Python实现股票数据接口
资源下载地址:https://download.csdn.net/download/sheziqiong/85984124
资源下载地址:https://download.csdn.net/download/sheziqiong/85984124
这篇文章主要介绍如何使用 Python 股票数据和实现数据接口。
1.定时抓取和解析数据
2.存储数据到 MongoDB
3.缓存数据到 Redis
4.配置 Nginx 和数据接口
1.定时抓和解析数据
按照链接的格式,我们拼接好股票代码、年份和季度:
url = "http://quotes.money.163.com/trade/lsjysj_" + key + ".html?year=" + year + "&season=" + season
拼接好链接后,使用 requests 库获取页面的内容:
requests.get(url)
self.parse_pager(content.content, item["code"])
考虑到网络请求可能会失败,我们在请求失败时设置多次重新请求(最多 8 次),如果多次请求后仍然失败,则将请求的相关内容存储到 error_logs 中:
# 请求失败后重新请求(最多8次)
max_try = 8
for tries in range(max_try):
try:
content = requests.get(url)
self.parse_pager(content.content, item["code"])
break
except Exception:
if tries < (max_try - 1):
sleep(2)
continue
else:
add_error_logs("crawl_error", "501", key)
获取到页面内容后,我们先来分析页面结构(图 1),我们需要的数据大概是以这样的格式存在的:tr 标签表示股票某一天的行情,tr 标签下的 td 标签表示当前行情的详细数据:
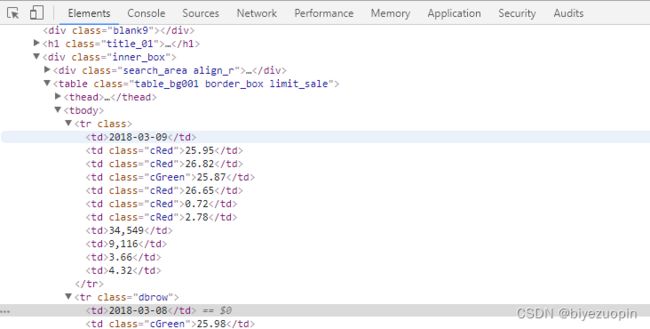
使用 BeautifulSoup 库对页面进行解析,soup.select(“div.inner_box tr”)会以列表的形势返回 div.inner_box 下的所有 tr 标签:
soup = bs4.BeautifulSoup(content, "lxml")
parse_list = soup.select("div.inner_box tr")
[x.string for x in item.select(“td”)]会将 tr 标签下的内容组合成一个数组 data,这个数组就是我们要抓取的数据:
data = [x.string for x in item.select("td")]
每次解析页面时,我们都会从数据库中取出当前股票已经存在的数据,用于判断待插入数据是否已经存在数据库中。这样做可以及时补全数据,并且避免数据重复插入。
if price["cur_timer"]not in timer_list:
self.dm.add_tk_item(key, price)
由于股票数据是频繁变动的,这就要求我们定时对数据进行更新,这里我们编写一个定时器来实现定时更新数据的功能:
timer = threading.Timer(time_interval, fun_timer)
timer.start()
我们设置每天 16 点更新数据:
if (hour =="16" or hour =="20")and minute =="00":
dc = ENDataCrawl()
dc.start_crawl()
sleep(time_interval)
rm = RedisManager()
rm.update_data()
2.存储数据到 MongoDB
这里我们使用 MongoDB 来存储数据,MongoDB 作为一个面向文档存储的数据库,操作起来相对比较简单和容易。在编写代码之前,我们需要先进行安装 MongoDB 安装教程,此外 python 操作 MongoDB 需要用到 pymongo 库,命令行下输入 pip install pymongo 安装即可。
安装完成后,我们开始编写 MongoDB 相关的代码,新建 DBManager 类用于管理数据库相关操作:
class DBManager:
def __init__(self, table_name):
# 指定端口和地址
self.client = MongoClient(mod_config.get_config("database", "dbhost"), int(mod_config.get_config("database", "dbport")))
# 选择数据库
self.db = self.client[mod_config.get_config("database", "dbname")]
self.table = self.db[table_name]
在 DBManager 类中,我们最常用到的有 add_tk_item 方法,这个方法会根据 tk_code(股票代码),将最新的数据插入到 price_list 中。
def add_tk_item(self, tk_code, price_item):
return self.table.update_one({'code': tk_code}, {"$push": {"price_list": price_item}})*
