顶会论文分析:知识图谱增强语言模型或是未来的发展趋势!
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要33分钟
跟随小博主,每天进步一丢丢



文 | Michael Galkin
源 | AI科技评论
在EMNLP 2020的论文投递中,知识图谱的研究热度不减,并成为继续推动NLP发展的重要动力之一。
在EMNLP 2020中,知识图谱领域有了哪些最新研究进展呢?作者从中选出了30篇文章,对未来2-3年知识图谱的研究趋势进行分析。让我们一起来看看!
知识图谱增强的语言模型:赋能Transformer
在EMNLP 2019中,以结构性知识增强的语言模型表现突出。
EMNLP 2019与2020均出现了许多包含Wikipedia或Wikidata实体的语言模型,但这里仍存在一个概念性问题:
我们应该如何衡量编码在语言模型参数中的“知识”?
一些初始尝试的LAMA benchmark,如与UCL合作的论文“Language Models as Knowledge Bases”将这个问题定义为:从Wikidata提取并进行单个token完型填空的事实匹配。比如,“iPhone是根据____设计的。”(答案自然是:苹果)
语言模型展示了一些事实性知识的概念,但展示的既不全面、也不深刻。因此,LAMA仍是局限于:1)single-token;2)只限于英语。
那么,我们能覆盖更复杂的任务和多样化的环境吗?能!
基于在XTREME等多语言基准中所取得的最新成果,CMU在读博士生江政宝(本科与硕士就读于中国人民大学,师从窦志成与文继荣)等人提出X-FACTOR模型,针对多语言模型是否能够展示一定的事实性知识进行了研究。

论文链接:
https://arxiv.org/pdf/2010.06189.pdf
X-FACTR是一种多语言基准,包含了23种语言的完形填空式问题,具有多个token空白处(达到5-10个)。作者针对X-FACTR探索了M-BERT,XLM和XLM-R,研究的主要发现为设计和训练知识丰富的语言模型提供了更大的发展空间:
在高资源语言中,多语言模型的准确度几乎很少达到15%,在低资源语言中甚至只有约5%。
M-BERT似乎比规模更大的XLM和XLM-R包含了更多的事实性知识。
Multi-token预测与single-token预测更难,针对此类实体,需采用non-trivial解码策略。
多种语言几乎无法对事实的有效性()达成共识。比如说,同样是“瑞士以___命名”,英语问题 “Switzerland was named after _” 和俄语问题 “Наименование Швейцарии восходит к _” 所给出的答案完全不同。
看到最新的 mT5(multilingual T5)和 M2M-100 在X-FACTR上的探测结果确实非常兴奋。不妨留言,预测一下基准多久会达到饱和状态。
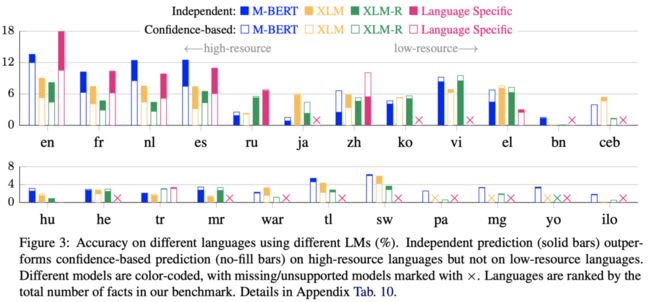
总的来说,多语言语言模型大约仅能恢复15%的用英语描述的事实,对其他语言的事实恢复则低于10%。
语言模型中的实体表征
EMNLP 2020中出现了四种语言模型实体表征的新方法!
方法一:
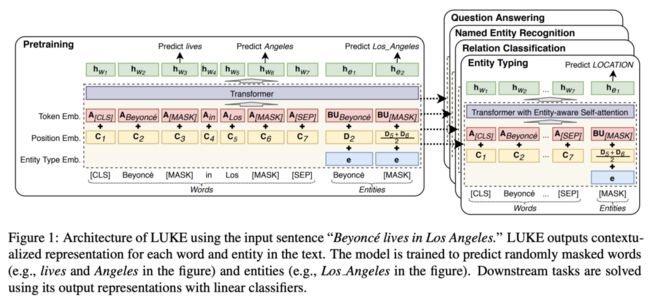
Ikuya Yamada等日本科研者在论文“LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention”中提出了一种具备预训练任务的Transformer模型——LUKE(基于知识嵌入的语言理解):MLM +预测文档中的被掩盖的实体(参见下图)。MLM + predicting masked entities within a document

作者保持一个实体嵌入矩阵(500K不同的实体),又添加了实体感知(entity-aware)的自注意机制。这个自注意机制在本质上是三个查询矩阵,取决于所计算的token类型(单词-实体,实体-实体,实体-单词)。一个简单的扩充就可以实现新的下游任务,并且相对于RoBERTa和最近的KG增强基线略微改进。
论文地址:
https://arxiv.org/pdf/2010.01057.pdf
方法二:
Thibault Févry等人在论文“Entity as Experts: Sparse Memory Access with Entity Supervision”中介绍了一个12层的Transformer模型—— Entities as Experts (EaE) :首先是像平时一样工作的4层,然后是从实体存储器中查询前100个带注释的实体的标记嵌入(token embeddings),最后是汇总嵌入通过8个Transformer层数。

