京东商品数据数据爬取
content
-
- 要求
- commodity
- mysql
要求
以饮料这一品种为例,获取10个页面的商品信息。具体包括详情页中的商品名称、价格、商品介绍(包括图片)、规格包装

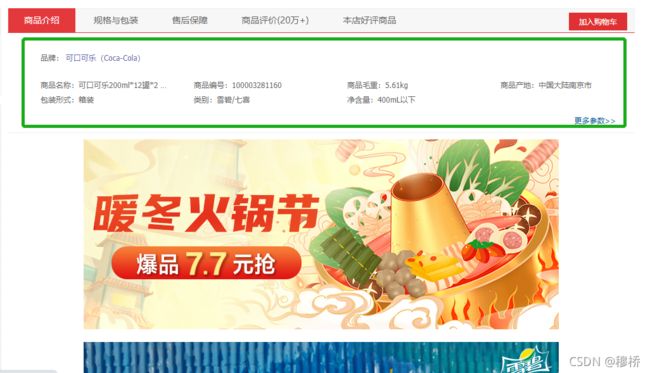

数据库字段要求

commodity
import requests
from scrapy import Selector
import requests
import json
import re
import mysql
import time
import threading
#import datetime
def get_proxy(website):
while True:
resp = requests.get(f'http://proxy.aigauss.com/proxy/next/{website}')
try:
j = resp.json()
p = f'{j["ip"]}:{j["port"]}'
print('使用代理 %s' % p)
return {
'http': p,
'https': p
}
except:
print(f'获取代理异常: {resp.text}')
time.sleep(2)
def request_get(url):
"""
通用请求
:param url:
:return:
"""
payload = {}
headers = {
'authority': 'p.3.cn',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'accept': '*/*',
'referer': 'https://search.jd.com/',
'accept-language': 'zh-CN,zh;q=0.9',
# 'Cookie': 'token=0af978cad27e9de4ef38e1d557b933c9,1,909184'
}
# 动态网页访问还是看一下postman就算请求内容不要经过js渲染
proxies=get_proxy('jd') #获取百度代理
response = requests.request("GET", url, headers=headers, data=payload,proxies=proxies)
return response.text
def get_list(page):
url="https://search.jd.com/Search?keyword=饮料&qrst=1&stock=1&pvid=d9f1f93b10b84ccbb39ffc80192158e8&" \
"page={}&s=1&click=0".format(page)
res=request_get(url)
res=Selector(text=res)
lst = []
for li in res.xpath('//div[@id="J_goodsList"]//li'):
dic = {}#放在循环外面 全部重复
print(li)
dic['sku'] = li.xpath('.//@data-sku').get()
dic['spu'] = li.xpath('.//@data-spu').get()
lst.append(dic)
return lst
def get_pic(sku,spu):
'''
获取详情页图片信息
:param sku:
:param spu:
:return:
sku spu中spu为空,分析发现其中spu==sku 除此之外有少量不等的情况忽略
'''
if spu == '':
print("spu is null",sku)
spu=sku
#return []
url = "https://cd.jd.com/description/channel?skuId={}&mainSkuId={}" \
"&charset=utf-8&cdn=2&callback=showdesc".format(sku, spu)
imgcon=request_get(url)
doc = imgcon[9:-1]
# print(res)
#print("url{}",url)
print("doc[:10]{}".format(doc[:10]))
doc = json.loads(doc)
htmlc = doc["content"]
res=Selector(text=htmlc)
print(imgcon)
lst = []
try:
imgcon = res.xpath("//style/text()").get()
image_row = re.compile(r'\.ssd-module-wrap \.(.*?)\{.*?\((.*?)\)')
image_info = re.findall(image_row, imgcon)
for image in image_info:
item = {
'image_id': image[0],
'image_url': 'https:' + image[1]
}
lst.append(item['image_url'])
except TypeError:
# 访问异常的错误编号和详细信息
for i in res.xpath("//img//@data-lazyload"):
img_link = "https:" + i.get()[2:-2]
lst.append(img_link)
except Exception as e:
print(e.args)
return lst
def basic_info(sku):
'''
获取详情页商品介绍+价格+商品名称信息
:param sku:
:return:
'''
url1 = "https://item.jd.com/{}.html".format(sku)
url2 = "https://item-soa.jd.com/getWareBusiness?skuId={}".format(sku)
res = request_get(url1)
res = Selector(text=res)
#获取商品介绍
print(url1)
name = ""
try:
for i in res.xpath('//div[@class="sku-name"]//text()'):
# 在名称前面有多个image 文字取最后一个
name=i.get().strip()
print(name)
except AttributeError:
name = res.xpath('//div[@class="sku-name"]//text()').get().strip()#else:针对except
if name == "":
print("name is null ",url1)
lst = []
# 品牌和其他属性介绍所在标签不同
brank=res.xpath('//div[@class="p-parameter"]//li//text()').get()
brank=res.xpath('//div[@class="p-parameter"]//li//a//text()').get()+brank
lst.append(brank)
for li in res.xpath('//div[@class="p-parameter"]//li'):
str=li.xpath('.//text()').get()
print(str)
lst.append(str)
intro=';'.join(lst)
#获取商品信息 包装规格等
dic={}
for dl in res.xpath('//div[@class="Ptable-item"]/dl/dl'):
keys=dl.xpath('.//dt//text()').get()
values = dl.xpath('.//dd//text()').get()
dic[keys]=values
# 获取商品价格
res = request_get(url2)
price = json.loads(res)["price"]["p"]
return name,price,intro,dic
def get_page(i):
lst = get_list(2 * i - 1)
for dic in lst:
try:
data = {}
data['pic'] = str(get_pic(dic['sku'], dic['spu']))
name, price, intro, size2pack = basic_info(dic['sku'])
# mysql要输入字符串
data['name'], data['price'], data['intro'], data['size2pack'] = name, price, str(intro), str(size2pack)
print(data)
mysql_client.insert_one('jd', data)
except Exception as e:
print("{}".format(repr(e)))
if __name__ == "__main__":
conn, cur = mysql.mysql_conn()
mysql_client = mysql.MysqlORM(conn, cur)
for i in range(11):
get_page(i)
mysql
import pymysql
from pymysql.cursors import DictCursor
def mysql_conn():
"""开发连接库"""
_conn = pymysql.connect(
host='localhost',
user='root',
passwd='123454321',
database='practice',
port=3306,
charset='utf8mb4'
)
_cur = _conn.cursor(DictCursor)
return _conn, _cur
class MysqlORM(object):
def __init__(self, conn, cur):
self.conn = conn
self.cur = cur
def insert_one(self, table: str, data: dict):
name = ','.join(data.keys())
print(name)
col = ','.join('%({})s'.format(k) for k in data.keys())
print(col)
sql = f'insert ignore into {table}({name}) values({col})'
self.cur.execute(sql, data)
self.conn.commit()
rowid = self.cur.lastrowid
print(f'{table} 插入一条数据 {rowid}')
return rowid
def update_one(self, table: str, data: dict, fixed: list):
fileds = [f'{name}=%({name})s' for name in data.keys() if name not in fixed]
where_phrase = [f'{name}=%({name})s' for name in fixed]
where = ' and '.join(where_phrase)
update_sql = f'update {table} set {",".join(fileds)} where {where}'
self.cur.execute(update_sql, data)
self.conn.commit()
print(f'{table} 更新一条数据到 {table} 成功')