以及 find_by_id 方法,这个方法会根据 tk_code 查询相应的股票信息。当我们需要对 Cursor 进行长时间循环遍历时,应该将 no_cursor_timeout 设置为 true。
def find_by_id(self, tk_code, request={}):
if tk_code:
request["code"] = tk_code
return self.table.find_one(request)
else:
# 数据量较大时避免CursorNotFoundException
return self.table.find({}, no_cursor_timeout=True)*
3.缓存数据到 Redis
为了提升响应速度,我们使用 Redis 对数据进行缓存,Redis 作为一个 key-value 存储系统,具有极高的性能。跟之前一样我们需要先安装 RedisRedis 安装教程,然后为 python 安装 Redis 库,使用 pip install Redis 命令。
接下来我们创建 RedisManager 类用于管理 Redis 的相关操作:
class RedisManager:
def __init__(self):
self.pool = redis.ConnectionPool(host=mod_config.get_config("redis", "redis_host"), port=mod_config.get_config("redis", "redis_port"), decode_responses=True)
self.r = redis.Redis(connection_pool=self.pool)
update_data 方法用于将 MongoDB 的数据同步到 Redis,每次系统执行完爬取业务后都会调用该方法:
def update_data(self):
# 将mongodb中的数据同步到redis中
dm = DBManager("tk_details")
code_list = dm.find_by_id("")
for item in code_list:
try:
code = item["code"][:6]
_result = dm.find_by_id(item["code"])
sorted_result = sorted(_result["price_list"], cmp=cmp_datetime, key=operator.itemgetter("cur_timer"))
self.r.set(code, sorted_result)
except Exception:
add_error_logs("redis_error", "501", item["code"])
continue
4.配置 Nginx 和数据接口
由于我们只有一个简单的数据接口,所以选择使用 Nginx,Nginx 作为一个高性能的 Web 和反向代理服务器,具有简洁高效,占用资源少等优点。考虑到很多开发者习惯在 Windows 下调试代码,我们先在 Windows 系统中安装 Nginxwindows 下安装 nginx(Windows 下 Nginx 是以应用的形式运行的,这可能也是很多人不愿意在 Windows 下运行 Nginx 的原因)。
配置好 Nginx 后我们开始编写数据接口,start_api_tkdata 方法会开启一个监听,用于响应 Nginx 的请求:
def start_api_tkdata():
WSGIServer(myapp, bindAddress=(mod_config.get_config("server", "server_host"), int(mod_config.get_config("server", "tk_data_port")))).run()
myapp 方法每次收到请求时,都会对请求的格式和参数进行校验,校验通过后则从 Redis 中获取数据以 JSON 格式返回。
start_response('200 OK', [('Content-Type', 'text/plain')])
result_json["data"] =str(result).replace("u'", "'")
result_json["tk_code"] =str(list_query[i +1])
return [json.dumps(result_json)]
编写完数据接口后,我们在本机启动 Nginx,在浏览器中输入 http://127.0.0.1/tkdata?code=600008,可以看到如下结果(图 2):
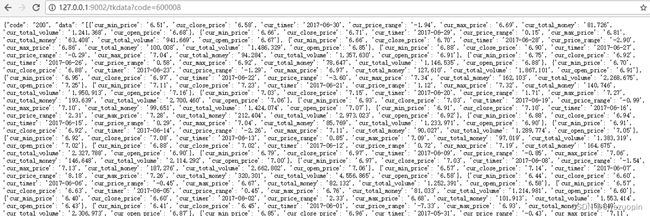
到此为止,我们的股票爬虫和数据接口就已经完成了,我们还可以在现有的基础上做一些优化,例如:
1.爬取数据时使用多线程和多进程。
2.添加更多的数据接口,添加均线、Macd、Boll 等指标数据,这些数据可以由收盘价计算得到。
3.添加数据检测和日志管理模块,如果你打算将这套系统用在生产环境中,这些模块是必须要有的。
资源下载地址:https://download.csdn.net/download/sheziqiong/85984124
资源下载地址:https://download.csdn.net/download/sheziqiong/85984124