论文地址:
https://arxiv.org/pdf/2004.07202.pdf
主要区别是EaE有三个预训练任务:指代探测+实体链接+vanilla MLM。EaE只需要在内部进行链接的、已注释的实体指代。使用基于BERT的110M初始设置,并添加1M x 256d实体,将产生总计约367M的参数(相当于BERT-Large的效果)。在LAMA探测中,EaE可以提高T-Rex任务的性能,同时又在TriviaQA和WebQuestions中保持与强大的T5-11B相当的竞争力。

方法三:
悉尼科技大学的在读博士生沈涛(本科就读于重庆邮电大学)利用背景KG的方式略有不同:在他们所提出的GLM模型(图形引导的屏蔽语言模型)中,图形提供了一张具有连接模式(k跳中的可到达实体)的命名实体词汇表。

论文地址:
https://arxiv.org/pdf/2004.14224.pdf
这张词汇表在两项预训练任务中得到利用:掩码实体预测(masked entity prediction) + 在存在干扰因素(如负面样本)的情况下对实体进行排名。KG帮助mask多信息实体、选择用于鲁棒性训练的hard negative samples。GLM的设计主要是用于常识性KG,比如ConceptNet、ATOMIC和与常识相关的任务,也可以附加本体KG。
方法四:
Nina Poerner等德国科研者在他们的E-BERT模型中充分使用了Wikipedia2Vec。这篇论文的主要观点是:vanilla BERT只训练单词嵌入,而Wikipedia2Vec同时训练单词和实体嵌入(270万个实体)。

论文地址:
https://arxiv.org/pdf/1911.03681.pdf
因此,我们首先学习BERT单词和Wikipedia2Vec单词之间的线性转换W,然后使用拟合参数W投映Wikipedia2Vec实体。最后,将一个实体与单词连接起来,例如:“Jean Mara的母语 ## is是[MASK]” 变成“ Jean_Marais / Jean Mara的母语 ##is 是 [MASK]”。这个过程中没有预训练任务。有趣的是,E-BERT-small 在LAMA探测上显示的结果要好于E-BERT-large。
自回归知识图谱增强语言模型
在自回归知识图谱增强语言模型中,语言模型的生成过程受到了结构化知识(如小型子图)的制约,或因为结构化知识变得更加丰富。
1、KGPT
来自加利福尼亚圣塔芭芭拉分校的Wenhu Chen(本科就读于华中科技大学)等人提出了一种用于数据到文本任务的生成模型——KGPT(knowledge-grounded pre-training,基于知识的预训练),以及一个庞大的新颖数据集KGText。

论文地址:
https://arxiv.org/pdf/2010.02307.pdf
他们的工作主要有三点贡献:
1)作者提出了一种对WebNLG、E2E NLG和WikiBio等各种数据到文本任务进行编码的通用格式,以作为语言模型的统一输入。
2)KGPT有两种编码器:一种是基于图注意力网络,一种是BERT-style,带有附加的位置嵌入式输入(参考以下插图)。本质上,你要将图形线性化为带有指针的序列,其中指针是实体、关系和full triples。解码器类似GPT-2,但具有复制机制。
3)KGText是一个新的预训练语料库,在这个库中,来自维基百科的英语句子与来自Wikidata的子图对齐,总共约有180万(子图,文本)对。作者等人确保每个子图及其成对的句子都描述几乎相同的事实。这是一个重大的贡献,因为以前的图形-文本数据集很小,并且包含一个受监督的设置。
将KGPT在KG Text上进行预训练后,KGPT在小样本和零样本场景中均展示了非常出色的性能,将 GPT-2 远远甩在后面。也就是说,不过5%的WebNLG(RDF到文本任务)训练数据就已经能够在小样本设置中产生40+ BLEU点,在完全零样本的设置中产生20+ BLEU点。

但笔者认为,KGPT仍存在两个缺陷:
1)KGPT依然缺少显式实体(每个实体嵌入是其子字单元的平均值)。而且,当编码一个给定的子图时,实体与文字之间没有区别。
2)需要在8个Titan RTX GPU上进行为期8天的预训练。当然,比在2048个TPU上进行30天的预训练略进步了一些。
2、来自清华大学的计昊哲(在读本科生)等人则采用了完全不同的方法:使用图形推理模块扩展解码器,使GPT-2编码器的GRF(Generation with Multi-Hop Reasoning Flow,具有多跳推理流程的生成)保持完整(请参考下图)。

论文地址:
https://arxiv.org/pdf/2009.11692.pdf
在处理与常识相关的任务和KG(如ATOMIC和ConceptNet)时,作者等人首先从输入文本中提取了由1-grams引出的k-hop子图。文本通过GPT编码器进行编码,而KG子图通过CompGCN进行编码。推理模块(本质上像消息传递)通过子图传播信息,并在各个实体上创建softmax分布以选择相关实体。最后,复制门(copy gate)决定是放置该实体,还是从词汇表中选择一个单词。
在故事结局生成、溯因推理NLG和解释生成等方向的实验证明,在自动衡量指标以及人工评估生成文本方面,各类GPT-2基线均有所提高。

3、MEGATRON-CTRL
来自英伟达的Peng Xu等人所创立的MEGATRON-CTRL(83亿参数)是这次会议中的重磅论文!

论文地址:https://arxiv.org/pdf/2010.00840.pdf
通过受控生成,我们不仅可以根据输入上下文来理解语言模型生成器,还可以使用能在特定方向上推动故事发展的一些关键字来进行调整。

在这个工作中,作者等人使用ConceptNet及其600K triples作为常识知识图谱和外部知识源。
首先,将关键字与triples进行匹配,然后通过通用语句编码器(USE)传递匹配好的关键字。另一方面,通过USE传递输入的上下文。最后,选择top-K最大内积向量。检索器使用负采样进行训练。
解码器是一个奇特的大型转换器(83亿参数),关键字生成器仅有25亿参数。培训只需要160辆Tesla V100。实验显示,这样的大型模型确实受益于背景知识,并且在AMT实验中更受人类欢迎。
NLG(数据到文本):Datasetlandia的新“伙伴”
EMNLP 2020 的主席曾说过,数据集并不是NLP研究领域里的“二等公民”。今年,我们看到了许多新的、大型的、设计良好的复杂任务/数据集,预计接下来会推动NLG的发展。
1、ENT-DESC
Liying Cheng(新加坡科技设计大学商业分析本科,机器学习博士生在读)等人提出了一个基于Wikidata的三元组到文本的数据集——ENT-DESC:给定主要实体的2-hop子图,主要任务是生成对子图的文本描述。

论文地址:
https://arxiv.org/pdf/2004.14813.pdf
ENT-DESC 在WebNLG中脱颖而出的原因主要有以下三点:
1)ENT-DESC 的规模非常大:包含110K 图形-文本对、超过11M的三元组、大约700K不同的实体以及1K不同的关系;
2)每个实体比例的三元组更高,但并非所有三元组都对生成的文本有利。比如,一些三元组其实是干扰项,模型应有足够的“鲁棒性”来消灭它们;
3)预期的描述比WebNLG的描述更长。
 MGCN模型的设计有点复杂:输入的多关系图形被划分为6个嵌入聚合的单关系图。这时候,为什么不直接采用像R-GCN或CompGCN之类的多关系GNN编码器呢?在WebNLG上探测时,MGCN的收益约为46.5个BLEU点,而前面提到的KGPT收益在65+以上。
MGCN模型的设计有点复杂:输入的多关系图形被划分为6个嵌入聚合的单关系图。这时候,为什么不直接采用像R-GCN或CompGCN之类的多关系GNN编码器呢?在WebNLG上探测时,MGCN的收益约为46.5个BLEU点,而前面提到的KGPT收益在65+以上。
但是,MGCN仍然为ENT-DESC展示了强有力的基线,因此,鼓励大家在新的数据集上展示他们的图幸到序列性能!
2、Logic2Text
来自UCSB的Zhiyu Chen等人提出了一个新的数据集:Logic2Text。这个数据集在逻辑上挑战了NLG系统的文本生成。必须注意的是:Logic2Text不仅是一个表格到文本的任务,而是一个拥有7种逻辑的复杂任务,包括计数、比较、最高级、聚合、大多数、唯一和有序。
 论文地址:
论文地址:
https://arxiv.org/pdf/2004.14579.pdf
该数据集包含约5000个表格和10700个(逻辑形式,文本)对。形式也很复杂,比方说,平均每个表单有9个节点和3个功能。作者等人在介绍数据集的过程中对构造与注释过程进行了全面介绍。
测试了几个生成基准后发现,居然是微调GPT-2的表现最佳。有趣的是,当去掉表格的标题时,质量下降超过30%。此外,Logic2Text 支持小样本设置,因此笔者假设,即使是更大型的Transformer也能执行零样本迁移。最后,你也可以反复执行某个任务,并使用这个数据集来训练语义解析器。

3、ToTTo
针对表格到文本,来自谷歌、佐治亚理工与CMU的Parikh等人介绍了一个包含了12万示例的大型数据集——ToTTo。这个数据集的任务是在给定一个表格和几个突出节点的情况下生成一个合乎情理的文本,比行到文本或列到文本更难。

论文地址:
https://arxiv.org/pdf/2004.14373.pdf
实验证明,合并了行/列的复杂表格结构(如下图所示)与non-trivial单元格突出显示,确实会使任务更加困难,并使模型看起来更具迷惑性。作者等人不仅详细描述了数据集的构建过程,在采用普通的BLEU指标之余,还采用了PARENT和BLEURT指标。

