win10 Tesseract-ORC安装教程以及使用案例(pdf拆分)
简介
OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修改bug、优化,重新发布。
下载
1、 Windows版本tesseract各版本下载T,本教程用的版本是tesseract-ocr-setup-4.00.00dev.exe(【注意】要3.0以上才支持中文)
2、 各版本对应字库,要识别简体中文需要下载chi_sim.traindata字库(【注意】根据版本下载对应字库)。
安装好tesseract后,可下载中文包
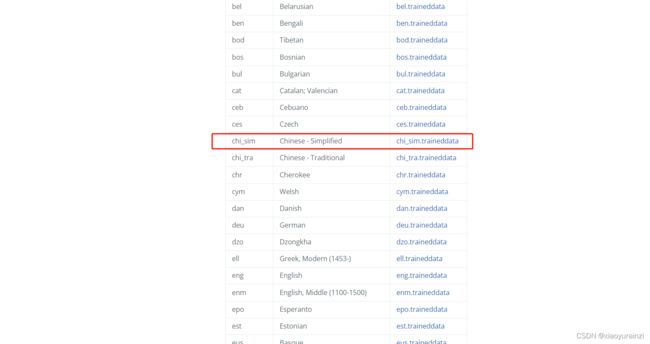
下载好中文包后,将文件放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下

安装
1 点击tesseract-ocr-setup-4.00.00dev.exe文件,按提示安装就行,安装成功之后如下张图:

2 在cmd窗口输入tesseract -v,配置成功如下图:

3 查看支持的语言类型:
1 将目录cd 到:
cd C:\Program Files (x86)\Tesseract-OCR
2 输入指令:
tesseract -v tesseract --list-langs -v tesseract --list-langs # 查看Tesseract-OCR支持语言,结果如图所示:

环境配置
1 增加一个TESSDATA_PREFIX变量名,变量值为我的语言字库文件夹安装路径C:\Program Files (x86)\Tesseract-OCR\tessdata 添加到变量中;如下图:

2 增加一个OCR_HOME变量名,变量值C:\Program Files (x86)\Tesseract-OCR;如下图:

3 在path中添加如图所示两个值

4 配置tesseract运行文件
...\Lib\site-packages\pytesseract\pytesseract.py
找到文件:tesseract_cmd = 'tesseract'
修改为:tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe' 你放tesseract.exe的路径
使用
Tesseract-ORC文字识别是配合着pytesseract模块使用的
pip install pytesseract
代码示例:
实现批量的根据关键字对pdf进行拆分的功能(这里的pdf为扫描件pdf):
from PIL import Image
import os
import pytesseract
import cv2 as cv
import fitz
def pdf_image(pdfPath,imgPath,new_pdf_file_path,keywords,zoom_x=2,zoom_y=2,rotation_angle=0):
"""
:param pdfPath: 需要处理的.pdf文件所在文件夹的位置
:param imgPath: .pdf转成图片后图片的保存路径
:param new_pdf_file_path: 新产生的.pdf所在文件夹的位置
:param keywords: 关键字
:param zoom_x:
:param zoom_y:
:param rotation_angle:
:return:
"""
file_list = [] # 新建一个空列表用于存放文件名
file_dir =pdfPath
for files in os.walk(file_dir): # 遍历指定文件夹及其下的所有子文件夹
for file in files[2]: # 遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
if os.path.splitext(file)[1] == '.PDF' or os.path.splitext(file)[1] == '.pdf': # 检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
# print(file_list)
# 创建存储图片的文件夹 D:\Users\admin\Desktop\save\img
if not os.path.exists(os.path.dirname(imgPath)):
os.mkdir(os.path.dirname(imgPath))
# 创建存储拆分后新pdf的文件夹 D:\Users\admin\Desktop\save\new_pdf_result
if not os.path.exists(new_pdf_file_path):
os.mkdir(new_pdf_file_path)
for file_path in file_list:
pdf = fitz.open(file_path) # 打开PDF文件
png_files = []
sources = []
# 逐页读取PDF
for pg in range(0, pdf.page_count):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).prerotate(rotation_angle)
pm = page.get_pixmap(matrix=trans, alpha=False)
# 开始写图像
pm._writeIMG(imgPath + str(pg) + ".png", 1)
# 依赖opencv
img=cv.imread(imgPath+str(pg)+".png")
text=pytesseract.image_to_string(Image.fromarray(img),lang='chi_sim')
# text = pytesseract.image_to_string(Image.open(imgPath +str(pg)+ ".png"), lang='chi_sim')
print(text)
# 将多个图片合并成一个pdf
if keywords in text:
png_files.append(imgPath+str(pg)+".png")
pdf.close()
if png_files:
png_files.sort()
output = Image.open(png_files[0])
png_files.pop(0)
for file in png_files:
png_file = Image.open(file)
if png_file.mode == "RGB":
png_file = png_file.convert("RGB")
sources.append(png_file)
# output.save(new_pdf_path, "pdf", save_all=True, append_images=sources)
new_pdf_path = os.path.join(new_pdf_file_path, os.path.basename(file_path))
output.save(new_pdf_path, save_all=True, append_images=sources)
pdf_path =r'D:\Users\admin\Desktop\new_pdf'
# keywords='中 国 证 券 期 货 市 场 衍 生 品 交 易 主 协 议'
keywords='中 国 证 券'
img_path =r'D:\Users\admin\Desktop\save\img\test'
new_pdf_file_path=r'D:\Users\admin\Desktop\save\new_pdf_result'
pdf_image(pdf_path,img_path,new_pdf_file_path,keywords)
可能遇到的问题有:
运行项目时,报错无法打开C:\Program Files (x86)\Tesseract-OCR\tessdata里面的中文包
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files\\Tesseract-OCR\\tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
解决方案:
项目环境配置添加TESSDATA_PREFIX=C:\Program Files (x86)\Tesseract-OCR\tessdata
如图所示:

参考资料:
Tesseract-OCR 安装、中文识别与训练字库
在window下搭建Tesseract-OCR图片识别文字环境变量
OCR识别扫描版PDF文件(Python版)
基于Python的PDF扫描文件OCR识别
如何使用Python进行PDF图片识别OCR
Please make sure the TESSDATA_PREFIX environment variable is set to your “tessdata“ directory.
解决pytesseract.pytesseract.TesseractError: (1, ‘Error opening data file C:\Program Files\Tesseract-
OS库应用之遍历文件夹的pdf文件,批量解析然后归档