【精读AI论文】inceptionV3 (Rethinking the Inception Architecture for Computer Vision)
文章目录
- 前言
- Abstract(摘要)
- Introduction(引言)
- General Design Principles(通用设计原则)
-
- 原则一
- 原则二
- 原则三
- 原则四
- Factorizing Convolutions with Large Filter Size(分解大卷积核 )
-
- 分解方法一:
- 分解方法二:
- Utility of Auxiliary Classifiers(辅助分类器)
- Efficient Grid Size Reduction(减小feature map尺寸)
- Inception-v2
- Model Regularization via Label Smoothing(LSR)
- Performance on Lower Resolution Input(小分辨率输入性能)
- Experimental Results and Comparisons(inceptionV3出炉)
- 小总结
inception系列:
- inceptionV1 & GoogleNet 精读
- inceptionV2 & BN 精读
- inceptionV3 精读
- inceptionV4 精读
- xception 精读
前言
今天看一下inception-V3,按照论文章节目录开始~
论文题目:Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/pdf/1512.00567.pdf
之前的俩版本:
- InceptionV1 精读
- InceptionV2 & BN 精读
强烈建议按顺序来,在这篇论文之前先看V1和V2。
这篇论文实际上应该是inceptionV3, inceptionV2是 BN的那一篇,不过在我查资料的时候,也有极少数人说inceptionV2和V3都是这一篇论文,不过没事,google这四篇论文都很牛,不管那个是V2,读就完了。
Abstract(摘要)
作者在摘要部分提到,2014年卷积神经网络开始做的又大又深,这里不就是暗示2014年的imagenet竞赛冠亚军 VGG和自己家的googleV1,尤其是庞然大物VGG嘛。。额 谁都拿VGG做例子,反面教材VGG实锤了。
提到了宽而深网络的痛点,计算复杂度高,无法在移动场景(边缘计算)和大数据场景下使用。
之后说出本篇论文的主旨:通过分解卷积+正则化提高计算效率
Introduction(引言)
第一段一句话总结: 卷积模型可以应用在各种领域。
第二段一句话总结: 好的学习模型更利于其他领域做迁移学习,作者得到一个启发:用深度学习做目标检测中的提取候选框任务。
第三段一句话总结:在参数上对比其他模型展现googlenet的优势(参数量-Alexnet:6000W,Googlenet:500W,VGG16:1.3E)
第四段一句话总结:模型计算量比PRelu低,可以在移动设备和大数据场景下使用,且各种加速优化方法都可以用在inception上(毕竟inception模块里面就是一堆的卷积和池化)。
最后一段一句话总结:一味的堆叠inception模块将使得计算量爆炸,换来的精准度并不划算,同时说了一下自己家的V1版本没有说明提高准确率的具体原因,所以—深度学习=炼丹炉 玄学了~
General Design Principles(通用设计原则)
这一章主要是介绍了作者想到的四种设计原则,开头的时候作者也说了,这几种设计原则你要大致上遵守,虽然没有严格的证明或者实验加持,但是可以表明的是,如果你背离这几个原则太多,则必然会造成较差的实验结果。(顺我者昌逆我者亡?)
原则一
避免过度的降维或者收缩特征 尤其在网络浅层。
- 前馈网络相当于一个有向无环图结构。
- feature map 长宽大小应随网络加深缓缓减小(不能猛减)。
- 过度的降维或者收缩特征将造成一定程度的信息丢失(信息相关性丢失)。
原则二
特征越多,收敛越快。
- 相互独立的特征越多,输入信息分解的越彻底。
- 就是inceptionV1里说的那个赫布理论。
原则三
3 * 3和5 * 5的卷积核卷积之前可以用1 * 1 的卷积核降维,信息不会丢失。
- 开头的单词 Spatial aggregation(空间聚集)也就是用大的感受野感受更多的信息,聚集在一起,即使用大尺寸的卷积核。
- 使用1 * 1 卷积可以降低维度,降低计算量,加速训练。
- inceptionV1中使用的模块里有 3 * 3 和 5 * 5的卷积,并且在他们之前有使用1 * 1 的卷积,这样的降维操作对于邻近单元的强相关性中损失的特征信息很少。
原则四
均衡网络中的深度和宽度。
- 深度就是指层数的多少,宽度指每一层中卷积核的个数,也就是提取到的特征数。
- 让深度和宽度并行提升,成比例的提升,能提高性能和计算效率。
- 可以让计算量在每一层上均匀分配,VGG那第一层全连接层的数据堆积就属于不均匀分配的情况。
Factorizing Convolutions with Large Filter Size(分解大卷积核 )
之前在Googlenet里面已经看到了inception模块使用1 * 1 的卷积核了。作者也在这里提到Googlenet的inception成功原因大部分得益于使用1 * 1 的卷积核,1 * 1 卷积核可以看作一个特殊的大卷积核分解过程,它不仅减少了计算量,还增加了网络的表达能力。
由上面的原则三也知道了,在使用大卷积核之前先用1 * 1卷积核,feature map信息不会丢失很多,因为感受野相邻的元素相关性很强,他们在卷积的过程中重合度很高,仅相差一个步长,所以feature map基本上不会丢失特征信息(元素特征相关性不变)。
inception模块为全卷积网络(可能有池化层,但没有全连接层),所以权重个数越多,计算量越大。所以就 -使用小卷积核–降维–参数量减少–计算量减小–节约内存–加速训练–节省出来的用于计算更多的卷积核组。‘
分解方法一:
简单说一下论文中第三页开头给出的这张图:
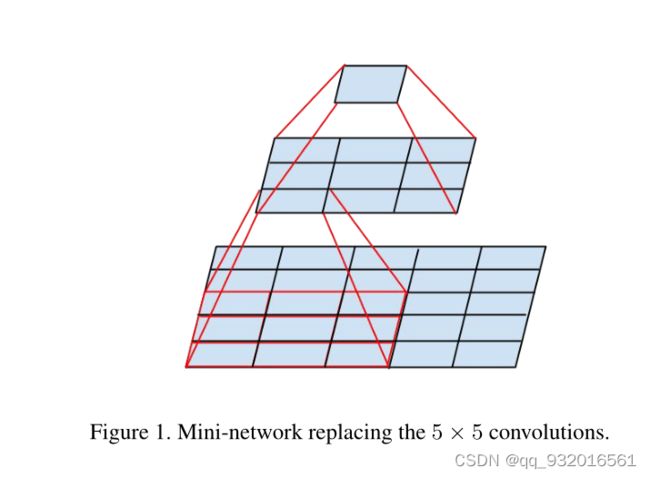
这图在之前论文复现里说过好多次了,其实就是讲大卷核用小卷积核替代的过程。
假设对于原图5 * 5 使用 5 * 5的卷积核去卷积(相当于一个全连接),只能得到一个1 * 1的feature map,而按照这个图,原图为5 * 5 ,现使用3 * 3 先卷积一次(步长为1),得到一个 3 * 3 的feature map,然后再使用一个3 * 3 的卷积核对刚才获得的feature map进行卷积,就同样得到了一个1 * 1的feature map。
5 * 5 卷积分解成两个 3 * 3卷积核。同理7 * 7分解成三个 3 * 3卷积核。
作者在3.1小节中提到:相同卷积核个数核feature map尺寸的情况下,5 * 5 卷积核比3 * 3卷积核计算量高了2.78倍。
相邻感受野的权值共享(共享卷积核,即卷积核内的数值都是一样的,用同一个卷积核),所以减少了很多计算量。
举个例子
在5 * 5的卷积核中: (H* W C) (5 * 5 * C) = 25 H W C 2 HWC^2 HWC2
在3 * 3的卷积核中: 2 * (H* W C) (3 * 3 * C) = 18 H W C 2 HWC^2 HWC2
由此作者得到了 28%的参数量减少。
对于分解后的激活函数,作者通过实验证明,保留对于原图的第一次3 * 3卷积的激活函数有较好效果(一层卷积变成两层了,增加了非线性变换,增强模型非线性表达能力),用BN后效果更好。
1 * 1卷积后接Relu有类似效果,(毕竟1 * 1 卷积也是一个卷积层)。
原来GoogleNet里的inceptionV1结构:

改进之后的inception结构:
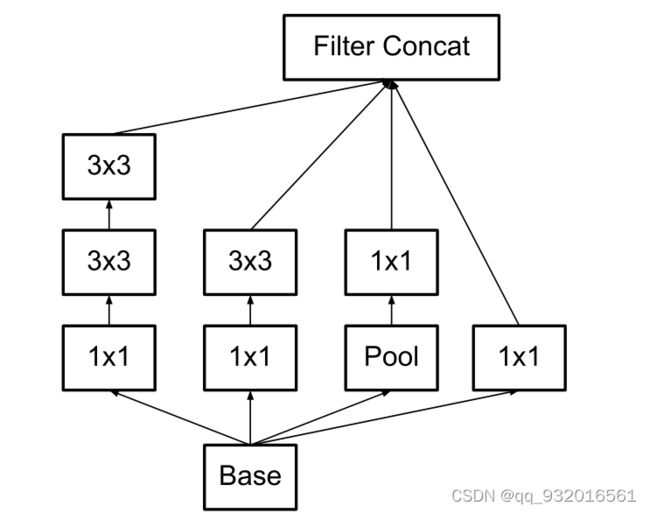
分解方法二:
上面的一个方法是 5 * 5分解成了 两个3* 3卷积。
3.2这一小节方法是,将3*3的卷积分解成 1 * 3和 3 * 1的两个不对称卷积(空间可分离卷积)。
具体卷积方法论文中给出了图:

简单解释一下上面的图,假设原始为3 * 3的图,使用3 * 1的卷积核去卷积,得到一个feature map,然后再用 1* 3 的卷积核对刚才得到的feature map做卷积得到1 * 1的feature map。
实际上这里直接用线代里的矩阵乘法更好理解,我在网上找了张图。
对于3 * 3矩阵的分解:分解成 3 * 1 和1 * 3的俩矩阵