说到指标,大家还在用BLEU吗?如果你还在用,那真是落后了!
谷歌团队有篇工作被EMNLP 2020收录,里面提出了一种新的指标:KoBE(基于知识的评估)。

论文地址:
https://arxiv.org/pdf/2009.11027.pdf
他们的思维很简单:一是让实体提及链接到一些多语言知识图谱;二是衡量对比已知实体在候选对象与来源中的Recall。
多语言是大型知识图谱的常见属性,但为什么不利用多语言作为衡量指标呢?
作者等人使用“Google Knowledge Graph Search API”进行实体链接。在WBE19任务上探索KoBE时,他们发现KoBE指标比BLEU更接近人类的判断。
除了数据集,Martin Schmitt等德国科研者的论文工作也值得探讨:他们将Visual Genome(VG)构建成图形到文本的场景,并提出了一个VG子集——VGball(虽然VGball比WebNLG还要大200倍)。该子集也支持将任务翻转到反侧,并训练模型提取三元组、并直接从图像中构建知识图谱。

论文地址:
https://arxiv.org/pdf/1904.09447.pdf
实体链接:大规模、多语言
谷歌与Facebook在实体链接上表现积极,还启动了他们的TPU和HPC集群来实现大规模的多语言实体链接!
1、100种语言的实体链接
来自谷歌的研究人员Jan A. Botha等人在100种语言中对实体链接进行了研究。不谈别的,这项研究一上来就打破了“仅支持英语”的僵局,对NLP研究领域是一项重大突破!

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.630.pdf
大型知识图谱(比如Wikidata)在设计上是与语言无关的,因此,我们为什么不利用英语以外的其他语言数据呢?实际上,一些实体中甚至不存在英语标记与描述。
该团队首先对包含了684M提及的HUGE数据集进行挖掘(HUGE数据集覆盖了104种语言的20M Wikidata实体),并设计了Mewsli-9(一个仅包含82K实体的300K提及的轻量级测试数据集,实体为9种语言)用于评估实体链接的性能。
在模型方面,谷歌团队采用了双编码器,一个Transformer(通常是BERT)对提及进行编码,另一个Transformer对实体描述进行编码,并计算余弦相似度作为最终运算。使用mBERT checkpoints进行初始化后,将模型在TPU v3上进行几天的训练。实验证明,这个方法非常有效:在Mewsli-9上,最佳模型(具有智能训练增强功能)能够达到Recall @ 1为90%和Recall @ 10为98%的微平均水平。
2、Facebook实体链接器:BLINK
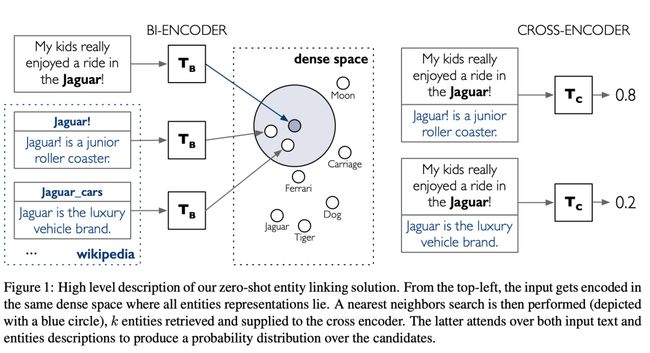
Facenbook的一个研究团队采取的方法略有不同:他们将英语版Wikipedia作为他们新的实体链接器BLINK中的背景KB和实体词汇。BLINK是专门为零样本设置创立的。

