了该track的媒体数据引用和描述(hint track除外)。一个MP4文件中的媒体可以包含多个track,且至少有一个track,这些track之间彼此独立,有自己的时间和空间信息。每个Track容器都有与它关联的media容器描述信息。Track Box必须包含Track Header Box(tkhd)和Media Box(mdia),此外还有很多可选的box,例如:
Track 剪辑容器:Track Clipping Box(clip);
Track 画板容器:Track Matte Box(matt) ;
Edit容器:Edit Box(edts);
Track参考容器:Track Reference Box(tref);
Track 配置加载容器:Track Load Setting Box(load);
Track 映射容器:Track Input Map Box(imap);
用户数据容器:User Data Box(udta);
trak容器的主要是使用目的如下:
包含媒体数据的引用和描述(media track);
包含mofier track信息;
流媒体协议的打包信息(hint track),hint track可以引用或者复制对应的媒体采样数据,它本身并不包含媒体数据;
track是多媒体文件中可以独立存操作的媒体单位,一个音频流就是一个track,一个视频流也是一个track。
hint track和mofier track必须保证完整性,同时要与至少一个media track一起存在。
Track Header Box
Box类型:‘tkhd’;容器: Track Box (‘trak’);是否强制:是;数量: 1个
该Box用于描述Track的基本属性,一个track中有且只有一个Track Header Box。
| 字段 | 长度/字节 | 含义 |
|---|---|---|
| 尺寸 | 4 | Box的字节数 |
| 类型 | 4 | tkhd |
| 版本 | 1 | Box的版本 |
| 标志 | 3 | 0x0001:track生效、 0x0002:track被用在Movie中、 0x0004:track被用在Movie预览中、 0x0008:track被用在Movie的Poster中; 媒体轨道的flag标志的默认值为7(即111:track_enabled,track_in_movie,track_in_preview)。 如果在媒体数据中所有轨道都没有设置track_in_movie和track_in_preview,则应将所有轨道视为在所有轨道上都设置了两个标志。 服务器提示轨道(hint track)应将track_in_movie和track_in_preview设置为0,以便在本地回放和预览时忽略它们。 |
| 生成时间 | 4 | Movie Box的起始时间 |
| 修订时间 | 4 | Movie Box的修订时间 |
| Track ID | 4 | 唯一标志改Track的一个非0值 |
| 保留 | 4 | 0 |
| Duration | 4 | 整数,申明媒体持续时长(在Movie Header Box指定的时间尺度下)。如果无法确定,值将被设置为1s。 |
| 保留 | 8 | 0 |
| Layer | 2 | 视频层,默认为0,值小的在上层 |
| alternate_group | 2 | 是一个整数,指定一组或一组轨道,该值默认为0,表示没有和其它轨道关联 |
| 音量 | 2 | Track的音量,1.0为正常音量 |
| 保留 | 2 | 0 |
| 矩阵结构 | 36 | 矩阵定义了此Track中两个坐标空间的映射关系 |
| 宽度 | 4 | 如果Track是video track,表示图像宽度,音频的话应该设置为0; 文字或者字幕track,宽高取决于编码格式,用于描述推荐渲染区域的尺寸。 对于这样的轨道,值0x0也可用于指示数据可以以任何大小呈现,并没有指定最优显示尺寸, 它的实际大小可以通过外部上下文或通过重用另一个轨道的宽高来确定。 对于这种轨道,也可以使用标志track_size_is_aspect_ratio。
|
| 高度 | 4 | 如果Track是video track,表示图像高度,音频的话应该设置为0 |
Media Box
Box类型:‘mdia’;容器: Track Box (‘trak’);是否强制:是;数量: 1个
是一个containerbox,Media Box包含声明有关轨道中媒体数据信息的所有对象,track媒体类型以及sample数据,描述sample信息。这是一个简单的容器对象。
一个Media Box必须包含以下容器:
媒体头:Media Header Box(mdhd);
句柄参考:Handler Reference(hdlr);
媒体信息:Media Infomation(minf);
用户数据:User Data Box(udta);
Media Header Box
Box类型:‘mdhd’;容器: Media Box (‘mdia’);是否强制:是;数量: 1个
Media Header Box 声明整体的媒体信息,这些信息也和track中的媒体特性相关。
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小字节数 |
| box type |
4 |
mdhd |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
|
| creation time |
4 |
创建时间(相对于UTC时间1904-01-01零点的秒数) |
| modification time |
4 |
修改时间 |
| time scale |
4 |
时间计算单位 |
| duration |
4 |
track的时间长度 |
| language |
2 |
媒体语言码。最高位为0,后面15位为3个字符(见ISO 639-2/T标准中定义) |
| pre-defined |
2 |
媒体回放质量,默认值为0 |
Handler Reference Box
Box类型:‘hdlr’;容器: Media Box (‘mdia’)或者Meta Box(‘meta’);是否强制:是;数量: 1个
该Box申明了track的媒体类型,描述了track中媒体数据播放的处理过程。该box也可以被包含在meta box(meta)中。
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
box类型 |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
|
| pre-defined |
4 |
|
| handler type |
4 |
只有两种类型:mhlr和dhlr mhlr:media handlers;它的子类型字段定义的就是数据类型,如下: “vide”— video track “soun”— audio track “hint”— hint track
dhlr:data handlers;它的子类字段定义的是数据引用类型,如文件的别名alis;
|
| reserved 保留 |
12 |
保留字段,默认为0 |
| component name |
不定 |
track type name,以‘\0’结尾的字符串,component就是生成此media的media handler,该字段长度可以为0; |
Media Information Box
Box类型:'minf ’;容器: Media Box (‘mdia’);是否强制:是;数量: 1个
是一个containerbox,该box包含了track中声明了媒体特征信息的所有对象。 它存储了解释track媒体数据的handler-specific信息,media handler用这些信息将媒体时间映射到媒体数据并进行处理。“minf”中的信息格式和内容与媒体类型以及解释媒体数据的media handler密切相关,其他media handler不知道如何解释这些信息。minf容器中的信息将作为音视频数据的映射存在,其包括以下的容器:
视频信息头:Viedo Meida Information Header(vmhd);
音频信息头:Sound Media Information Header (smhd);
数据信息:Data Information(dinf);
采样表:Sample Table(stbl);
Video media header
Box类型:‘vmhd’;容器: Media Information Box (‘minf’);是否强制:是;数量: 1个
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
box类型 |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
1 |
| graphics mode图形模式 |
4 |
视频合成模式,为0时拷贝原始图像,否则与opcolor进行合成 |
| opcolor |
2×3 |
颜色值{red,green,blue} |
Sound Media Header
Box类型:‘smhd’;容器: Media Information Box (‘minf’);是否强制:是;数量: 1个
该Box包含音频相关的媒体信息。该Header对于所有包含了audio的track适用。
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
box类型 |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
0 |
| balance |
2 |
立体声平衡,[8.8] 格式值,一般为0,-1.0表示全部左声道,1.0表示全部右声道,音频均衡是用来控制计算机连个扬声器的声音混合效果。 |
| reserved |
2 |
保留字段,默认值0; |
Track Data Layout Structures
Box类型:‘dinf’;容器: Media Information Box (‘minf’)或者Meta Box (‘meta’);是否强制:是;数量: 1个
是一个containerbox,该Box包含媒体信息在track中的位置信息,包含一个’dref’类型的Box。
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
box类型 |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
0 |
| 条目数目 |
4 |
data references的数目 |
Data Reference Box
Box类型:'dref ’;容器: Data Information Box (‘dinf’);是否强制:是;数量: 1个
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
url/alis/rsrc |
| version |
1 |
data reference的版本 |
| flags |
3 |
0x0001 |
| 数据 |
可变 |
data reference信息 |
Data Reference Box对象包含一个数据引用表(通常是URL),用于声明播放需要使用到的媒体数据的位置。
引用表中的数据索引(index)和track中的数据绑定。通过这种方式,一个track可能被分割为多个sources。
track可以被分成若干段,每一段都可以根据“url”或“urn”指向的地址来获取数据,sample描述(stbl)中会用这些片段的序号将这些片段组成一个完整的track。一般情况下,当数据被完全包含在文件中时,“url”或“urn”中的定位字符串是空的。
Sample Table Box-----指明sampe时序和物理布局的表
Box类型:‘stbl’;容器: Media Information Box (‘minf’);是否强制:是;数量: 1个
是一个containerbox,是MP4中最复杂的一个box,采样参数列表容器它包含了一个track中所有媒体样本的所有时间和数据的引用信息。使用容器中的sample信息,可以定位sample的媒体时间、定位其类型,决定其大小,以及在其它容器中,确定相邻sample的offset。sample是媒体数据存储的单位,存储在media的chunk中。
Sample Table Box它包含以下容器:
采样描述容器:Sample Description Box (stsd);
采样时间容器:Time to Sample Box(stts);
采样同步容器:Sync Sample Box(stss);
Chunk采样容器:Sample To Chunk Box(stsc);
采样大小容器:Sample Size Box(stsz);
Chunk偏移容器:Chunk Offset Box(stco);
Shadow 同步容器:Shadow Sync Box(stsh);
如果Sample Table Box所在的track没有引用任何数据,那么它就不是一个有用的media track,不需要包含任何子Box;
如果Sample Table Box所在的track引用了数据,那么他必须包含以下Box:采样描述容器、采样大小容器、Chunk采样容器、Chunk偏移容器,所有的子表都有相同的sample数目。Sample Description Box (stsd)是必不可少的一个Box,至少包含一个条目,该box包含了Data reference box进行sample数据检索的信息。没有Sample Description Box (stsd)就无法计算media sample的存储位置。“stsd”包含了编码的信息,其存储的信息随媒体类型不同而不同。Sync Sample Box(stss)是可选的,如果不存在Sync Sample Box,则所有样本都是同步样本。
Sample Description Box
Box类型:‘stsd’;容器: Sample Table Box (‘stbl’);是否强制:是;数量: 1个
样本描述容器:提供了编码类型和用于编码初始化的详细信息。视频的编码类型、宽高、长度,音频的声道、采样等信息都会出现在这个box中。
Decoding Time to Sample Box
Box类型:‘stts’;容器: Sample Table Box (‘stbl’);是否强制:是;数量: 1个
该Box包含了一个解码时间到sample索引的映射关系表(Table entries)。entries表中的每个entry给出了具有相同时长的连续sample的数和这些sample的时间间隔值。将这些时间间隔相加在一起,就可以得到一个完整的time与sample之间的映射。将所有的时间间隔相加在一起,就可以得到该track的总时长。 “stts”存储了sample的duration,描述了sample时序的映射方法,我们通过它可以找到任何时间的sample。“stts”可以包含一个压缩的表来映射时间和sample序号,用其他的表来提供每个sample的长度和指针。表中每个条目提供了在同一个时间偏移量里面连续的sample序号,以及samples的偏移量。递增这些偏移量,就可以建立一个完整的time to sample表。
Sync Sample Box
Box类型:‘stss’;容器: Sample Table Box (‘stbl’);是否强制:否;数量: 0个或1个
该Box提供流中同步样本的紧凑标记,标记了关键帧,提供随机访问点标记。 它包含了一个table, table的每个entry标记了一个sample,该sample是媒体关键帧。table按sample编号的严格递增顺序排列。如果不存在该Box,则每个sample都是关键帧。
Composition Time to Sample Box
Box类型:‘ctts’;容器: Sample Table Box (‘stbl’);是否强制:否;数量: 0个或1个
Composition Time to Sample Box也被称为时间合成偏移表,每个音视频的sample都有自己解码顺序和显示顺序。对每个sample而言,解码顺序和显示顺序往往都不相同。这时,就有了Composition Time to Sample Box。
有一种特殊情况,sample的解码顺序和显示顺序一致。那么mp4文件中将不会出现Composition Time to Sample Box,Decoding Time to Sample Box :‘stts’ 将即提供解码顺序,也代表了显示顺序,同时可以根据时长计算每个sample开始和结束的时间。
一般而言,显示顺序和和解码顺序通常不一致(涉及到I、P、B帧的解码顺序)。此时Decoding Time to Sample Box提供解码顺序,Composition Time to Sample Box通过差值的形体,可以计算出显示时间。
Sample To Chunk Box
Box类型:‘stsc’;容器: Sample Table Box (‘stbl’);是否强制:是;数量: 1个
媒体数据中的sample被分组为一个个chunk,一个chunk可以包含多个sample。 chunk可以具有不同的大小,并且chunk内的sample可以具有不同的大小。
Sample To Chunk Box中有一个table,该table可用于查找包含样本的块,其位置以及关联的sample信息。
每个entry都给出具有相同特征的一组chunk的第一个chunk的索引,和这些具有相同特征的chunk中每个包含几个sample。
Sample Size Boxes
Box类型:‘stsz’ 、 'stz2 ’;容器: Sample Table Box (‘stbl’);是否强制:是;数量: 1个
Sample Size Boxes给出了sample的总数,以及一张关于sample大小的表。该表显示了sample和sample size的映射关系。
Chunk Offset Box
Box类型:‘stco’ 、 ‘co64’;容器: Sample Table Box (‘stbl’);是否强制:是;数量: 1个
Chunk Offset Box 包含一个chunk的偏移表,将每个chunk的索引提供给包含文件。 有两种版本,允许使用32位或64位偏移。 后者在管理非常大的演示文稿时非常有用。 这些变体中的至多一个将出现在样本表的任何单个实例中。如果Box类型是’stco’ ,则是32位, 'co64’为64位。偏移是文件偏移,而不是文件中任何Box(例如Media Data Box)的偏移。 这允许在没有任何Box结构的文件中引用媒体数据。 它还意味着在构建一个自包含的ISO文件时必须小心,因为Movie Box的大小会影响媒体数据的块偏移。
edts容器
该容器定义了创建Movie媒体文件中一个track的一部分媒体,所有的edts数据都在一个表里,包括每一部分的时间偏移量和长度,如果没有该表那么track就会立即开始播放,一个空的edts数据用来定位到track的起始时间偏移位置。
***************************FLV****************************
flv:https://blog.csdn.net/weixin_42462202/article/details/88661883、https://blog.csdn.net/whoyouare888/article/details/100095059、https://blog.csdn.net/huibailingyu/article/details/42879573和https://blog.csdn.net/weixin_42462202/article/details/88665310(打包h264到flv)
由Adobe Flash延伸出来的的一种流行网络视频封装格式。可以很好的保护原始地址,不容易被下载到,目前很多视频分享网站都采用这种格式。FLV 封装的媒体文件具有体积轻巧、封装播放简单等特点,很适合网络应用。目前各浏览器普遍使用 Flash Player 作为网页播放器,使得安装有浏览器的计算机终端不需要另外安装播放器,这也是 FLV 格式广为流行的原因之一。
解析工具:flvparse、FlvAnalyzer、命令ffprobe -v trace -i xx.flv也可以解析,还能够将关键帧索引相关信息打印出来;
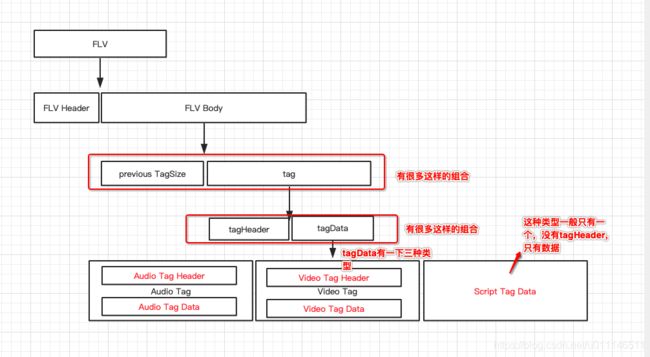
flv的总体结构:
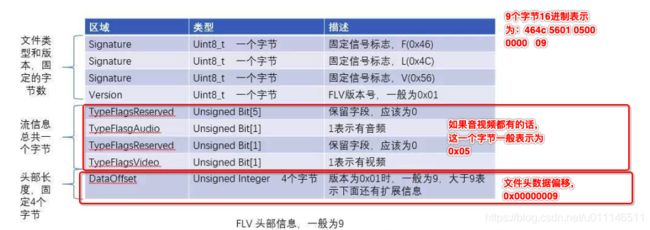
FLVHeader的结构:Header 部分记录了FLV的类型、版本、流信息、Header 长度等。一般整个Header占用9个字节,大于9个字节则表示头部信息在这基础之上还存在扩展数据。
举例:
Signature:0x46('F')
Signature:0x4c('L')
Signature:0x56('V')
Version:01
Flags:01
TypeFlagsReserved [Bit 3-7]:0
TypeFlagsAudio [Bit 2]:0
TypeFlagsReserved [Bit 1]:0
TypeFlagsVideo [Bit 0]:1
DataOffset:00 00 00 09
preTagSize:00 00 00 00 // 第一个tag默认为0
FLV Body的结构:Body 是由多个Tag组成的,每个Tag下面有PreviousTagSize(占4个字节的空间,表示的是PreviousTagSize前面的Tag的大小),用来记录这个Tag 的长度,对于FLV版本0x01来说,数值等于 11(tag header总是11个字节) + Tag的DataSize。

每个FLV Tag 也是由两部分组成的:FLV Tag Header 和 FLV Tag Data。FLV Tag Header 存放了当前Tag的类型,数据长度、时间戳、时间戳扩展、StreamsID等信息,然后再接着数据区FLV Tag Data。
FLV Tag Header :存放了当前Tag的类型,数据长度、时间戳、时间戳扩展、StreamsID等信息。一般tagheader占用11个字节。

举例:
TagType:12(表示这是一个script tag)
Datasize:00 00 9f(Tag Data 部分的大小)
Timestamp:00 00 00(该Tag的时间戳)
Timestamp_ex:00(时间戳的扩展部分)
StreamID::00 00 00(总是0)FLV Tag Data分成 Audio Tag ,Video Tag ,Script Tag 三种。
Audio Tag :音频的Tag Data又分为 Audio Tag Header 和Audio Tag Data 。
Audio Tag Header:通常占用1个字节,包含四个参数。
Audio Tag Data:当音频为AAC编码时,比其他编码会多出一个AACPacketType(占用一个字节),0表示AAC的序列头,1表示裸数据。
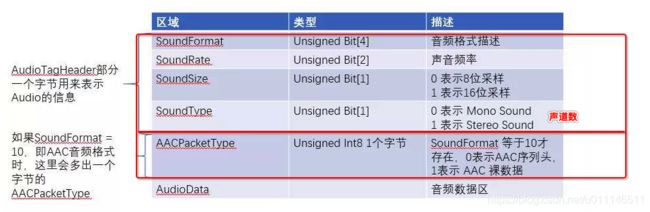
前4bits表示SoundFormat,其数值对应声音格式,如下:
0 - Linear PCM, platform endian
1 - ADPCM
2 - MP3
3 - LinearPCM,little endian
4 - Nellymoser 16-kHz mono
5 - Nellymoser 8-kHZ mono
6 - Nellymoser
7 - G.711 A-law logarithmic PCM
8 - G.711 U-law logarithmic PCM
9 - reserved
10 - AAC
11 - Speex
14 - MP3 8-kHz
15 - Device-specific sound第5、6bit 表示SoundRate,数值对应采样率,对于AAC来说,总是3:
0 - 5.5kHz
1 - 11kHz
2 - 22kHz
3 - 44kHz第7bit 表示采样大小:
0 - snd 8 bit
1 - snd 16 bit第8bit 表示音频声道数,对于AAC来说,总是1:
0 - sndMono
1 - sndStereo
针对AAC编码,AudioData数据区的定义如下:
AACPacketType = 0 时,表示AAC序列头,也就是AudioSpecificConfig, AACPacketType = 1 时,表示AAC的裸流,也就是AAC Raw frame data。
Video Tag :Video Tag 由一个字节的Video Tag Header 和Video Tag Data 。
Video Tag Header:通常由一个字节构成,包含两个参数,前4bit表示类型,后4bit表示编码器Id。

Video Tag Data :下面的例子是H264编码,比一般的编码会多出AACPacketType(占一个字节)和compositionTime(CTS,PTS和DTS的时间差,占三个字节);

如果是H264编码,上面data数据就是NALU数据包,如果有其他编码格式,就是他类型的数据包。
当采用H264编码时,videoData区内容规则如下:AACPacketType = 0 时,data的内容就是AVCDecoderConfigurationRecord;AVCsequenceheader(H264序列头)只会出现在第一个Video Tag,且只有一个。为了能够从FLV中获取NALU,必须知道前面的NALU长度所占的字节数,通常是1、2、4个字节,这个内容则必须从AVCDecoderConfigurationRecord中获取。
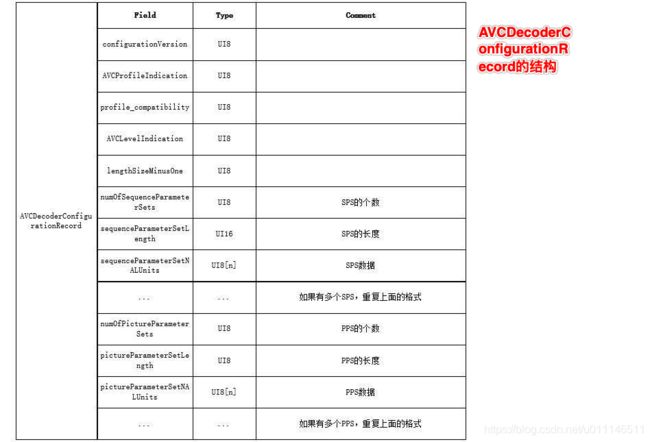
configurationVersion:01
AVCProfileIndication:64
profile_compatibility:00
AVCLevelIndication:1e
lengthSizeMinusOne:ff (NALUSize的长度,计算方法为:1 + (lengthSizeMinusOne & 3)=4)
numOfSequenceParameterSets:e1(低五位为SPS的个数,计算方法为:numOfSequenceParameterSets & 0x1F=1)
sequenceParameterSetLength:00 18(SPS的长度,24)
sequenceParameterSetNALUnits:67 64 00 1e ac d9 40 a0 33 b0 11 00 00 03 02 47 00 00 6d 34 0f 16 2d 96(SPS)
numOfPictureParameterSets:01(PPS的个数)
pictureParameterSetLength:00 06(PPS的长度)
pictureParameterSetNALUnits:68 eb e3 cb 22 c0(PPS)
previousTagSize:00 00 00 39当AACPacketType = 1 时,数据区的内容就是H264裸流数据(NALU数据,NALU length和NALU Data依次交替排列,如下图)。

Script Tag :没有header,只有Script Tag Data。Script Tag 封装了单一方法,此方法通常在 Flash 播放器中的网络流对象上被调用。数据 Tag 包含方法名和一组参数,也就是两个AMF包。当FLV Tag Header中TagType = 0x12时, 这个Tag就是Script tag。Script Tag一般只有一个,是FLV文件的第一个Tag,用于存放FLV文件信息,比如时长、分辨率、音频采样率等。所有的数据都是以数据类型 + (数据长度) + 数据出现,数据类型占1个字节,数据长度看数据类型是否存在,后面才是数据。
Script Tag Data结构包含两个AMF包。AMF(Action Message Format)是Adobe设计的一种通用数据封装格式。AMF(Action Message Format)是Flash与服务端通信的一种常见的二进制编码模式,其传输效率高,可以在HTTP层面上传输。https://blog.csdn.net/cabbage2008/article/details/50500021/、https://www.cnblogs.com/lidabo/p/9018548.html
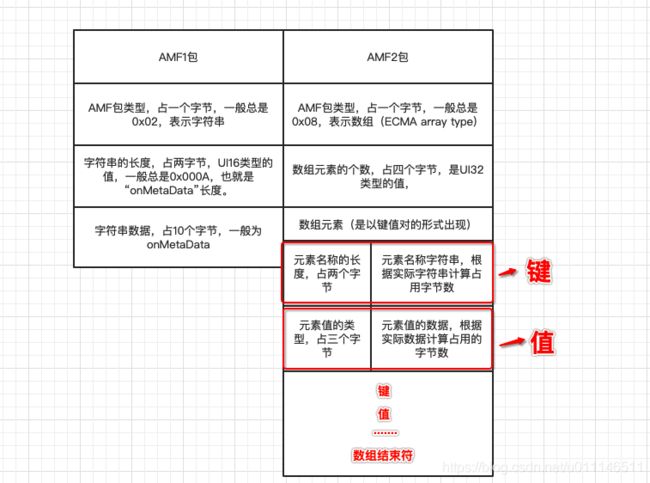
举例:
AMF1包:
type:02(表示字符串)
stringLen:00 0a(字符串长度为10)
string:6f 6e 4d 65 74 61 44 61 74 61(onMetaData)AMF2包:
type:08(表示数组)
arrayNum:00 00 00 07(数组元素个数)
stringLen:00 08(第一个数组元素字符串长度)
string:64 75 72 61 74 69 6f 6e(duration)
valType:00(数据类型,double型)
val:40 03 70 a3 d7 0a 3d 71(double型)
stringLen:00 05
string:77 69 64 74 68(width)
...
