pytorch学习笔记 —— torch.nn.Embedding
torch.nn.Embedding 可以实现 word embedding,在自然语言处理中比较常用;
word embedding 的理解
将源数据映射到另外一个空间中,一对一映射。
假设将 A 空间中的单词 a1 和 a2 对应 B 空间中的映射是多维变量 b1 和 b2,那么若 a1 < a2 ,则 b1 < b2。
通过 word embedding,就可以将自然语言所表示的单词或短语转换为计算机能够理解的由实数构成的向量或矩阵形式(比如,one-hot 就是一种简单的 word embedding 的方法);
这样得到一个向量以后,就可以通过计算向量之间的相似度来得出语义的相关性;
torch.nn.Embedding 的使用
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2,scale_grad_by_freq=False, sparse=False)
- num_embeddings:嵌入字典的大小(词的个数);
- embedding_dim:每个嵌入向量的大小;
- padding_idx:若给定,则每遇到 padding_idx 时,位于 padding_idx 的嵌入向量(即 padding_idx 映射所对应的向量)为0;
- max_norm:若给定,则每个大于 max_norm 的数都会被规范化为 max_norm;
- norm_type:为 max_norm 计算 p-范数的 p值;
- scale_grad_by_freq:若给定,则将按照 mini-batch 中 words 频率的倒数 scale gradients;
- sparse:若为 True,则 weight 矩阵将是稀疏张量。
输入:含有待提取 indices 的任意 shape 的 Long Tensor;
输出:输出 shape =(*,H),其中 * 为输入的 shape,H = embedding_dim(若输入 shape 为 N*M,则输出 shape 为 N*M*H);
torch.nn.Embedding 的权重为 num_embeddings * embedding_dim 的矩阵,例如输入10个词,每个词用3为向量表示,则权重为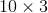 的矩阵;
的矩阵;
代码演示
官方代码:
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]]) # output的shape为(2*4*3)对于 padding_idx 的理解,自己写了一个比较清楚的:
import torch
from torch import nn
input = torch.LongTensor([[1, 2, 6, 4], [5, 6, 7, 8]])
em = nn.Embedding(10, 3, padding_idx=6)
output = em(input)
print("output:",output)
print("output.shape:",output.shape)
print("em.weight.shape:",em.weight.shape)运行结果如下:

可以看出 “6” 所对应映射的向量被填充了0。