入门数据挖掘-心电图信号预测datawhale组队学习笔记-task5 模型融合
心电图信号预测 - task 5 模型融合
-
- 1. 融合方法
-
- 1.1 简单加权融合
- 1.2 stacking/blending[^1]
- 1.2.1 stacking
- 1.2.2 blending
- 1.3 boosting/bagging
- 2. 代码示例
-
- 2.1 回归(分类概率)融合
- 2.2 Stacking融合(回归)
-
- 2.3 分类模型融合
-
- 2.3.1 Voting投票机制
- 2.3.2 分类的Stacking/Blending融合
1. 融合方法
1.1 简单加权融合
- 回归(分类概率):算术平均,几何平均融合
- 分类: 投票(Voting)
- 综合:排序融合,log融合
1.2 stacking/blending1
1.2.1 stacking
构建多层模型,利用预测结果再拟合预测。
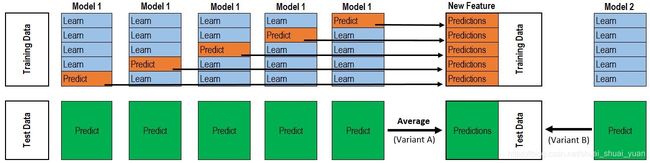
- stacking是一种分层模型集成框架。
以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型, stacking两层模型都使用了全部的训练数据。 - 对于每一轮的 5-fold,Model 1都要做5次训练和预测。
train data:每次分为learn和predict, 五次预测结果合并记作P1。
test data:每次,Model 1获得对测试数据的预测结果,最后得到一个平均预测值,记作p1。
第一层共训练n个模型,5-fold 预测值矩阵 X n 作为第二层模型的train data,来自test data的预测值矩阵 X n 作为test data.
#Out-of-Fold predictions
ntrain = train.shape[0]
ntest = test.shape[0]
kf = KFold(n_splits=5, random_state=100)
def get_oof(clf, X_train, y_train, X_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((5, ntest))
for i, (train_index, test_index) in enumerate(kf.split(X_train)):
kf_X_train = X_train[train_index]
kf_y_train = y_train[train_index]
kf_X_test = X_train[test_index]
clf.train(kf_X_train, kf_y_train)
oof_train[test_index] = clf.predict(kf_X_test)
oof_test_skf[i,:] = clf.predict[X_test]
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
1.2.2 blending
和Stacking是一种类似的多层模型融合的形式
其主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。
在第一层,我们在这70%的数据上训练多个模型,然后去预测那30%数据的label,同时也预测test集的label。
在第二层,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练,然后用test集第一层预测的label做特征,用第二层训练的模型做进一步预测.
其优点在于
- 比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
- 避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
缺点在于:
- 使用了很少的数据(第二阶段的blender只使用training set10%的量)
- blender可能会过拟合
- stacking使用多次的交叉验证会比较稳健
1.3 boosting/bagging
多树的提升方法:xgboost, Adaboost, GBDT。
2. 代码示例
2.1 回归(分类概率)融合
# 简单加权平均,融合结果
import numpy as np
import pandas as pd
from sklearn import metrics
test_pred1 = [1.2, 2.1, 3.4, 4.5]
test_pred1 = [1.3, 2.6, 3.5, 3.9]
test_pred1 = [1.1, 2.7, 3.2, 4.2]
y_test_true = [1, 2, 3, 6]
def Weighted_method(test_pred1, test_pred2, test_pred3, w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pred1)+w[1]*pd.Series(test_pred2)+w[2]*pd.Series(test_pred3)
return Weighted_result
#预测结果
pred1_MAE = metrics.mean_absolute_error(y_test_true, test_pred1)
#pred2_MAE, pred3_MAE
#加权计算MAE
w = [0.3, 0.4, 0.3]
weighted_pred = Weighted_method(test_pred1, test_pred2, test_pred3, w)
print('Weighted_pred MAE:', metrics.mean_absolute_error(y_test_ture, weighted_pred))
# Mean平均
def Mean_method(test_pre1, test_pre2, test_prep3):
Mean_result = pd.concat([pd.Series(test_pre1), pd.Series(test_pre2), pd.Series(teste_pre3)], axis=1).mean(axis=1)
return Mean_result
# Median平均
def Medain_method(test_pre1, test_pre2, test_prep3):
Mean_result = pd.concat([pd.Series(test_pre1), pd.Series(test_pre2), pd.Series(teste_pre3)], axis=1).median(axis=1)
return Median_result
2.2 Stacking融合(回归)
from sklearn import linear_model
def Stacking_method(train_reg1, train_reg2, train_reg3, y_train_true, test_pre1, test_pre2, test_pre3, model_L2=linear_model.LinearRegression()):
model_L2.fit(pd.concat([pd.Series(train_reg1), pd.Series(train_reg2), pd.Series(train_reg3)], axis=1).values, y_train_true)
Stacking_result = model_L2.predict(pd.concat([pd.Series(test_pre1), pd.Series(test_pre2), pd.Series(test_pre3)], axis=1).values)
return Stacking_result
## 生成一些简单的样本数据,train_prei 代表第i个模型对train data的预测值
train_reg1 = [3.2, 8.2, 9.1, 5.2]
train_reg2 = [2.9, 8.1, 9.0, 4.9]
train_reg3 = [3.1, 7.9, 9.2, 5.0]
# y_train_true 代表train data的label真实值
y_train_true = [3, 8, 9, 5]
# test_prei 代表第i个模型对test data的预测结果
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表test data的label真实值
y_test_true = [1, 3, 2, 6]
model_L2= linear_model.LinearRegression()
Stacking_pre = Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,
test_pre1,test_pre2,test_pre3,model_L2)
print('Stacking_pre MAE:',metrics.mean_absolute_error(y_test_true, Stacking_pre))
- 第二层Stacking的模型不宜选取的过于复杂,这样会导致模型在训练集上过拟合,从而使得在测试集上并不能达到很好的效果。
2.3 分类模型融合
import numpy as np
import lightgbm as lgb
from sklearn.datasets import make_blobs
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
from sklearn.metrics import accuracy_score,roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
2.3.1 Voting投票机制
分为硬投票和软投票两种, 采用少数服从多数的思想.
- 硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
iris = datasets.load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = lgb.LGBMClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.7,
colsample_bytree=0.6, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=200, max_depth=10, min_samples_split=10,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1)
# 硬投票
eclf = VotingClassifier(estimators=[('lgb', clf1), ('rf', clf2), ('svc', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['LGB', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
2.3.2 分类的Stacking/Blending融合
'''
5-Fold Stacking
'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier,GradientBoostingClassifier
import pandas as pd
#创建训练的数据集
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(solver='lbfgs'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
#5折stacking
n_splits = 5
skf = StratifiedKFold(n_splits)
skf = skf.split(X, y)
for j, clf in enumerate(clfs):
#依次训练各个单模型
dataset_blend_test_j = np.zeros((X_predict.shape[0], 5))
for i, (train, test) in enumerate(skf):
#5-Fold交叉训练,使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
#对于测试集,直接用这k个模型的预测值均值作为新的特征。
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j]))
clf = LogisticRegression(solver='lbfgs')
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print("Val auc Score of Stacking: %f" % (roc_auc_score(y_predict, y_submission)))
stacking参考知乎Kaggle机器学习之模型融合(stacking)心得. ↩︎