论文地址:
https://arxiv.org/pdf/1911.03814.pdf
BLINK也采用双编码器范式,但所有实体描述都是预计算,并储存在FAISS索引中(这些索引都是[CLS]嵌入)。上下文的实体提及(需要预先注释)通过另一个Transformer传递,产生的提及嵌入通过FAISS在索引中搜索top-K个最近邻居。最后,top-K选项通过交叉编码器进行排名。
实验证明:1)基于FAISS的检索器快速(〜2ms /查询)且准确(Recall @ 10> 90%),远远优于TF-IDF和BM-25;2)在零样本场景下,BLINK超过了所有基准线;3)即使只有1个CPU,推理速度也很快,因此你也可以将模型插入应用程序中!
3、ELQ
但是,BLINK需要带注释的实体提及。MIT与Facebook的合作团队在他们的论文中提出ELQ(Entity Linking for Questions,用于问题的实体链接),解决了这个问题。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.522.pdf
ELQ与BLINK驻留在相同的存储库中,因为它们可以完美互补。
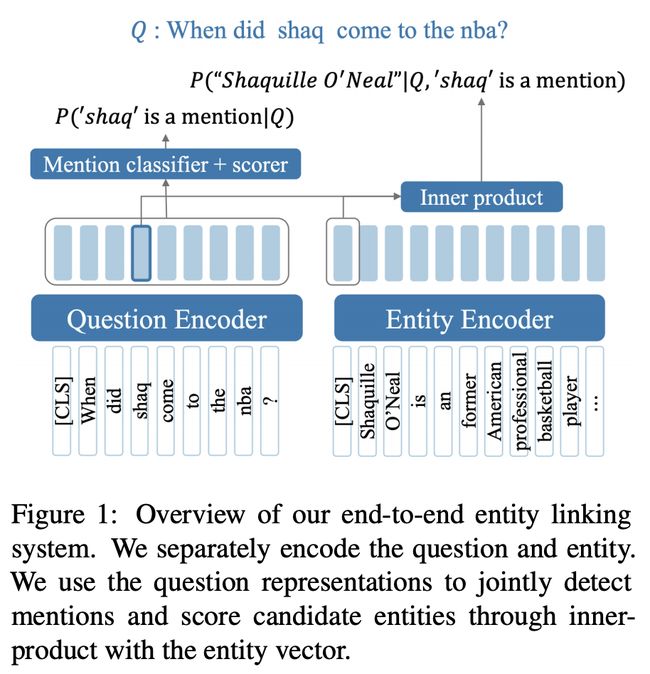
虽然ELQ的架构与BLINK相似,都是双编码器+ FAISS,但ELQ共同学习了提及检测和歧义消除,不要求输入注释!
此外,ELQ在实际应用中的表现也很出色:在QA数据集(如WebQSP和GraphQuestions)上,ELQ的表现优于TAGME和BLINK,并提高了大型QA数据集(如Natural Questions和TriviaQA)的准确性。
4、COMETA
来自剑桥大学与UCL的研究团队提出了一个医学实体链接语料库:COMETA。它的目标医疗知识图谱是SNOMED-CT。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.253.pdf
COMETA包含了2万个经过精心注释的实体提及(从Reddit中摘取),涉及约8000个SNOMED CT的通用概念和特定概念。
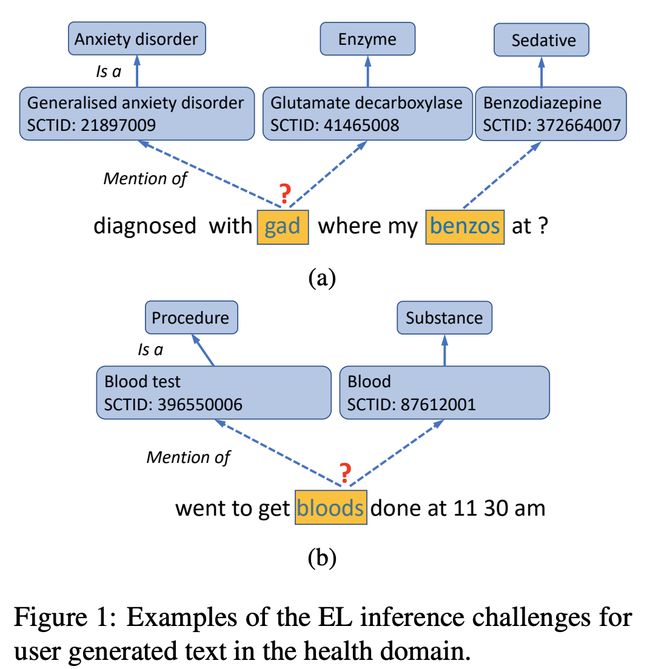
该研究团队探讨了20种基于规则与基于BERT的EL基准线,发现医疗EL任务仍然非常艰巨,尤其是在零样本设置中。
关系抽取:OpenIE 6与神经抽取器
OpenIE是现代NLP应用程序的基础框架,可使用开放模式(无背景本体)从文本中提取三元组。
1、OpenIE 6
在EMNLP 2020中,一个来自印度的研究团队介绍了OpenIE 6——基于他们的IE方法的下一代版本。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.306.pdf
与其他OpenIE相比,OpenIE 6的创新主要体现在:
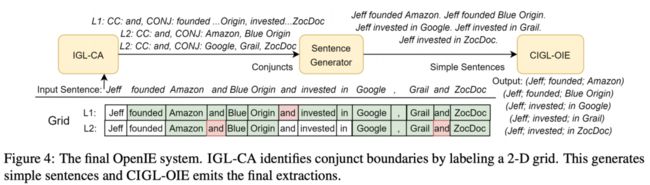
首先,OpenIE 6将三重提取构建为2-D(num_words x num_extraction)网格标记任务,使得每次提取的词都可以归类为“主语”、“谓语”、“宾语”或“无标记”。亮点是:该研究团队提出了一种基于BERT的迭代网格标签(Iterative Grid Labeling,IGL)系统,可以帮助执行2-D网格标签任务。也就是说,IGL有助于解析协调的连词(如下图的IGL-CA),并在三重提取过程(CIGL-OIE)中应用软约束。软约束与POS标签中的信号、头部动词覆盖率和排他性、附加到头部动词的提取计数等合起来,就是最终的损失函数。
实验表明,在多个基准测试中,OpenIE 6 比OpenIE 5 快10倍,性能也得到了显着且连贯的提升(约4个F1点)。你也可以用这4点来换更高的速度,不仅获得OpenIE 5级的性能,还能快50倍。
2、OpenIE神经架构系统研究
在这个话题上,来自剑桥大学与Serein AI的合作团队更进一步,进行了有关OpenIE神经架构的系统研究。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.690.pdf
该团队将典型的神经OpenIE架构分解为3个基本块:嵌入,编码和预测。在探究各种组合时,他们发现:LM上下文嵌入+ Transformer编码器+ LSTM预测器在OpenIE16基准上有了巨大的改进(提升200%)。此外,他们还提到,vanilla NLL损失可能更偏向浅层预测,应根据句子中宾语的位置进行适当调整。值得注意的是:尽管Transformer改善了数量,但在设计训练机制时仍需要考虑IE任务的本质。

3、DualTKB
IBM与AWS AI的合作团队提出了DualTKB模型,旨在以循环的方式从文本中学习图、以及从图中学习文本。为此,该模型可以从统一编码器中生成文本(比如翻译)和三元组(单跳路径)。

论文地址:
https://arxiv.org/pdf/2010.14660.pdf
具体而言,编码器将某些文本(选项A)或线性化三元组(选项B)作为输入,然后两个解码器分别生成文本(A)或另一个三元组(B)。也就是说,你可以有多种路线,例如A-B(从文本中提取三元组)或B-B(链接到预测)等。重复这个过程,你可以从文本中迭代提取更多三元组,或者对模型进行反向翻译。
在常识数据集上,DualTKB在完成知识图谱和文本生成上都展现了非常不错的结果(虽然GRU不知为何会优于BERT),还可以在WebNLG或其他带有并行注释的关系提取数据集上轻松尝试。
知识图谱表征学习:Temporal KGC与FB15K-237的“继承者”
EMNLP 2020收到了大约20篇关于知识图谱表征学习的论文,而相当一部分又是关于Temporal KG,比如有些工作研究时间印戳,阐明某个事实在特定的时间范围内有效,如(奥巴马,美国总统,2009年,2017年)。
我们需要在已知四元组/五元组剩余部分的情况下预测一个主语或一个宾语。几个重要的工作如下:
1、TeMP
来自加拿大Mila实验室的研究团队提出TeMP(Temporal Message Passing framework,时态消息传递框架),将结构化GNN编码器(使用R-GCN)与时间编码器配对。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.462.pdf
作者在实验中使用了时间编码器:GRU和自注意机制。也就是说,????的每个时间步都使用GNN编码,它们的输入也被馈送到时间编码器中。此外,附加的门控机制考虑到在特定时间范围内发生的实体的频率(例如,奥巴马在1900-1950年间很少被提及,而在2000-2020年间提及的次数则明显增加)。最终的实体嵌入在gating之后被计算出,并被馈送到解码器中(此处的解码器是ComplEx,虽然我认为KG嵌入家族中的所有评分功能都可以使用。
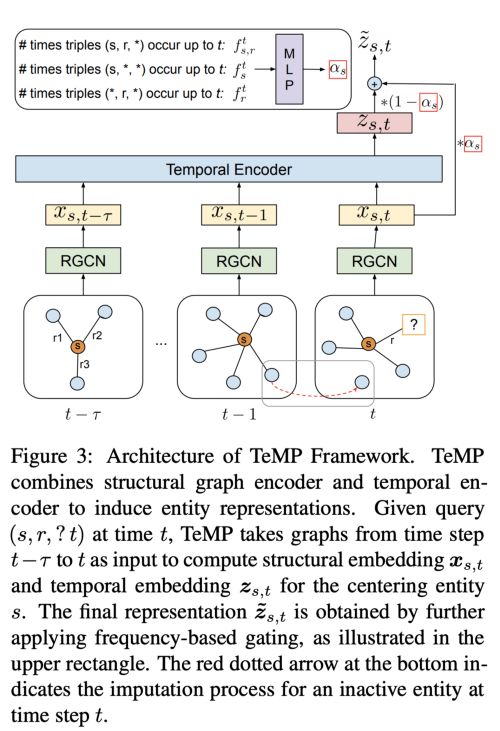
Jin等人也在RE-NET中用了类似的R-GCN+RNN方法,但用解码器处理时间成分的方式不同。我们取得的结论是:多关系GNN具有时间感!

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.541.pdf
2、DyERNIE
先插入一则数学知识讲解:我们知道,双曲嵌入的嵌入尺寸较小(一般是32d或64d),还能够带来极具竞争力的效果。截至现在,此类模型已在经典静态知识图谱的完成设置中得到探索。那么,双曲+时间=?
Zhen Han等人在DyERNIE模型中应用高等数学来模拟知识图谱的时间面。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.593.pdf
实体的时态交互被建模为流形上具备一定速度的运动。DyERNIE利用黎曼流形的乘积来处理不同的曲率,并定义了应用于四元组(s,p,o,t)的新评分函数。实验表明,20d/40d/100d模型的性能确实优于基线,且学习到的速度确实可以捕捉时间面。
但是,你可能会在附录中发现,在标准数据集上训练一个100d模型可能最多需要350个小时。
3、aeIOU
一个来自印度的研究团队提出了一个宝贵的方法论:大多数Temporal KG完成任务都会测量查询(s,r,?,t)或(?,r,o,t),即使未充分探索预测实际时间间隔(s, r, o, ?) 。此外,应用于此任务的现有指标可能低估或高估了系统性能。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.305.pdf
受到经常在CV中应用的gIOU的启发,该团队提出了一种用于时间间隔预测的新指标:aeIOU(affinity enhanced Interp over Union)。