end:00 00 09
AMF2包数组中的元素,按照键值对出现,键值对仅跟着上一个键值对,最后还有一个数组的结束符00 00 09。键其实就是属性名(PropertyName包含StringLength和StringData两个数据),值就是属性值(PropertyData包括类型和数据)。
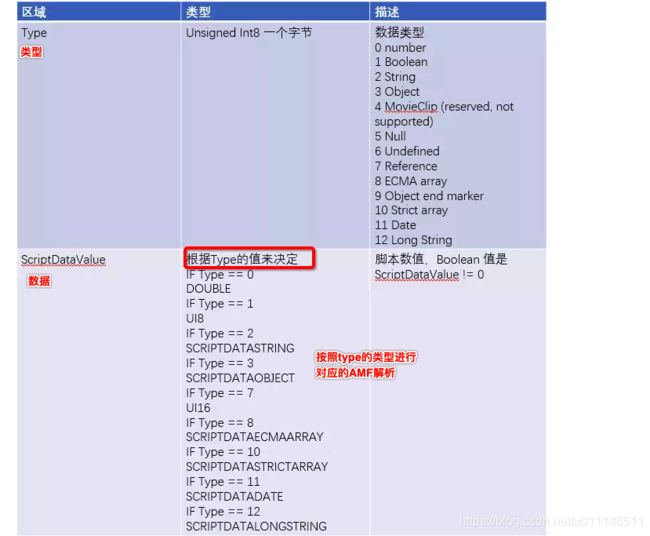
SCRIPTDATAVALUE (AMF2包的内容)的两个字段,Type 是类型,ScriptDataValue 是值。Type 的值确定 ScriptDataValue 的类型。因为 ScriptDataValue 的类型是动态的,由运行时解析得到的 Type 的值确定,所以这里类型和值用了两个字段。如果是静态类型,显然只用一个字段就可以了。
ScriptDataValue 的类型解析如下:
SCRIPTDATA:
SCRIPTDATA 包含 Body 字段。如果采用了加密,Body 的类型是 EncryptedBody。如果未采用加密,则 Body 的类型是 ScriptTagBody。ScriptTagBody 包含以 AMF(Action Message Format) 编码的 SCRIPTDATA。AMF 是一种紧凑二进制格式,用于序列化 ActionScript 对象图。
typedef struct {
IF Encrypted
EncryptedBody Body
else
ScriptTagBody Body;
} SCRIPTDATA;ScriptTagBody:
typedef struct {
SCRIPTDATAVALUE Name;//Data Tag 中的方法名,
SCRIPTDATAVALUE Value;//方法的一组参数
} ScriptTagBody;SCRIPTDATASTRING:
typedef struct {
UI16 StringLength;//StringData 字段的长度,单位字节,
STRING StringData;//字符串实际数据,注意不带结束符 NUL。
} SCRIPTDATASTRING;SCRIPTDATAECMAARRAY:
typedef struct {
UI32 ECMAArrayLength;//ECMA 数组元素个数
SCRIPTDATAOBJECTPROPERTY[] Variables;//变量名和变量值的列表,即 ECMA 数组,数组元素是键值对
SCRIPTDATAOBJECTEND ListTerminator;//列表终止符
} SCRIPTDATAECMAARRAY;SCRIPTDATAOBJECTPROPERTY:
typedef struct {
SCRIPTDATASTRING PropertyName;//对象属性或变量的名称(包含StringLength和StringData两个数据)
SCRIPTDATAVALUE PropertyData;//对象属性或变量的值和类型(包含类型和数据)
} SCRIPTDATAOBJECTPROPERTY;ScriptTagBody onMetaData;
onMetaData.Name.Type == 0x02
onMetaData.Name.ScriptDataValue.StringLength == 0x000A
onMetaData.Name.ScriptDataValue.StringData == "onMetaData"
onMetaData.Value.Type == 0x08
onMetaData.Value.ScriptDataValue.ECMAArrayLength ==
onMetaData.Value.ScriptDataValue.Variables[0].PropertyName == {0x0005, "width"} // SCRIPTDATASTRING 类型
onMetaData.Value.ScriptDataValue.Variables[0].PropertyData == {0x00, 1280.0} // SCRIPTDATAVALUE 类型
onMetaData.Value.ScriptDataValue.Variables[1].PropertyName == {0x0005, "height"} // SCRIPTDATASTRING 类型
onMetaData.Value.ScriptDataValue.Variables[1].PropertyData == {0x00, 720.0} // SCRIPTDATAVALUE 类型
ECMAARRAY数组中值的常用属性字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| audiocodecid | Number | 音频编解码器 ID |
| audiodatarate | Number | 音频码率,单位 kbps |
| audiodelay | Number | 由音频编解码器引入的延时,单位秒 |
| audiosamplerate | Number | 音频采样率 |
| audiosamplesize | Number | 音频采样点尺寸 |
| canSeekToEnd | Boolean | 指示最后一个视频帧是否是关键帧 |
| creationdate | String | 创建日期与时间 |
| duration | Number | 文件总时长,单位秒 |
| filesize | Number | 文件总长度,单位字节 |
| framerate | Number | 视频帧率 |
| height | Number | 视频高度,单位像素 |
| stereo | Boolean | 音频立体声标志 |
| videocodecid | Number | 视频编解码器 ID |
| videodatarate | Number | 视频码率,单位 kbps |
| width | Number | 视频宽度,单位像素 |
ECMA array和strict array的区别在于strict array的length严格规定了数组的长度,因此没有结束标识符。ECMA array有数组结束符。ECMA array的length不一定是数组的真实长度,因此解析时需要判断是否到达00 00 09,而不是用length来做for循环。
***************mov*********************
mov:
Apple公司开发的一种视频格式,默认的播放器是苹果的QuickTime。具有较高的压缩比率和较完美的视频清晰度等特点,并可以保存alpha通道。mov的格式和MP4有点相似,也是Box包含Box。
avi:
优点是图像质量好,无损AVI可以保存alpha通道。缺点也不少,体积过于庞大,而且糟糕的是压缩标准不统一。
***************mkv*****************
mkv:https://www.matroska.org/index.html、https://blog.csdn.net/pakaco/article/details/54924413
Matroska 是开源多媒体容器标准。mkv只是Matroska媒体系列的其中一种文件格式。Matroska媒体定义了几种类型的文件:MKV是视频文件,它里面可能还包含有音频和字幕;MKA是单一的音频文件,但可能有多条及多种类型的音轨;MKS是字幕文件、MK3D files。
Matroska的核心设计特性:文件内的快速查找;高错误恢复率;分章节;可选字幕;可选音频轨;模块化的可扩展性;基于互联网的流传输;类似DVD提供的菜单。
mkv是万能封装器,具有良好的兼容和纠错,可带外挂字幕。这是目前比较主流的多媒体封装格式,这个封装格式可把多种不同编码的视频及 16条或以上不同格式的音频和语言不同的字幕封装到一个Mkv档内。它也是其中一种开放源代码的多媒体封装格式。
MKV是建立在EBML这种语言的基础上,所以要了解MKV格式需要先了解EBML这种语言。
EBML是一种类似于XML格式的可扩展二进制元语言,使用可变长度的整数存储,以节省空间。
EBML基本元素结构:
typedef struct {
vint ID // EBML-ID,ID标志属性类型
vint size // size of element,size为后面data部分的大小
char[size] data // data部分为ID所标识属性的实际数据
} EBML_ELEMENT;上面可以看到ID和size的类型都是vint,vint(Unsigned Integer Values of Variable Length)可变长度无符号整型,比传统32/64位整型更加节省空间。
长度计算方法为:
长度 = 1 +整数前缀0比特的个数.
从MKV文件中简单接一段来举个例子。这是16进制表示方式:
![]()
因为每个EBML元素都是由ID、 size 、data 三部分组成,我们就按照这些来分析。
将0x42 转成2进制 为 01000010 按照上面规则 前面有1个0 所以知道ID的长度为2,也就是ID的值为 0x4282。
将0x88 转成2进制为 10001000 1为开头 长度就是1,去掉前缀1变成了00001000 ,也就是 size的值为 8.
接下来的8个字节就是data值:6D 61 74 72 6F 73 6B 61 根据上面ID值查表得知 这个EMBL 名称为DocType 也就是说data的内容是string格式,所以转成askII码 data值就是“matroska” 和后面显示的一致。
所以这个EBML元素就解析出来了
ID=0x4282;
size=8;
data=“matroska” ;
得到的信息就是 DocType = matroska。
MKV的总体结构:整体来看可分为2大部分:EBML Header和Segment。EBML元素都有自己的级别,每一个高一级的元素由若干次一级的元素组成。
EBML Header由EBMLVersion、DocType等子元素组成,包含了文件的版本、文档类型等相关信息。MKV文件的开头部分是EBML header。
Segment部分保存了媒体文件的视频和音频的实际数据,其data部分又可以分为SeekHead、Tracks、Cluster等若干子元素。MKV除了上面的EBML header,剩下的都属于Segment。
|
EBML Header:
| Element Name | L | EBML ID | Ma | Mu | Rng | Default | T | 1 | 2 | 3 | 4 | W | Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EBML Header | |||||||||||||
| EBML | 0 | [1A][45][DF][A3] | * | * | - | - | m | * | * | * | * | * | Set the EBML characteristics of the data to follow. Each EBML document has to start with this. |
| EBMLVersion | 1 | [42][86] | * | - | - | 1 | u | * | * | * | * | * | The version of EBML parser used to create the file. |
| EBMLReadVersion | 1 | [42][F7] | * | - | - | 1 | u | * | * | * | * | * | The minimum EBML version a parser has to support to read this file. |
| EBMLMaxIDLength | 1 | [42][F2] | * | - | - | 4 | u | * | * | * | * | * | The maximum length of the IDs you'll find in this file (4 or less in Matroska). |
| EBMLMaxSizeLength | 1 | [42][F3] | * | - | - | 8 | u | * | * | * | * | * | The maximum length of the sizes you'll find in this file (8 or less in Matroska). This does not override the element size indicated at the beginning of an element. Elements that have an indicated size which is larger than what is allowed by EBMLMaxSizeLength shall be considered invalid. |
| DocType | 1 | [42][82] | * | - | - | matroska | s | * | * | * | * | * | A string that describes the type of document that follows this EBML header. 'matroska' in our case or 'webm' for webm files. |
| DocTypeVersion | 1 | [42][87] | * | - | - | 1 | u | * | * | * | * | * | The version of DocType interpreter used to create the file. |
| DocTypeReadVersion | 1 | [42][85] | * | - | - | 1 | u | * | * | * | * | * | The minimum DocType version an interpreter has to support to read this file. |
Segment:
| Element Name | L | EBML ID | Ma | Mu | Rng | Default | T | 1 | 2 | 3 | 4 | W | Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Segment | |||||||||||||
| Segment | 0 | [18][53][80][67] | * | * | - | - | m | * | * | * | * | * | This element contains all other top-level (level 1) elements. Typically a Matroska file is composed of 1 segment. |
Meta Seek Information
| Meta Seek Information | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SeekHead | 1 | [11][4D][9B][74] | - | * | - | - | m | * | * | * | * | * | Contains the position of other level 1 elements. |
| Seek | 2 | [4D][BB] | * | * | - | - | m | * | * | * | * | * | Contains a single seek entry to an EBML element. |
| SeekID | 3 | [53][AB] | * | - | - | - | b | * | * | * | * | * | The binary ID corresponding to the element name. |
| SeekPosition | 3 | [53][AC] | * | - | - | - | u | * | * | * | * | * | The position of the element in the segment in octets (0 = first level 1 element). |
Segment Information
| Element Name | L | EBML ID | Ma | Mu | Rng | Default | T | 1 | 2 | 3 | W | Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Segment Information | ||||||||||||
| Info | 1 | [15][49][A9][66] | * | * | - | - | m | * | * | * | * | Contains miscellaneous general information and statistics on the file. |
| SegmentUID | 2 | [73][A4] | - | - | not 0 | - | b | * | * | * | A randomly generated unique ID to identify the current segment between many others (128 bits). | |
| SegmentFilename | 2 | [73][84] | - | - | - | - | 8 | * | * | * | A filename corresponding to this segment. | |
| PrevUID | 2 | [3C][B9][23] | - | - | - | - | b | * | * | * | A unique ID to identify the previous chained segment (128 bits). | |
| PrevFilename | 2 | [3C][83][AB] | - | - | - | - | 8 | * | * | * | An escaped filename corresponding to the previous segment. | |
| NextUID | 2 | [3E][B9][23] | - | - | - | - | b | * | * | * | A unique ID to identify the next chained segment (128 bits). | |
| NextFilename | 2 | [3E][83][BB] | - | - | - | - | 8 | * | * | * | An escaped filename corresponding to the next segment. | |
| SegmentFamily | 2 | [44][44] | - | * | - | - | b | * | * | * | A randomly generated unique ID that all segments related to each other must use (128 bits). | |
| ChapterTranslate | 2 | [69][24] | - | * | - | - | m | * | * | * | A tuple of corresponding ID used by chapter codecs to represent this segment. | |
| ChapterTranslateEditionUID | 3 | [69][FC] | - | * | - | - | u | * | * | * | Specify an edition UID on which this correspondance applies. When not specified, it means for all editions found in the segment. | |
| ChapterTranslateCodec | 3 | [69][BF] | * | - | - | - | u | * | * | * | The chapter codec using this ID (0: Matroska Script, 1: DVD-menu). | |
| ChapterTranslateID | 3 | [69][A5] | * | - | - | - | b | * | * | * | The binary value used to represent this segment in the chapter codec data. The format depends on theChapProcessCodecID used. | |
| TimecodeScale | 2 | [2A][D7][B1] | * | - | - | 1000000 | u | * | * | * | * | Timecode scale in nanoseconds (1.000.000 means all timecodes in the segment are expressed in milliseconds). When combined with TimecodeScaleDenominator the Timecode scale is given by the fraction TimecodeScale/TimecodeScaleDenominator in seconds. |
| TimecodeScaleDenominator | 2 | [2A][D7][B2] | * | - | - | 1000000000 | u | Timecode scale numerator, seeTimecodeScale. | ||||
| Duration | 2 | [44][89] | - | - | > 0 | - | f | * | * | * | * | Duration of the segment (based on TimecodeScale). |
| DateUTC | 2 | [44][61] | - | - | - | - | d | * | * | * | * | Date of the origin of timecode (value 0), i.e. production date. |
| Title | 2 | [7B][A9] | - | - | - | - | 8 | * | * | * | General name of the segment. | |
| MuxingApp | 2 | [4D][80] | * | - | - | - | 8 | * | * | * | * | Muxing application or library ("libmatroska-0.4.3"). |
| WritingApp | 2 | [57][41] | * | - | - | - | 8 | * | * | * | * | Writing application ("mkvmerge-0.3.3"). |
Track
| Element Name |
L |
EBML ID |
Ma |
Mu |
Rng |
Default |
T |
1 |
2 |
3 |
W |
Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Track |
||||||||||||
| Tracks |
1 |
[16][54][AE][6B] |
- |
* |
- |
- |
m |
* |
* |
* |
* |
A top-level block of information with many tracks described. |
| TrackEntry |
2 |
[AE] |
* |
* |
- |
- |
m |
* |
* |
* |
* |
Describes a track with all elements. |
| TrackNumber |
3 |
[D7] |
* |
- |
not 0 |
- |
u |
* |
* |
* |
* |
The track number as used in the Block Header (using more than 127 tracks is not encouraged, though the design allows an unlimited number). |
| TrackUID |
3 |
[73][C5] |
* |
- |
not 0 |
- |
u |
* |
* |
* |
* |
A unique ID to identify the Track. This should be kept the same when making a direct stream copy of the Track to another file. |
| TrackType |
3 |
[83] |
* |
- |
1-254 |
- |
u |
* |
* |
* |
* |
A set of track types coded on 8 bits (1: video, 2: audio, 3: complex, 0x10: logo, 0x11: subtitle, 0x12: buttons, 0x20: control). |
| FlagEnabled |
3 |
[B9] |
* |
- |
0-1 |
1 |
u |
|
* |
* |
* |
Set if the track is usable. (1 bit) |
| FlagDefault |
3 |
[88] |
* |
- |
0-1 |
1 |
u |
* |
* |
* |
* |
Set if that track (audio, video or subs) SHOULD be active if no language found matches the user preference. (1 bit) |
| FlagForced |
3 |
[55][AA] |
* |
- |
0-1 |
0 |
u |
* |
* |
* |
* |
Set if that track MUST be active during playback. There can be many forced track for a kind (audio, video or subs), the player should select the one which language matches the user preference or the default + forced track. Overlay MAY happen between a forced and non-forced track of the same kind. (1 bit) |
| FlagLacing |
3 |
[9C] |
* |
- |
0-1 |
1 |
u |
* |
* |
* |
* |
Set if the track may contain blocks using lacing. (1 bit) |
| MinCache |
3 |
[6D][E7] |
* |
- |
- |
0 |
u |
* |
* |
* |
|
The minimum number of frames a player should be able to cache during playback. If set to 0, the reference pseudo-cache system is not used. |
| MaxCache |
3 |
[6D][F8] |
- |
- |
- |
- |
u |
* |
* |
* |
|
The maximum cache size required to store referenced frames in and the current frame. 0 means no cache is needed. |
| DefaultDuration |
3 |
[23][E3][83] |
- |
- |
not 0 |
- |
u |
* |
* |
* |
* |
Number of nanoseconds (not scaled via TimecodeScale) per frame ('frame' in the Matroska sense -- one element put into a (Simple)Block). |
| TrackTimecodeScale |
3 |
[23][31][4F] |
* |
- |
> 0 |
1.0 |
f |
* |
* |
* |
|
DEPRECATED, DO NOT USE. The scale to apply on this track to work at normal speed in relation with other tracks (mostly used to adjust video speed when the audio length differs). |
| TrackOffset |
3 |
[53][7F] |
- |
- |
- |
0 |
i |
|
|
|
|
A value to add to the Block's Timecode. This can be used to adjust the playback offset of a track. |
| MaxBlockAdditionID |
3 |
[55][EE] |
* |
- |
- |
0 |
u |
* |
* |
* |
|
The maximum value of BlockAddID. A value 0 means there is no BlockAdditions for this track. |
| Name |
3 |
[53][6E] |
- |
- |
- |
- |
8 |
* |
* |
* |
* |
A human-readable track name. |
| Language |
3 |
[22][B5][9C] |
- |
- |
- |
eng |
s |
* |
* |
* |
* |
Specifies the language of the track in theMatroska languages form. |
| CodecID |
3 |
[86] |
* |
- |
- |
- |
s |
* |
* |
* |
* |
An ID corresponding to the codec, see thecodec page for more info. |
| CodecPrivate |
3 |
[63][A2] |
- |
- |
- |
- |
b |
* |
* |
* |
* |
Private data only known to the codec. |
| CodecName |
3 |
[25][86][88] |
- |
- |
- |
- |
8 |
* |
* |
* |
* |
A human-readable string specifying the codec. |
| AttachmentLink |
3 |
[74][46] |
- |
- |
not 0 |
- |
u |
* |
* |
* |
|
The UID of an attachment that is used by this codec. |
| CodecSettings |
3 |
[3A][96][97] |
- |
- |
- |
- |
8 |
|
|
|
|
A string describing the encoding setting used. |
| CodecInfoURL |
3 |
[3B][40][40] |
- |
* |
- |
- |
s |
|
|
|
|
A URL to find information about the codec used. |
| CodecDownloadURL |
3 |
[26][B2][40] |
- |
* |
- |
- |
s |
|
|
|
|
A URL to download about the codec used. |
| CodecDecodeAll |
3 |
[AA] |
* |
- |
0-1 |
1 |
u |
|
* |
* |
|
The codec can decode potentially damaged data (1 bit). |
| TrackOverlay |
3 |
[6F][AB] |
- |
* |
- |
- |
u |
* |
* |
* |
|
Specify that this track is an overlay track for the Track specified (in the u-integer). That means when this track has a gap (seeSilentTracks) the overlay track should be used instead. The order of multiple TrackOverlay matters, the first one is the one that should be used. If not found it should be the second, etc. |
| TrackTranslate |
3 |
[66][24] |
- |
* |
- |