实际上在到这之前我就在想,为啥不继续分解3 * 3卷积变成更小的,就像5 * 5 分解成两个 3 * 3那样,3 * 3也可以分解成两个2 * 2卷积,为啥非要弄成这种 3* 1 和1 * 3的不对称卷积?
作者在后面给出了原因,通过实验计算,将3 * 3 分解成两个2 * 2可以减少11%的参数量,而分解成3 *1 和1 * 3 可以减少33%的参数量(所以上面的5 * 5 分解也可以使用非对称分解喽?)。
两个小结论:
- 这种分解 (n *n 分解成了 n * 1 和1 * n) n 越大节省的运算量越大。
- 这种分解在前面的层效果不好,使用feature map大小在12-20之间。
将3 * 3用不对称分解之后的结构变成下面这样:

还有一个变种,可以理解成上面这个是在深度上分解,而下面这个是在宽度上分解。
应用在最后的输出分类层之前,用该模块扩展特征维度生成高维稀疏特征(增加特征个数,符合原则二)。

Utility of Auxiliary Classifiers(辅助分类器)
首先回顾一下在GooglenetV1里面的辅助分类器。

就是上面这样的辅助分类器,在浅层的时候直接输出一个分类结果,为了是让浅层使特征更加有区分性(让浅层学到区分性的特征),加速收敛,防止梯度消失,辅助分类器一个在浅层一个在中层,最终结果:L=L(最后)+0.3xL(辅1)+0.3xL(辅2),测试阶段去掉辅助分类器。
然后在这篇论文中,这一章作者直接说了 辅助分类器并没有加速收敛,但结果显示,带有辅助分类器的网络精度确实比没有辅助分类器的高,只高一点,移除了浅层的分类器对网络没有什么太大的影响。
Efficient Grid Size Reduction(减小feature map尺寸)
这章作者主要介绍了更高效的下采样方案。
传统的两种方法减小feature map的方法:先池化再升维,则丢失了过多信息,先升维再池化,则计算量复杂度变大。
为了解决上面的问题,提出了inception的并行模块。
inception并行模块结构图:
左边两路卷积,右边池化。最后再叠加,可以在不丢失信息的情况下减小参数量。

Inception-v2
我在开头的时候说到,这篇论文应该是inceptionV3,V2是BN那一篇,但是写这篇论文的时候作者就是把他叫成V2了,所以这一章作者起了这么个标题。
这一章主要就是汇总了上面所有的改进方法模块。
看一下作者给出的网络:

这里面的
- figure 5 ------ 5 * 5 卷积分解成两个3 * 3 卷积
- figure 6------ 应用的那个不对称卷积
- figure 7------ 用在输出分类前的那个扩展组合
作者说这个网络是符合上面说的设计的四大原则的, 网络有42层深,计算量是googlenet的2.5倍(仍比VGG高效)。
Model Regularization via Label Smoothing(LSR)
作者在这章提出了一种正则化方法 LSR,我尝试看了一下这一章,奈何水平不够,只能从表层理解没法深入原理。
Label Smoothing Regularization(LSR)标签平滑正则化,机器学习中的一种正则化方法,是一种通过在输出y中添加噪声,实现对模型进行约束,降低模型过拟合(overfitting)程度的一种约束方法(regularization methed)。
Performance on Lower Resolution Input(小分辨率输入性能)
到八章主要介绍了一些训练细节,就不说了。
第九章作者思考了一下模型在小分辨率图像输入的时候的性能。
首先说了一下模型在大分辨率图像输入下更高效的原因,一个是浅层的感受野大,因为输入分辨率大,所以卷积核大。
第二个原因是模型的深度大。
然后作者保持模型复杂度不变(对小分辨率图像减小前两层的步长,或者移除第一个池化层),单纯的提升输入图像分辨率做实验得到结果:

可以看到当分辨率提高之后正确率确实提高了,但是提高的微乎其微,三种情况几乎持平,且不能根据输入的分辨率变小而减少网络的大小,那样网络的性能会变得很差。
Experimental Results and Comparisons(inceptionV3出炉)
inceptionV3出炉过程直接看这张图:

从上面章节中提出的的inceptionV2结构开始改进:
- inceptionV2 加入RMSProp(一种计算梯度的方法,详细原理)
- 在上面的基础上加入Label Smoothing(LSR,标签平滑正则化)
- 在上面的基础上再加入 7 * 7的卷积核分解(分解成3 * 3)
- 在上面的基础上再加入含有BN的辅助分类器
所以本文最终提出的inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux
这里说的inceptionV2是本论文中的inceptionV2并不是BN那一篇。
小总结
- 四大设计原则
- 在浅层不要过度降维或收缩特征
- 特征越多,收敛越快。
- 大卷积核之前用1 * 1卷积降维,信息不丢失
- 均衡网络中的深度和宽度
- 不对称卷积核分解
- 直接打脸V1中的辅助分类器,并造了新的带BN的辅助分类器
- 使用新的 inception并行模块解决了传统采样层的问题
- inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux