操作系统实践 linux命令期末汇总
操作系统实践 linux命令
- Linux 1 简介
-
- linux介绍
-
- GPL
- linux发行版
- linux系统标准化
- 登入与登出
- 常用快捷键
- 补充内容
- Linux 2 Shell
-
- Shell
- 环境变量
- 别名
- Shell 元字符
- 查看系统信息
- 补充内容
- Linux 4 文件系统
-
- 文件类型
- 设备命名
- 分区命名规则
- 让文件系统工作起来
- 关于文件的命令
- 逻辑卷管理
- Linux 5 文件安全
-
- 改变文件访问权限
- 默认文件访问权限
- 特殊权限位
- Linux6 文件处理
-
- 查看文件内容
- 去重
- 补丁
- 文件压缩
- 查找
- 排序
- Cut
- paste
- 正则表达式
- grep(筛选满足要求的行)
- sed(替换删除插入操作)
- awk(筛选满足要求的行或者列)
- Linux 7 重定向和管道
-
- 管道
- tee
- FIFOS (named pipes)
- Linux 8 文件共享
-
- 链接文件
- 硬链接
- 软链接
- Linux 9 进程
-
- ps命令
- nice值
- 其他命令
- 进程切换
- 命令的顺序和并行执行
- 命令和进程异常终止
- crontab与at 定时操作
-
- at
- crontab
- Linux 11 打包
-
- tar命令
- Linux 12 shell 脚本编程
-
- 执行命令
- 指定解释器
- 变量
- 只读shell变量
- 命令替换
- 输入输出
- 选择分支
- 循环
-
- for循环
- while语句
- 读入文件的每一行
Linux 1 简介
linux介绍
GPL

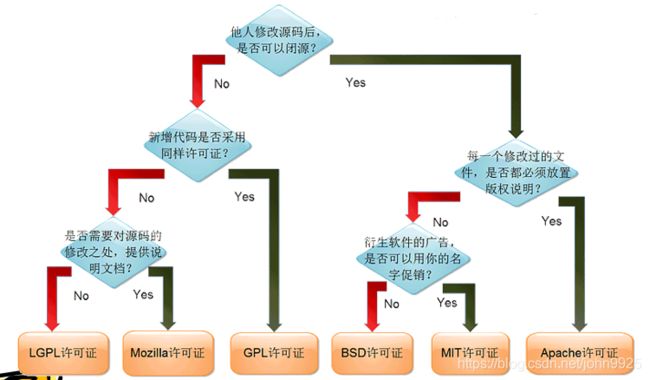
可见redistribute后,要用同样的许可证
linux发行版

linux系统标准化
1.Portable Operation System Interface(POSIX)可移植操作系统接口
2.Single UNIX Specification (SUS)单一UNIX规范
3.Linux Standard Base (LSB)
登入与登出
用户信息存放 /etc/passwd
用户密码存放 /etc/shadow
passwd修改密码
reboot重启
shutdown关机
poweroff会发送一个 ACPI 信号来通知系统关机。
halt通知硬件来停止所有的 CPU 功能,但是仍然保持通电。你可以用它使系统处于低层维护状态
常用快捷键
ctrl a 光标移到最前
ctrl e 最后
ctrl u 删除光标前所有
ctrl k 删除光标后所有
ctrl c取消当前命令
tab自动补全
补充内容
history 查看历史命令
!!执行上一次执行的命令
type看文件类型
Linux 2 Shell
Shell
/etc/profile: system environment 配置系统所有人的环境信息
$HOME/. bash_profile(.profile,.bash_login): 每次登陆的时候都会执行一次,配置个人的环境信息。
$HOME/.bashrc: 每次使用bash,都会执行。(每次登录会执行一次,因为profile里写了执行bashrc的代码)
有些命令使用后只对当次登录有效,每次重新登录系统效果就会消失,要永久保留效果把这个命令加入到.profile 或者.bashrc中
环境变量
$PATH:command searching path
$HOME:user logging on directory
$PS1:command prompt
$LANG: language
当执行一个文件的时候会在PATH中找
为PATH环境变量增加当前目录
PATH=$PATH:.
.表示当前目录
..表示上一个目录
这样写相当于给变量赋值,学了后面变量赋值就可以理解了。
这样修改后,每次重新登录系统效果就会消失,要永久保留效果把这个命令加入到.profile 或者.bashrc中
which ls 查看ls命令在哪里
执行结果/bin/ls
别名
为命令创建别名
alias tt="tail" 这样使用tt就代表tail命令了
查看所有别名
alias
取消别名
unalias tt这样tt这个别名就取消了
Shell 元字符
不要把元字符跟正则搞混了
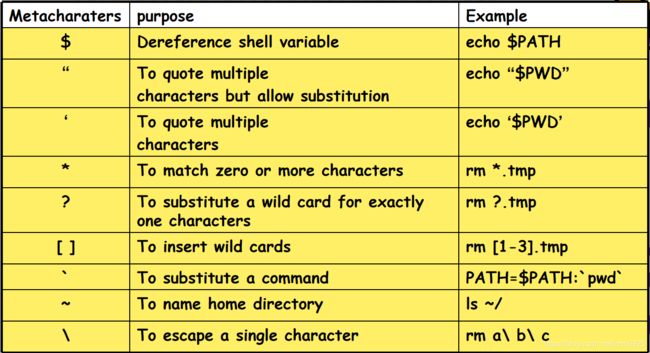
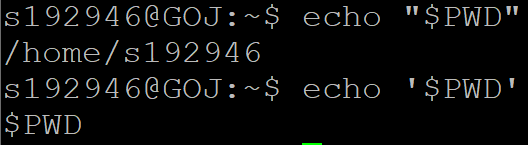
$访问变量的值
""括住字符串,括号内允许替换(可以使用变量的值)
''括住字符串(原样输出)
*匹配任意0个或多个字符
?匹配恰好一个字符
[]匹配中括号内的单个字符。
如[13]表示匹配1或者3 。如[1-23-5]表示匹配1~ 2或者3~ 5的单个字符 。如[1-2]表示匹配1~ 2的单个字符 。也可以[A-Z]或者[a-z]
反撇号,表示使用命令的结果,一般用来把一个命令结果赋给一个变量
~家目录
练习
Give the command to list the following files:
1.end with .o, like a.o abc.o
ls *.o
2. start with a, end with b, like a1b acb acdb
ls a*b
3. only two characters, first is a lower letter, second is a digital, like a1 b3 c9
ls [a-z0-9]
4. all the files whose name contains only two characters your home directory(假设当前就在家目录)
ls ??
5. output the string like“the current path is xxx”, xxx stands for the current directory name. if your are in /tmp, output "the current path is /tmp”
echo “the current path is $PWD”
查看系统信息
whoami:用户信息
hostname:主机名
uname:OS information(如linux)
-r看版本
-a看完整全部信息
free:看内存信息
-h以人性化方式显示,(大小以多少k多少g显示)
-l显示详细信息
date:system date
补充内容
命令执行顺序
1.alias
2.Build-in command
3.Execute file
查看帮助信息
man 命令
Linux 4 文件系统
文件类型
Simple/ordinary file 普通文件
Directory 目录
Symbolic (soft) link 符号链接文件:A Link File is created by the system when a symbolic link in created to an existing file.
Special (device) files – block special files and character special files 特殊文件(块文件,字符文件):
A special File is a means of accessing hardware devices, including the keyboard, hard disk, CD-ROM drive, tape drive and printer.
Character Special Files
Correspond to character-oriented devices (e.g., Keyboard)
Block Special Files
Correspond to block-oriented devices (e.g., a disk)
Named pipe (FIFO) 命名管道:Tools that enable processes to communicate with each other
Socket
设备命名

分区命名规则
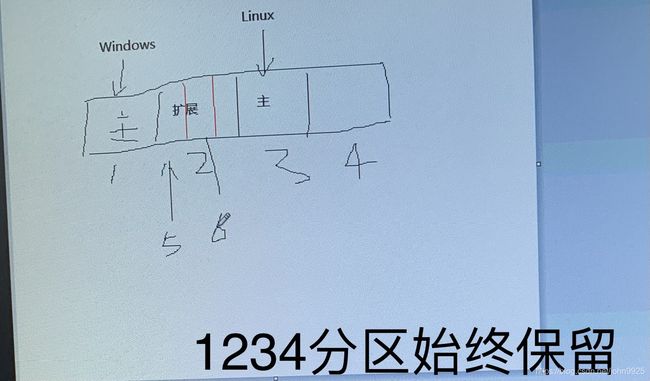
每个硬盘最多4个主分区,1~4编号。扩展分区(逻辑分区)从5开始编号。
让文件系统工作起来
/etc/fstab是用来存放文件系统的静态信息的文件,当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂载到指定的目录
Disk Partition(分区): parted
Format the partition(分区格式化): mkfs
Mount the disk partition(分区挂载)
mount [-t vfstype] [-o options] device dir (把分区挂载到目录中)
加-t是指定分区格式
-auto mount the partition: /etc/fstab(若需要每次启动自动挂载,需要把信息加到fstab中)
/mnt 是挂接光驱、USB设备的目录,加载后,会在mnt里多出相应设备的目录。mnt是mount的缩写。


关于文件的命令
dfdisk free,通过文件系统来快速获取空间大小的信息。当我们删除一个文件的时候,这个文件不是马上就在文件系统当中消失了,而是暂时消失了,当所有程序都不用时,才会根据OS的规则释放掉已经删除的文件。 df记录的是通过文件系统获取到的文件的大小,他比du强的地方就是能够看到已经删除 的文件,而且计算大小的时候,把这一部分的空间也加上了,更精确了。
dudisk usage,是通过搜索文件来计算每个文件的大小,然后累加,du能看到的文件只是一些当前存在的,没有被删除的
mkdir a创建一个名为a的目录
rmdir a删除名为a的目录,目录内非空时无法删除。此时可用rm -r
ls查看当前位置的文件
-l详细信息
-h人性化显示,(文件大小以K,G显示)
![]()
对-l的解释:
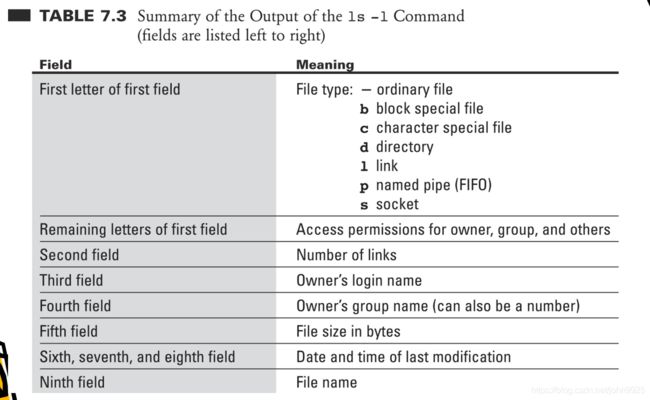
touch a创建一个名为a的文件
cat a查看a文件的内容
cp a b复制a到b,如果b是目录,会在b中产生一个a文件。否则产生一个名为b的文件(内容跟a一样)
-r如果a是目录,则要加-r参数,表示递归复制
mv a b若b是目录,则把a移动到b目录。否则把a改名为b
rm a删除a文件
-r强制删除,a是目录也可以删
-i删除时给提示是否要删。
逻辑卷管理

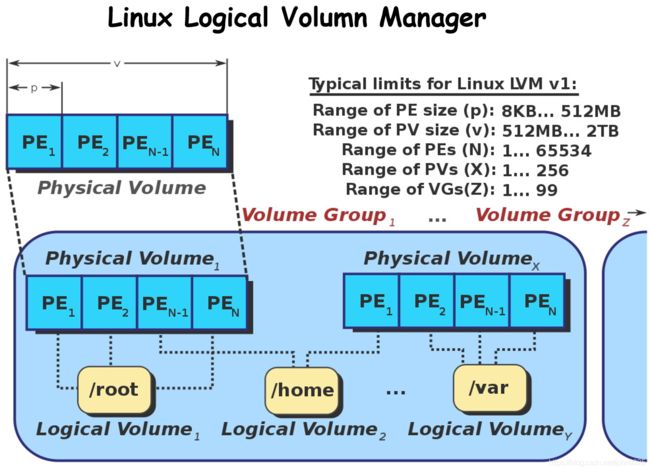
大致内容为:
1.新增硬盘,硬盘分区,设置分区格式为8e
2.分区转为物理卷,加入卷组中
3.扩展逻辑卷(可以理解为逻辑卷就是根目录的大小,卷组的大小就是可分配的大小)
4.同步文件系统
Linux 5 文件安全
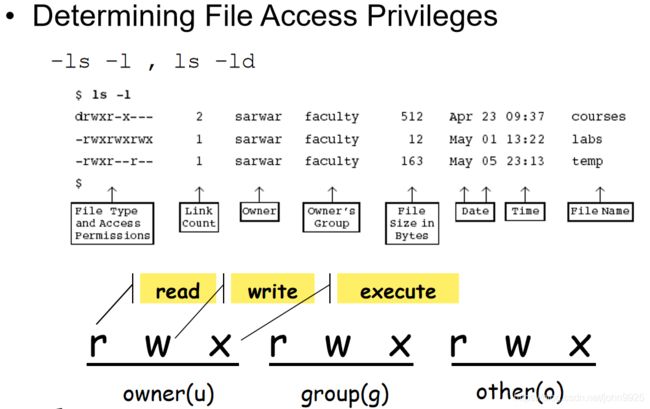
id查看用户id,所属组
chown或者chgrp改变文件所有者
改变文件访问权限

例子
chmod 277 file二进制下每一位代表rwx 所以这里表示对作者w,同组rwx,其他rwxchmod a+x file表示给所有人增加x权限chmod a-wx file所有人减少wx权限chmod uo=r作者和其他人只有r权限
对于目录而言,给目录增加执行权限,其他人就可以用cd命令到这个目录
默认文件访问权限
umask查看当前掩码值 4位,第一位是特殊权限位,第二位作者,第三位同组,第四位其他人
-S查看当前创建文件默认权限
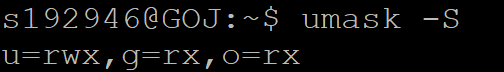
可执行文件或者目录的权限是777-umask
其他文件是666-umask
设置umask为777 umask 777
特殊权限位
SUID 运行某程序时,相应进程的属主是程序文件自身的属主,而不是启动者(启动者临时获得文件属主的权限)
chmod u+s file
chmod 4xxx file
SGID 运行某程序时,相应进程的属主是程序文件自身的属组,而不是启动者所属的基本组(启动者临时获得文件属组的权限)
chmod g+s file
chmod 2xxx file
Sticky:在一个公共目录,每个都可创建文件,删除自己的文件,但不能删除别人的文件
chmod o+t file
chmod 1xxx file
Linux6 文件处理
查看文件内容
cat查看文件全部内容
-n显示行号,空行也计
-b显示行号,空行不增加行号
nl查看文件全部内容,并标行号,空行不标号
more文件内容较多的时候可以使用,分页查看,f下一页,b前一页,/关键词(快速定位)
od -c看整个文件内容包括空格换行符等等

head -5看前5行 -后的数字表示前几行,tail用法一样表示后几行
tail +300从300行到末尾
tail -f 实时看文件的追加内容
wc展示总行数,单词数,字符数
-l 只看行数 -w只看单词数 -c只看字符数
比如希望统计系统中的用户数
wc -l /etc/passwd
去重
uniq去重,只能去除连续的重复行。可以配合排序实现去除所有重复行
-c 每行连续出现多少次
补丁
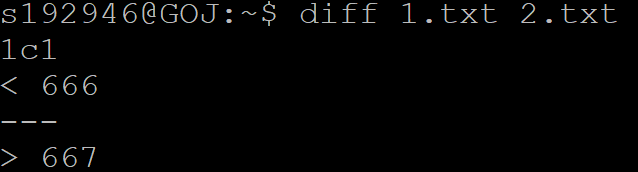
diff old new > patch_file产生一个old和new文件差异的文件
patch old patch_file对旧文件patch,就会变成新文件。
文件压缩
gzip把文件压缩为.gz结尾的压缩文件,原文件消失
-d解压,压缩文件消失
gunzip解压,跟gzip -d效果一样
bzip2同理,产生.bz2结尾文件
-d解压
查找
find . -name file在当前目录按名字找,file可以包含元字符
-size要求大小必须是size
+-文件大小比这个值大或者小
排序
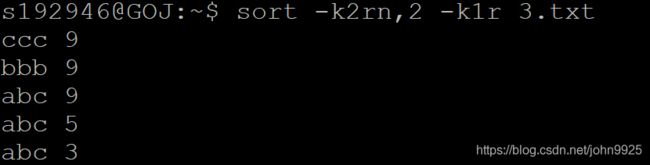
sort
-k2 按第二个字段(当做字符串)小到大排序
-nk2第二个字段当数字小到大
-r逆序
-t:设置分隔符为:,没设置的话默认分隔符空格或者TAB
多要求排序
除了最后一个要求,其他都要,数字数字是操作的列。
Cut
cut -f1,2 把文件第一字段第二字段截取出来。默认定位符(\t)分隔
-d'$'设置分隔符为$
-c3,4,8-11按字符分隔,第三第四和8-11列的字符

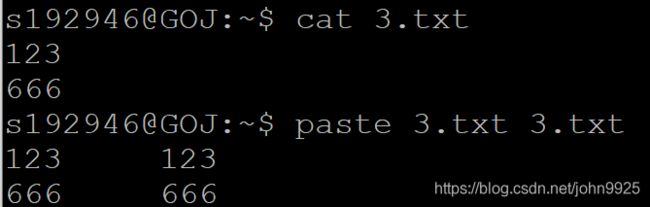
paste
paste file1 file2把file2每一行对应粘到file1的每一行
正则表达式
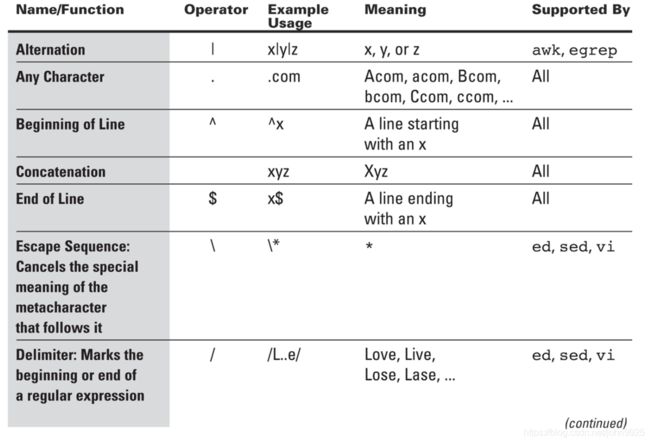

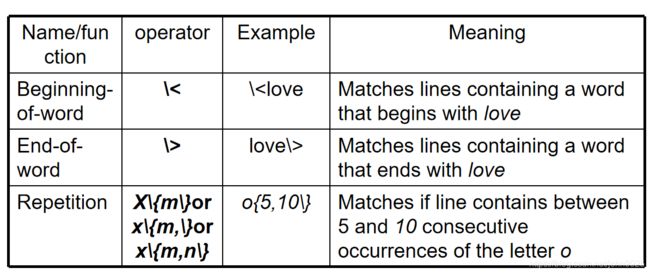
如果用egrep的话。重复次数就不用\{m\}直接{m}即可
grep(筛选满足要求的行)
可以直接用egrep功能更多
grep 选项 '正则' file 注意正则不用//围绕
-n显示行号(在原文本中的行)
-c显示行数量
-v不包含(取反)
-w完整匹配 比如grep '26' file则626会被匹配到,加了-w就匹配不到了
file可以用元字符,配合-l 只显示文件名
-i忽略大小写
例子:

Sort data in /tmp/databook using salary as the sort key in reverse order. Show your session.
sort -t: -nk5 -r /tmp/databook
Display all the user name and user id in the system
cut -d':' -f1,3 /etc/passwd
With grep(/tmp/databook)
Print all lines containing the string San.
grep 'San' /tmp/databook
Print all lines where the person’s first name starts with J.
grep '^J' /tmp/databook
Print all lines ending in 700.
grep '700$' /tmp/databook
Print all lines that don’t contain 834.
grep -v '834' /tmp/databook
Print all lines where birthdays are in December.
grep ':12/' /tmp/databook
Print all lines where the phone number is in the 408 area code.
grep ':408-' /tmp/databook
Print all lines containing an uppercase letter, followed by four lowercase letters, a comma, and one uppercase letter.
grep '[A-Z][a-z]\{4\}, [A-Z]' /tmp/databook
或者grep '[A-Z][a-z]{4}, [A-Z]' /tmp/databook
Print lines where the last name begins with K or k.
grep -i '\
Print lines preceded by a line number where the salary is a six-figure number.
grep -n ':[0-9]\{6\}\>' /tmp/databook
Print lines containing Lincoln or lincoln (remember that grep is insensitive to case).,
egrep 'Lincoln|lincoln' /tmp/databook
或者grep '[Ll]incoln' /tmp/databook
sed(替换删除插入操作)
sed '[地址]command' file
sed只要是写正则都要/正则/
[地址]用3,4替换表示处理3到4行
s/正则/x/把满足正则的东西替换成x,后面加个g表示全局(所有)替换
(无g只替换每行第一个满足的,有g每行全部替换)
/正则/d把满足正则的东西删掉
-n '2,4p'打印2-4行, -n和p是一起使用的
/正则/i/string i表示在该行(满足正则的行),a表示该行后插入string
!取反,i要放选项前,若sed -n '2,4!p'表示不打印2~4行
-i修改,只有加了这个参数才会对文件修改
可以先在''里最开始用/正则/然后再操作替换之类的。比如对名字为xx的人,把他生日替换掉。
例子:
With sed(/tmp/databook).
Change Jon’s name to Joanthan
sed 's/Jon/Joanthan/' /tmp/databook
Delete the first three lines
sed '1,3d' /tmp/databook
Print lines 5 through 10
sed -n '5,10p' /tmp/databook
Delete lines containing Lane
sed '/Lane/d' /tmp/databook
Print all lines where the birthdays are in November or December
sed -n '/:1[1-2]\//p' /tmp/databook
Replace the line containing Jose with JOSE HAS RETIRED.
sed 's/.*Jose.*/JOSE HAS RETIRED./' /tmp/databook
Change Popeye’s birthday to 11/14/46
sed '/^Popeye/s/[0-9]*\/[0-9]*\/[0-9]*/11\/14\/46/' /tmp/databook
Delete all blank lines
sed '/^$/d' /tmp/databook
awk(筛选满足要求的行或者列)
对字段(列)进行处理
awk '' file
定位符和空格都是默认分隔符
-F:设置分隔符为:。-F'[: ]'表示设置分隔符为:或空格
'/正则/{print $1}'打印满足正则的第一列。如果不加{}的话,打印整行
$0表示原来的行
$1,$3第一列,第三列,打印的时候中间以空格隔开。
$1","$3第一列,第三列,打印的时候中间以,隔开。
$4>100要求第四个字段的值>100
$2~/正则/第二列满足正则的行!~表示不满足
注意awk表示重复次数直接 {m}即可
支持算数运算符(±*/^),支持逻辑运算与或非(&&,||,!),支持比较符

NR表示行号,可放在{}内
NR>=3&&NR<=5第三行到第五行的整行
例子:
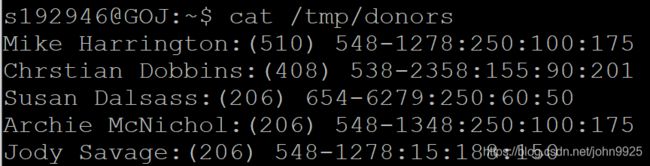
With awk(/tmp/donors): contains the names, phone numbers, and money contributions to the party campaign for the past three months
Print all the phone numbers
awk -F: '{print $2}' /tmp/donors
Print Dan’s phone number
awk -F: '/^Dan/{print $2}' /tmp/donors
Print Susan’s name and phone number
awk -F: '/^Susan/{print $1,$2}' /tmp/donors
Print all last names beginning with D
awk -F'[: ]' '$2~/^D/{print $2}' /tmp/donors
Print all first names beginning with either a C or E.
awk -F'[: ]' '/^[CE]/{print $1}' /tmp/donors
Print all first names containing only four characters.
awk -F'[: ]' '/^[A-Z][a-z]{3} /{print $1}' /tmp/donors
Print the first names of all those in the 916 area code.
awk -F'[: ]' '/:\(916\)/{print $1}' /tmp/donors
Print Main’s campaign contributions. Each value should be printed with a leading dollar sign; e.g., $250 $100 $175.
awk -F'[: ]' '$2~/^Main/{print "$"$5,"$"$6,"$"$7}' /tmp/donors
Print second name followed with a comma and first name
awk -F'[: ]' '{print $2","$1}' /tmp/donors
Print the first and last names of those who contributed more than $100 in the second month.
awk -F: '$4>100{print $1}' /tmp/donors
Print the names and phone numbers of those who contributed less than $85 in the last month.
awk -F: '$5<85{print $1,$2}' /tmp/donors
Print the names of those who contributed between $75 and $150 in the first month.
awk -F: '$3>=75 && $3<=150 {print $1}' /tmp/donors
Print the names of those who contributed less than $800 over the three-month period.
awk -F: '$3+$4+$5<800 {print $1}' /tmp/donors
Print the names and addresses of those with an average monthly contribution greater than $200.
awk -F: '($3+$4+$5)/3>200 {print $1,$2}' /tmp/donors
Print the first name of those not in the 916 area code.
awk -F: '$2!~/\(916\)/{print $1}' /tmp/donors
Print each record preceded by the number of the record.
awk '{print NR,$0}' /tmp/donors
Print the name and total contribution of each person.
awk -F: '{print $1,$3+$4+$5}' /tmp/donors
Linux 7 重定向和管道
command < file2 命令的输入从file2
tr ‘:’ ‘ ’ < donors 表示把donors中的:替换成空格
tr abc 123表示a对应1,b对应2,c对应3 。不重定向的话会从键盘获取输入。我输入abca会得到1231
可以配合a-z,1-9之类的使用
... > file把...的内容**(正确的)重定向到file,全部覆盖
... >> file在file末尾追加**内容
... 2>file错误输出重定向到file。(把错误提示信息)
/dev/null永远是空,配合错误输出重定向使用
... >& file**全部(包括错误)**都弄到file中,包括错误信息
Command > out-file 2>err-file这样可以同时把结果和错误信息都存下来
Command > out-file >& all-file则outfile是空的,allfile有内容
cat f1 f2 > f3把f1 f2 的东西弄到f3中
(f1的内容,然后换行f2的内容)
例子
sort –k4 –n student_record > result
who >> stu_login
cat f1 f2 > f3
管道
|对命令的结果再用其他的操作。
例如
sort student_record | uniq先排序后去重
ls –l | more
统计系统当前多少人
who | wc -l
tee
grep '^Ste' databook| tee file1 file2...| wc –l保存一份到file1,file2…中,一份继续通过管道给wc
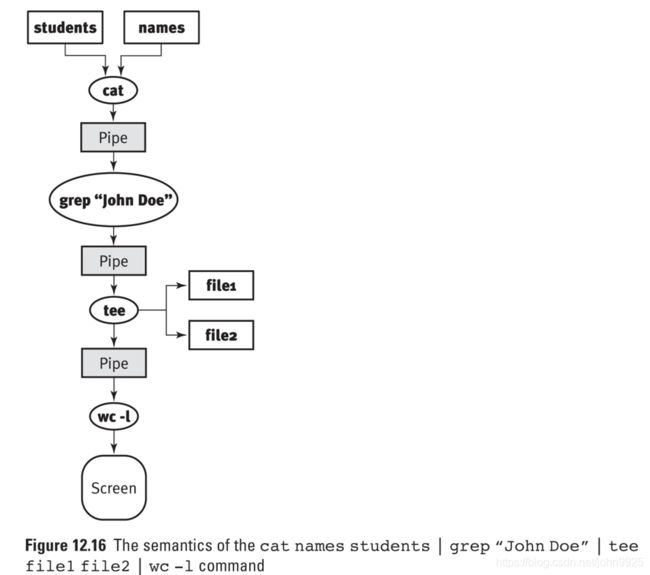
FIFOS (named pipes)
fifo 命名管道文件 。 类似弹幕
mkfifo 创建
-m mask比如mask是777,管道权限就是所有人都可以rwx
cat > /tmp/pipe就可以不断从屏幕输入东西
然后在一台主机cat < /tmp/pipe就可以实现在这台主机看别人输入的东西
Linux 8 文件共享
链接文件
ln 选项 存在的文件 新文件(填两个目录也可)
-f强行产生
-n新文件存在就不产生
前两个都是硬链接
-s软链接
链接文件修改任意文件的内容,新旧文件内容都会改变。
ls -li file看详细的索引号。可以看到用硬连接的两个文件指向同一个索引。

硬链接
新文件和旧文件是共享的,新文件是旧的链接文件,新增一个目录条目,和旧文件同一个索引结点号。
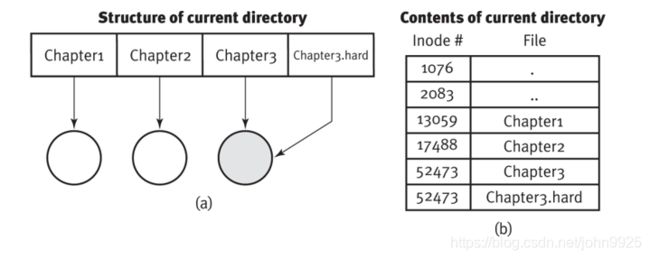
软链接
新增一个目录条目,新的索引结点号,硬盘单独有个区域,存的是旧文件的地址。取出来后再访问旧文件,需要读取两次硬盘,效率低一些
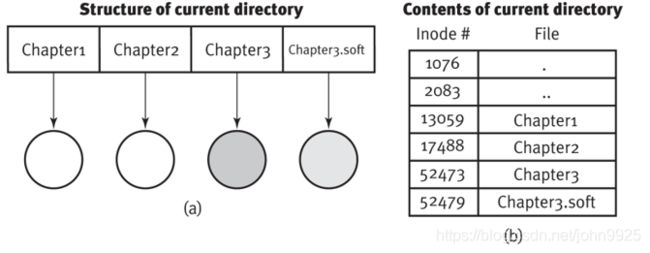
硬连接缺点:而软链接可以
无法跨分区创建
无法链接目录
旧文件删除后,硬链接的新文件还可以访问,软链接的新文件不行(因为软连接本质是访问旧文件)。
Linux 9 进程
ps命令
ps -l看自己bash相关进程
-e所有进程
-u user看user用户的进程
内部命令执行不创建进程,外部命令执行时会创建
nice值
nice value越低越优先 值在-20~19之间
设置nice值
nice -n 值 进程
普通用户只能设置 >0 的值降低优先级
其他命令
type 命令看命令是内部还是外部命令
top实时看进程信息
pstree看进程树
进程切换
在最后加 &改为后台进程,fg切换为前台,bg切换为后台
(前台运行时不读取任何命令)
(后台运行时可以输入命令,此时前台是shell)
ctrl z进程暂停 ctrl c进程终止
在暂停状态切换为前台/后台可以恢复运行
jobs -l 看进程状态

[]内是任务号,25944是进程id
+表示刚才操作的进程,-是上一个操作的进程。
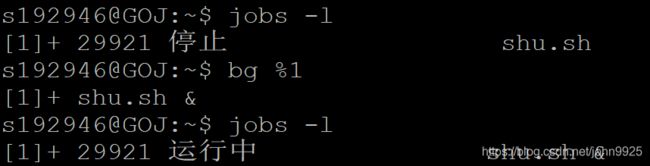
fg %任务号(任务号就是[]内数字),切换到前台
不加%的话默认对最近操作的进程操作
命令的顺序和并行执行
命令;命令;命令依次执行命令
命令&命令&命令同时执行
(命令;命令)> file 使用命令组,让两个命令同一环境(同一个进程)
A daemon is a system process running in the background
Used to offer various types of services to users and handle system administration tasks
命令和进程异常终止
kill -信号量 进程id/文件名不加选项默认发送15信号量,使进程退出。但可能被恶意屏蔽掉
信号量9,必杀
killall 进程id/文件名

nohup 命令使进程忽略信号量1
比如nohup /tmp/count &
exit后shell停止,shell会给子进程发送1信号量关闭。设置进程为后台执行,且使用nohup后,即使exit了,该后台进程也会继续执行。
crontab与at 定时操作
at只会一次性,而crontab是循环


两种方式设置以后都是发邮件,邮件有命令执行结果
at
s192946@GOJ:~$ at 17:33
warning: commands will be executed using /bin/sh
at> ls
at> <EOT>
job 50 at Sun Jun 27 17:33:00 2021
s192946@GOJ:~$ at -l
50 Sun Jun 27 17:33:00 2021 a s192946
crontab
crontab 是一个文件,在文件内编辑想要的设置。
![]()
每个位置的解释如下:

* 取值范围内的所有数字
/ 每过多少个数字
- 从X到Z
,散列数字
例子:
每周5 11:00 执行ls命令
00 11 * * 5 ls
每分钟执行 ls
* * * * * ls
在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup:
0 6-12/3 * 12 * /usr/bin/backup
Linux 11 打包
tar命令
首先要弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件。
为什么要区分这两个概念呢?这源于 Linux 中很多压缩程序只能针对一个文件进行压缩,这样当你想要压缩一大堆文件时,你得先将这一大堆文件先打成一个包(tar命令),然后再用压缩程序进行压缩(gzip bzip2命令)。
tar 打包
-j bz2解压
-z 用gz解压
-x 释放
-c 创建打包文件
-v:显示操作过程
-t或--list:列出备份文件的内容
-f 指定文件
-z 用gz压缩
-j 用bz2压缩
//注意顺序不要乱,v加不加都可,加了会显示包内容
-jcvf 创建
-jtvf 查看tar压缩包内容
-jxvf 释放
以上三个都是对bz2文件的操作,如果要对gz文件,把j换成z
wget 链接 通过连接下载东西
例子
tar -jcvf log.tar.bz2 log2012.log打包后,以bz2压缩
Linux 12 shell 脚本编程
nano用法:写完以后,ctrl+o ,回车,ctrl+x退出。
.sh 以sh结尾的文件就是shell脚本
执行命令
source 或者 . file直接读入脚本并执行,而不是产生一个子进程来执行bash 或者 sh file调用子进程执行./file当前路径使用bash执行脚本,所以也是调用子进程执行
前2个都可以直接执行,最后一个要先添加权限chmod +x file。
指定解释器
可以在脚本最前面加入
#! /bin/sh
比如希望用python3.8解释
#! /usr/bin/python3.8
然后就可以./file 执行了,否则默认使用bash执行
是指此脚本使用/bin/sh来解释执行,#!是特殊的表示符,其后面跟的是此解释此脚本的shell的路径。
变量
变量赋值
变量名=值 为变量赋值,注意等号两端不可有空格
也可以 变量名1=值1 变量名2=值2 变量名3=值3 。。。。。每个赋值以空格分隔
echo $变量名 输出变量的值
a=1 默认a是字符串
实现两个变量(整型)的运算
echo $((a+b))
expr $a + $b 注意加号两端空格,这个是命令,会直接输出值,可以用反撇赋值给变量。如果不加expr会认为两个字符串拼接
+ - \* /整除
声明变量
declare -i 变量名 声明变量为整型
-a 数组
-f 函数
转为全局变量
export变量 把变量变为环境变量(全局变量)
注意
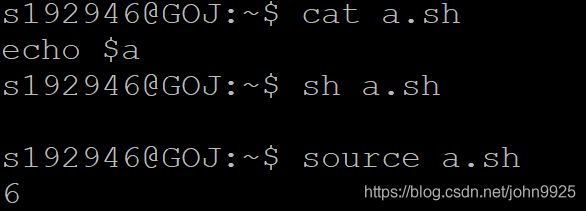
调用子进程执行脚本会复制一份(!所以子进程修改不会影响到父)父进程的环境变量,而用户自定义变量不会复制。(所以在脚本中加echo用户变量,然后用️2方法执行,会无法输出,因为子进程无这个用户变量)
解决办法:
1.把用户变量转为全局变量,export一下
2.使用1方法执行脚本
如下变量a是我一早就创建的。
清空(删除)变量
unset 变量名
只读变量
readonly 变量名 (设置变量为只读,不可修改)
只读shell变量
脚本中使用这些变量。这些变量会从命令行中读入。(命令行从键盘输入的数)
$0 脚本文件名
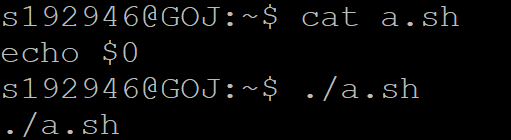
$1-9 参数。 比如 a=$1
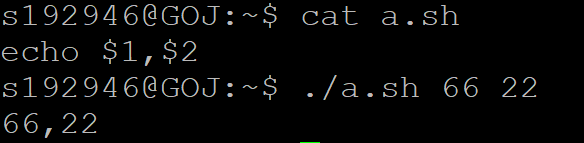
$* 和 $@。 表示读入所有参数 如 ./arg.sh a b c d
前者“a b c d”强调整体 -------- 后者“a”“b”“c”“d” 强调独立
使用for的时候就可以看出来了,前者是一整块,后者是一个一个值
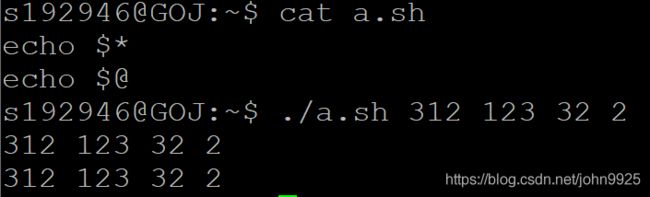
$#后面参数个数
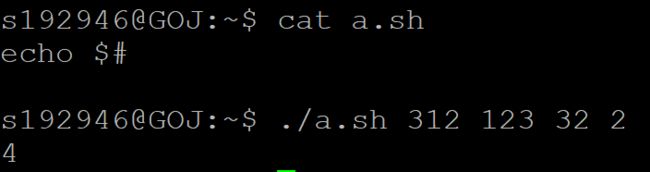
$$ 当前shell进程的进程id
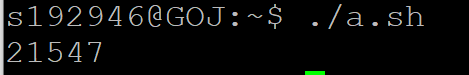
$? 最近一个程序的退出时返回值
成功使用命令后 $?一般为0
比如使用grep后,如果什么都没有,返回值就是非0 . 找到东西返回值就是0
$! 最近一个切换到后台的进程id
命令替换
把命令执行结果赋值给变量
- 变量=`命令` (使用反撇号围起来)
- 变量=$(命令)
输入输出
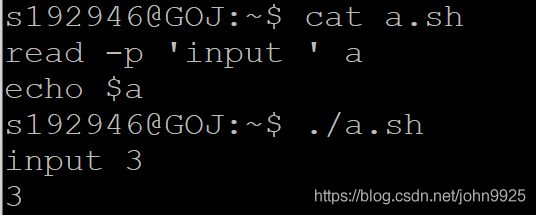
读入
read 变量1 变量2 从键盘读入变量的值
-p '增加提示语'
输出
echo $变量
-n不要默认换行符,否则两个echo输出内容换行
-e使""中转义字符有效

注意
假如只有两个变量 a b
但是读入的时候输入了x y z三个字符串
则a是x
b是 y z
解决办法是在b后面多加个other (随便加个变量)
注释
#注释内容
选择分支
注意:
当输入的变量是字符串时,如果字符串含有空格,必须用双引号"$var"避免判断的时候把空格后的字符串用来判断
read a
if [ $a = "good" ] 如果在这里加then 要 ;then
then
echo "2"
elif [ $a = "bad" ]
then
echo "1"
else
echo "0"
fi
注意
1.[]里两端都需要空格
2.记得加then 最后一个else不用加
3.结尾记得加fi,表示结束
4.注意表达式中的$变量,是直接把变量的值替换过来,如果变量是字符串 x="aaa bbb"
if 中我写$x = "aaa bbb"会被判断为flase 说表达式过多
此时把"$x" = "aaa bbb" 就会判断为true了。“”可以避免空格的问题
扩展
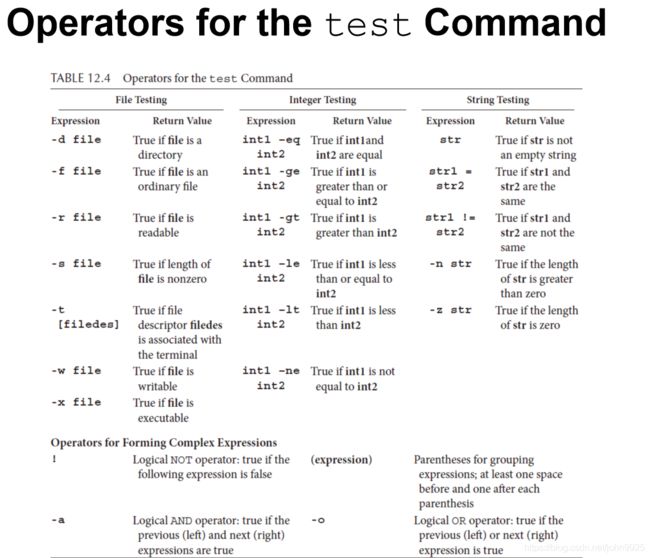
1.[]可替换成test express 注意express两侧不要加括号
2.可以在脚本最后加exit 0 表示正常退出 。exit 1 返回1并退出脚本(可以表明发生异常)
循环
for循环
in后面是参数列表,name是变量
如果把in后面的参数列表去掉,就是取前端命令行的参数,实现对命令行参数的遍历
for name in marry jack tom
do
echo $name
done
注意
1.用do done环绕
2.name是变量,输出的时候记得$
while语句
while 【 express 】
do
…
done
读入文件的每一行
cat file |
while read line
do
.....
done