- |
m |
* |
* |
* |
|
The track identification for the given Chapter Codec. |
| TrackTranslateEditionUID |
4 |
[66][FC] |
- |
* |
- |
- |
u |
* |
* |
* |
|
Specify an edition UID on which this translation applies. When not specified, it means for all editions found in the segment. |
| TrackTranslateCodec |
4 |
[66][BF] |
* |
- |
- |
- |
u |
* |
* |
* |
|
The chapter codec using this ID (0: Matroska Script, 1: DVD-menu). |
| TrackTranslateTrackID |
4 |
[66][A5] |
* |
- |
- |
- |
b |
* |
* |
* |
|
The binary value used to represent this track in the chapter codec data. The format depends on the ChapProcessCodecID used. |
| Video |
3 |
[E0] |
- |
- |
- |
- |
m |
* |
* |
* |
* |
Video settings. |
| FlagInterlaced |
4 |
[9A] |
* |
- |
0-1 |
0 |
u |
|
* |
* |
* |
Set if the video is interlaced. (1 bit) |
| StereoMode |
4 |
[53][B8] |
- |
- |
- |
0 |
u |
|
|
* |
* |
Stereo-3D video mode (0: mono, 1: side by side (left eye is first), 2: top-bottom (right eye is first), 3: top-bottom (left eye is first), 4: checkboard (right is first), 5: checkboard (left is first), 6: row interleaved (right is first), 7: row interleaved (left is first), 8: column interleaved (right is first), 9: column interleaved (left is first), 10: anaglyph (cyan/red), 11: side by side (right eye is first), 12: anaglyph (green/magenta), 13 both eyes laced in one Block (left eye is first), 14 both eyes laced in one Block (right eye is first)) . There are some more details on 3D support in the Specification Notes. |
| OldStereoMode |
4 |
[53][B9] |
- |
- |
- |
- |
u |
|
|
|
|
DEPRECATED, DO NOT USE. Bogus StereoMode value used in old versions of libmatroska. (0: mono, 1: right eye, 2: left eye, 3: both eyes). |
| PixelWidth |
4 |
[B0] |
* |
- |
not 0 |
- |
u |
* |
* |
* |
* |
Width of the encoded video frames in pixels. |
| PixelHeight |
4 |
[BA] |
* |
- |
not 0 |
- |
u |
* |
* |
* |
* |
Height of the encoded video frames in pixels. |
| PixelCropBottom |
4 |
[54][AA] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
The number of video pixels to remove at the bottom of the image (for HDTV content). |
| PixelCropTop |
4 |
[54][BB] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
The number of video pixels to remove at the top of the image. |
| PixelCropLeft |
4 |
[54][CC] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
The number of video pixels to remove on the left of the image. |
| PixelCropRight |
4 |
[54][DD] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
The number of video pixels to remove on the right of the image. |
| DisplayWidth |
4 |
[54][B0] |
- |
- |
not 0 |
PixelWidth |
u |
* |
* |
* |
* |
Width of the video frames to display. The default value is only valid when DisplayUnit is 0. |
| DisplayHeight |
4 |
[54][BA] |
- |
- |
not 0 |
PixelHeight |
u |
* |
* |
* |
* |
Height of the video frames to display. The default value is only valid when DisplayUnit is 0. |
| DisplayUnit |
4 |
[54][B2] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
How DisplayWidth & DisplayHeight should be interpreted (0: pixels, 1: centimeters, 2: inches, 3: Display Aspect Ratio). |
| AspectRatioType |
4 |
[54][B3] |
- |
- |
- |
0 |
u |
* |
* |
* |
* |
Specify the possible modifications to the aspect ratio (0: free resizing, 1: keep aspect ratio, 2: fixed). |
| ColourSpace |
4 |
[2E][B5][24] |
- |
- |
- |
- |
b |
* |
* |
* |
|
Same value as in AVI (32 bits). |
| GammaValue |
4 |
[2F][B5][23] |
- |
- |
> 0 |
- |
f |
|
|
|
|
Gamma Value. |
| FrameRate |
4 |
[23][83][E3] |
- |
- |
> 0 |
- |
f |
|
|
|
|
Number of frames per second. Informationalonly. |
| Audio |
3 |
[E1] |
- |
- |
- |
- |
m |
* |
* |
* |
* |
Audio settings. |
| SamplingFrequency |
4 |
[B5] |
* |
- |
> 0 |
8000.0 |
f |
* |
* |
* |
* |
Sampling frequency in Hz. |
| OutputSamplingFrequency |
4 |
[78][B5] |
- |
- |
> 0 |
Sampling Frequency |
f |
* |
* |
* |
* |
Real output sampling frequency in Hz (used for SBR techniques). |
| Channels |
4 |
[9F] |
* |
- |
not 0 |
1 |
u |
* |
* |
* |
* |
Numbers of channels in the track. |
| ChannelPositions |
4 |
[7D][7B] |
- |
- |
- |
- |
b |
|
|
|
|
Table of horizontal angles for each successive channel, see appendix. |
| BitDepth |
4 |
[62][64] |
- |
- |
not 0 |
- |
u |
* |
* |
* |
* |
Bits per sample, mostly used for PCM. |
| TrackOperation |
3 |
[E2] |
- |
- |
- |
- |
m |
|
|
* |
|
Operation that needs to be applied on tracks to create this virtual track. For more detailslook at the Specification Notes on the subject. |
| TrackCombinePlanes |
4 |
[E3] |
- |
- |
- |
- |
m |
|
|
* |
|
Contains the list of all video plane tracks that need to be combined to create this 3D track |
| TrackPlane |
5 |
[E4] |
* |
* |
- |
- |
m |
|
|
* |
|
Contains a video plane track that need to be combined to create this 3D track |
| TrackPlaneUID |
6 |
[E5] |
* |
- |
not 0 |
- |
u |
|
|
* |
|
The trackUID number of the track representing the plane. |
| TrackPlaneType |
6 |
[E6] |
* |
- |
- |
- |
u |
|
|
* |
|
The kind of plane this track corresponds to (0: left eye, 1: right eye, 2: background). |
| TrackJoinBlocks |
4 |
[E9] |
- |
- |
- |
- |
m |
|
|
* |
|
Contains the list of all tracks whose Blocks need to be combined to create this virtual track |
| TrackJoinUID |
5 |
[ED] |
* |
* |
not 0 |
- |
u |
|
|
* |
|
The trackUID number of a track whose blocks are used to create this virtual track. |
| TrickTrackUID |
3 |
[C0] |
- |
- |
- |
- |
u |
|
|
|
|
DivX trick track extenstions |
| TrickTrackSegmentUID |
3 |
[C1] |
- |
- |
- |
- |
b |
|
|
|
|
DivX trick track extenstions |
| TrickTrackFlag |
3 |
[C6] |
- |
- |
- |
0 |
u |
|
|
|
|
DivX trick track extenstions |
| TrickMasterTrackUID |
3 |
[C7] |
- |
- |
- |
- |
u |
|
|
|
|
DivX trick track extenstions |
| TrickMasterTrackSegmentUID |
3 |
[C4] |
- |
- |
- |
- |
b |
|
|
|
|
DivX trick track extenstions |
| ContentEncodings |
3 |
[6D][80] |
- |
- |
- |
- |
m |
* |
* |
* |
|
Settings for several content encoding mechanisms like compression or encryption. |
| ContentEncoding |
4 |
[62][40] |
* |
* |
- |
- |
m |
* |
* |
* |
|
Settings for one content encoding like compression or encryption. |
| ContentEncodingOrder |
5 |
[50][31] |
* |
- |
- |
0 |
u |
* |
* |
* |
|
Tells when this modification was used during encoding/muxing starting with 0 and counting upwards. The decoder/demuxer has to start with the highest order number it finds and work its way down. This value has to be unique over all ContentEncodingOrder elements in the segment. |
| ContentEncodingScope |
5 |
[50][32] |
* |
- |
not 0 |
1 |
u |
* |
* |
* |
|
A bit field that describes which elements have been modified in this way. Values (big endian) can be OR'ed. Possible values: 1 - all frame contents, |
| ContentEncodingType |
5 |
[50][33] |
* |
- |
- |
0 |
u |
* |
* |
* |
|
A value describing what kind of transformation has been done. Possible values: 0 - compression, |
| ContentCompression |
5 |
[50][34] |
- |
- |
- |
- |
m |
* |
* |
* |
|
Settings describing the compression used. Must be present if the value of ContentEncodingType is 0 and absent otherwise. Each block must be decompressable even if no previous block is available in order not to prevent seeking. |
| ContentCompAlgo |
6 |
[42][54] |
* |
- |
- |
0 |
u |
* |
* |
* |
|
The compression algorithm used. Algorithms that have been specified so far are: 0 - zlib, |
| ContentCompSettings |
6 |
[42][55] |
- |
- |
- |
- |
b |
* |
* |
* |
|
Settings that might be needed by the decompressor. For Header Stripping (ContentCompAlgo=3), the bytes that were removed from the beggining of each frames of the track. |
| ContentEncryption |
5 |
[50][35] |
- |
- |
- |
- |
m |
* |
* |
* |
|
Settings describing the encryption used. Must be present if the value of ContentEncodingType is 1 and absent otherwise. |
| ContentEncAlgo |
6 |
[47][E1] |
- |
- |
- |
0 |
u |
* |
* |
* |
|
The encryption algorithm used. The value '0' means that the contents have not been encrypted but only signed. Predefined values: 1 - DES, 2 - 3DES, 3 - Twofish, 4 - Blowfish, 5 - AES |
| ContentEncKeyID |
6 |
[47][E2] |
- |
- |
- |
- |
b |
* |
* |
* |
|
For public key algorithms this is the ID of the public key the the data was encrypted with. |
| ContentSignature |
6 |
[47][E3] |
- |
- |
- |
- |
b |
* |
* |
* |
|
A cryptographic signature of the contents. |
| ContentSigKeyID |
6 |
[47][E4] |
- |
- |
- |
- |
b |
* |
* |
* |
|
This is the ID of the private key the data was signed with. |
| ContentSigAlgo |
6 |
[47][E5] |
- |
- |
- |
0 |
u |
* |
* |
* |
|
The algorithm used for the signature. A value of '0' means that the contents have not been signed but only encrypted. Predefined values: 1 - RSA |
| ContentSigHashAlgo |
6 |
[47][E6] |
- |
- |
- |
0 |
u |
* |
* |
* |
|
The hash algorithm used for the signature. A value of '0' means that the contents have not been signed but only encrypted. Predefined values: 1 - SHA1-160 |
Cluster
| Element Name | L | EBML ID | Ma | Mu | Rng | Default | T | 1 | 2 | 3 | W | Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster | ||||||||||||
| Cluster | 1 | [1F][43][B6][75] | - | * | - | - | m | * | * | * | * | The lower level element containing the (monolithic) Block structure. |
| Timecode | 2 | [E7] | * | - | - | - | u | * | * | * | * | Absolute timecode of the cluster (based on TimecodeScale). |
| SilentTracks | 2 | [58][54] | - | - | - | - | m | * | * | * | The list of tracks that are not used in that part of the stream. It is useful when using overlay tracks on seeking. Then you should decide what track to use. | |
| SilentTrackNumber | 3 | [58][D7] | - | * | - | - | u | * | * | * | One of the track number that are not used from now on in the stream. It could change later if not specified as silent in a further Cluster. | |
| Position | 2 | [A7] | - | - | - | - | u | * | * | * | The Position of the Cluster in the segment (0 in live broadcast streams). It might help to resynchronise offset on damaged streams. | |
| PrevSize | 2 | [AB] | - | - | - | - | u | * | * | * | * | Size of the previous Cluster, in octets. Can be useful for backward playing. |
| SimpleBlock | 2 | [A3] | - | * | - | - | b | * | * | * | Similar to Block but without all the extra information, mostly used to reduced overhead when no extra feature is needed. (see SimpleBlock Structure) | |
| BlockGroup | 2 | [A0] | - | * | - | - | m | * | * | * | * | Basic container of information containing a single Block or BlockVirtual, and information specific to that Block/VirtualBlock. |
| Block | 3 | [A1] | * | - | - | - | b | * | * | * | * | Block containing the actual data to be rendered and a timecode relative to the Cluster Timecode. (see Block Structure) |
| BlockVirtual | 3 | [A2] | - | - | - | - | b | A Block with no data. It must be stored in the stream at the place the real Block should be in display order. (see Block Virtual) | ||||
| BlockAdditions | 3 | [75][A1] | - | - | - | - | m | * | * | * | Contain additional blocks to complete the main one. An EBML parser that has no knowledge of the Block structure could still see and use/skip these data. | |
| BlockMore | 4 | [A6] | * | * | - | - | m | * | * | * | Contain the BlockAdditional and some parameters. | |
| BlockAddID | 5 | [EE] | * | - | not 0 | 1 | u | * | * | * | An ID to identify the BlockAdditional level. | |
| BlockAdditional | 5 | [A5] | * | - | - | - | b | * | * | * | Interpreted by the codec as it wishes (using the BlockAddID). | |
| BlockDuration | 3 | [9B] | - | - | - | TrackDuration | u | * | * | * | * | The duration of the Block (based on TimecodeScale). This element is mandatory when DefaultDuration is set for the track (but can be omitted as other default values). When not written and with no DefaultDuration, the value is assumed to be the difference between the timecode of this Block and the timecode of the next Block in "display" order (not coding order). This element can be useful at the end of a Track (as there is not other Block available), or when there is a break in a track like for subtitle tracks. When set to 0 that means the frame is not a keyframe. |
| ReferencePriority | 3 | [FA] | * | - | - | 0 | u | * | * | * | This frame is referenced and has the specified cache priority. In cache only a frame of the same or higher priority can replace this frame. A value of 0 means the frame is not referenced. | |
| ReferenceBlock | 3 | [FB] | - | * | - | - | i | * | * | * | * | Timecode of another frame used as a reference (ie: B or P frame). The timecode is relative to the block it's attached to. |
| ReferenceVirtual | 3 | [FD] | - | - | - | - | i | Relative position of the data that should be in position of the virtual block. | ||||
| CodecState | 3 | [A4] | - | - | - | - | b | * | * | The new codec state to use. Data interpretation is private to the codec. This information should always be referenced by a seek entry. | ||
| Slices | 3 | [8E] | - | - | - | - | m | * | * | * | * | Contains slices description. |
| TimeSlice | 4 | [E8] | - | * | - | - | m | * | * | * | * | Contains extra time information about the data contained in the Block. While there are a few files in the wild with this element, it is no longer in use and has been deprecated. Being able to interpret this element is not required for playback. |
| LaceNumber | 5 | [CC] | - | - | - | 0 | u | * | * | * | * | The reverse number of the frame in the lace (0 is the last frame, 1 is the next to last, etc). While there are a few files in the wild with this element, it is no longer in use and has been deprecated. Being able to interpret this element is not required for playback. |
| FrameNumber | 5 | [CD] | - | - | - | 0 | u | The number of the frame to generate from this lace with this delay (allow you to generate many frames from the same Block/Frame). | ||||
| BlockAdditionID | 5 | [CB] | - | - | - | 0 | u | The ID of the BlockAdditional element (0 is the main Block). | ||||
| Delay | 5 | [CE] | - | - | - | 0 | u | The (scaled) delay to apply to the element. | ||||
| SliceDuration | 5 | [CF] | - | - | - | 0 | u | The (scaled) duration to apply to the element. | ||||
| ReferenceFrame | 3 | [C8] | - | - | - | - | m | DivX trick track extenstions | ||||
| ReferenceOffset | 4 | [C9] | * | - | - | - | u | DivX trick track extenstions | ||||
| ReferenceTimeCode | 4 | [CA] | * | - | - | - | u | DivX trick track extenstions | ||||
| EncryptedBlock | 2 | [AF] | - | * | - | - | b | Similar to SimpleBlock but the data inside the Block are Transformed (encrypt and/or signed). (see EncryptedBlock Structure) | ||||
Cueing Data
| Cueing Data | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cues | 1 | [1C][53][BB][6B] | - | - | - | - | m | * | * | * | * | A top-level element to speed seeking access. All entries are local to the segment. Should be mandatory for non "live" streams. |
| CuePoint | 2 | [BB] | * | * | - | - | m | * | * | * | * | Contains all information relative to a seek point in the segment. |
| CueTime | 3 | [B3] | * | - | - | - | u | * | * | * | * | Absolute timecode according to the segment time base. |
| CueTrackPositions | 3 | [B7] | * | * | - | - | m | * | * | * | * | Contain positions for different tracks corresponding to the timecode. |
| CueTrack | 4 | [F7] | * | - | not 0 | - | u | * | * | * | * | The track for which a position is given. |
| CueClusterPosition | 4 | [F1] | * | - | - | - | u | * | * | * | * | The position of the Cluster containing the required Block. |
| CueRelativePosition | 4 | [F0] | - | - | - | - | u | The relative position of the referenced block inside the cluster with 0 being the first possible position for an element inside that cluster. | ||||
| CueDuration | 4 | [B2] | - | - | - | - | u | The duration of the block according to the segment time base. If missing the track's DefaultDuration does not apply and no duration information is available in terms of the cues. | ||||
| CueBlockNumber | 4 | [53][78] | - | - | not 0 | 1 | u | * | * | * | * | Number of the Block in the specified Cluster. |
| CueCodecState | 4 | [EA] | - | - | - | 0 | u | * | * | The position of the Codec State corresponding to this Cue element. 0 means that the data is taken from the initial Track Entry. | ||
| CueReference | 4 | [DB] | - | * | - | - | m | * | * | The Clusters containing the required referenced Blocks. | ||
| CueRefTime | 5 | [96] | * | - | - | - | u | * | * | Timecode of the referenced Block. | ||
***********************************TS********************************************
TS:
MPEG-TS一种标准数据容器格式,传输与存储音视频、节目与系统信息协议数据,应用于数字广播系统,譬如DVB,ATSC与IPTV。传输流在MPEG-2第1部分系统中规定,正式称为ISO / IEC标准13818-1或ITU-T建议书[1]。
MPEG2/DVB是一种多媒体传输、复用技术,在数字电视广播中可提供数百个节目频道。复用的含义是,可以同时传输多层节目。
MPEG2-TS从视频的任意位置都可以独立解码。
ts 文件为传输流文件,视频编码主要格式为 H264/MPEG4,音频为 AAC/MP3。
ts 文件分为三层:
- ts 层:Transport Stream,是在 pes 层的基础上加入数据流的识别和传输必须的信息。
- pes 层: Packet Elemental Stream,是在音视频数据上加了时间戳等对数据帧的说明信息。
- es 层:Elementary Stream,即音视频数据。是经过编码的数据。

ts header:
ts包大小固定为188字节,ts层分为三个部分:ts header、adaptation field、payload。ts header固定4个字节;adaptation field可能存在也可能不存在,主要作用是给不足188字节的数据做填充;payload是pes数据。
| sync_byte |
8bit |
同步字节,固定为0x47 |
| transport_error_indicator |
1bit |
传输错误指示符,表明在ts头的adapt域后由一个无用字节,通常都为0,这个字节算在adapt域长度内 |
| payload_unit_start_indicator |
1bit |
负载单元起始标示符,一个完整的数据包开始时标记为1 |
| transport_priority |
1bit |
传输优先级,0为低优先级,1为高优先级,通常取0 |
| pid |
13bit |
pid值(Packet ID号码,唯一的号码对应不同的包) |
| transport_scrambling_control |
2bit |
传输加扰控制,00表示未加密 |
| adaptation_field_control |
2bit |
是否包含自适应区,‘00’保留;‘01’为无自适应域,仅含有效负载;‘10’为仅含自适应域,无有效负载;‘11’为同时带有自适应域和有效负载。 |
| continuity_counter |
4bit |
递增计数器,从0-f,起始值不一定取0,但必须是连续的 |
ts层的内容是通过PID值来标识的,主要内容包括:PAT表、PMT表、音频流、视频流。解析ts流要先找到PAT表,只要找到PAT就可以找到PMT,然后就可以找到音视频流了。PAT表的PID值固定为0。PAT表和PMT表需要定期插入ts流,因为用户随时可能加入ts流,这个间隔比较小,通常每隔几个视频帧就要加入PAT和PMT。PAT和PMT表是必须的,还可以加入其它表如SDT(业务描述表)等,不过hls流只要有PAT和PMT就可以播放了。
- PAT表:他主要的作用就是指明了PMT表的PID值。
- PMT表:他主要的作用就是指明了音视频流的PID值。
- 音频流/视频流:承载音视频内容。
| 表 |
PID 值 |
| PAT |
0x0000 |
| CAT |
0x0001 |
| TSDT |
0x0002 |
| EIT,ST |
0x0012 |
| RST,ST |
0x0013 |
| TDT,TOT,ST |
0x0014 |
adaption
| adaptation_field_length |
1B |
自适应域长度,后面的字节数 |
| flag |
1B |
取0x50表示包含PCR或0x40表示不包含PCR |
| PCR |
5B |
Program Clock Reference,节目时钟参考,用于恢复出与编码端一致的系统时序时钟STC(System Time Clock)。 |
| stuffing_bytes |
xB |
填充字节,取值0xff |
自适应区的长度要包含传输错误指示符标识的一个字节。pcr是节目时钟参考,pcr、dts、pts都是对同一个系统时钟的采样值,pcr是递增的,因此可以将其设置为dts值,音频数据不需要pcr。如果没有字段,ipad是可以播放的,但vlc无法播放。打包ts流时PAT和PMT表是没有adaptation field的,不够的长度直接补0xff即可。视频流和音频流都需要加adaptation field,通常加在一个帧的第一个ts包和最后一个ts包里,中间的ts包不加。
PAT格式(Program Association Table,节目关联表)
PAT表定义了当前TS流中所有的节目,其PID为0x0000,它是PSI的根节点,要查寻找节目必须从PAT表开始查找。
| table_id |
8b |
PAT表固定为0x00 |
| section_syntax_indicator |
1b |
固定为1 |
| zero |
1b |
固定为0 |
| reserved |
2b |
固定为11 |
| section_length |
12b |
后面数据的长度 |
| transport_stream_id |
16b |
传输流ID,固定为0x0001 |
| reserved |
2b |
固定为11 |
| version_number |
5b |
版本号,固定为00000,如果PAT有变化则版本号加1 |
| current_next_indicator |
1b |
固定为1,表示这个PAT表可以用,如果为0则要等待下一个PAT表 |
| section_number |
8b |
固定为0x00 |
| last_section_number |
8b |
固定为0x00 |
| 开始循环 |
|
|
| program_number |
16b |
节目号为0x0000时表示这是NIT,节目号为0x0001时,表示这是PMT |
| reserved |
3b |
固定为111 |
| PID |
13b |
节目号对应内容的PID值 |
| 结束循环 |
|
|
| CRC32 |
32b |
前面数据的CRC32校验码 |
PMT格式( Program Map Table,节目映射表 )
| table_id |
8b |
PMT表取值随意,0x02 |
| section_syntax_indicator |
1b |
固定为1 |
| zero |
1b |
固定为0 |
| reserved |
2b |
固定为11 |
| section_length |
12b |
后面数据的长度 |
| program_number |
16b |
频道号码,表示当前的PMT关联到的频道,取值0x0001 |
| reserved |
2b |
固定为11 |
| version_number |
5b |
版本号,固定为00000,如果PAT有变化则版本号加1 |
| current_next_indicator |
1b |
固定为1 |
| section_number |
8b |
固定为0x00 |
| last_section_number |
8b |
固定为0x00 |
| reserved |
3b |
固定为111 |
| PCR_PID |
13b |
PCR(节目参考时钟)所在TS分组的PID,指定为视频PID |
| reserved |
4b |
固定为1111 |
| program_info_length |
12b |
节目描述信息,指定为0x000表示没有 |
| 开始循环 |
|
|
| stream_type |
8b |
流类型,标志是Video还是Audio还是其他数据,h.264编码对应0x1b,aac编码对应0x0f,mp3编码对应0x03 |
| reserved |
3b |
固定为111 |
| elementary_PID |
13b |
与stream_type对应的PID |
| reserved |
4b |
固定为1111 |
| ES_info_length |
12b |
描述信息,指定为0x000表示没有 |
| 结束循环 |
|
|
| CRC32 |
32b |
前面数据的CRC32校验码 |
pes层是在每一个视频/音频帧上加入了时间戳等信息,pes包内容很多,我们只留下最常用的。 PES层主要分为三个部分PES header(固定6个字节),optional header(可选),和pes payload(也就是ES层了)。
| pes start code |
3B |
开始码,固定为0x000001 |
| stream id |
1B |
音频取值(0xc0-0xdf),通常为0xc0 |
| pes packet length |
2B |
后面pes数据的长度,0表示长度不限制, |
| flag |
1B |
通常取值0x80,表示数据不加密、无优先级、备份的数据 |
| flag |
1B |
取值0x80表示只含有pts,取值0xc0表示含有pts和dts |
| pes data length |
1B |
后面数据的长度,取值5或10 |
| pts |
5B |
33bit值 |
| dts |
5B |
33bit值 |
packet_start_code_prefix: 固定0x000001
stream_id: 指定基本流的类型与编号
PES_packet_length: 表明在该字段后面还有多少个字节。0表明PES包的长度未指示也未限定,对于当前的PES包而言。
PES_scrambling_control: PES包的有效载荷的加扰方式。
PES_priority: 多路复用器可以通过该位最优化基本流内的数据。
data_alignment_indicator:
copyright: PES包中的有效载荷确定具有版权的话,就置位。
orginal_or_copy: 置位时,表明PES包的有效载荷的内容是原始的,非复制的。
PTS_DTS_flags: 2比特字节,表明PTS/DTC的存在情况。
ES_rate_flag: 置位,表明后面存在ES_rate字段。
PES_header_data_length: 表明该PES包头中由任选字段与填充字节所占据的字节总数。任选字段譬如ES_rate。
marker_bit: 为1的比特位。
PTS: 对于音频而言,如果该PES包中存在PTS字段,则有效负载中肯定有新的音频存取单元(access unit),该PTS对应于该音频存取单元。新的音频存取单元指的是一帧新的音频帧。对于视频而言,一般情况下,跟音频一样。
DTS: 解码时间标志,当前CEDARX解码器未用到DTS。
ES_rate: 基本流速率,指定系统目标解码器接收PES包字节的速率。
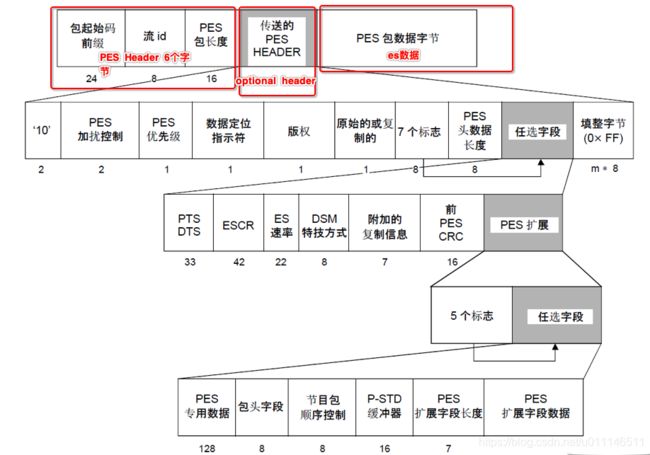
ES---Elementary Streams,是经过编码的视频流或音频流。打包 ES 层数据时 pes 头和 es 数据之间要加入一个 type=9 的 nalu,关键帧 slice 前必须要加入 type=7 和 type=8 的 nalu,而且是紧邻的。
***********************M3U8********************
M3U8:
可以说是索引文件, 是HLS流媒体协议的基础,一般用在HLS直播中。HLS 是新一代流媒体传输协议,其基本实现原理为将一个大的媒体文件进行分片,将该分片文件资源路径记录于 m3u8 文件(即 playlist)内。
「m3u」和「m3u8」文件都是苹果公司bai使用的HTTP Live Streaming(HLS) 协议格式的基础。M3U它是一种播放多媒体列表的文件格式,而m3u8 是使用 UTF-8 编码的 M3U。m3u8格式特点是带有一个目录信息或文件。m3u8说白了只是一个播放列表,里面存的是一堆视频片段的URL,手上的浏览器缓存电影就是m3u8的格式,需要进行转码后才能播放。m3u8记录一个索引纯文本的文件,打开播放时并不是去播放它,而是根据索引找到对应的网络地址在线播放,m3u8的好处就是可以做多码率适配,根据不同的网络带宽,客户端自动选择一个适合的码率进行播放,保证视频的流畅度。
M3U8 文件实质是一个播放列表(playlist),其可能是一个媒体播放列表(Media Playlist),或者是一个主列表(Master Playlist)。
当 M3U8 文件作为媒体播放列表(Media Playlist)时,其内部信息记录的是一系列媒体片段资源,顺序播放该片段资源,即可完整展示多媒体资源。
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
#EXT-X-ENDLIST当 M3U8 作为主播放列表(Master Playlist)时,其内部提供的是同一份媒体资源的多份流列表资源。
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=150000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/low/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=240000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/lo_mid/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=440000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/hi_mid/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=640000,RESOLUTION=640x360,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/high/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=64000,CODECS="mp4a.40.5"
http://example.com/audio/index.m3u8
#EXT-X-ENDLIST
BANDWIDTH 指定码率
RESOLUTION 分辨率
PROGRAM-ID 唯一ID
CODECS 指定流的编码类型常用字段解析:
#EXTM3U M3U8文件头,必须放在第一行;
#EXT-X-MEDIA-SEQUENCE 第一个TS分片的序列号,一般情况下是0,但是在直播场景下,这个序列号标
识直播段的起始位置; #EXT-X-MEDIA-SEQUENCE:0
#EXT-X-TARGETDURATION 每个分片TS的最大的时长; #EXT-X-TARGETDURATION:10 每个分
片的最大时长是 10s
#EXT-X-ALLOW-CACHE 是否允许cache; 默认情况下是YES
#EXT-X-ENDLIST M3U8文件结束符;如果结尾不存在 #EXT-X-ENDLIST,那么一定是直播。
#EXTINF extra info,分片TS的信息,如时长,带宽等;一般情况下是
#EXTINF:,[] 后面可以跟着其他的信息,逗号之前是当前分片的ts时长,分片时长 移动
要小于 #EXT-X-TARGETDURATION 定义的值;
#EXT-X-VERSION M3U8版本号
#EXT-X-DISCONTINUITY 该标签表明其前一个切片与下一个切片之间存在中断。说明有不连续的视频出现,这个视频绝大多数情况下就是广告;
#EXT-X-PLAYLIST-TYPE 表明流媒体类型;VOD 即 Video on Demand,表示该视频流为点播源,因此服务器不能更改该 M3U8 文件。EVENT 表示该视频流为直播源,因此服务器不能更改或删除该文件任意部分内容(但是可以在文件末尾添加新内容)
#EXT-X-KEY 是否加密解析, #EXT-X-KEY:METHOD=AES-
128,URI="https://priv.example.com/key.php?r=52" 加密方式是AES-128,秘钥需要请求
https://priv.example.com/key.php?r=52 ,请求回来存储在本地;</code></pre>
<blockquote>
<ol>
<li><code>#EXTM3U</code>:<br> 每个 m3u8 文件第一行必须是这个 tag,如上面的两个示例。</li>
<li><code>#EXTINF</code>:<br> 指定每个媒体段(ts)的持续时间,这个仅对其后面的 URI 有效,每两个媒体段 URI 间被这个 tag 分隔开<br> 其格式为:<code>#EXTINF:<duration>,<title></code>
<ul>
<li>duration:表示持续的时间(秒),"Durations MUST be integers if the protocol version of the Playlist file is<br> less than 3",否则可以是浮点数。</li>
</ul></li>
<li><code>#EXT-X-BYTERANGE</code>:<br> 表示媒体段是一个媒体 URI 资源中的一段,只对其后的 media URI 有效,<br> 格式为:<code>#EXT-X-BYTERANGE:<n>[@o]</code>
<ul>
<li>n:表示这个区间的大小</li>
<li>o:表示在 URI 中的 offset</li>
<li>The EXT-X-BYTERANGE tag appeared in version 4 of the protocol</li>
</ul></li>
<li><code>#EXT-X-TARGETDURATION</code>:<br> 指定当前视频流中的单个切片(即 ts)文件的最大时长(秒)。所以 #EXTINF 中指定的时间长度必须小于或是等于这个最大值。这个 tag 在整个 Playlist 文件中只能出现一次(在嵌套的情况下,一般有真正<br> ts url 的 m3u8 才会出现该 tag)。格式为:<code>#EXT-X-TARGETDURATION:<s></code>
<ul>
<li>s:表示最大的秒数。</li>
</ul></li>
<li><code>#EXT-X-MEDIA-SEQUENCE</code>:<br> 每一个 media URI 在 Playlist 中只有唯一的序号,相邻之间序号 +1。<br> 格式为:<code>#EXT-X-MEDIA-SEQUENCE:<number></code>。一个 media URI 并不是必须要包含的,如果没有,默认为 0.</li>
<li><code>#EXT-X-KEY</code>:<br> 表示怎么对 media segments 进行解码。其作用范围是下次该 tag 出现前的所有 media URI。<br> 格式为:<code>#EXT-X-KEY:<attribute-list></code>
<ul>
<li>NONE 或者 AES-128。如果是 NONE,则 URI 以及 IV 属性必须不存在,如果是 AES-128(Advanced Encryption Standard),则 URI 必须存在,IV 可以不存在。</li>
<li>对于 AES-128 的情况,keytag 和 URI 属性共同表示了一个 key 文件,通过 URI 可以获得这个 key,如果没有 IV(Initialization Vector),则使用序列号作为 IV 进行编解码,将序列号的高位赋到 16 个字节的 buffer 中,左边补 0;如果有 IV,则将该值当成 16 个字节的 16 进制数。</li>
</ul></li>
<li><code>#EXT-X-PROGRAM-DATE-TIME</code>:<br> 将一个绝对时间或是日期和一个媒体段中的第一个 sample 相关联,只对下一个 media URI 有效,格式如下:<code>#EXT-X-PROGRAM-DATE-TIME:<YYYY-MM-DDThh:mm:ssZ></code>
<ul>
<li>例如:<code>#EXT-X-PROGRAM-DATE-TIME:2010-02-19T14:54:23.031+08:00</code></li>
</ul></li>
<li><code>#EXT-X-ALLOW-CACHE</code>:<br> 是否允许做 cache,这个可以在 Playlist 文件中任意地方出现,并且最多只出现一次,作用效果是所有的媒体段。格式如下:<code>#EXT-X-ALLOW-CACHE:<YES|NO></code></li>
<li><code>#EXT-X-PLAYLIST-TYPE</code>:<br> 提供关于 Playlist 的可变性的信息,这个对整个 Playlist 文件有效,是可选的,格式如下:<code>#EXT-X-PLAYLIST-TYPE:<EVENT|VOD></code>
<ul>
<li>VOD,即为点播视频,服务器不能改变 Playlist 文件,换句话说就是该视频全部的 ts 文件已经被生成好了</li>
<li>EVENT,就是实时生成 m3u8 和 ts 文件。服务器不能改变或是删除 Playlist 文件中的任何部分,但是可以向该文件中增加新的一行内容。它的索引文件一直处于动态变化中,播放的时候需要不断下载二级 index 文件</li>
</ul></li>
<li><code>#EXT-X-ENDLIST</code>:<br> 表示 m3u8 文件的结束,live m3u8 没有该 tag。它可以在 Playlist 中任意位置出现,但是只能出现一个,格式如下:<code>#EXT-X-ENDLIST</code></li>
<li><code>#EXT-X-MEDIA</code>:<br> 被用来在 Playlist 中表示相同内容的不同语种/译文的版本,比如可以通过使用 3 个这种 tag 表示 3 种不同语音的音频,或者用 2 个这个 tag 表示不同角度的 video。在 Playlist 中,这个标签是独立存在的,其格式如下:<code>#EXT-X-MEDIA:<attribute-list></code>
<ul>
<li>该属性列表中包含:URI、TYPE、GROUP-ID、LANGUAGE、NAME、DEFAULT、AUTOSELECT。</li>
<li>URI:如果没有,则表示这个 tag 描述的可选择版本在主 PlayList 的 EXT-X-STREAM-INF 中存在</li>
<li>TYPE:AUDIO and VIDEO</li>
<li>GROUP-ID:具有相同 ID 的 MEDIAtag,组成一组样式</li>
<li>LANGUAGE:identifies the primary language used in the rendition</li>
<li>NAME:The value is a quoted-string containing a human-readable description of the rendition. If the LANGUAGE attribute is present then this description SHOULD be in that language</li>
<li>DEFAULT:YES 或是 NO,默认是 No,如果是 YES,则客户端会以这种选项来播放,除非用户自己进行选择</li>
<li>AUTOSELECT:YES 或是 NO,默认是 No,如果是 YES,则客户端会根据当前播放环境来进行选择(用户没有根据自己偏好进行选择的前提下)</li>
<li>The EXT-X-MEDIA tag appeared in version 4 of the protocol。</li>
</ul></li>
<li><code>#EXT-X-STREAM-INF</code>:<br> 指定一个包含多媒体信息的 media URI 作为 Playlist,一般做 m3u8 的嵌套使用,它只对紧跟后面的 URI 有效,格式如下:<code>#EXT-X-STREAM-INF:<attribute-list></code>
<ul>
<li>常用的属性如下:</li>
<li>BANDWIDTH:带宽,必须有</li>
<li>PROGRAM-ID:该值是一个十进制整数,唯一地标识一个在 Playlist 文件范围内的特定的描述。一个 Playlist 文件中可能包含多个有相同 ID 的此 tag</li>
<li>CODECS:指定流的编码类型,不是必须的</li>
<li>RESOLUTION:分辨率</li>
<li>AUDIO:这个值必须和 AUDIO 类别的 "EXT-X-MEDIA" 标签中 "GROUP-ID" 属性值相匹配</li>
<li>VIDEO:同上</li>
</ul></li>
<li><code>#EXT-X-DISCONTINUITY</code>:<br> 当遇到该 tag 的时候说明以下属性发生了变化:
<ul>
<li>file format</li>
<li>number and type of tracks</li>
<li>encoding parameters</li>
<li>encoding sequence</li>
<li>timestamp sequence</li>
</ul></li>
<li><code>#ZEN-TOTAL-DURATION</code>:<br> 表示这个 m3u8 所含 ts 的总时间长度</li>
</ol>
<p> </p>
</blockquote>
<p>************************************************************************************************************************************************</p>
<p><span style="color:#f33b45;"><strong>音频封装格式:</strong></span></p>
<p><span style="color:#f33b45;">无损压缩</span><br> 无损压缩指的是在无损格式之间的压缩(转换),无论压缩(转换)成什么格式,音质都是相同的,并且都能还原成最初同样的文件。平时所说的无损均是指无损压缩,没有无损码率的说法。对于各种格式的压缩都是对应着一种算法(或者说编码),播放的时候需要有解码器进行译码,而且不同的解码器也可能会影响解压出来的文件完整性。常见的无损格式有:<br><span style="color:#f33b45;">wav</span>:微软公司的一种声音文件格式,是无压缩的最接近真实声音的格式(其次是midi),支持多采样率多量化精度。所有的无损格式本质都是wav的压缩,在播放时会转回wav。<br><span style="color:#f33b45;">flac</span>:Free Lossless Audio Coded,是国际通用格式,特点是压缩比高,编码算法也相当成熟,当flac文件受损时依然能正常播放。另外,该格式也是最先得到广泛硬件支持的无损格式。<br> ape:使用Monkey‘s Audio软件对CD抓轨而转换成的文件格式,但优势并不突出,解码较慢。<br> wma-lossless:也是微软公司出品,特点是压缩比高,但未成为主流。<br><span style="color:#f33b45;">aiff</span>:苹果公司出品,是Apple苹果电脑上面的标准音频格式。<br> DSD:Sony大法的,不是很了解,欣赏不来辣种文化,但就说单纯的冲,还是要冲的。</p>
<p><span style="color:#f33b45;">有损压缩</span><br> 有损压缩指的是声音信息在压缩过程中发生了丢失,且所丢失的声音无法用采样率和位数表示出来。但特点就是压缩后的文件变的很小,常在流媒体中使用。常见的有损格式有:<br><span style="color:#f33b45;">mp3</span>:模拟人耳听觉研究出的一种复杂算法,被称为“心理声学模型”。它通过抽取音频中的一些频段来达到提高压缩比,降低码率,减少所占空间,但同时声音的细节如人声的情感、后期的混响等等都已经发生变形。盲听的话也很难较快地分辨出wav和mp3,需要借助设备。mp3目前是最为普及的声频压缩格式,可以最大程度地保留压缩前的音质。<br><span style="color:#f33b45;">wma</span>:微软公司力作,特点是在较低比特率下(如64kbps),wma可以在与mp3相同的音质条件下获得更小的体积。并且在超低比特率(如16kbps),wma音质比mp3要好得多。<br><span style="color:#f33b45;">aac</span>:苹果电脑上的声音文件储存格式。<br> ogg:完全免费、开放和没有专利限制,但普及性较差。</p>
<p>m4a:M4A是MPEG-4 音频标准的文件的扩展名,最常用的.m4a文件是使用AAC格式的(文件),不过其他的格式,比如Apple Lossless甚至mp3也可以被放在.m4a容器里(TC注:这个container的概念类似于.mkv文件)。可以安全地把只包含音频的.mp4 文件的扩展名改成.m4a。</p>
<p> </p>
<p>************************************************************************************************************************************************</p>
<p><span style="color:#f33b45;"><strong>流媒体协议</strong></span>:常见的直播方式:RTMP、HTTP+FLV、HLS、WEBRTC、RTSP、DASH;</p>
<p><span style="color:#f33b45;">RTMP</span> (Real Time Messaging Protocol):实时信息传输协议,Adobe 公司为 Flash 播放器和服务器之间音视频数据传输开发的私有协议,是一种应用层的协议。工作在 TCP 之上的明文协议,默认使用端口 1935。协议中的基本数据单元成为消息(Message),传输的过程中消息会被拆分为更小的消息块(Chunk)单元。最后将分割后的消息块通过 TCP 协议传输,接收端再反解接收的消息块恢复成流媒体数据。</p>
<p><span style="color:#f33b45;"><code>HLS</code></span> (HTTP Live Streaming) :苹果公司出的,基于 HTTP/80 的流媒体网络传输协议,有效避免防火墙拦截。HLS流可以用于直播,也可以用于点播;https://tools.ietf.org/html/rfc8216</p>
<p>HLS 的工作原理是把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U (m3u8) playlist文件,用于寻找可用的媒体流。我们播放一个HLS,首先要对HLS流对应的M3U8文件进行解析,解析M3U8文件,首先要搞清楚M3U8的封装格式;</p>
<p><span style="color:#f33b45;">HTTP+FLV</span>:将流媒体数据封装成 FLV 格式,然后通过 HTTP 协议传输给客户端。因为网络流量较大,它不适合做拉流协议。</p>
<p>WEBRTC:一个支持网页浏览器进行实时语音对话或视频对话的 API。它于 2011 年 6 月 1 日开源并在 Google、Mozilla、Opera 支持下被纳入万维网联盟的 W3C 推荐标准。目前主要应用于视频会议和连麦中。底层基于 SRTP 和 UDP,弱网情况优化空间大且可以实现点对点通信,通信双方延时低。</p>
<p>RTSP:</p>
<p>DASH:</p>
<p>************************************************************************************************************************************************</p>
<p><span style="color:#f33b45;"><strong>视频编解码协议</strong>:</span>音频数据和音频采样数据PCM的转换;视频数据和视频像素数据YUV或者RGB的转换;编解码协议H264(视频)、AAC(音频)有软编解码和硬编解码。</p>
<blockquote>
<p>在视频编解码技术定义方面有两大标准机构。一个是<span style="color:#f33b45;">国际电信联盟 (ITU)</span> 致力于电信应用,已经开发了用于低比特率视频电话的 <span style="color:#f33b45;"><strong>H.26x 标准</strong></span>,其中包括 H.261、H.262、H.263 与 <u>H.264</u>;另一个是<span style="color:#f33b45;">国际标准化组织 (ISO) </span>主要针对消费类应用,已经针对运动图像压缩定义了<strong><span style="color:#f33b45;"> MPEG 标准</span></strong>。MPEG 标准包括 MPEG1、<u>MPEG2</u> 与 MPEG4。https://blog.csdn.net/eydwyz/article/details/78497534</p>
<p>国际电信联盟ITU-T在完成H.263(针对视频会议之用的串流视频标准)后,与ISO/IEC机构连手合作,由两机构共同成立一个名为JVT(Joint Video Team)的联合工作小组,以MPEG-4技术为基础进行更适于视频会议(Video Conference)运用的衍生发展,联合制订了一个新的标准。 这个标准,ITU-T方面称之为H.264。但ISO/IEC的则将这个新标准归纳于MPEG系列,称为MPEG-4 Part 10(第10部分,也叫ISO/IEC 14496-10),MPEG-4 Part 10的另一个代称是MPEG-4 AVC(Advanced Video Coding,先进视频编码)。</p>
<p>所谓的<span style="color:#f33b45;">H.264其实与MPEG-4/AVC就是同一回事</span>,即H.264=MPEG-4 Part 10=ISO/IEC 14496-10=MPEG-4 AVC。</p>
</blockquote>
<p>编码规范和封装格式多种多样,是因为它们<span style="color:#f33b45;">对应的最佳码率不同:</span></p>
<p>640x272低分辨率的主要是Real Video,最佳码率在350-600Kbps,封装文件格式为RM或者RMVB,我们经常在网上下载的300M左右的电影基本都是RealVideo规范的RMVB文件;</p>
<p>分辨率为1024x438时,一般就开始使用Xvid编码了,码率也在800-1300Kbps不等,封装文件经常是AVI,文件体积在700MB左右;</p>
<p>720P的影片,我们经常下载的X264/AVC编码MKV封装文件,码率5-6MB,音频部分可以达到5.1音效,影音效果很不错,但文件体积都在4.3GB上下,一张DVD碟的容量,网上下载往往需要数天;</p>
<p>1080P影片经常采用的有H.264编码和VC1编码,码率30Mbps上下,体积达到22-40GB,虽然效果震撼,但是不方便网络共享。对于容量8GB左右的MP4,综合视频来源以及体积,最适合的是Xvid编码、码率在1300Kbps左右、文件体积700MB-1.4GB的AVI,以及同样码率和体积的RV40编码RMVB,还有码率350-600Kbps的RMVB。</p>
<p><strong>常见封装格式和编解码器常用组合</strong>:(标注所有格式的,表示大多数的格式都可以用;下面的表格中只标注了主要格式/常用格式,还有其他比较老的格式/用的不多的格式,具体情况自行网络查询)</p>
<table>
<thead>
<tr>
<th>封装容器</th>
<th>视频流编码格式</th>
<th>音频流编码格式</th>
</tr>
</thead>
<tbody>
<tr>
<td>AVI</td>
<td>Xvid</td>
<td>MP3</td>
</tr>
<tr>
<td>AVI</td>
<td>Divx</td>
<td>MP3</td>
</tr>
<tr>
<td>Matroska(后缀就是MKV)</td>
<td>Xvid(所有格式)</td>
<td>MP3(所有格式)</td>
</tr>
<tr>
<td>Matroska(后缀就是MKV)</td>
<td>Xvid(所有格式)</td>
<td>AAC(所有格式)</td>
</tr>
<tr>
<td>Matroska(后缀就是MKV)</td>
<td>H264(所有格式)</td>
<td>AAC(所有格式)</td>
</tr>
<tr>
<td>MP4</td>
<td>Xvid</td>
<td>MP3</td>
</tr>
<tr>
<td>MP4</td>
<td>H264</td>
<td>AAC</td>
</tr>
<tr>
<td>3GP</td>
<td>H.263</td>
<td>AAC</td>
</tr>
</tbody>
</table>
<table>
<thead>
<tr>
<th>封装容器</th>
<th>视频流编码格式</th>
<th>音频流编码格式</th>
</tr>
</thead>
<tbody>
<tr>
<th>flv </th>
<td>H264</td>
<td>AAC、MP3</td>
</tr>
<tr>
<td>f4v</td>
<td>H264</td>
<td>AAC、MP3</td>
</tr>
<tr>
<td>mov</td>
<td>所有格式</td>
<td>所有格式</td>
</tr>
<tr>
<td>ts</td>
<td>MPEG-4、H264</td>
<td>AAC</td>
</tr>
<tr>
<td>ASF</td>
<td>所有格式</td>
<td>所有格式</td>
</tr>
<tr>
<td> </td>
<td> </td>
<td> </td>
</tr>
<tr>
<td> </td>
<td> </td>
<td> </td>
</tr>
<tr>
<td> </td>
<td> </td>
<td> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>***<span style="color:#f33b45;">MPEG-4</span>(<span style="color:#f33b45;"><strong>Xvid</strong></span> 和<span style="color:#f33b45;"><strong>Divx)</strong></span>***</p>
<p>Xvid是一个开放源代码的视频编解码器。</p>
<p>Divx是基于MPEG4标准的编码器。有免费和收费版本。</p>
<p><strong>***<span style="color:#f33b45;">H265</span>***</strong></p>
<p>H.265(HEVC)标准围绕着现有的视频编码标准H.264,保留原来的某些技术,同时对一些相关的技术加以改进。新技术使用先进的技术用以改善码流、编码质量、延时和算法复杂度之间的关系,达到最优化设置。具体的研究内容包括:提高压缩效率、提高鲁棒性和错误恢复能力、减少实时的时延、减少信道获取时间和随机接入时延、降低复杂度等。</p>
<p>H265的结构和H264相似,也是一个个Nalu组成,一个nalu开始是四个字节的起始码00000001,接着是Nalu头,接着是数据RBSP,<span style="color:#f33b45;">h265的nal unit header由两个字节构成(H264的头由一个字节构成)</span>,如下图所示 :</p>
<p>0 1<br> 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5<br> + -+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+<br> | F | Type | LayerId | TID |<br> +------------ - +---------------- - +</p>
<p>hevc加入了nal所在的时间层的TID,原来H264中的nal_ref_idc信息合并到了naltype中,通常情况下F为0,layerid为0, TID为1。</p>
<p>其语法如下表中的定义:</p>
<table border="1">
<tbody>
<tr>
<td> <p>nal_unit_header( ) {</p> </td>
<td> <p>Descriptor</p> </td>
</tr>
<tr>
<td> <p><strong> forbidden_zero_bit</strong></p> </td>
<td> <p>f(1)</p> </td>
</tr>
<tr>
<td> <p><strong> nal_unit_type</strong></p> </td>
<td> <p>u(6)</p> </td>
</tr>
<tr>
<td> <p><strong> nuh_reserved_zero_6bits</strong></p> </td>
<td> <p>u(6)</p> </td>
</tr>
<tr>
<td> <p> <strong>nuh_temporal_id_plus1</strong></p> </td>
<td> <p>u(3)</p> </td>
</tr>
<tr>
<td> <p>}</p> </td>
<td> <p> </p> </td>
</tr>
</tbody>
</table>
<blockquote>
<p>H265的帧类型分析:</p>
<p> 00 00 00 01 40 01 的nuh_unit_type的值为 32, 语义为视频参数集 VPS</p>
<p> 00 00 00 01 42 01 的nuh_unit_type的值为 33, 语义为序列参数集 SPS</p>
<p> 00 00 00 01 44 01 的nuh_unit_type的值为 34, 语义为图像参数集 PPS</p>
<p> 00 00 00 01 4E 01 的nuh_unit_type的值为 39, 语义为补充增强信息 SEI</p>
<p> 00 00 00 01 26 01 的nuh_unit_type的值为 19, 语义为可能有RADL图像的IDR图像的SS编码数据 IDR</p>
<p> 00 00 00 01 02 01 的nuh_unit_type的值为1, 语义为被参考的后置图像,且非TSA、非STSA的SS编码数据</p>
</blockquote>
<p>H265 帧类型判断:int type = (code & 0x7E)>>1;(h264的判断:<strong>int</strong> nalu_type = (frame[4] & 0x1F);)</p>
<p> </p>
<p><strong>***<span style="color:#f33b45;">H264</span>***</strong></p>
<p><strong>h264的压缩比是最高的,主要应用于低码率下的实时在线播放。</strong></p>
<p><strong>h264文档:</strong>http://read.pudn.com/downloads147/ebook/635957/新一代视频压缩编码标准H.264.pdf</p>
<p>h264原理:https://www.jianshu.com/p/1b3f8187b271、</p>
<p>H264码流结构分析:https://www.cnblogs.com/mamamia/p/8580097.html、https://www.jianshu.com/p/9522c4a7818d</p>
<p>h264协议帧头数据解析:https://www.jianshu.com/p/e061bc1c20c8</p>
<p id="articleContentId">H264中的NALU概念解析:https://blog.csdn.net/pkx1993/article/details/79974858</p>
<p>FFmpeg的H.264解码器源代码简单分析:https://blog.csdn.net/leixiaohua1020/article/details/45001033</p>
<p>数据有大小不定的nalu构成,最常见的是一个nalu存储了一帧压缩编码后的数据.<span style="color:#f33b45;">H.264编解码比较复杂,要经过帧内预测、帧间预测、熵编码、环路滤波;</span></p>
<p>对于一段连续的帧图像来说,前一帧和后一帧之间的关联度和相似性很高,只记录当前帧和下一帧与当前帧之间的帧数据差,能够快速的帮助我们实现视频压缩编解码。为了方便图像之间的压缩,将原图像当前帧设置为Fn,下一帧设置为Fn-1;</p>
<p>对Fn进行<strong>帧内相似压缩编码</strong>,使用估计函数进行重新映射(图像还原);再利用当前帧对图和帧差信息对下一帧图片进行估计和还原。具体编码框架如下图:</p>
<p><br><a href="http://img.e-com-net.com/image/info8/8f7e1001782c4ac68acb754dbe8c4b17.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第17张图片" height="280" src="http://img.e-com-net.com/image/info8/8f7e1001782c4ac68acb754dbe8c4b17.jpg" width="650" style="border:1px solid black;"></a></p>
<p>在上图中,输入的帧或场Fn以宏块为单位被编码器处理。首先,按帧内或者帧间预測编码的方法进行处理。假设採用帧间预測编码,其预測值PRED是由当前片中前面已编码的參考图像经运动补偿(MC)后得到,当中參考图像用F’n-1表示。预測值PRED和当前块相减后,产生一个残差块Dn,经块变换、量化后产生一组量化后的变换系数X,再经熵编码,与解码所需的一些头信息一起组成压缩后的码流,经NAL(网络自适应层)供传输和存储用。</p>
<p> </p>
<p><a href="http://img.e-com-net.com/image/info8/03181dac12cf41f79b584c17a56239b9.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第18张图片" height="159" src="http://img.e-com-net.com/image/info8/03181dac12cf41f79b584c17a56239b9.jpg" width="650" style="border:1px solid black;"></a></p>
<p>将编码器的NAL输出的H264比特流经熵解码得到量化后的一组变换系数X,再经反量化、反变换,得到残差D’n。利用从该比特流中解码出的头信息,解码器就产生一个预測块PRED,它和编码器中的原始PRED是同样的。当该解码器产生的PRED与残差D’n相加后,就得到了uF’n,再经滤波后,最后就得到滤波后的解码输出图像F’n</p>
<p><strong>H264采用了独特的I帧、P帧和B帧策略来实现,连续帧之间的压缩</strong>;</p>
<p>h264的压缩方法:H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。在H264中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流,以I帧开始,到下一个I帧结束。<strong>一个序列就是一段内容差异不太大的图像编码后生成的一串数据流</strong>。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个I帧和3、4个P帧。GOP,也就是一个序列;</p>
<p>1.分组:把几帧图像分为一组(GOP,也就是一个序列),为防止运动变化,帧数不宜取多。 <br> 2.定义帧:将每组内各帧图像定义为三种类型,即I帧、B帧和P帧; <br> 3.预测帧:以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧; <br> 4.数据传输:最后将I帧数据与预测的差值信息进行存储和传输。</p>
<p>宏块: 在H.264中,句法元素被组织成五个层次:序列(sequence)、图像(frame/field-picture)、片(slice)、宏块(macroblock)、子块(sub-block)。https://blog.csdn.net/ivy_reny/article/details/47144121</p>
<p><a href="http://img.e-com-net.com/image/info8/c9253857134541449c651cace16a18ee.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第19张图片" height="280" src="http://img.e-com-net.com/image/info8/c9253857134541449c651cace16a18ee.jpg" width="650" style="border:1px solid black;"></a></p>
<p>宏块是编码处理的基本单元,通常宏块大小为16x16个像素。一个编码图像首先要划分成多个块(4x4 像素)才能进行处理,显然宏块应该由整数个块组成. 输入的帧或场Fn以宏块为单位被编码器处理。</p>
<p> 视频压缩中,一幅图像(picture)可以分成一帧(frame)或两场(field)。在H.264中,一幅图像可以编码为一个或多个片(slice),每个slice由宏块组成,一个宏块由一个16×16亮度像素和附加的一个8×8 Cb和一个8×8 Cr彩色像素块组成。宏块是H.264编码的基本单位,可以采用不同的编码类型。slice共有5种类型。slice的目的是为了限制误码的扩散和传输,使编码片相互间保持独立。一个slice编码之后被打包进一个NALU(NALU相当一个片),<span style="color:#f33b45;">NALU除了容纳slice还可以容纳其它数据,如序列参数集SPS、PPS、SEI等</span>。 </p>
<p>H.264 原始码流(又称为裸流),是有一个接一个的 NALU 组成的,而它的功能分为两层:<span style="color:#f33b45;">视频编码层</span>(VCL, Video Coding Layer)和<span style="color:#f33b45;">网络提取层</span>(NAL, Network Abstraction Layer)。<br> VCL数据是被压缩编码后的视频数据序列。在 VCL 数据传输或存储之前,这些编码的 <span style="color:#f33b45;">VCL 数据,先被映射或封装进 NAL 单元</span>(以下简称 NALU,Nal Unit) 中。在<span style="color:#f33b45;">VCL数据要封装到NAL单元中之后,才可以用来传输或存储。</span><br> 一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成,第一部分 Start Code 用于标示这是一个NALU 单元的开始,必须是"00 00 00 01"(帧开始) 或"00 00 01"(帧中)。第二部分是<span style="color:#f33b45;">对应于视频编码的 NALU 头部信息。</span>第三部分是<span style="color:#f33b45;">一个原始字节序列负荷(RBSP, Raw Byte Sequence Payload),</span>它的基本结构是:在原始编码数据的后面填加了结尾 比特。一个 bit“1”若干比特“0”,以便字节对齐。</p>
<p><a href="http://img.e-com-net.com/image/info8/6c0eda07fde94c68b34df7a6b5feca32.jpg" target="_blank"><img alt="" height="58" src="http://img.e-com-net.com/image/info8/6c0eda07fde94c68b34df7a6b5feca32.jpg" width="650"></a></p>
<p>(1)VCL只关心编码部分,重点在于编码算法以及在特定硬件平台的实现,<span style="color:#f33b45;">VCL输出的是编码后的纯视频流信息,没有任何冗余头信息</span>。<br> (2)NAL关心的是VCL的输出纯视频流如何被<span style="color:#f33b45;">表达和封包</span>以利于网络传输。</p>
<p>做编码器的人关心的是VCL部分;做视频传输和解码播放的人关心的是NAL部分。</p>
<p><strong>slice的概念</strong>:slice的目的是为了限制误码的扩散和传输,使编码片相互间保持独立。一幅图像(picture)可以分成<span style="color:#f33b45;">一帧(frame)或两场(field)</span>。在H.264中,一幅图像可以编码为一个或多个片(slice),每个slice由宏块组成。https://www.jianshu.com/p/c38506f50eb7</p>
<p>一帧图片经过 H.264 编码器之后,就被编码为一个或多个片(slice),而装载着这些片(slice)的载体,就是 NALU 了。一个frame是可以分割成多个Slice来编码的,而<strong>一个Slice编码之后被打包进一个NAL单元</strong>,不过NAL单元除了容纳Slice编码的码流外,还可以容纳其他数据,比如序列参数集SPS。<br> (1)SODB:String Of Data Bits ,最原始 的编码数据,没有任何附加数据 。<br> (2)RBSP:Raw Byte Sequence Payload ,在 SODB 的基础上加了rbsp_stop_ont_bit(bit 值为 1)并用 0 按字节补位对齐 。<br> (3)EBSP:在 RBSP 的基础上在最后一个字节前增加了防止伪起始码字节(0X03) 。<br> (4)NALU:Network Abstraction Layer Units,<span style="color:#f33b45;">是对RBSP的封装</span>。<span style="color:#f33b45;">RTP是对NALU的封装</span>。</p>
<p> (5)关系:SODB + RBSP trailing bits = RBSP。<br> NAL header(1 byte) + RBSP = NALU。</p>
<p> </p>
<p>RBSP:封装于网络抽象单元的数据称之为原始字节序列载荷RBSP,它是NAL的基本传输单元。其中,RBSP又分为视频编码数据和控制数据。其基本结构是:在原始编码数据的后面填加了结尾比特。一个bit“1”若干比特“0”,以便字节对齐。</p>
<p><strong>码流是由一个个的NAL Unit组成的,NALU是<span style="color:#f33b45;">由NALU头和RBSP数据组成</span>,RBSP可能是<span style="color:#f33b45;">SPS,PPS,Slice或SEI</span>,目前我们这里SEI不会出现,而且SPS位于第一个NALU,PPS位于第二个NALU,其他就是Slice(严谨点区分的话可以把IDR等等再分出来)了。</strong></p>
<p> </p>
<blockquote>
<p>NALU头由<span style="color:#f33b45;">一个字节(8bit)</span>组成,它的语法如下:</p>
<p>forbidden_zero_bit:禁止位,占一个bit, 在 H.264 规范中规定了这一位必须为 0, 0表示网络传输没有出错 ,1表示语法出错。</p>
<p>nal_reference_bit:占两个bit,取值范围为0~3,取值越大,表示当前NAL越重要,需要优先受到保护。如果当前NAL是属于参考帧的片,或是序列参数集,或是图像参数集这些重要的单位时,本句法元素必需大于0。</p>
<p>nal_unit_type:占5个bit,NAL的类型,1~12由H.264使用,24~31由H.264以外的应用使用,简述如下:</p>
<p>0 没有定义</p>
<p>1-23 NAL单元 单个 NAL 单元包</p>
<p>1 不分区,非IDR图像的片-----0x61</p>
<p>2 片分区A</p>
<p>3 片分区B-------0x01</p>
<p>4 片分区C</p>
<p>5 IDR图像中的片段------------0x65</p>
<p>6 补充增强信息单元(SEI)-------0x06</p>
<p>7 序列参数集SPS---------0x67</p>
<p>8 图像参数集PPS---------0x68</p>
<p>9 分割符</p>
<p>10 序列结束符</p>
<p>11 码流结束符</p>
<p>12 填充数据</p>
<p>13-23 保留</p>
<p>24 STAP-A 单一时间的组合包</p>
<p>25 STAP-B 单一时间的组合包</p>
<p>26 MTAP16 多个时间的组合包</p>
<p>27 MTAP24 多个时间的组合包</p>
<p>28 FU-A 分片的单元</p>
<p>29 FU-B 分片的单元</p>
<p>30-31 没有定义</p>
</blockquote>
<p> </p>
<p><strong>SPS PPS详解</strong>:https://zhuanlan.zhihu.com/p/27896239</p>
<p> <strong> I帧前面必须有SPS和PPS数据,也就是类型为7和8,类型为1表示这是一个P帧或B帧。</strong><br> SPS序列参数集: 包含的是针对一连续编码视频序列的参数,保存了一组编码视频序列(Coded video sequence)的全局参数,如标识符 seq_parameter_set_id、帧数及 POC 的约束、参考帧数目、解码图像尺寸和帧场编码模式选择标识等等。 所谓的编码视频序列即原始视频的一帧一帧的像素数据经过编码之后的结构组成的序列。而每一帧的编码后数据所依赖的参数保存于图像参数集中。https://www.jianshu.com/p/19fa110c2383<br> PPS图像参数集:对应的是一个序列中某一幅图像或者某几幅图像,其参数如标识符 pic_parameter_set_id、可选的 seq_parameter_set_id、熵编码模式选择标识、片组数目、初始量化参数和去方块滤波系数调整标识等等。</p>
<p><a href="http://img.e-com-net.com/image/info8/986c48dbc18e420fab630b26d3240419.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第20张图片" height="767" src="http://img.e-com-net.com/image/info8/986c48dbc18e420fab630b26d3240419.jpg" width="650" style="border:1px solid black;"></a></p>
<p>各种封装格式中的NAlU有一些区别,由于NAL的语法中没有给出长度信息,实际的传输、存储系统需要增加额外的头实现各个NAL单元的定界。 <br> AVI文件和MPEG TS流采取的是字节流的语法格式,即在NAL单元之前增加0x00000001的同步码(即看到0x00000001,便知道到了NALU的开头),则从AVI文件或MPEG TS PES 包中读出的一个H.264视频帧以下面的形式存在: <br> 00 00 00 01 06 ... 00 00 00 01 67 ... 00 00 00 01 68 ... 00 00 00 01 65 ... <br> SEI信息 SPS PPS IDR Slice <br> 而对于MP4文件,NAL单元之前没有同步码,却有若干字节的长度码,来表示NAL单元的长度,这个长度码所占用的字节数由MP4文件头给出;此外,从MP4读出来的视频帧不包含PPS和SPS,这些信息位于MP4的文件头中,解析器必须在打开文件的时候就获取它们。</p>
<blockquote>