符号⋓是最小的hull(连续间隔),同时包含了gold和预测间隔。该团队证明,aeIOU可以更好地理解任务的复杂性,并通过新模型TimePlex展示其优势。TimePlex模型增加了特定时态的归纳偏差(例如,一个人的出生年份应该早于一个人的死亡年份)。
4、CoDEx
说回链接预测,来自密歇根大学的Safavi和Koutra对FB15K-237和其他KGE基准测试的缺点进行了彻底研究,并得到结论:这些模型在至少7年前采取的偏差和设计不适用于这个领域在2021年的发展。
 图注:“是时候想一个更多样、更复杂的基准测试了。”
图注:“是时候想一个更多样、更复杂的基准测试了。”
假设每年有约50 KG新嵌入论文,模型确实会过度拟合数据集,因此,模型很难证明其表达能力——这仅仅是因为基准数据集无法从这种表达能力中受益。相反,两位作者提出了一个从Wikidata和Wikipedia中提取的知识图谱完成数据集:CODEX。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.669.pdf
这个数据集包括了:1)小/中/大子图;2)两项任务:链接预测和三元组分类;3)6种语言的实体和类型描述,没有任何语言能够覆盖全部实体;4)众包难负例;5)消除了测试泄漏源和大部分FB15K-237偏差。
5、消除KG嵌入的偏见
来自Amazon Alexa与Facebook的研究团队继续使用偏见,针对如何通过KG嵌入模型来减轻KG中的偏见进行了研究。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.595.pdf
例如,在Wikidata中,大多数人将银行家设为男性,但我们并不希望性别影响所有人在Wikidata中的职业预测。快速解决这个问题的方法可能是放弃所有“糟糕”的三元组,但随后我们发现,没有女性担任过美国总统,因此模型的质量会受到损害。
该团队提出了另一种非常有用的程序:本质是创建一个可能存在偏差关系的掩码,并分配一个KL损失函数对预测建模,以将概率推至平衡。实验表明,这个方法确实有可能减少某些谓词的偏见,且不必牺牲大量模型的预测能力。
6、来自加拿大麦吉尔大学Borealis AI的研究团队进行了一项有趣的研究:专注于样本外设置,即在测试时间内,一个新的无形的节点作为主语或宾语到达。有些人可能会将这项设置称为归纳,但我们还不清楚为什么作者不采取样本。

论文地址:
https://www.aclweb.org/anthology/2020.findings-emnlp.241.pdf
这篇论文中,有两种任务能够被称为归纳任务:1)一个无形实体中的三元组附加在可见的、经过训练的图上;2)测试集包含了一个全新的图,我们需要预测这个看不见的图中的链接。在用于GNN的标准归纳任务中,节点通常仍具有特性,但在此设置中,该研究团队特别阐明这些节点没有特性(且简单的节点度启发式方法不是很有用)。那么,我们要如何推断已到达的不可见实体的嵌入呢?
作者等人建议将可见实体和关系的嵌入聚合起来,并提出两种策略:1)在1跳邻域进行简单的平均;2)解决最小二乘问题(使用O(n³)时间的逆矩阵) 。他们还为此任务设计了WN18RR和FB15K-237的子集。论文发现,这两种聚合策略都能够应对这项任务。笔者认为,这项工作唯一的缺点是无法获知最小二乘法的训练时间。
ConvAI + KGs:站在OpenDialKG的肩膀上
OpenDialKG是ACL 2019的亮点之一。作为一个大规模对话数据集,OpenDialKG包含丰富的底层KG和相当复杂的任务。基线模型还有很大的改进空间。在EMNLP 2020中,我们发现,受OpenDialKG的影响或使用OpenDialKG,基于KG的ConvAI系统取得了明显的进步。
1、AttnIO
在EMNLP 2020中,一篇由Jung等人完成的工作受到了审稿人的大加赞誉:将注意力流应用于多跳遍历(multi-hop traversal)。他们采用的方法是AttnIO:对incoming与outgoing流程建模。

论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.280.pdf
incoming flow的本质是在采样子图上对基于GNN的邻域聚合(具有关系类型的GAT)进行操作。对话框的上下文(和实体名称)通过ALBERT进行编码。outgoing️流则由outgoing edges的注意力得分决定。解码器迭代成T步(分别获得T长路径)。
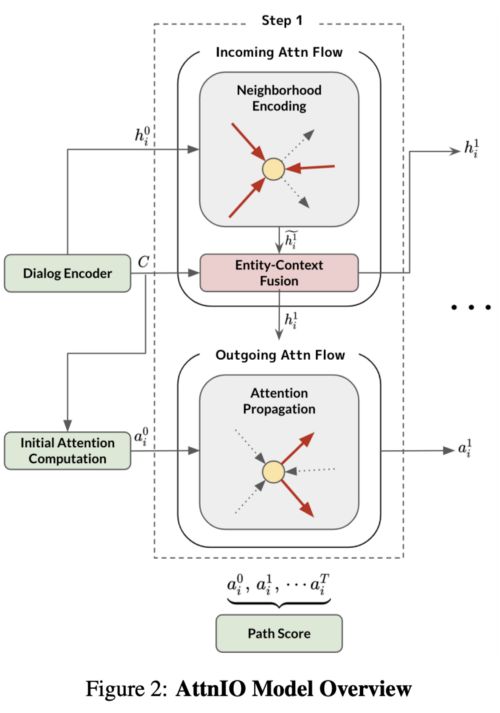
从数量上看,实验表明,与原来的OpenDialKG基线相比,AttnIO的性能大大提高,尤其是在top-1和top-3预测方面。从质量上看,案例研究表明,AttnIO生成了能被人类评估者理解的可解释推理路径。将工作扩展到具有100M个节点和1.1B边缘的大型KG(如Wikidata)可能是一项令人兴奋的工作。
2、KE模型
来自香港科技大学的研究团队采用了不同的方式来合并KB和KG。我们在上文中已经讨论过,大型的transformer语言模型趋于展现一些事实知识。那么,我们为什么不把所有知识都放入LM参数中呢?这个研究团队提出的KE(Knowledge Embedder,知识嵌入器)模型就是基于这个想法。

论文地址:
https://arxiv.org/pdf/2009.13656.pdf
我们的目标是在对话中生成KG事实的所有合理组合,并在该语料库放置任意LM。他们建议的策略如下:1)使用SQL或Cypher查询relational DB或KG的内容,然后将查询转换为对话模板(如下图所示);2)使用查询结果集填充模板;3)将那些模板化的对话输入到LM中,假设它会在其参数中记住KB事实。
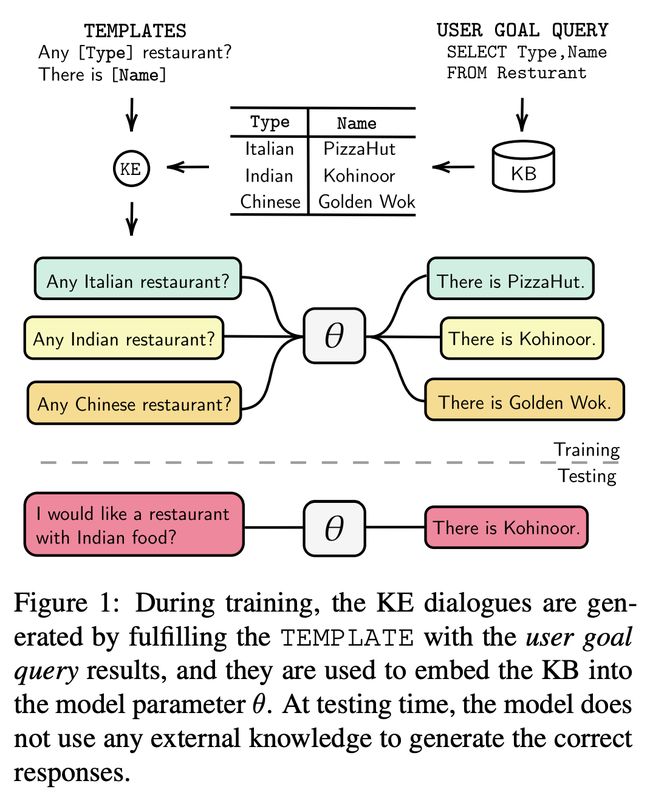
该研究团队将KE与GPT2连接,并在各种ConvAI数据集(包括OpenDialKG)上探索了该模型。确实,GPT2大大得益于KE模块(在某些数据集上甚至产生了 + 20 F1点),并且与基于显式检索的模型相当。
但这个工作也有一些缺点:原来的OpenDialKG图太大,以至于无法使用当前策略生成的所有对话模板。因此,这些数字与AttnIO相距甚远,将来还有很大的改进空间。
除此之外,有两篇论文也展示了在对话系统中使用KG的好处:
来自墨尔本大学的研究团队提出GraphDialog模型,专注于SMD和MultiWOZ数据集。通过将原始表格数据转换为KG并正确编码图,他们大大提高了实体检索F1分数。

论文地址:
https://arxiv.org/pdf/2010.01447.pdf
在医学领域,来自CMU的研究团队开发了一个用于医患对话的系统:MedFilter。他们将一部分话音编码(以及话语信息)插入到UMLS(一个庞大的医学本体)中。MedFilter可以更好地提取和分类症状、病人的倾诉和药物。非常高兴看到知识图谱在现实生活中得到应用!

论文地址:
https://arxiv.org/pdf/2010.02246.pdf
总结
EMNLP 2020出现了更复杂的基准测试、经过全面设计的任务以及探测方法论。随着模型尺寸的增长(且是在表达能力方面),以及GPU获得了更多的RAM,对计算力进行明智的投资显得十分重要。
知识图谱增强语言模型可能是语言模型的未来发展方向:当我们用完整个互联网上的新文本,就是时候注入更多结构化的归纳偏差了。
原文链接:
https://mgalkin.medium.com/knowledge-graphs-in-nlp-emnlp-2020-2f98ec527738
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】 下载二:南大模式识别PPT 后台回复【南大模式识别】 说个正事哈 由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。 感谢支持,比心。投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。 方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。记得备注呦 推荐两个专辑给大家:专辑 | 李宏毅人类语言处理2020笔记专辑 | NLP论文解读专辑 | 情感分析 整理不易,还望给个在看!