Notes: One-shot Adversarial Attacks on Visual Tracking with Dual Attention
One-shot Adversarial Attacks on Visual Tracking with Dual Attention
Paper can be found here.
目录
- One-shot Adversarial Attacks on Visual Tracking with Dual Attention
-
- Introduction
- Methodology
-
- One-shot attack with dual loss
- Dual attention attack
Important features:
- free-model ( black-box?)
- only add perturbations in the initial frame
Introduction
Challenges to address:
- First, online visual tracking is unable to pre-know the category of tracked and to learn beforehand because of the free-model tacked target and the continuous video frames.
- Secondly, it is difficult to set an optimization objective to generate adversarial examples since a successful attack on the tracking task is significantly different from that on the multi-classification task which could merely maximize the probability of the class with the second-highest confidence. Specifically, the tracking task in each frame is the same as that of classifying all candidate boxes into one positive sample and the others into negative samples. Such a special binary classification problem makes it difficult to perform a successful attack if only one candidate box is selected to increase its confidence. (not quite understood)
- Last but not least, different from the NMS (Non-Maximum Suppression) algorithm used in the detection, the Gaussian windows are widely applied to refine the box confidences in the tracking task, which induces difficulties to balance the strength and the success of the attack.
This paper target trackers based on Siamese networks, proposes a one-shot attack framework— only slightly perturbing the pixel values of the object patch in the initial frame of a video, which achieves the goal of attacking the tracker in subsequent frames, i.e. failure to the tracking of SiamRPN.
Methodology
To address the challenges:
- To attack arbitrary targets, this method only add perturbations to the first frame of each video, namely one-shot attack.
- The attack must be able to perturb certain number of candidates. This paper optimizes two losses: a batch confidence loss to reduce confidence of high-quality boxes and raise confidence of low-quality boxes, and a feature loss for general attack.
- To improve attack power, this paper employs dual attention mechanism.
– batch confidence loss: confidence attention.
– feature loss: feature attention.
Dual-attention network
reference: https://arxiv.org/abs/1809.02983
“Attention is, to some extent, motivated by how we pay visual attention to different regions of an image or correlate words in one sentence.
"In a nutshell, attention in deep learning can be broadly interpreted as a vector of importance weights: in order to predict or infer one element, such as a pixel in an image or a word in a sentence, we estimate using the attention vector how strongly it is correlated with (or “attends to” as you may have read in many papers) other elements and take the sum of their values weighted by the attention vector as the approximation of the target."reference
One-shot attack with dual loss
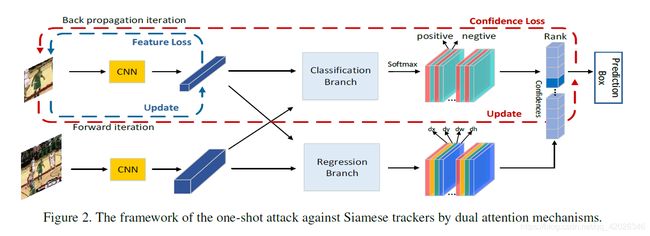
Given: initial frame; ground truth bbox of the tracked target.
Goal: generate an adversarial target image z ∗ = z + Δ z . z^*=z+\Delta z. z∗=z+Δz.
z ∗ = arg min ∣ z k − z k ∗ ∣ ≤ ε L ( z , z ∗ ) z^*=\argmin_{|z_k-z_k^*| \leq \varepsilon} \mathcal L(z,z^*) z∗=∣zk−zk∗∣≤εargminL(z,z∗)
z z z: target patch
z k z_k zk: the per pixel of clean image of image z z z
z k ∗ z_k^* zk∗: the per pixel of clean image of the adversary.
Batch confidence loss
The purpose of this approach based on batch confidence is to suppress the candidates with high confidence and stimulate the can didates with moderate confidence.
L 1 = ∑ R 1 : p f ( z ∗ , x i ) − ∑ R q : r f ( z ∗ , x i ) , s . t . ∣ z k − z k ∗ ∣ ≤ ε \mathcal L_1 =\sum_{\mathcal R_{1:p}}f(z^*, x_i) −\sum_{\mathcal R_{q:r}}f(z^*, x_i), s.t.\space |z_k-z_k^*| \leq \varepsilon L1=R1:p∑f(z∗,xi)−Rq:r∑f(z∗,xi),s.t. ∣zk−zk∗∣≤ε
X X X: search area around the target and twice the size of it, including n n n candidates { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn}.
f ( z , x i ) f(z,x_i) f(z,xi): tracking model which takes z z z and x i x_i xi as inputs and the confidence of each candidate as the output.
