pandas 第一行_Pandas教程:使用Python和Pandas分析视频游戏数据


Python的pandas库是使Python成为一种用于数据分析的优秀编程语言的原因之一。Pandas使得导入、分析和可视化数据变得更加容易。它构建在NumPy和matplotlib等包的基础上,为您提供一个简单、方便的方式来进行大部分的数据分析和可视化工作。
在这篇Python数据科学教程中,我们将使用Pandas来分析来自IGN(一个流行的视频游戏评论网站)的视频游戏评论,这些数据是使用Eric Grinstein收集的。哪款主机赢得了“主机大战”(也就是好评度较高的游戏)?这个数据集将帮助我们找出答案。
当我们分析视频游戏评价时,我们将学习一些关键的pandas概念,比如索引。您可以继续在我们的其他Python教程中学习更多关于Python和pandas的内容,或者报名参加我们的《Python Pandas课程》。许多我们的其他《数据科学课程》也使用了pandas。
注意,本教程是使用Python 3.5编写的,并使用Jupyter Notebook构建的。您可能正在使用Python、pandas和Jupyter的一个更新版本,但是您的结果基本上应该是相同的。
使用Pandas导入数据
如果您正在学习本教程,您将需要下载此数据集,您可以在这里下载。地址:https://www.dataquest.io/wp-content/uploads/2019/09/ign.csv
我们要做的第一步是读入数据。数据是以一个逗号分隔的值或者csv文件进行存储的,其中每一行由一个新行进行分隔,每一列由一个逗号(,)进行分隔。此ign.csv文件的前几行如下:

正如您在上面所看到的,文件中的每一行都代表了IGN所评论过的一款游戏。列包含有关该游戏的信息:
score_phrase — IGN 形容这款游戏这与它收到的分数相关联。
score_phrase — IGN是怎样以一个单词描述这个游戏的。这与游戏的得分相关联。
title — 游戏名称。
url —全部评价的URL地址。
platform — 该游戏的评测平台(PC、PS4等).
score — 游戏的分数,从1.0到10.0。
genre — 游戏类型。
editors_choice — 如果该游戏不是一个编辑的选择,就是N,如果是就为Y。这与分数紧密相连。
release_year — 游戏发布年份。
release_month —游戏发布月份。
release_day — 游戏发布日。
还有一个包含行索引值的前导列。我们可以安全地忽略这一列,但是稍后我们将深入研究索引值是什么。
为了在Python和pandas中有效地处理数据,我们需要将该csv文件读入一个Pandas DataFrame中。DataFrame是一种表示和处理表格数据的方式——表格形式的数据,比如电子表格。表格数据有行和列,就像我们的csv文件一样,但是如果我们可以将它看作一个表,那么我们将更容易读取和排序。
为了读入数据,我们需要使用pandas.read_csv函数。这个函数将接受一个csv文件并返回一个DataFrame。以下代码将:
导入pandas库。我们把它重命名为pd。这样打字就更快了。这是数据分析和数据科学中的一个标准约定,您经常会在其他人的代码中看到pandas被导入为pd。
将 ign.csv读入到一个DataFrame中,并将结果分配给一个名为reviews的新变量,这样我们就可以使用reviews来引用我们的数据。

一旦我们读入了一个DataFrame,以一种更直观的方式来查看我们所拥有的内容是很有帮助的。方便地是,Pandas为我们提供了两种方法,使我们能够快速打印出一个表格中的数据。这些函数是:
DataFrame.head()——打印一个DataFrame的前N行, N是你作为一个参数传递给该函数的一个数字,例如,DataFrame.head(7)。如果不传递任何参数,默认值为5。
DataFrame.tail() ——打印一个DataFrame的后N行。同样,默认值是5。
我们将使用head方法来查看reviews中的内容:
![]()
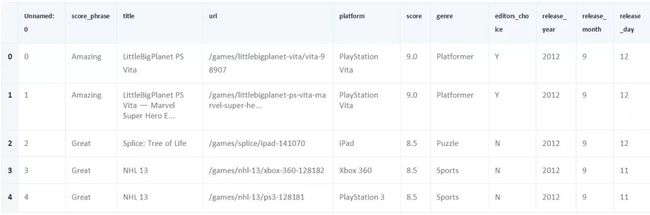
我们还可以访问pandas.DataFrame.shape属性来查看reviews中有多少行和列:

正如我们所看到的,所有内容都被正确地读入了——我们有18,625行和11列。
与一个类似的Python包(如NumPy)相比,使用pandas的一大优点是,pandas允许我们拥有具有不同数据类型的列。在我们的数据集reviews中,我们有存储浮点值(如score)、字符串值(如score_phrase)和整数(如release_year)的列,所以在这里使用NumPy会很困难,但是Pandas和Python可以很好地处理它。
现在我们已经正确地读入了数据,让我们对reviews进行索引,以获得我们想要的行和列。
使用Pandas索引DataFrame
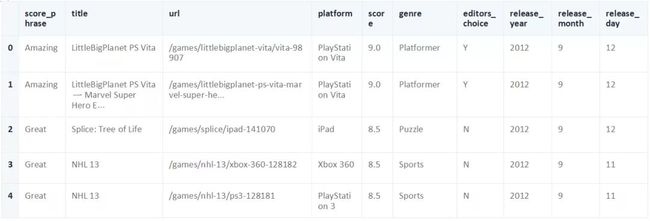
之前,我们使用head方法打印了前5行reviews。我们可以使用pandas. DataFrame .iloc方法来完成同样的事情。iloc方法允许我们根据位置检索行和列。为了做到这一点,我们需要指定我们想要的行的位置,以及我们想要的列的位置。下面的代码将通过选择第0行到第5行以及我们数据集中的所有列来复制我们的reviews.head()方法的结果:
![]()

让我们更深入地研究我们的代码:我们指定了我们想要的行0:5。这意味着我们想要从位置0到位置5的行,但不包括位置5。
第一行被认为位于位置0,因此选择行0:5可以得到位置0、1、2、3和4的行。我们也需要所有的列,我们使用快捷方式来选择它们。它是这样工作的:如果我们省略第一个位置值,比如:5,它假设我们的意思是0。如果我们省略最后一个位置值,比如0:,则假定我们指的是DataFrame中的最后一行或列。我们需要所有列,所以只指定了一个冒号(:),没有任何位置值。这会给我们返回从0到最后一列的列。下面是一些索引示例,以及结果:
reviews.iloc[:5,:] —前5行以及这些行的所有列。
reviews.iloc[:,:] — 整个DataFrame。
reviews.iloc[5:,5:] —从位置5向上的所有行,以及从位置5向上的所有列。
reviews.iloc[:,0] — 第一列,以及该列的所有行。
reviews.iloc[9,:] — 第10行,以及该行的所有列。
按位置索引与NumPy索引非常相似。如果您想了解更多,您可以阅读我们的NumPy教程。现在我们知道了如何按位置索引,让我们删除第一列,它没有任何有用的信息:

通过Python和Pandas使用标签进行索引
既然我们已经知道了如何按位置检索行和列,那么有必要研究处理DataFrames的另一种主要方法,即按标签检索行和列。与NumPy相比,Pandas的一个主要优势是它的每个列和行都有一个标签。处理列位置是可能的,但是很难跟踪哪个数字对应于哪个列。
我们可以使用pandas.DataFrame.loc方法来处理标签,它允许我们使用标签而不是位置来索引。我们可以像这样使用loc方法来显示reviews的前五行:


上面的这些实际上看起来与reviews.iloc[0:5,:]并没有太大的不同。这是因为虽然行标签可以接受任何值,但是我们的行标签与位置完全匹配。您可以看到上面表格最左边的行标签(它们是粗体的)。您还可以通过访问DataFrame的index属性来查看它们。我们将显示reviews的行索引:
![]()
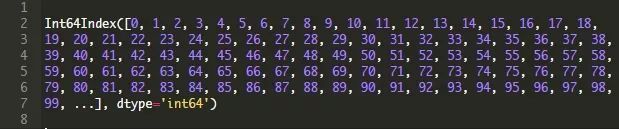
不过,索引并不总是必须与位置相匹配。在下面的代码单元格中,我们将:
获取reviews的第10行到第20行,并将结果分配给some_reviews。
显示some_reviews的前5行。


正如您在上面看到的,在some_reviews中,行索引从10开始,到20结束。因此,尝试loc小于10或大于20的数字将导致一个错误:
![]()

正如我们前面提到的,当您处理数据时,列标签可以使工作变得更容易。我们可以在loc方法中指定列标签,来按标签而不是按位置检索列。

我们也可以通过传入一个列表来一次指定多个列:
![]()

Pandas Series对象
我们可以用几种不同的方法检索Pandas中的单个列。到目前为止,我们已经看到了这类方法的两种类型的语法:
reviews.iloc[:,1]——将检索第二列。
reviews.loc[:,"score_phrase"] ——也将检索第二列。
还有第三种方法,甚至更简单一些,可以检索整个列。我们可以只用方括号指定列名,就像使用字典一样:

我们也可以用这个方法来使用列的列表:
![]()



18625 行 × 2列
当我们检索单个列时,实际上是在检索一个Pandas Series对象。DataFrame存储表格数据,而Series存储数据的单个列或单个行。
我们可以验证单个列就是一个Series:

我们可以手动创建一个Series来更好地理解它是如何工作的。要创建一个Series,我们在实例化时将一个列表或NumPy数组传递给该Series对象:

一个Series可以包含任何类型的数据,包括混合类型。这里,我们创建了一个包含字符串对象的Series:

使用Pandas创建一个DataFrame
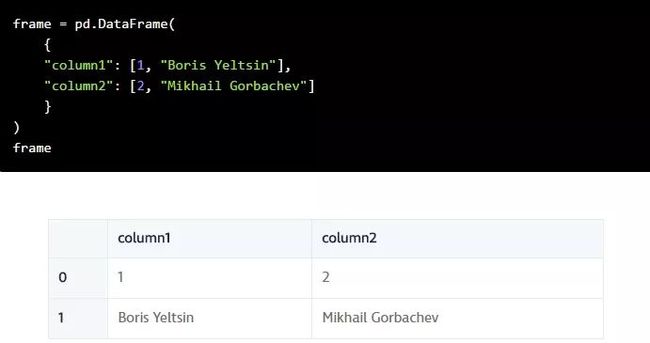
我们可以通过向DataFrame类传递多个Series来创建一个DataFrame。这里,我们传入我们刚刚创建的两个Series对象,
s1作为第一行,s2作为第二行:

我们也可以用一个包含列表的列表来完成同样的事情。每个内部列表在结果DataFrame中作为一行进行处理:

当我们创建了一个DataFrame时,我们可以指定列标签:
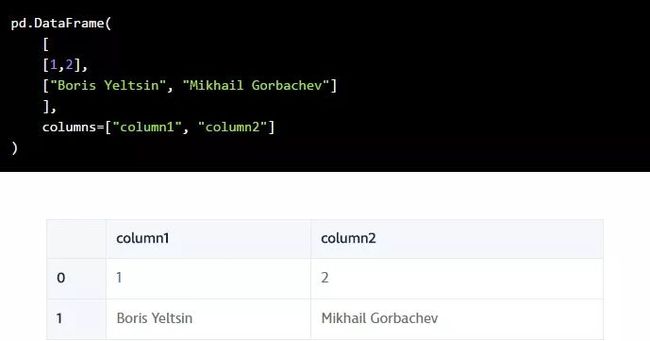
以及行标签 (索引):

还需要注意的是,我们不需要缩进和单独的行。我们已经以这样的方式编写了代码以便让它更容易解析,但是您经常会遇到所有代码都写成一行的情况。例如,下面的代码将产生与我们在本段上面的表格中看到的完全相同的结果:

无论如何,一旦我们添加了标签,我们就可以使用它们索引DataFrame:

如果将一个字典传入DataFrame构造函数,我们就可以跳过指定columns关键字参数。这将自动设置列名:
Pandas DataFrame方法
如前所述,pandas DataFrame中的每一列都是一个Series对象:

我们可以在一个Series对象上调用与在一个DataFrame上相同的方法,包括head:

Pandas Series和DataFrame当然还有其他方法,可以简化计算。例如,我们可以使用pandas.Series.mean方法求一个 Series的平均值:

我们也可以调用类似的pandas.DataFrame.mean 方法,该方法默认会找出一个DataFrame中每个数值列的均值:

我们可以将axis关键字参数修改为mean,以便计算每一行或每一列的平均值。默认情况下,axis等于0,将计算每一列的平均值。我们也可以把它设为1来计算每一行的均值。注意,这将只计算每一行中数值的平均值:

在Series和DataFrame上还有相当多的像mean的方法。以下是一些方便的方法:
pandas.DataFrame.corr —找出一个DataFrame中列之间的相关系数。
pandas.DataFrame.count — 统计每个DataFrame列非空值的数目。
pandas.DataFrame.max —找到每一列中的最高值。
pandas.DataFrame.min —找到每一列中的最低值。
pandas.DataFrame.median — 找到每一列的中位数。
pandas.DataFrame.std — 找到每一列的标准偏差。
例如,我们可以使用corr方法来查看是否有某些列与score列相关。这将告诉我们,是最近发行的游戏获得了更高的评价(release_year),还是年末发行的游戏得分更高(release_month):

正如我们在上面看到的,我们的数字列没有一个与score相关,所以我们知道发布时间与评价分数之间没有线性关系。
使用Pandas对DataFrame进行数学运算
我们还可以在Python中使用pandas对Series或DataFrame对象执行数学操作。例如,我们可以将score列中的每个值除以2,来将0-10的范围转换为0-5:

所有常见数学运算符在Python中都可以工作执行,如+、-、*、/和^,都将在pandas中的 Series或DataFrame上工作,并将应用于一个DataFrame或一个Series中的每个元素。
Pandas中的布尔索引
现在我们已经了解了一些pandas的基本知识,让我们转向分析的重点。我们在前面看到,reviews的score列中所有值的平均值都在7左右。如果我们想找出所有得分高于平均水平的游戏呢?
我们可以从进行一个比较开始。将一个Series中的每个值与指定的值进行比较,然后生成一个包含布尔值的Series,这些值表明比较的状态。例如,我们可以看到哪一行的score值高于7:
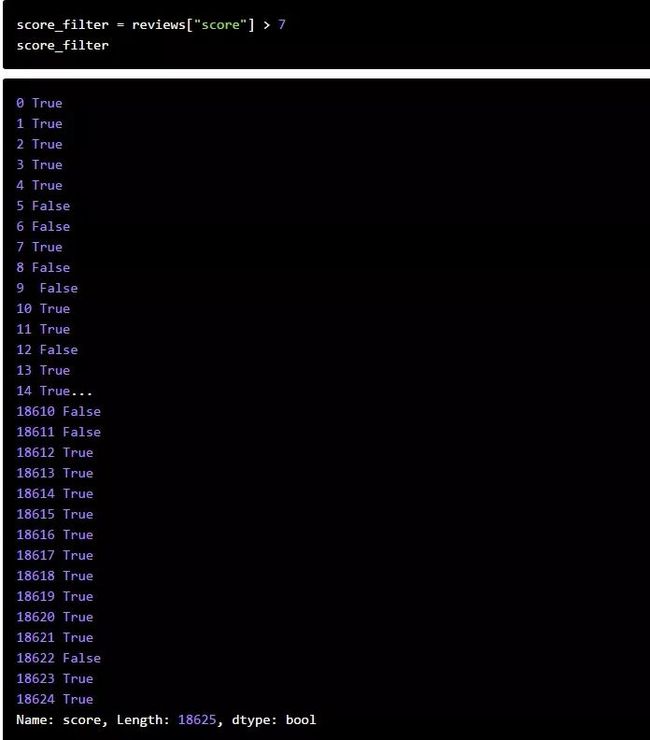
一旦我们有了一个布尔Series,我们就可以使用它在DataFrame中只选择Series包含值True的行。因此,我们只能在reviews中选择score值大于7的行:


我们可以使用多种条件进行过滤。假设我们想找到为Xbox One发行且得分超过7的游戏。在以下代码中,我们:
设置一个带有两个条件的过滤器。
--检查得分是否大于7。
--检查平台是否等于Xbox One。
将该过滤器应用到reviews去获取我们想要的行。
使用 head方法打印filtered_reviews的前5行。

当使用多个条件进行过滤时,将每个条件放在圆括号中,并使用单个连接符(&)将它们分开是很重要的。
使用Pandas绘制图表
现在我们知道了如何过滤,我们可以创建一些图表来观察Xbox One的评价分布和PlayStation 4的评价分布情况。这将帮助我们找出哪个主机拥有更好的游戏。
我们可以通过一个直方图来实现这一点,它将绘制不同得分范围的频率。我们可以使用pandas.DataFrame.plot方法为每个主机生成一个直方图。该方法在底层使用了流行的Python绘图库matplotlib来生成好看的图表。
plot方法默认会绘制一个折线图。我们需要传入关键字参数kind="hist"来绘制直方图。在以下代码中,我们:
调用%matplotlib inline来在一个Jupyter notebook中对绘图进行设置。
过滤出只含有关于Xbox One的数据的评价。
对score列进行绘图。

我们也可以为PS4做同样的操作:

从我们的直方图中可以看出,PlayStation 4比Xbox One具有更多高评分的游戏。
显然,这只是冰山一角时,我们可能需要分析这些数据集的潜在方向,但我们已经迈向了一个伟大的开端:我们使用Python和pandas导入了一个数据集,学着去使用各种不同的索引方法选择数据点,并做了一些快速的探索性数据分析来回答我们开始时提出的问题。
免费的Pandas备忘录
如果你有兴趣了解更多关于pandas的知识,请查看我们关于NumPy和pandas的互动课程。你可以免费注册并完成第一个任务。你也可能想要通过我们的免费pandas备忘录将你的pandas技能提升到下一个水平!
延伸阅读
希望本Pandas教程能够帮助您使用Pandas和Python读取、探索、分析和可视化数据。在下一篇文章中,我们将讨论数据分组和更高级的计算。你可以在这里找到它。如果你想了解更多关于Pandas的内容,请查看以下资源:
《Dataquest上的Pandas课程》
《10分钟掌握Pandas》
《Pandas数据结构介绍》
本文最后一次更新于2019年9月。
英文原文:https://www.dataquest.io/blog/pandas-python-tutorial/
译者:测试