<p><span style="color:#f33b45;">NALU的顺序要求</span> :<br> H.264/AVC标准对送到解码器的NAL单元顺序是有严格要求的,如果NAL单元的顺序是混乱的,必须将其重新依照规范组织后送入解码器,否则解码器不能够正确解码。 <br> (1)序列参数集NAL单元(nal_unit_type为7)必须在传送所有以此参数集为参考的其他NAL单元之前传送,不过允许这些NAL单元中间出现重复的序列参数集NAL单元。所谓重复的详细解释为:序列参数集NAL单元都有其专门的标识,如果两个序列参数集NAL单元的标识相同,就可以认为后一个只不过是前一个的拷贝,而非新的序列参数集。 <br> (2)图像参数集NAL单元(nal_unit_type为8)必须在所有以此参数集为参考的其他NAL单元之先,不过允许这些NAL单元中间出现重复的图像参数集NAL单元,这一点与上述的序列参数集NAL单元是相同的。 <br> (3)不同基本编码图像中的片段(slice)单元和数据划分片段(data partition)单元在顺序上不可以相互交叉,即不允许属于某一基本编码图像的一系列片段(slice)单元和数据划分片段(data partition)单元中忽然出现另一个基本编码图像的片段(slice)单元片段和数据划分片段(data partition)单元。 <br> (4)参考图像的影响:如果一幅图像以另一幅图像为参考,则属于前者的所有片段(slice)单元和数据划分片段(data partition)单元必须在属于后者的片段和数据划分片段之后,无论是基本编码图像还是冗余编码图像都必须遵守这个规则 <br> (5)基本编码图像的所有片段(slice)单元和数据划分片段(data partition)单元必须在属于相应冗余编码图像的片段(slice)单元和数据划分片段(data partition)单元之前。 <br> (6)如果数据流中出现了连续的无参考基本编码图像,则图像序号小的在前面。 <br> (7)如 果arbitrary_slice_order_allowed_flag置为1,一个基本编码图像中的片段(slice)单元和数据划分片段(data partition)单元的顺序是任意的,如果arbitrary_slice_order_allowed_flag置为零,则要按照片段中第一个宏块的位置来确定片段的顺序,若使用数据划分,则A类数据划分片段在B类数据划分片段之前,B类数据划分片段在C类数据划分片段之前,而且对应不同片段的数据划分片段不能相互交叉,也不能与没有数据划分的片段相互交叉。 <br> (8)如果存在SEI(补充增强信息) 单元的话,它必须在它所对应的基本编码图像的片段(slice)单元和数据划分片段(data partition)单元之前,并同时必须紧接在上一个基本编码图像的所有片段(slice)单元和数据划分片段(data partition)单元后边。假如SEI属于多个基本编码图像,其顺序仅以第一个基本编码图像为参照。 <br> (9)如果存在图像分割符的话,它必须在所有SEI 单元、基本编码图像的所有片段slice)单元和数据划分片段(data partition)单元之前,并且紧接着上一个基本编码图像那些NAL单元。 <br> (10)如果存在序列结束符,且序列结束符后还有图像,则该图像必须是IDR(即时解码器刷新)图像。序列结束符的位置应当在属于这个IDR图像的分割符、SEI 单元等数据之前,且紧接着前面那些图像的NAL单元。如果序列结束符后没有图像了,那么它的就在比特流中所有图像数据之后。 </p>
</blockquote>
<p> </p>
<p>**********************************编码协议的传输流格式*******************************************************</p>
<ul>
<li>AAC音频文件(传输流)格式有ADIF和ADTS:</li>
<li>ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。</li>
<li>ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。</li>
</ul>
<p> </p>
<p>H264网络传输的startcode是数据的length,不是0x00000001,网络传输都是用的大端序(高地址低字节)。NALU 有两种格式:Annex B 和 AVCC。Annex B 格式startcode以 0x 00 00 01 或 0x 00 00 00 01 开头, AVCC 格式以 NALU 的长度开头。</p>
<p>**************************************************************************************************</p>
<p><strong>DTS、PTS</strong>:https://blog.csdn.net/ai2000ai/article/details/77367481、https://www.cnblogs.com/leisure_chn/p/10584910.html</p>
<p>在视频流中,先到来的 B 帧无法立即解码,需要等待它依赖的后面的 I、P 帧先解码完成,这样一来播放时间与解码时间不一致了,顺序打乱了,那这些帧该如何播放呢?这时就需要我们来了解另外两个概念:DTS 和 PTS。</p>
<ul>
<li>DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。</li>
<li>PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。</li>
</ul>
<p>虽然 DTS、PTS 是用于指导播放端的行为,但它们是在编码的时候由编码器生成的。</p>
<p>当视频流中没有 B 帧时,通常 DTS 和 PTS 的顺序是一致的。但如果有 B 帧时,就回到了我们前面说的问题:解码顺序和播放顺序不一致了。</p>
<p>音频帧的 DTS、PTS 顺序是一致的。</p>
<p>DTS(解码时间戳)和PTS(显示时间戳)分别是解码器进行解码和显示帧时相对于SCR(系统参考)的时间戳。SCR可以理解为解码器应该开始从磁盘读取数据时的时间。mpeg文件中的每一个包都有一个SCR时间戳并且这个时间戳就是读取这个数据包时的系统时间。通常情况下,解码器会在它开始读取mpeg流时启动系统时钟(系统时钟的初始值是第一个数据包的SCR值,通常为0但也可以不从0开始)。</p>
<p> </p>
<p><strong>采集顺序</strong>指图像传感器采集原始信号得到图像帧的顺序。<br><strong>编码顺序</strong>指编码器编码后图像帧的顺序。存储到磁盘的本地视频文件中图像帧的顺序与编码顺序相同。<br><strong>传输顺序</strong>指编码后的流在网络中传输过程中图像帧的顺序。<br><strong>解码顺序</strong>指解码器解码图像帧的顺序。<br><strong>显示顺序</strong>指图像帧在显示器上显示的顺序。<br><strong>采集顺序与显示顺序相同。编码顺序、传输顺序和解码顺序相同。</strong><br> 以图中“B[1]”帧为例进行说明,“B[1]”帧解码时需要参考“I[0]”帧和“P[3]”帧,因此“P[3]”帧必须比“B[1]”帧先解码。这就导致了解码顺序和显示顺序的不一致,后显示的帧需要先解码。</p>
<h2 id="scroller-9"> </h2>
<h3 id="scroller-10"> 时间基与时间戳的概念</h3>
<p>在FFmpeg中,时间基(time_base)是时间戳(timestamp)的单位,<span style="color:#f33b45;">时间戳值乘以时间基,可以得到实际的时刻值(以秒等为单位)</span>。例如,如果一个视频帧的dts是40,pts是160,其time_base是1/1000秒,那么可以计算出此视频帧的解码时刻是40毫秒(40/1000),显示时刻是160毫秒(160/1000)。FFmpeg中时间戳(pts/dts)的类型是int64_t类型,把一个time_base看作一个时钟脉冲,则可把dts/pts看作时钟脉冲的计数。</p>
<h3 id="scroller-12">三种时间基tbr、tbn和tbc</h3>
<p>不同的封装格式具有不同的时间基。在FFmpeg处理音视频过程中的不同阶段,也会采用不同的时间基。<br> FFmepg中有三种时间基,命令行中tbr、tbn和tbc的打印值就是这三种时间基的倒数:<br> tbn:对应<span style="color:#f33b45;">容器</span>中的时间基,也是AVPacket中的时间基。值是AVStream.time_base的倒数。<br> tbc:对应<span style="color:#f33b45;">编解码器</span>中的时间基。值是AVCodecContext.time_base的倒数,<span style="color:#f33b45;">每帧时间戳递增1</span>,解码过程中,此参数已过时,<span style="color:#f33b45;">建议直接使用帧率倒数用作时间基</span>。<br> tbr:从<span style="color:#f33b45;">视频流中猜测</span>得到,可能是帧率或场率(帧率的2倍)</p>
<p>FFmpeg还有一个内部时间基AV_TIME_BASE(以及分数形式的AV_TIME_BASE_Q),AV_TIME_BASE及AV_TIME_BASE_Q用于FFmpeg内部函数处理,使用此时间基计算得到时间值表示的是微秒,如下:</p>
<pre><code>// Internal time base represented as integer
#define AV_TIME_BASE 1000000
// Internal time base represented as fractional value
#define AV_TIME_BASE_Q (AVRational){1, AV_TIME_BASE}</code></pre>
<p> 在封装格式处理例程中,不深入理解时间戳也没有关系。但在编解码处理例程中,时间戳处理是很重要的一个细节,必须要搞清楚。</p>
<p><span style="color:#f33b45;">容器(文件层)中的时间基(AVStream.time_base)与编解码器上下文(视频层)里的时间基(AVCodecContex.time_base)不一样,解码编码过程中需要进行时间基转换</span>。</p>
<p><strong>视频按帧进行播放,所以原始视频帧时间基为 1/framerate。视频解码前需要处理输入 AVPacket 中各时间参数,将输入<span style="color:#f33b45;">容器</span>中的时间基转换为 1/framerate 时间基;视频编码后再处理输出 AVPacket 中各时间参数,将 1/framerate 时间基转换为输出容器中的时间基。(<span style="color:#f33b45;">编解码中的时间基一般为帧率的倒数</span>)</strong></p>
<p><strong>音频按采样点进行播放,所以原始音频帧时间为 1/sample_rate。音频解码前需要处理输入 AVPacket 中各时间参数,将输入容器中的时间基转换为 1/sample_rate 时间基;音频编码后再处理输出 AVPacket 中各时间参数,将 1/sample_rate 时间基转换为输出容器中的时间基。如果引入音频 FIFO,从 FIFO 从读出的音频帧时间戳信息会丢失,需要使用 1/sample_rate 时间基重新为每一个音频帧生成 pts,然后再送入编码器</strong>。</p>
<p><span style="color:#f33b45;">编解码的时间基转换</span>:</p>
<pre><code>解码前的时间基转换:封装格式的时间基转换为编解码的时间基
av_packet_rescale_ts(ipacket, sctx->i_stream->time_base, sctx->o_codec_ctx->time_base);
编码后的时间基转换:编解码的时间基转换为封装格式的时间基
av_packet_rescale_ts(&opacket, sctx->o_codec_ctx->time_base, sctx->o_stream->time_base);
</code></pre>
<p> </p>
<p><span style="color:#f33b45;">转封装的时间基转换</span>:直接从一种封装格式的时间基转换到另一种封装格式的时间基;<span style="color:#f33b45;">不需要流的时间基和编码的时间基转换</span>。</p>
<pre><code>不同封装格式具有不同的时间基,在转封装(将一种封装格式转换为另一种封装格式)过程中,时间基转换如下:
这里是分别转换pts、dts、duration;
av_read_frame(ifmt_ctx, &pkt);
pkt.pts = av_rescale_q_rnd(pkt.pts, in_stream->time_base, out_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
pkt.dts = av_rescale_q_rnd(pkt.dts, in_stream->time_base, out_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
pkt.duration = av_rescale_q(pkt.duration, in_stream->time_base, out_stream->time_base);
下面的代码具有和上面代码相同的效果:
这里是一次性吧所有时间基转换;
// 从输入文件中读取packet
av_read_frame(ifmt_ctx, &pkt);
// 将packet中的各时间值从输入流封装格式时间基转换到输出流封装格式时间基
av_packet_rescale_ts(&pkt, in_stream->time_base, out_stream->time_base);
这里流里的时间基in_stream->time_base和out_stream->time_base,是容器中的时间基</code></pre>
<p>************************************************************************************************************************************************</p>
<p><span style="color:#f33b45;"><strong>视频像素数据</strong></span>:https://blog.csdn.net/mydear_11000/article/details/50404084、https://www.cnblogs.com/blogs-of-lxl/p/10839053.html、https://blog.csdn.net/weixin_42229404/article/details/81937646</p>
<p>保存了屏幕上每个点的像素值;视频像素体积很大;一个小时RGB24的视频体积计算:<span style="color:#f33b45;">3600*25(帧率)*1920*1080*3(取样精度为8bit,每个像素点占3字节的数据)=559.9GB</span>;</p>
<p>常见的视频像素数据类型(颜色编码方法)有RGB24、RGB32、YUV420P、YUV422P、YUV444P;最常用的是YUV420P;</p>
<p>Cr反映了RGB输入信号红色部分与RGB信号亮度值之间的差异,而Cb反映的是RGB输入信号蓝色部分与RGB信号亮度值之间的差异,此即所谓的色差信号,一般所讲的YUV大多是指YCbCr。</p>
<p>从摄像头采集到的数据一般都是YUV或者RGB格式(这个由摄像头决定),不管是YUV还是RGB,他们都是原始的图像数据,是没有经过压缩的。</p>
<p><strong>数字媒体采样</strong>: 其实就是对媒体内容进行数字化,主要有两种方式:①时间采样,用来捕捉一个信号在一个周期内的变化.如录音时的音高和声调变化. ②空间采样: 一般用在可视化内容的数字化过程中,对一幅图片在一定分辨率下捕捉其亮度和色度。</p>
<p><strong>音频采样</strong>:用麦克风把声波机械能量转换成电信号, 再通过一个编码方法(LPCM)进行数字化. 此过程中 采样或测量一个音频信号过程的周期率 被称为采样率, 采样率越高信号越完整清晰。</p>
<p><strong>视频采样</strong>: 视频其实就由一系列"帧"图片组成,时间轴线上每一帧都表示一个场景. 要显示出连续的动画,其实就是在短时间间隔内提供特定数量的帧. 1s内所连续展现的帧数就称为帧率。</p>
<blockquote>
<p>视频内容的存储: 我们先确定每个独立帧图片的大小,以1280x720分辨率为例,一帧像素数量约等于一百万个像素点,通常称1M . 如果对每个像素点使用8位的RGB三原色存储,一个像素就需要24位存储空间. 一帧就需要2.6MB的存储空间. 而一个帧率30FBS的一秒视频就需要79MB存储. 显然,这不合实际. 所以需要专门对其的存储和传输格式做压缩处理 .</p>
</blockquote>
<p><strong>色彩二次抽样</strong>: 实际上视频数据一般不以RGB而是以YUV颜色模式存在的. YUV使用色彩通道替换了RBG像素的亮度通道. 这样可以大幅减少存储在每个像素中的颜色信息,而不至于让图片质量严重受损.这个过程就叫色彩二次抽样.</p>
<p><a href="http://img.e-com-net.com/image/info8/9610c9d746314485aacea24637970e3b.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第21张图片" height="537" src="http://img.e-com-net.com/image/info8/9610c9d746314485aacea24637970e3b.jpg" width="650" style="border:1px solid black;"></a></p>
<p><span style="color:#f33b45;">YUV相比于RGB格式最大的好处是可以做到在保持图像质量降低不明显的前提下,减小文件大小。YUV格式之所以能够做到,是因为进行了采样操作</span>。</p>
<p>YUV,分为三个分量,“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。YUV是一种颜色编码方法,主要用于电视系统以及模拟视频领域,它将亮度信息(Y)与色彩信息(UV)分离,没有UV信息一样可以显示完整的图像,只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。并且,YUV不像RGB那样要求三个独立的视频信号同时传输,所以用YUV方式传送占用极少的频宽。</p>
<p>YUV几种采样格式:https://www.cnblogs.com/cumtchw/p/10224329.html</p>
<p>一个宏块由一个16×16亮度像素和附加的<span style="color:#f33b45;">一个8×8 Cb</span>和<span style="color:#f33b45;">一个8×8 Cr</span>彩色像素块组成。</p>
<p><strong>YUV数据的几种采样格式如下</strong>:</p>
<p>4:4:4 这个不用解释了,这是每个像素占三个字节的内存.</p>
<p>4:2:2 Y0U0V0 Y1U1V1 Y2U2V2 Y3U3V3对于这四个像素,采样之后存放的码流为:Y0U0 Y1V1 Y2U2 Y3V3,占用的内存大小为4+4/2 +4/2=8</p>
<p>4:2:0并不意味着只有Y和U而没有V,他指的是对于每行扫描线来说,只有一种色度分量以2:1的抽样率存储,相邻的扫描行存储不同的色度分量,也就是说,如果一行是4:2:0的话,下一行就是4:0:2, 对于[Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3] [Y4 U4 V4] [Y5 U5 V5] [Y6 U6 V6] [Y7U7 V7] 。采样之后存放的码流为Y0 U0 Y1 Y2 U2 Y3 Y4 V4 Y5 Y6 V6 Y7. 占用的内存是width*height*3/2.</p>
<p>YUV的优点之一是色度通道可以具有比Y通道更低的采样率而不会显着降低感知质量。称为A:B:C符号的符号用于描述U和V相对于Y的采样频率:</p>
<blockquote>
<ul>
<li>4:4:4 表示没有对色度通道进行缩减采样。</li>
<li>4:2:2 意味着2:1的水平缩减采样,没有垂直下采样。每扫描一行,每两个U或V采样包含四个Y采样。</li>
<li>4:2:0 表示2:1水平缩减采样,2:1垂直缩减采样。</li>
<li>4:1:1 表示4:1水平缩减采样,没有垂直下采样。每个扫描线对于每个U或V采样包含四个Y采样。4:1:1采样比其他格式少见。</li>
</ul>
</blockquote>
<p> <strong> YUV 4:4:4采样,每一个Y对应一组UV分量。数据大小:Y*1+Y*1+Y*1<br> YUV 4:2:2采样,每两个Y共用一组UV分量。数据大小: Y*1+Y*1/2+Y*1/2<br> YUV 4:2:0采样,每四个Y共用一组UV分量。数据大小:Y*1+Y*1/4+Y*1/4</strong></p>
<p><a href="http://img.e-com-net.com/image/info8/eb8283960a304b8382243899fae7ce05.jpg" target="_blank"><img alt="FFmpeg之视频封装格式、流媒体协议、视频编解码协议和传输流格式、时间戳和时间基、视频像素数据_第22张图片" height="126" src="http://img.e-com-net.com/image/info8/eb8283960a304b8382243899fae7ce05.jpg" width="650" style="border:1px solid black;"></a></p>
<p> <a href="http://img.e-com-net.com/image/info8/35f31bd3d1ae4fb6a8a7c482ed979ac8.jpg" target="_blank"><img alt="" height="88" src="http://img.e-com-net.com/image/info8/35f31bd3d1ae4fb6a8a7c482ed979ac8.jpg" width="650"></a></p>
<p> </p>
<p> YUV格式有两大类:<strong>packed</strong>和<strong>planar</strong>。注:planar还分平面存储和平面打包格式。</p>
<p>packed模式的YUV格式,每个像素点的Y,U,V是连续交错存储的。<span style="color:#f33b45;">三个分量存在一个Byte型数组里;</span></p>
<p>Plane模式,即平面模式,并不是将YUV数据交错存储,而是先存放所有的Y分量,然后存储所有的<span style="color:#f33b45;">U(Cb)</span>分量,最后存储所有的<span style="color:#f33b45;">V(Cr)</span>分量,这个是<span style="color:#f33b45;">平面存储格式</span>。相邻的两个Y共用其相邻的两个Cb、Cr。先存放所有的Y分量,然后紧接着UV交错存储叫<span style="color:#f33b45;">平面打包格式</span>。<span style="color:#f33b45;">Y、U、V分量分别存在三个Byte型数组中</span>。</p>
<p>YUV像素格式来源于RGB像素格式,通过公式运算,YUV三分量可以还原出RGB,YUV转RGB的公式如下:</p>
<pre><code>R = Y + 1.403V
G = Y - 0.344U - 0.714V
B = Y + 1.770U
</code></pre>
<p>一般,将RGB和YUV的范围均限制在[0, 255]间,则有如下转换公式:</p>
<pre><code>R = Y + 1.403(V - 128)
G = Y - 0.344(U - 128) - 0.714(V - 128)
B = Y + 1.770(U - 128)
</code></pre>
<p>保存YUV420P格式的数据,用以下代码:output是文件名(xx.rgb或者xx.yuv),保存最终存储YUV或者RGB的数据;</p>
<pre><code>
fwrite(pFrameYUV->data[0],(pCodecCtx->width)*(pCodecCtx->height),1,output);
fwrite(pFrameYUV->data[1],(pCodecCtx->width)*(pCodecCtx->height)/4,1,output);
fwrite(pFrameYUV->data[2],(pCodecCtx->width)*(pCodecCtx->height)/4,1,output);</code></pre>
<p> </p>
<p>保存RGB24格式的数据,用以下代码:</p>
<pre><code>fwrite(pFrameYUV->data[0],(pCodecCtx->width)*(pCodecCtx->height)*3,1,output);</code></pre>
<p>保存UYVY格式的数据,用以下代码:</p>
<pre><code>fwrite(pFrameYUV->data[0],(pCodecCtx->width)*(pCodecCtx->height),2,output);</code></pre>
<p>YUV420P格式需要写入data[0],data[1],data[2];而RGB24,UYVY格式却仅仅是写入data[0],他们的区别到底是什么呢?经过研究发现,在FFMPEG中,图像原始数据包括两种:planar和packed。planar就是将几个分量分开存,比如YUV420中,data[0]专门存Y,data[1]专门存U,data[2]专门存V。而packed则是打包存,所有数据都存在data[0]中。具体哪个格式是planar,哪个格式是packed,可以查看pixfmt.h文件。注:有些格式名称后面是LE或BE,分别对应little-endian或big-endian。另外<span style="color:#f33b45;">名字后面有P的是planar格式</span>。</p>
<p>************************************************************************************************************************************************</p>
<p><span style="color:#f33b45;"><strong>音频编解码协议:</strong></span></p>
<p><strong>mp3</strong>:</p>
<p><strong>aac</strong>:</p>
<p><strong>ac-3</strong>:</p>
<p> </p>
<p> </p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1609018732502351872"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(iOS/oc,音视频,ffmpeg)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1892510328776880128.htm"
title="docker部署kafka(单节点) + Springboot集成kafka" target="_blank">docker部署kafka(单节点) + Springboot集成kafka</a>
<span class="text-muted">wsdhla</span>
<a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/kafka/1.htm">kafka</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a>
<div>环境:操作系统:win10Docker:DockerDesktop4.21.1(114176)、DockerEnginev24.0.2SpringBoot:2.7.15步骤1:创建网络:dockernetworkcreate--subnet=172.18.0.0/16net-kafka步骤2:安装zk镜像dockerpullzookeeper:latestdockerrun-d--restarta</div>
</li>
<li><a href="/article/1892510091140198400.htm"
title="mysql实时同步到es" target="_blank">mysql实时同步到es</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>测试了多个方案同步,最终选择oceanu产品,底层基于Flinkcdc1、实时性能够保证,binlog量很大时也不产生延迟2、配置SQL即可完成,操作上简单下面示例mysql的100张分表实时同步到es,优化备注等文本字段的like查询创建SQL作业CREATETABLEfrom_mysql(idint,cidintNOTNULL,gidbigintNOTNULL,contentvarchar,c</div>
</li>
<li><a href="/article/1892509329303597056.htm"
title="YashanDB数据分区" target="_blank">YashanDB数据分区</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>本文内容来自YashanDB官网,原文内容请见https://doc.yashandb.com/yashandb/23.3/zh/%E6%A6%82%E5%BF%B5%...#分区概述YashanDB可以将大规模数据拆分成更小、更便于管理的对象,即分区。通过对数据进行分区管理,可以减少无效数据的访问,提升大规模数据下的访问、操作性能。表可以根据某些条件进行分区,不同分区独立管理。分区表提供了更高效</div>
</li>
<li><a href="/article/1892508687893852160.htm"
title="Nginx配置反向代理不成功的原因(Docker安装版)" target="_blank">Nginx配置反向代理不成功的原因(Docker安装版)</a>
<span class="text-muted">程序员迪迦</span>
<a class="tag" taget="_blank" href="/search/%E9%A1%B9%E7%9B%AE%E5%AE%9E%E6%88%98/1.htm">项目实战</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>问题背景在linux服务器中使用docker下载了Nginx,然后根据网上的教程来配置反向代理的时候发现80端口无法访问server块的配置server{listen80;server_name127.0.0.1;#access_log/var/log/nginx/host.access.logmain;location/{proxy_passhttp://127.0.0.1:8080;#inde</div>
</li>
<li><a href="/article/1892508570369454080.htm"
title="cocos creator从零开发简单框架(12)-代码生成单色Sprite" target="_blank">cocos creator从零开发简单框架(12)-代码生成单色Sprite</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/cocos/1.htm">cocos</a>
<div>在写Panel前,先写个方法生成单色Sprite,这样当碰到需要单色Sprite的时候不需要在编辑器拖拽和代码动态加载资源。编辑framework/scripts/AppUtil.ts,添加newSpriteNode方法。//生成默认白色100x100大小Sprite(单色)节点publicstaticnewSpriteNode(name:string='newSpriteNode'):cc.No</div>
</li>
<li><a href="/article/1892508571845849088.htm"
title="cocos creator从零开发简单框架(14)-Panel遮罩" target="_blank">cocos creator从零开发简单框架(14)-Panel遮罩</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/cocos/1.htm">cocos</a>
<div>遮罩相关属性编辑framework/scripts/view/PanelMgr.ts,增加遮罩相关成员变量及初始化方法。//所有面板privatestatic_panels:Map=newMap()privatestatic_maskName='_mask'privatestatic_maskPrefab:cc.Nodepublicstaticinit(){this._panels.clear()</div>
</li>
<li><a href="/article/1892507686784790528.htm"
title="cocos creator从零开发2048(06)-格子移动逻辑和键盘控制移动" target="_blank">cocos creator从零开发2048(06)-格子移动逻辑和键盘控制移动</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/cocos/1.htm">cocos</a>
<div>编辑scripts/Game.ts,添加_moving属性标识当前是否移动中。privategridsReversed:Grid[][]=[]private_moving=false添加move方法移动格子。privatemove(grids:Grid[]){letlastIdx=grids.length-1letlastNum=grids[lastIdx].numfor(leti=grids.l</div>
</li>
<li><a href="/article/1892502890174541824.htm"
title="Jupyter使用Nginx做反向代理" target="_blank">Jupyter使用Nginx做反向代理</a>
<span class="text-muted">syuszu</span>
<a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a>
<div>1.在/nginx/conf/nginx.conf上进行修改因为jupyter对于header有过滤,需要将header复制,实例如下:server{server_name127.0.0.1;#入口地址listen80;location/{proxy_passhttp://127.0.0.1:8888;#jupyter服务器地址proxy_set_headerHost$host;proxy_set</div>
</li>
<li><a href="/article/1892502881513304064.htm"
title="nginx反向代理导致jupyter 或jupyterlab 无法输出" target="_blank">nginx反向代理导致jupyter 或jupyterlab 无法输出</a>
<span class="text-muted">NEOzhuo</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/jupyter/1.htm">jupyter</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a>
<div>代码运行能力依赖于websocket,因此需要设置nginx的反向代理server{server_nameDOMAINIP_ADDRESS;#服务器域名和IP地址listen80;location/{proxy_passhttp://127.0.0.1:JUPYTER_PORT/;#JUPYTER_PORT为Jupyter运行端口proxy_set_headerX-Real-IP$remote_a</div>
</li>
<li><a href="/article/1892498963177730048.htm"
title="ArcGIS Runtime SDK for iOS 开发之地图范围(map extent)" target="_blank">ArcGIS Runtime SDK for iOS 开发之地图范围(map extent)</a>
<span class="text-muted">hlj184</span>
<a class="tag" taget="_blank" href="/search/ArcGIS/1.htm">ArcGIS</a><a class="tag" taget="_blank" href="/search/for/1.htm">for</a><a class="tag" taget="_blank" href="/search/IOS/1.htm">IOS</a><a class="tag" taget="_blank" href="/search/arcgis/1.htm">arcgis</a><a class="tag" taget="_blank" href="/search/ios%E5%BC%80%E5%8F%91/1.htm">ios开发</a><a class="tag" taget="_blank" href="/search/map/1.htm">map</a><a class="tag" taget="_blank" href="/search/extent/1.htm">extent</a>
<div>注:本篇文章翻译自:https://developers.arcgis.com/ios/objective-c/guide/iphonesdk-mapnavigation.htm;地图视图包含了地图范围被定义和改变的选项。值得注意的是,底图(加载到地图中的第一层图层)定义了下列地图属性:初始化范围全部范围空间参考系其中,初始范围可以被改变,而空间参考不可以改变。本篇文章主要讨论针对开发者和最终用户</div>
</li>
<li><a href="/article/1892494551290015744.htm"
title="UDP通信开发" target="_blank">UDP通信开发</a>
<span class="text-muted">Charary</span>
<a class="tag" taget="_blank" href="/search/udp/1.htm">udp</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a>
<div>开发流程:UDP本身不考虑链接,不存在客户和服务器的概念,UDP开发只有三步:创建UDP的套接字socket(AF_INET,SOCK_DGRAM,0)绑定自己的属性bindUDP随意的发送和接收数据sendto/recvfromUDP接口函数:sendto()函数功能:UDP专用的发送函数函数原型:ssize_tsendto(intsockfd,//套接字constvoid*buf,//待发送的</div>
</li>
<li><a href="/article/1892492282075082752.htm"
title="Linux常用的命令一" target="_blank">Linux常用的命令一</a>
<span class="text-muted">Agome99</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a>
<div>目录1.常用命令1.常用命令1)#与$提示的区别'#'表示用户有root权限,一般的以root用户登录提示符为#,'$'提示符表示用户为普通用户2)ifconfig查看ip地址eno1:代表由主板bios内置的网卡ens1:代表主板bios内置的PCI_E网卡enp2s0:PCI-E独立网卡eth0:如果以上都不用,则返回默认的网卡名ens33则属于第二种类型,即说明你的网卡是内置的PCI-E网卡</div>
</li>
<li><a href="/article/1892489889514057728.htm"
title="嵌入式音视频开发(二)ffmpeg音视频同步" target="_blank">嵌入式音视频开发(二)ffmpeg音视频同步</a>
<span class="text-muted">云雨歇</span>
<a class="tag" taget="_blank" href="/search/%E9%9F%B3%E8%A7%86%E9%A2%91/1.htm">音视频</a><a class="tag" taget="_blank" href="/search/ffmpeg/1.htm">ffmpeg</a>
<div>系列文章目录嵌入式音视频开发(零)移植ffmpeg及推流测试嵌入式音视频开发(一)ffmpeg框架及内核解析嵌入式音视频开发(二)ffmpeg音视频同步嵌入式音视频开发(三)直播协议及编码器文章目录系列文章目录前言一、音视频同步1.1基础概念1.2三种同步方法二、音视频同步的实现2.1时间基的转换问题2.2音频为基准2.2.1实现思路2.2.2代码大纲2.3外部时钟同步2.3.1实现思路2.3.2</div>
</li>
<li><a href="/article/1892489257264672768.htm"
title="nginx反向代理jupyter" target="_blank">nginx反向代理jupyter</a>
<span class="text-muted">jerry-89</span>
<a class="tag" taget="_blank" href="/search/jupyterlab/1.htm">jupyterlab</a><a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/jupyter/1.htm">jupyter</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>1.jupyter配置打开配置文件/home/jack/.jupyter/jupyter_notebook_config.py2.反向代理配置这个/jack/与上面添加的对应location/jack/{proxy_passhttp://192.168.196.164:8888/jack/;proxy_set_headerHost$host;proxy_set_headerX-Real-IP$re</div>
</li>
<li><a href="/article/1892486356869902336.htm"
title="在瑞芯微RK3588平台上使用RKNN部署YOLOv8Pose模型的C++实战指南" target="_blank">在瑞芯微RK3588平台上使用RKNN部署YOLOv8Pose模型的C++实战指南</a>
<span class="text-muted">机 _ 长</span>
<a class="tag" taget="_blank" href="/search/YOLO%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E6%9C%89%E6%95%88%E6%B6%A8%E7%82%B9%E6%94%B9%E8%BF%9B/1.htm">YOLO系列模型有效涨点改进</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E8%90%BD%E5%9C%B0%E5%AE%9E%E6%88%98/1.htm">深度学习落地实战</a><a class="tag" taget="_blank" href="/search/YOLO/1.htm">YOLO</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>在人工智能和计算机视觉领域,人体姿态估计是一项极具挑战性的任务,它对于理解人类行为、增强人机交互等方面具有重要意义。YOLOv8Pose作为YOLO系列中的新成员,以其高效和准确性在人体姿态估计任务中脱颖而出。本文将详细介绍如何在瑞芯微RK3588平台上,使用RKNN(RockchipNeuralNetworkToolkit)框架部署YOLOv8Pose模型,并进行C++代码的编译和运行。注本文全</div>
</li>
<li><a href="/article/1892485474463838208.htm"
title="深度学习之目标检测的常用标注工具" target="_blank">深度学习之目标检测的常用标注工具</a>
<span class="text-muted">铭瑾熙</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B/1.htm">目标检测</a><a class="tag" taget="_blank" href="/search/%E7%9B%AE%E6%A0%87%E8%B7%9F%E8%B8%AA/1.htm">目标跟踪</a>
<div>1LabelImgLabelImg是一款开源的图像标注工具,标签可用于分类和目标检测,它是用Python编写的,并使用Qt作为其图形界面,简单好用。注释以PASCALVOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持COCO数据集格式。2labelmelabelme是一款开源的图像/视频标注工具,标签可用于目标检测、分割和分类。灵感是来自于MIT开源的一款标注工具Label</div>
</li>
<li><a href="/article/1892482448659378176.htm"
title="【vue】Mammoth.js的使用:将.docx转换成HTML" target="_blank">【vue】Mammoth.js的使用:将.docx转换成HTML</a>
<span class="text-muted">暴富暴富暴富啦啦啦</span>
<a class="tag" taget="_blank" href="/search/1024%E7%A8%8B%E5%BA%8F%E5%91%98%E8%8A%82/1.htm">1024程序员节</a>
<div>mammoth.convertToHtml(input,options):把源文档转换为HTML文档mammoth.convertToMarkdown(input,options):把源文档转换为Markdown文档。mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。npminstallelement-uimammot</div>
</li>
<li><a href="/article/1892480683775946752.htm"
title="YOLOv8 Pose使用RKNN进行推理" target="_blank">YOLOv8 Pose使用RKNN进行推理</a>
<span class="text-muted">い不靠譜︶朱Sir</span>
<a class="tag" taget="_blank" href="/search/%E5%AE%9E%E7%94%A8%E9%A1%B9%E7%9B%AE%E9%83%A8%E7%BD%B2/1.htm">实用项目部署</a><a class="tag" taget="_blank" href="/search/YOLO/1.htm">YOLO</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/pip/1.htm">pip</a>
<div>关注微信公众号:朱sir的小站,发送202411081即可免费获取源代码下载链接一、简单介绍YOLOv8-Pose是一种基于YOLOv8架构的姿态估计模型,能够识别图像中的关键点位置,这些关键点通常表示人体的关节、特征点或其他显著位置。该模型在COCO关键点数据集上训练,适合多种姿势估计任务。二、ONNX推理1.首先需要先将Pytorch模型转换为Onnx模型,下载pt模型这里给出官方的权重下载地</div>
</li>
<li><a href="/article/1892473871148314624.htm"
title="单细胞轨迹分析-monocle包的使用" target="_blank">单细胞轨迹分析-monocle包的使用</a>
<span class="text-muted">探序基因</span>
<a class="tag" taget="_blank" href="/search/r%E8%AF%AD%E8%A8%80/1.htm">r语言</a>
<div>探序基因肿瘤研究院整理安装:monocle源码下载:https://www.bioconductor.org/packages/release/bioc/html/monocle.htmlR版本,4.2.0BiocManager::install("monocle")不过在安装过程中还是报错了:Warning:无法在https://bioconductor.org/packages/3.15/bi</div>
</li>
<li><a href="/article/1892473492138422272.htm"
title="TCP 握手数据包分析" target="_blank">TCP 握手数据包分析</a>
<span class="text-muted">inquisiter</span>
<a class="tag" taget="_blank" href="/search/tcp%2Fip/1.htm">tcp/ip</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>一、客户端数据分析:spu@spu:~/code/pcap$tcpdump-rclient_all.pcap-Xreadingfromfileclient_all.pcap,link-typeEN10MB(Ethernet)17:58:56.346748IP192.168.1.178.55814>192.168.1.117.socks:Flags[S],seq2615205588,win64240</div>
</li>
<li><a href="/article/1892471976795107328.htm"
title="前端导出word文件—包含canvas(echarts图表)" target="_blank">前端导出word文件—包含canvas(echarts图表)</a>
<span class="text-muted">Liuer_Qin</span>
<a class="tag" taget="_blank" href="/search/js/1.htm">js</a><a class="tag" taget="_blank" href="/search/canvas/1.htm">canvas</a><a class="tag" taget="_blank" href="/search/echarts/1.htm">echarts</a><a class="tag" taget="_blank" href="/search/echarts/1.htm">echarts</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a>
<div>一、使用的插件html-docx-js二、整体思路因为canvas是运行在内存中的,所以不能简单的通过dom获取canvas图片,需要手动的先将canvas转为image。三、实现先克隆要下载的DOM的副本。因为canvas是运行在内存中的,所以也不能通过cloneNode方法克隆下来(克隆下来是空的)。我们这里将原DOM中的canvas转成图片,然后插入到副本的对应位置,这样操作不会影响原DOM</div>
</li>
<li><a href="/article/1892470464907898880.htm"
title="语聊房软件开发流程与基础功能" target="_blank">语聊房软件开发流程与基础功能</a>
<span class="text-muted">ALLSectorSorft</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a>
<div>开发一款语聊房软件需要系统的规划和多领域技术整合。以下是关键流程、基础功能及示例代码:---一、开发流程1.需求分析-明确目标用户(社交/游戏/教育)-竞品分析(Clubhouse/Discord/狼人杀)-核心功能优先级排序2.技术选型-实时语音:声网Agora(推荐)/腾讯云TRTC/WebRTC-即时通讯:Socket.io/Sendbird/Firebase-后端框架:Node.js/Sp</div>
</li>
<li><a href="/article/1892468194430480384.htm"
title="使用rknn进行yolo11-pose部署" target="_blank">使用rknn进行yolo11-pose部署</a>
<span class="text-muted">点PY</span>
<a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E9%83%A8%E7%BD%B2/1.htm">深度学习模型部署</a><a class="tag" taget="_blank" href="/search/pytorch/1.htm">pytorch</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>文章目录概要生成ONNX生成RKNN实测效果概要使用RKNN进行YOLOv11Pose部署的必要性在于,RKNN能将YOLOv11Pose模型转化为适合Rockchip硬件平台(如RV1109、RV1126)执行的格式,充分利用其AI加速功能,显著提高推理速度和效率。此外,RKNN提供模型优化(如量化)功能,有助于减少计算资源消耗,提升实时处理能力,特别适合在嵌入式设备上进行高效、低功耗的姿态估计</div>
</li>
<li><a href="/article/1892464284550623232.htm"
title="如何将Docker容器打包并在其他服务器上运行" target="_blank">如何将Docker容器打包并在其他服务器上运行</a>
<span class="text-muted">IT小辉同学</span>
<a class="tag" taget="_blank" href="/search/%E6%8A%80%E5%B7%A7%E6%80%A7%E5%B7%A5%E5%85%B7%E6%A0%8F/1.htm">技巧性工具栏</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%91%E9%83%A8%E7%BD%B2/1.htm">分布式云部署</a><a class="tag" taget="_blank" href="/search/%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E/1.htm">搜索引擎</a><a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E5%AE%B9%E5%99%A8/1.htm">容器</a>
<div>如何将Docker容器打包并在其他服务器上运行我会幻想很多次我们的相遇,你穿着合身的T恤,一个素色的外套,搭配一条蓝色的牛仔裤,干净的像那天空中的云朵,而我,还是一个的傻傻的少年,我们相识而笑,默默不语,如此甚好!Docker容器使得应用程序的部署和管理变得更加简单和高效。有时,我们可能需要将一个运行中的Docker容器打包,并在其他服务器上运行。本文将详细介绍如何实现这一过程。1.提交容器为镜像</div>
</li>
<li><a href="/article/1892459737694400512.htm"
title="ROS turtlesim 无法通过 键盘控制 turtle 移动" target="_blank">ROS turtlesim 无法通过 键盘控制 turtle 移动</a>
<span class="text-muted">狗头鹰</span>
<a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>原因:当我们在singlemachine上进行试验时,如果出现了上述问题,除了指令输入错误、本地没该功能包,未选中turtle_teleop_key终端进行操作等简单原因外,还有可能是未正确设置环境变量ROS_MASTER_URI,ROS_HOSTNAMEsolutions:vim~/.basrhc打开文件.bashrc,在文件末尾加上exportROS_HOSTNAME=ubuntu.local</div>
</li>
<li><a href="/article/1892458724304416768.htm"
title="Python-tkinter自制登录界面(含注册)" target="_blank">Python-tkinter自制登录界面(含注册)</a>
<span class="text-muted">GCHEK</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>简单的用户登录、注册界面importtkinterastkimporttimeimportsubprocessimportsysimportosimporttkinter.messageboxwindow=tk.Tk()window.title('GCHEK')window.geometry('400x300')#设置储存用户信息的容器,这里用的txt。ifnotos.path.exists('U</div>
</li>
<li><a href="/article/1892458219784171520.htm"
title="【干货】视频文件抽帧(opencv和ffmpeg方式对比)" target="_blank">【干货】视频文件抽帧(opencv和ffmpeg方式对比)</a>
<span class="text-muted">zkFun</span>
<a class="tag" taget="_blank" href="/search/%E8%B6%85%E7%A1%AC%E5%B9%B2%E8%B4%A7/1.htm">超硬干货</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/opencv/1.htm">opencv</a><a class="tag" taget="_blank" href="/search/ffmpeg/1.htm">ffmpeg</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>1废话不多说,直接上代码opencv方式importtimeimportsubprocessimportcv2,osfrommathimportceildefextract_frames_opencv(video_path,output_folder,frame_rate=1):"""使用OpenCV从视频中抽取每秒指定帧数的帧,并保存到指定文件夹。如果视频长度不是整数秒,则会在最后一帧时补充空白</div>
</li>
<li><a href="/article/1892456833910632448.htm"
title="Docker Compose部署大语言模型LLaMa3+可视化UI界面Open WebUI" target="_blank">Docker Compose部署大语言模型LLaMa3+可视化UI界面Open WebUI</a>
<span class="text-muted">m0_74824877</span>
<a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a><a class="tag" taget="_blank" href="/search/ui/1.htm">ui</a>
<div>一、介绍Ollama:部署+运行大语言模型的软件LLaMa3:史上最强开源AI大模型—Meta公司新发布的大语言模型OpenWebUI:AI用户界面,可通过浏览器访问二、Docker部署docker-compose.yml文件如下:version:'3'services:ollama:container_name:bruce-ollamaimage:ollama/ollamavolumes:-./</div>
</li>
<li><a href="/article/1892453179853959168.htm"
title="微信支付-扫码支付全流程" target="_blank">微信支付-扫码支付全流程</a>
<span class="text-muted">自娱自乐22</span>
<a class="tag" taget="_blank" href="/search/thinkphp/1.htm">thinkphp</a><a class="tag" taget="_blank" href="/search/php/1.htm">php</a><a class="tag" taget="_blank" href="/search/%E5%BE%AE%E4%BF%A1%E6%89%AB%E7%A0%81%E6%94%AF%E4%BB%98/1.htm">微信扫码支付</a>
<div>微信支付官方文档:`https://pay.weixin.qq.com/wiki/doc/api/index.html`微信支付分为2种模式:【模式一】:商户后台系统根据微信支付规则链接生成二维码,链接中带固定参数productid(可定义为产品标识或订单号)。用户扫码后,微信支付系统将productid和用户唯一标识(openid)回调商户后台系统(需要设置支付回调URL),商户后台系统根据pr</div>
</li>
<li><a href="/article/1892453053508939776.htm"
title="mac+php5.3的docker-compose.yml分享" target="_blank">mac+php5.3的docker-compose.yml分享</a>
<span class="text-muted">自娱自乐22</span>
<a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a>
<div>version:'3'services:nginx:image:nginx:latestcontainer_name:nginx-composevolumes:-./wwwroot:/usr/share/nginx/html:rw-./nginx/nginx/:/etc/nginx/:rw-./log/nginx:/var/log/nginx:rwrestart:alwayslinks:-phpp</div>
</li>
<li><a href="/article/107.htm"
title="web报表工具FineReport常见的数据集报错错误代码和解释" target="_blank">web报表工具FineReport常见的数据集报错错误代码和解释</a>
<span class="text-muted">老A不折腾</span>
<a class="tag" taget="_blank" href="/search/web%E6%8A%A5%E8%A1%A8/1.htm">web报表</a><a class="tag" taget="_blank" href="/search/finereport/1.htm">finereport</a><a class="tag" taget="_blank" href="/search/%E4%BB%A3%E7%A0%81/1.htm">代码</a><a class="tag" taget="_blank" href="/search/%E5%8F%AF%E8%A7%86%E5%8C%96%E5%B7%A5%E5%85%B7/1.htm">可视化工具</a>
<div>在使用finereport制作报表,若预览发生错误,很多朋友便手忙脚乱不知所措了,其实没什么,只要看懂报错代码和含义,可以很快的排除错误,这里我就分享一下finereport的数据集报错错误代码和解释,如果有说的不准确的地方,也请各位小伙伴纠正一下。
NS-war-remote=错误代码\:1117 压缩部署不支持远程设计
NS_LayerReport_MultiDs=错误代码</div>
</li>
<li><a href="/article/234.htm"
title="Java的WeakReference与WeakHashMap" target="_blank">Java的WeakReference与WeakHashMap</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%B1%E5%BC%95%E7%94%A8/1.htm">弱引用</a>
<div>首先看看 WeakReference
wiki 上 Weak reference 的一个例子:
public class ReferenceTest {
public static void main(String[] args) throws InterruptedException {
WeakReference r = new Wea</div>
</li>
<li><a href="/article/361.htm"
title="Linux——(hostname)主机名与ip的映射" target="_blank">Linux——(hostname)主机名与ip的映射</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/hostname/1.htm">hostname</a>
<div>一、 什么是主机名
无论在局域网还是INTERNET上,每台主机都有一个IP地址,是为了区分此台主机和彼台主机,也就是说IP地址就是主机的门牌号。但IP地址不方便记忆,所以又有了域名。域名只是在公网(INtERNET)中存在,每个域名都对应一个IP地址,但一个IP地址可有对应多个域名。域名类型 linuxsir.org 这样的;
主机名是用于什么的呢?