R 1 : n \mathcal R_{1:n} R1:n: ranking of the confidence of n n n candidates.
R 1 : p \mathcal R_{1:p} R1:p: the sort in the first p p p.
R q : r \mathcal R_{q:r} Rq:r: the sort from q q q to r r r.
Feature loss
The Euclidean distance of the feature maps of z z z and z ∗ z^* z∗ are maximized.
L 2 = − ∑ j = 1 : C ∣ ∣ ϕ j ( z ∗ ) − ϕ j ( z ) ∣ ∣ 2 , s . t . ∣ z k − z k ∗ ∣ ≤ ε \mathcal L_2 =-\sum_{j=1:C}||\phi_j(z^*)-\phi_j(z)||_2, s.t.\space |z_k-z_k^*| \leq \varepsilon L2=−j=1:C∑∣∣ϕj(z∗)−ϕj(z)∣∣2,s.t. ∣zk−zk∗∣≤ε
ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅): feature map of CNNs.
C C C: channels
Dual attention attack
Confidence attention
By applying the confidence attention mechanism to the loss function, we can distinguish the degree of suppression and stimulation for the candidates with different confidences.
The confidence loss function is rewritten as:
L 1 ∗ = ∑ R 1 : p { w i ∗ f ( z ∗ , x i ) } − ∑ R q : r f ( z ∗ , x i ) , s . t . ∣ z k − z k ∗ ∣ ≤ ε \mathcal L_1^* =\sum_{\mathcal R_{1:p}}\{w_i*f(z^*, x_i)\} −\sum_{\mathcal R_{q:r}}f(z^*, x_i), s.t.\space |z_k-z_k^*| \leq \varepsilon L1∗=R1:p∑{wi∗f(z∗,xi)}−Rq:r∑f(z∗,xi),s.t. ∣zk−zk∗∣≤ε
w i = 1 a + b ⋅ tanh ( c ⋅ ( d ( x i ) − d ( x 1 ) ) ) w_i=\frac{1}{a+b \space\cdot\space\tanh(c\space\cdot\space(d(x_i)-d(x_1))) } wi=a+b ⋅ tanh(c ⋅ (d(xi)−d(x1)))1
d ( x i ) d(x_i) d(xi): the coordinates distance between the any i i i-th candidate x i x_i xi and first x 1 x_1 x1 in the sorted confidence list.
Feature attention
This paper further considers the channel-wise activation-guided attention of feature maps to distinguish the importance of different channels, which will guarantee the generalization ability of the one-shot attack.
The confidence loss function is rewritten as:
L 2 ∗ = − ∑ j = 1 : C ∣ ∣ w j ′ ⋅ ϕ j ( z ∗ ) − ϕ j ( z ) ∣ ∣ 2 , s . t . ∣ z k − z k ∗ ∣ ≤ ε \mathcal L_2^* =-\sum_{j=1:C}||w_j'\space\cdot\space \phi_j(z^*)-\phi_j(z)||_2, s.t.\space |z_k-z_k^*| \leq \varepsilon L2∗=−j=1:C∑∣∣wj′ ⋅ ϕj(z∗)−ϕj(z)∣∣2,s.t. ∣zk−zk∗∣≤ε
w j = 1 a ′ + b ′ ⋅ tanh ( c ′ ⋅ ( m ( ϕ j ( z ) ) − m ( ϕ j ( z ) ) m i n ) ) w_j=\frac{1}{a'+b'\space\cdot\space\tanh(c'\space\cdot\space(m(\phi_j(z))-m(\phi_j(z))_{min}))} wj=a′+b′ ⋅ tanh(c′ ⋅ (m(ϕj(z))−m(ϕj(z))min))1
m ( ⋅ ) m(\cdot) m(⋅): the mean of each channel
ϕ j ( z ) \phi_j(z) ϕj(z)
m ( ⋅ ) m i n m(\cdot)_{min} m(⋅)min: the minimum mean
Dual attention loss
L = α L 1 ∗ + β L 2 ∗ \mathcal L = \alpha\mathcal L_1^*+\beta\mathcal L_2^* L=αL1∗+βL2∗
In the implementation, we use Adam optimizer to minimize the loss by iteratively perturbing the pixels along the gradient directions within the patch area, and the generation process stops when the number of iterations reaches 100 or the first candidate of the ranking R τ [ 1 ] \mathcal R_\tau[1] Rτ[1] behinds p p p in the initial ranking R 0 \mathcal R_0 R0.
Adam: a method for efficient stochastic optimization that only requires first-order gradients with little memory requirement. The method computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients; the name Adam is derived from adaptive moment estimation.