答:在一个局域网中,每台机器都有一个主</div>
</li>
<li><a href="/article/488.htm"
title="oracle 常用技巧" target="_blank">oracle 常用技巧</a>
<span class="text-muted">18289753290</span>
<div>oracle常用技巧 ①复制表结构和数据 create table temp_clientloginUser as select distinct userid from tbusrtloginlog ②仅复制数据 如果表结构一样 insert into mytable select * &nb</div>
</li>
<li><a href="/article/615.htm"
title="使用c3p0数据库连接池时出现com.mchange.v2.resourcepool.TimeoutException" target="_blank">使用c3p0数据库连接池时出现com.mchange.v2.resourcepool.TimeoutException</a>
<span class="text-muted">酷的飞上天空</span>
<a class="tag" taget="_blank" href="/search/exception/1.htm">exception</a>
<div>有一个线上环境使用的是c3p0数据库,为外部提供接口服务。最近访问压力增大后台tomcat的日志里面频繁出现
com.mchange.v2.resourcepool.TimeoutException: A client timed out while waiting to acquire a resource from com.mchange.v2.resourcepool.BasicResou</div>
</li>
<li><a href="/article/742.htm"
title="IT系统分析师如何学习大数据" target="_blank">IT系统分析师如何学习大数据</a>
<span class="text-muted">蓝儿唯美</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>我是一名从事大数据项目的IT系统分析师。在深入这个项目前需要了解些什么呢?学习大数据的最佳方法就是先从了解信息系统是如何工作着手,尤其是数据库和基础设施。同样在开始前还需要了解大数据工具,如Cloudera、Hadoop、Spark、Hive、Pig、Flume、Sqoop与Mesos。系 统分析师需要明白如何组织、管理和保护数据。在市面上有几十款数据管理产品可以用于管理数据。你的大数据数据库可能</div>
</li>
<li><a href="/article/869.htm"
title="spring学习——简介" target="_blank">spring学习——简介</a>
<span class="text-muted">a-john</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>Spring是一个开源框架,是为了解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只能由EJB完成的事情。然而Spring的用途不仅限于服务器端的开发,从简单性,可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。其主要特征是依赖注入、AOP、持久化、事务、SpringMVC以及Acegi Security
为了降低Java开发的复杂性,</div>
</li>
<li><a href="/article/996.htm"
title="自定义颜色的xml文件" target="_blank">自定义颜色的xml文件</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div><?xml version="1.0" encoding="utf-8"?> <resources> <color name="white">#FFFFFF</color> <color name="black">#000000</color> &</div>
</li>
<li><a href="/article/1123.htm"
title="运营到底是做什么的?" target="_blank">运营到底是做什么的?</a>
<span class="text-muted">aoyouzi</span>
<a class="tag" taget="_blank" href="/search/%E8%BF%90%E8%90%A5%E5%88%B0%E5%BA%95%E6%98%AF%E5%81%9A%E4%BB%80%E4%B9%88%E7%9A%84%EF%BC%9F/1.htm">运营到底是做什么的?</a>
<div>文章来源:夏叔叔(微信号:woshixiashushu),欢迎大家关注!很久没有动笔写点东西,近些日子,由于爱狗团产品上线,不断面试,经常会被问道一个问题。问:爱狗团的运营主要做什么?答:带着用户一起嗨。为什么是带着用户玩起来呢?究竟什么是运营?运营到底是做什么的?那么,我们先来回答一个更简单的问题——互联网公司对运营考核什么?以爱狗团为例,绝大部分的移动互联网公司,对运营部门的考核分为三块——用</div>
</li>
<li><a href="/article/1250.htm"
title="js面向对象类和对象" target="_blank">js面向对象类和对象</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/js/1.htm">js</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1/1.htm">面向对象</a><a class="tag" taget="_blank" href="/search/%E5%87%BD%E6%95%B0%E5%88%9B%E5%BB%BA%E7%B1%BB%E5%92%8C%E5%AF%B9%E8%B1%A1/1.htm">函数创建类和对象</a>
<div>接触js已经有几个月了,但是对js的面向对象的一些概念根本就是模糊的,js是一种面向对象的语言 但又不像java一样有class,js不是严格的面向对象语言 ,js在java web开发的地位和java不相上下 ,其中web的数据的反馈现在主流的使用json,json的语法和js的类和属性的创建相似
下面介绍一些js的类和对象的创建的技术
一:类和对</div>
</li>
<li><a href="/article/1377.htm"
title="web.xml之资源管理对象配置 resource-env-ref" target="_blank">web.xml之资源管理对象配置 resource-env-ref</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/web.xml/1.htm">web.xml</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a>
<div>resource-env-ref元素来指定对管理对象的servlet引用的声明,该对象与servlet环境中的资源相关联
<resource-env-ref>
<resource-env-ref-name>资源名</resource-env-ref-name>
<resource-env-ref-type>查找资源时返回的资源类</div>
</li>
<li><a href="/article/1504.htm"
title="Create a composite component with a custom namespace" target="_blank">Create a composite component with a custom namespace</a>
<span class="text-muted">sunjing</span>
<div>https://weblogs.java.net/blog/mriem/archive/2013/11/22/jsf-tip-45-create-composite-component-custom-namespace
When you developed a composite component the namespace you would be seeing would </div>
</li>
<li><a href="/article/1631.htm"
title="【MongoDB学习笔记十二】Mongo副本集服务器角色之Arbiter" target="_blank">【MongoDB学习笔记十二】Mongo副本集服务器角色之Arbiter</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a>
<div> 一、复本集为什么要加入Arbiter这个角色 回答这个问题,要从复本集的存活条件和Aribter服务器的特性两方面来说。 什么是Artiber? An arbiter does
not have a copy of data set and
cannot become a primary. Replica sets may have arbiters to add a </div>
</li>
<li><a href="/article/1758.htm"
title="Javascript开发笔记" target="_blank">Javascript开发笔记</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>
获取iframe内的元素
通常我们使用window.frames["frameId"].document.getElementById("divId").innerHTML这样的形式来获取iframe内的元素,这种写法在IE、safari、chrome下都是通过的,唯独在fireforx下不通过。其实jquery的contents方法提供了对if</div>
</li>
<li><a href="/article/1885.htm"
title="Web浏览器Chrome打开一段时间后,运行alert无效" target="_blank">Web浏览器Chrome打开一段时间后,运行alert无效</a>
<span class="text-muted">bozch</span>
<a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/chorme/1.htm">chorme</a><a class="tag" taget="_blank" href="/search/alert/1.htm">alert</a><a class="tag" taget="_blank" href="/search/%E6%97%A0%E6%95%88/1.htm">无效</a>
<div>今天在开发的时候,突然间发现alert在chrome浏览器就没法弹出了,很是怪异。
试了试其他浏览器,发现都是没有问题的。
开始想以为是chorme浏览器有啥机制导致的,就开始尝试各种代码让alert出来。尝试结果是仍然没有显示出来。
这样开发的结果,如果客户在使用的时候没有提示,那会带来致命的体验。哎,没啥办法了 就关闭浏览器重启。
结果就好了,这也太怪异了。难道是cho</div>
</li>
<li><a href="/article/2012.htm"
title="编程之美-高效地安排会议 图着色问题 贪心算法" target="_blank">编程之美-高效地安排会议 图着色问题 贪心算法</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E4%B9%8B%E7%BE%8E/1.htm">编程之美</a>
<div>
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
public class GraphColoringProblem {
/**编程之美 高效地安排会议 图着色问题 贪心算法
* 假设要用很多个教室对一组</div>
</li>
<li><a href="/article/2139.htm"
title="机器学习相关概念和开发工具" target="_blank">机器学习相关概念和开发工具</a>
<span class="text-muted">chenbowen00</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/matlab/1.htm">matlab</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a>
<div>基本概念:
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
开发工具
M</div>
</li>
<li><a href="/article/2266.htm"
title="[宇宙经济学]关于在太空建立永久定居点的可能性" target="_blank">[宇宙经济学]关于在太空建立永久定居点的可能性</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E7%BB%8F%E6%B5%8E/1.htm">经济</a>
<div>
大家都知道,地球上的房地产都比较昂贵,而且土地证经常会因为新的政府的意志而变幻文本格式........
所以,在地球议会尚不具有在太空行使法律和权力的力量之前,我们外太阳系统的友好联盟可以考虑在地月系的某些引力平衡点上面,修建规模较大的定居点</div>
</li>
<li><a href="/article/2393.htm"
title="oracle 11g database control 证书错误" target="_blank">oracle 11g database control 证书错误</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E8%AF%81%E4%B9%A6%E9%94%99%E8%AF%AF/1.htm">证书错误</a><a class="tag" taget="_blank" href="/search/oracle+11G+%E5%AE%89%E8%A3%85/1.htm">oracle 11G 安装</a>
<div>oracle 11g database control 证书错误
win7 安装完oracle11后打开 Database control 后,会打开em管理页面,提示证书错误,点“继续浏览此网站”,还是会继续停留在证书错误页面
解决办法:
是 KB2661254 这个更新补丁引起的,它限制了 RSA 密钥位长度少于 1024 位的证书的使用。具体可以看微软官方公告:</div>
</li>
<li><a href="/article/2520.htm"
title="Java I/O之用FilenameFilter实现根据文件扩展名删除文件" target="_blank">Java I/O之用FilenameFilter实现根据文件扩展名删除文件</a>
<span class="text-muted">游其是你</span>
<a class="tag" taget="_blank" href="/search/FilenameFilter/1.htm">FilenameFilter</a>
<div>在Java中,你可以通过实现FilenameFilter类并重写accept(File dir, String name) 方法实现文件过滤功能。
在这个例子中,我们向你展示在“c:\\folder”路径下列出所有“.txt”格式的文件并删除。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 </div>
</li>
<li><a href="/article/2647.htm"
title="C语言数组的简单以及一维数组的简单排序算法示例,二维数组简单示例" target="_blank">C语言数组的简单以及一维数组的简单排序算法示例,二维数组简单示例</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a><a class="tag" taget="_blank" href="/search/array/1.htm">array</a>
<div># include <stdio.h>
int main(void)
{
int a[5] = {1, 2, 3, 4, 5};
//a 是数组的名字 5是表示数组元素的个数,并且这五个元素分别用a[0], a[1]...a[4]
int i;
for (i=0; i<5; ++i)
printf("%d\n",</div>
</li>
<li><a href="/article/2774.htm"
title="PRIMARY, INDEX, UNIQUE 这3种是一类 PRIMARY 主键。 就是 唯一 且 不能为空。 INDEX 索引,普通的 UNIQUE 唯一索引" target="_blank">PRIMARY, INDEX, UNIQUE 这3种是一类 PRIMARY 主键。 就是 唯一 且 不能为空。 INDEX 索引,普通的 UNIQUE 唯一索引</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/primary/1.htm">primary</a>
<div>PRIMARY, INDEX, UNIQUE 这3种是一类PRIMARY 主键。 就是 唯一 且 不能为空。INDEX 索引,普通的UNIQUE 唯一索引。 不允许有重复。FULLTEXT 是全文索引,用于在一篇文章中,检索文本信息的。举个例子来说,比如你在为某商场做一个会员卡的系统。这个系统有一个会员表有下列字段:会员编号 INT会员姓名 </div>
</li>
<li><a href="/article/2901.htm"
title="java集合辅助类 Collections、Arrays" target="_blank">java集合辅助类 Collections、Arrays</a>
<span class="text-muted">shuizhaosi888</span>
<a class="tag" taget="_blank" href="/search/Collections/1.htm">Collections</a><a class="tag" taget="_blank" href="/search/Arrays/1.htm">Arrays</a><a class="tag" taget="_blank" href="/search/HashCode/1.htm">HashCode</a>
<div>
Arrays、Collections
1 )数组集合之间转换
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
a)Arrays.asL</div>
</li>
<li><a href="/article/3028.htm"
title="Spring Security(10)——退出登录logout" target="_blank">Spring Security(10)——退出登录logout</a>
<span class="text-muted">234390216</span>
<a class="tag" taget="_blank" href="/search/logout/1.htm">logout</a><a class="tag" taget="_blank" href="/search/Spring+Security/1.htm">Spring Security</a><a class="tag" taget="_blank" href="/search/%E9%80%80%E5%87%BA%E7%99%BB%E5%BD%95/1.htm">退出登录</a><a class="tag" taget="_blank" href="/search/logout-url/1.htm">logout-url</a><a class="tag" taget="_blank" href="/search/LogoutFilter/1.htm">LogoutFilter</a>
<div> 要实现退出登录的功能我们需要在http元素下定义logout元素,这样Spring Security将自动为我们添加用于处理退出登录的过滤器LogoutFilter到FilterChain。当我们指定了http元素的auto-config属性为true时logout定义是会自动配置的,此时我们默认退出登录的URL为“/j_spring_secu</div>
</li>
<li><a href="/article/3155.htm"
title="透过源码学前端 之 Backbone 三 Model" target="_blank">透过源码学前端 之 Backbone 三 Model</a>
<span class="text-muted">逐行分析JS源代码</span>
<a class="tag" taget="_blank" href="/search/backbone/1.htm">backbone</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/1.htm">源码分析</a><a class="tag" taget="_blank" href="/search/js%E5%AD%A6%E4%B9%A0/1.htm">js学习</a>
<div>Backbone 分析第三部分 Model
概述: Model 提供了数据存储,将数据以JSON的形式保存在 Model的 attributes里,
但重点功能在于其提供了一套功能强大,使用简单的存、取、删、改数据方法,并在不同的操作里加了相应的监听事件,
如每次修改添加里都会触发 change,这在据模型变动来修改视图时很常用,并且与collection建立了关联。 </div>
</li>
<li><a href="/article/3282.htm"
title="SpringMVC源码总结(七)mvc:annotation-driven中的HttpMessageConverter" target="_blank">SpringMVC源码总结(七)mvc:annotation-driven中的HttpMessageConverter</a>
<span class="text-muted">乒乓狂魔</span>
<a class="tag" taget="_blank" href="/search/springMVC/1.htm">springMVC</a>
<div>这一篇文章主要介绍下HttpMessageConverter整个注册过程包含自定义的HttpMessageConverter,然后对一些HttpMessageConverter进行具体介绍。
HttpMessageConverter接口介绍:
public interface HttpMessageConverter<T> {
/**
* Indicate</div>
</li>
<li><a href="/article/3409.htm"
title="分布式基础知识和算法理论" target="_blank">分布式基础知识和算法理论</a>
<span class="text-muted">bluky999</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E4%B8%80%E8%87%B4%E6%80%A7%E5%93%88%E5%B8%8C/1.htm">一致性哈希</a><a class="tag" taget="_blank" href="/search/paxos/1.htm">paxos</a>
<div>
分布式基础知识和算法理论
BY NODEXY@2014.8.12
本文永久链接:http://nodex.iteye.com/blog/2103218
在大数据的背景下,不管是做存储,做搜索,做数据分析,或者做产品或服务本身,面向互联网和移动互联网用户,已经不可避免地要面对分布式环境。笔者在此收录一些分布式相关的基础知识和算法理论介绍,在完善自我知识体系的同</div>
</li>
<li><a href="/article/3536.htm"
title="Android Studio的.gitignore以及gitignore无效的解决" target="_blank">Android Studio的.gitignore以及gitignore无效的解决</a>
<span class="text-muted">bell0901</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/gitignore/1.htm">gitignore</a>
<div> github上.gitignore模板合集,里面有各种.gitignore : https://github.com/github/gitignore
自己用的Android Studio下项目的.gitignore文件,对github上的android.gitignore添加了
# OSX files //mac os下 .DS_Store </div>
</li>
<li><a href="/article/3663.htm"
title="成为高级程序员的10个步骤" target="_blank">成为高级程序员的10个步骤</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a>
<div>What
软件工程师的职业生涯要历经以下几个阶段:初级、中级,最后才是高级。这篇文章主要是讲如何通过 10 个步骤助你成为一名高级软件工程师。
Why
得到更多的报酬!因为你的薪水会随着你水平的提高而增加
提升你的职业生涯。成为了高级软件工程师之后,就可以朝着架构师、团队负责人、CTO 等职位前进
历经更大的挑战。随着你的成长,各种影响力也会提高。 </div>
</li>
<li><a href="/article/3790.htm"
title="mongdb在linux下的安装" target="_blank">mongdb在linux下的安装</a>
<span class="text-muted">xtuhcy</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>一、查询linux版本号:
lsb_release -a
LSB Version: :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch:printing-4.0-amd64:printing-4.0-noa</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>