【实战项目】高并发内存池
文章目录
- 项目介绍
- 内存池技术
- 设计一个定长的内存池
- 高并发内存池整体框架设计
- thread cache
-
- thread cache整体框架
- threadcache哈希桶映射对齐规则
- thread cache申请内存
- threadcacheTLS无锁访问
- central cache
-
- central cache整体框架
- central cache申请内存
- page cache
-
- page cache整体框架
- page cache申请内存
- 申请内存流程
- 内存释放
-
- threadcache释放内存
- central cache回收内存
- pagecache回收内存
- 内存释放流程
- 使用定长内存池配合脱离使用new
- 释放对象时优化为不传对象大小
- 多线程环境下对比malloc测试
- 性能瓶颈分析
- 使用基数树进行优化
-
- 基数树
- 利用基数树修改原代码
- 修改后的性能测试
- 项目源码
项目介绍
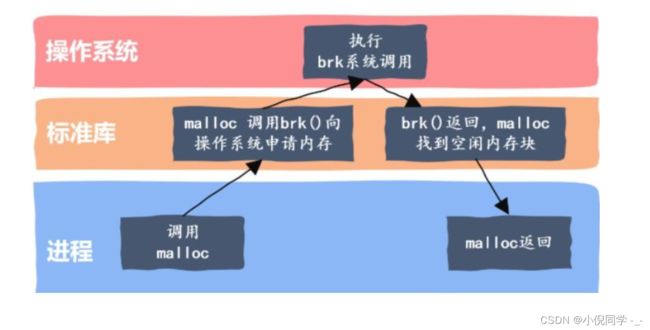
该项目实现一个高并发的内存池,他的原型是google的一个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)。

这个项目是把tcmalloc最核心的框架简化后拿出来,模拟实现出一个自己的高并发内存池,目的就是学习tcamlloc的精华。
这个项目会用到C/C++、数据结构(链表、哈希桶)、操作系统内存管理、单例模式、多线程、互斥锁等方面的知识。
tcmalloc源代码
内存池技术
池化技术
所谓“池化技术”,就是程序先向系统申请过量的资源,然后自己管理,以备不时之需。之所以要申请过量的资源,是因为每次申请该资源都有较大的开销,不如提前申请好了,这样使用时就会变得非常快捷,大大提高程序运行效率。
在计算机中,有很多使用“池”这种技术的地方,除了内存池,还有连接池、线程池、对象池等。以服务器上的线程池为例,它的主要思想是:先启动若干数量的线程,让它们处于睡眠状态,当接收到客户端的请求时,唤醒池中某个睡眠的线程,让它来处理客户端的请求,当处理完这个请求,线程又进入睡眠状态。
内存池
内存池是指程序预先从操作系统申请一块足够大内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
内存池主要解决的问题
内存池主要解决的还是效率的问题,其次如果从系统的内存分配器的角度来看,还需要解决一下内存碎片的问题。那么什么是内存碎片呢?
采用分区式存储管理的系统,在储存分配过程中产生的、不能供用户作业使用的主存里的小分区称成内存碎片,如下图所示

内存碎片又分为外碎片和内碎片,上面演示的是外碎片。外部碎片是一些空闲的连续内存区域太小,这些内存空间不连续,以至于合计的内存足够,但是不能满足一些的内存分配申请需求。内部碎片是由于一些对齐的需求,导致分配出去的空间中一些内存无法被利用。
malloc
C/C++中动态申请内存并不是直接去堆上申请的,而是通过malloc函数去申请的,C++中的new本质上也是封装了malloc函数。
malloc就是一个内存池。malloc() 相当于向操作系统“批发”了一块较大的内存空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。
malloc的实现方式有很多种,一般不同编译器平台用的都是不同的。比如windows的vs系列用的微软自己实现的一套,linux下的gcc用的glibc中的ptmalloc。
设计一个定长的内存池
我们知道申请内存使用的是malloc,它在任何场景下都可以用,这就意味着什么场景下它都不会有很高的性能。
定长内存池是针对固定大小内存块的申请和释放的问题,因为它申请和释放的内存块大小是固定的,所以不需要考虑内存碎片化的问题。
通过定长内存池,我们先熟悉一下简单内存池是如何控制的,其次,它也是后面高并发内存池的一个基础组件。
如何实现定长
我们可以利用非类型模板参数来控制向该内存池申请的内存大小,如下面代码,可以控制每次向内存池申请的内存大小为N
template<size_t N>
class ObjectPool
{};
此外,定长内存池也叫做对象池,在创建对象池时,对象池可以根据传入的对象类型的大小来实现“定长”,我们可以通过模板参数来实现定长,例如创建定长内存池时传入的对象类型是int,那么该内存池就只支持4字节大小内存的申请和释放。
template<class T>
class ObjectPool
{};
定长内存池向堆申请空间
这里申请空间不用malloc,而是用malloc的底层,直接向系统要内存,在Windows下,可以调用VirtualAlloc函数,在Linux下,可以调用brk或mmap函数。这里以Windows为主。
#ifdef _WIN32
#include定长内存池中的成员变量
对于申请的大块内存,我们可以利用指针进行管理,再用一个变量来记录申请的内存中剩余的内存大小。指针最好为字符指针,因为字符指针一次可以走任意的字节,很灵活。
对于释放回来的内存,我们可以利用链表来管理,这就需要一个指向链表的指针。

所以定长内存池中设计了三个变量
- 指向大块内存的指针
- 记录大块内存在切分过程中剩余字节数的变量
- 记录回收内存自由链表的头指针
定长内存池为用户申请空间
当我们为用户申请空间时,优先使用释放回来的内存,即自由链表。将自由链表头删一块内存返回。
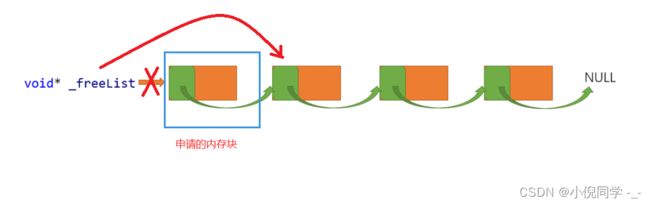
如果自由链表当中没有内存块,那么我们就在大块内存中切出定长的内存块进行返回。内存块切出后,及时更新_memory指针的指向,以及_remainBytes的值。

当大块内存不够切分出一个对象时,调用封装的SystemAlloc函数向系统申请一大块内存,再进行切分。
注意:为了让释放的内存能够并入自由链表中,我们必须保证切分出来的对象能够存下一个地址,即申请的内存块至少为4字节(32位)或8字节(64位)。
template<class T>
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
// 优先把还回来内存块对象,再次重复利用
if (_freeList)
{
// 从自由链表头删一个对象
void* next = *((void**)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
// 剩余内存不够一个对象大小时,则重新开大块空间
if (_remainBytes < sizeof(T))
{
_remainBytes = 128 * 1024;
_memory = (char*)SystemAlloc(_remainBytes >> 13);
// 申请内存失败抛异常
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
//从大块内存中切出objSize字节的内存
obj = (T*)_memory;
//保证对象能够存下一个地址
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
// 调整成员变量
_memory += objSize;
_remainBytes -= objSize;
}
// 定位new,显示调用T的构造函数初始化
new(obj)T;
return obj;
}
private:
char* _memory = nullptr;// 指向大块内存的指针
size_t _remainBytes = 0;// 大块内存在切分过程中剩余字节数
void* _freeList = nullptr;// 还回来过程中链接的自由链表的头指针
};
定长内存池管理回收的内存
我们用链表管理回收的内存,为了方便使用和节省空间,我们用内存块的前4个字节(32位平台)或8个字节(64位平台)记录下一个内存块的起始地址,如下图所示。

当回收内存块时,将内存块头插入自由链表即可。
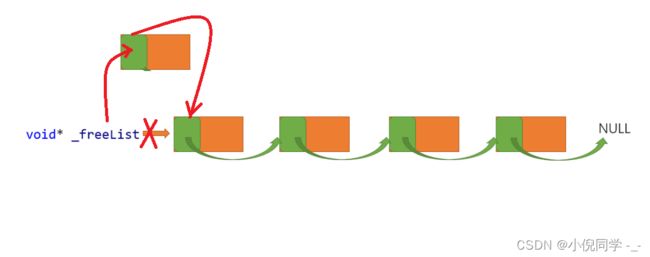
代码实现起来也很简单,就是链表的头插。
void Delete(T* obj)
{
// 显示调用析构函数清理对象
obj->~T();
// 头插
*(void**)obj = _freeList;
_freeList = obj;
}
这里还存在一个问题:如何让一个指针在32位平台下解引用后能向后访问4个字节,在64位平台下解引用后能向后访问8个字节呢?
这里我们利用二级指针,因为二级指针存储的是一级指针的地址,而一级指针会在不同的平台下呈现出不同的大小(32位平台大小为4字节,64位平台大小为8字节),二级指针解引用会向后访问一级指针的大小。这个操作在下面项目中会经常使用,建议写成函数。
static void*& NextObj(void* obj)
{
return *(void**)obj;
}
定长内存池总体代码
template<class T>
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
// 优先使用还回来内存块对象,再次重复利用
if (_freeList)
{
// 从自由链表头删一个对象返回
void* next = *((void**)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
// 剩余内存不够一个对象大小时,则重新开大块空间
if (_remainBytes < sizeof(T))
{
_remainBytes = 128 * 1024;
_memory = (char*)SystemAlloc(_remainBytes >> 13);
// 申请内存失败抛异常
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
//从大块内存中切出objSize字节的内存
obj = (T*)_memory;
//保证对象能够存下一个地址
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
// 调整成员变量
_memory += objSize;
_remainBytes -= objSize;
}
// 定位new,显示调用T的构造函数初始化
new(obj)T;
return obj;
}
void Delete(T* obj)
{
// 显示调用析构函数清理对象
obj->~T();
// 头插
*(void**)obj = _freeList;
_freeList = obj;
}
private:
char* _memory = nullptr;// 指向大块内存的指针
size_t _remainBytes = 0;// 大块内存在切分过程中剩余字节数
void* _freeList = nullptr;// 还回来过程中链接的自由链表的头指针
};
性能检测
下面将定长内存池和malloc/free进行性能对比
先用new和delete多次申请和释放TreeNode结点,利用clock函数记录整个过程消耗的时间。再用我们自己设计的定长内存池的New和Delete多次申请和释放TreeNode结点,记录整个过程消耗的时间。对两次使用的时间进行比较。
测试代码如下
void TestObjectPool()
{
// 申请释放的轮次
const size_t Rounds = 5;
// 每轮申请释放多少次
const size_t N = 100000;
std::vector<TreeNode*> v1;
v1.reserve(N);
size_t begin1 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode);
}
for (int i = 0; i < N; ++i)
{
delete v1[i];
}
v1.clear();
}
size_t end1 = clock();
std::vector<TreeNode*> v2;
v2.reserve(N);
ObjectPool<TreeNode> TNPool;
size_t begin2 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New());
}
for (int i = 0; i < N; ++i)
{
TNPool.Delete(v2[i]);
}
v2.clear();
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl;
cout << "object pool cost time:" << end2 - begin2 << endl;
}
这里我们调成Release版进行测试
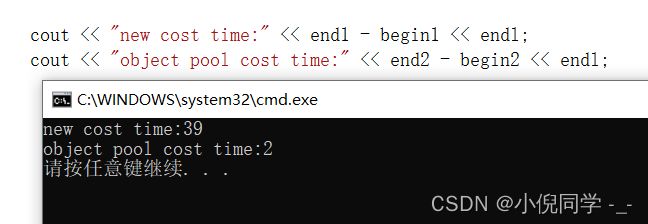
从结果中我们可以看出,设计的定长内存池要比malloc和free快一些。但是定长内存池只适用于申请和释放固定大小的内存,而malloc和free可以申请和释放任意大小的内存。为了解决定长内存池的局限性,谷歌大佬设计了tcmalloc,下面模拟实现tcmalloc简易版本。
高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,那么我们项目的原型tcmalloc就是在多线程高并发的场景下更胜一筹,所以这次我们实现的内存池需要考虑以下几方面的问题。
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。
concurrent memory pool主要由以下3个部分构成:
- thread cache: 线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
- central cache: 中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache在合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache中没有内存对象时才会找central cache,所以这里竞争不会很激烈。
- page cache: 页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
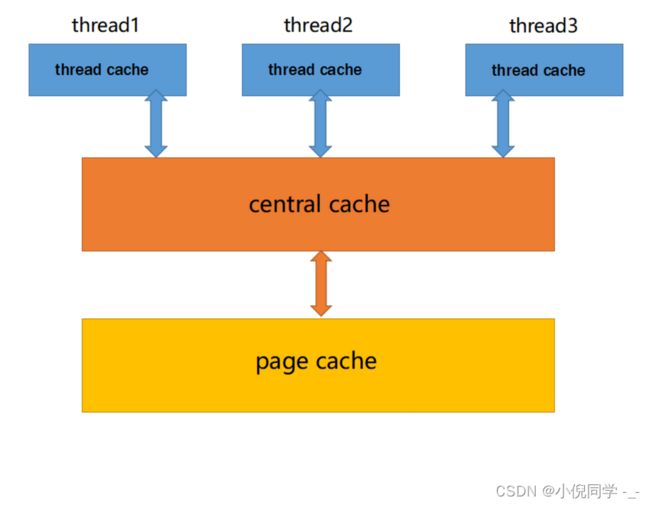
thread cache
thread cache整体框架
thread cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
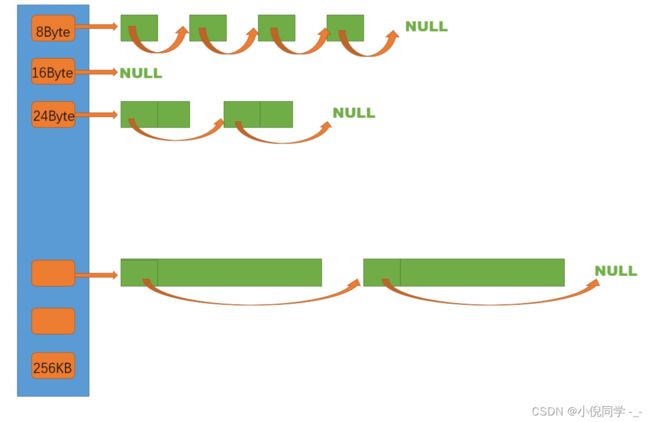
当线程要申请内存时,通过计算得到对齐后的字节数,从而找到对应的哈希桶,如果哈希桶中的自由链表不为空,就从自由链表中头删一块内存返回。如果哈希桶中的自由链表为空,就需要向下一层的central cache申请内存。
thread cache 代码框架如下
class ThreadCache
{
public:
// 申请和释放内存对象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size);
// 释放对象时,链表过长时,回收内存到中心缓存
void ListTooLong(FreeList& list, size_t size);
private:
// 哈希桶
FreeList _freeLists[NFREELIST];
};
// TLS thread local storage(TLS线程本地存储)
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
哈希桶中的自由链表是单链表结构,和上文实现的定长内存池一样,通过内存块的前4位或8位地址连接下一内存块。
代码如下
static void*& NextObj(void* obj)
{
return *(void**)obj;
}
class FreeList
{
public:
// 将释放的对象头插到自由链表
void Push(void* obj)
{
assert(obj);
//头插
NextObj(obj) = _freeList;
_freeList = obj;
++_size;
}
// 从自由链表头部获取一个对象
void* Pop()
{
assert(_freeList);
// 头删
void* obj = _freeList;
_freeList = NextObj(obj);
--_size;
return obj;
}
// 将释放的n个内存块头插入自由链表
void PushRange(void* start, void* end,size_t n)
{
NextObj(end) = _freeList;
_freeList = start;
_size += n;
}
// 从自由链表头部获取n个内存块
void PopRange(void*& start, void*& end, size_t n)
{
assert(n >= _size);
start = _freeList;
end = start;
// 确定获取内存块链表结尾
for (size_t i = 0; i < n - 1; i++)
{
end = NextObj(end);
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
// 更新内存块剩余数量
_size -= n;
}
// 判断自由链表是否为空
bool Empty()
{
return _freeList == nullptr;
}
// 记录当前一次申请内存块的数量
size_t& MaxSize()
{
return _maxSize;
}
// 自由链表中内存块的数量
size_t Size()
{
return _size;
}
private:
void* _freeList=nullptr;// 指向自由链表的指针
size_t _maxSize = 1;// 一次申请内存块的数量
size_t _size = 0;// 记录自由链表中内存块数量
};
threadcache哈希桶映射对齐规则
对象大小的对齐映射规则
对象大小的对齐映射并不是均匀的,而是成倍增长的。对象大小的对齐映射固定不变的话,如果映射值较小,就会创建大量的哈希桶,例如256kb如果按照8byte划分,则会创建32768个哈希桶。如果映射值较大,又会造成大量的空间浪费,产生内碎片问题。
为了减少空间浪费率和创建哈希桶的内存开销,我们设计了如下映射关系

空间浪费率
空间浪费率为浪费的字节数除以对齐后的字节数,以129~1024这个区间为例,该区域的对齐数是16,那么最大浪费的字节数就是15,而最小对齐后的字节数就是这个区间内的前16个数所对齐到的字节数,也就是144,那么该区间的最大浪费率就是 15 ÷ 144 ≈ 10.42%
计算对象大小的对齐映射数
计算对象大小的对齐映射数时,我们可以先判断该字节属于哪个区间,再调用子函数完成映射
static size_t _RoundUp(size_t size, size_t alignNum)
{
size_t alignSize=0;
if (size%alignNum != 0)
{
alignSize = (size / alignNum + 1)*alignNum;
}
else
{
alignSize = size;
}
return alignSize;
}
//获取向上对齐后的字节数
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}
子函数也可以利用位运算,位运算的速度是比乘法和除法更快的,但是这种方法不易想到
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1)&~(alignNum - 1));
}
计算内存映射的哈希桶
获取字节对应的哈希桶下标时,也是先判断它在哪个区间,再调用子函数去找。
size_t _Index(size_t bytes, size_t alignNum)
{
alignNum=1<<alignNum;
if (bytes%alignNum == 0)
{
return bytes / alignNum - 1;
}
else
{
return bytes / alignNum;
}
}
// 计算映射的哪一个自由链表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= 13);
// 每个区间有多少个链
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 3);
}
else if (bytes <= 1024){
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024){
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024){
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024){
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else{
assert(false);
}
return -1;
}
映射哈希桶的子函数也可使用位运输
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
thread cache申请内存
thread cache申请内存
- 当申请的内存size<=256KB时,先获取到线程本地存储的thread cache对象,再通过计算找到size映射的哈希桶下标 i 。
- 查看下标为 i 的哈希桶中的自由链表是否为空,如果哈希桶中的自由链表不为空,就从自由链表中头删一块内存返回。
- 如果哈希桶中的自由链表为空,则批量从central cache中获取一定数量的对象,插入到自由链表并返回一个对象。
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
// 计算对齐映射字节数
size_t alignSize = SizeClass::RoundUp(size);
// 计算映射的哈希桶下标
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty())
{
// 从自由链表中头删一块返回
return _freeLists[index].Pop();
}
else
{
// 向CentralCache层申请空间
return FetchFromCentralCache(index, alignSize);
}
}
thread cache向central cache获取内存
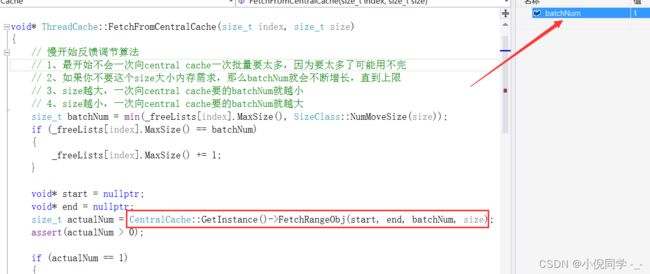
这里会用到慢开始反馈调节算法:
开始不会一次向central cache一次批量要太多,因为要太多了可能用不完,如果你不断申请这个size大小的内存,那么batchNum就会不断增长,直到上限。
static const size_t MAX_BYTES = 256 * 1024;// 一次可申请的最大字节数,我们把它用宏定义表示。
// 一次thread cache从中心缓存获取多少个内存块
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 大对象一次批量上限低
int num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
// thread cache向central cache获取内存。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
// 慢开始算法
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
// 向CentralCache申请一段内存
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
// 将申请的一段内存头插入对应的自由链表
_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);
return start;
}
}
threadcacheTLS无锁访问
要实现每个线程无锁的访问属于自己的thread cache,我们需要用到线程局部存储TLS(Thread Local Storage),这是一种变量的存储方法,使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。
//TLS - Thread Local Storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
但不是每个线程被创建时就立马有了属于自己的thread cache,而是当该线程调用相关申请内存的接口时才会创建自己的thread cache,因此在申请内存的函数中会包含以下逻辑。
//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
central cache
central cache整体框架
当Thread Cache映射的自由链表为空时它会向central cache申请内存。central cache也是一个哈希桶结构,他的哈希桶的映射关系跟thread cach是一样的。不同的是他的每个哈希桶位置挂是SpanList链表结构,不过每个映射桶下面的span中的大内存块被按映射关系切成了一个个小内存块对象挂在span的自由链表中。
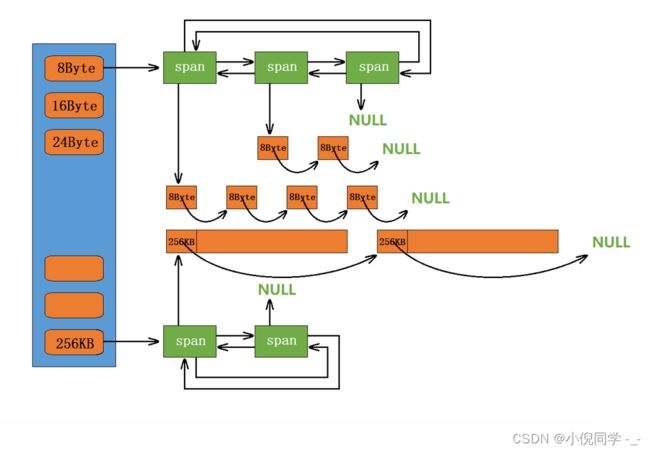
Span
Span是一个结构体,该结构体管理以页为单位的大块内存,Span和Span间用双链表连接起来。Span的内部有自由链表,该自由链表是根据哈希桶映射大小切分好的内存块。Span的内部还记录了内存块的使用等信息,具体结构如下
// 在64位下PAGE_ID 8字节,在32位下PAGE_ID 4字节
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
// linux
#endif
// 管理多个连续页大块内存跨度结构
struct Span
{
PAGE_ID _pageId;// 大块内存起始页的页号
size_t _n = 0;// 页的数量
Span* _next = nullptr;// 双向链表的结构
Span* _prev = nullptr;
size_t _objSize = 0; // 切好的小对象的大小
size_t _useCount = 0;// 切好小块内存,被分配给thread cache的计数
void* _freeList = nullptr;// 切好的小块内存的自由链表
bool _isUse=false;// 该页是否被使用
};
SpanList
不同于thread cache哈希桶上的自由链表FreeList,central cache的哈希桶上的自由链表为SpanList,连接Span的双链表
// 带头双向循环链表
class SpanList
{
public:
// 构造
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span* Begin()
{
return _head->_next;
}
Span* end()
{
return _head;
}
// 判空
bool Empty()
{
return _head->_next == _head;
}
// 插入新页
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
// 头插
void PushFront(Span* span)
{
Insert(Begin(), span);
}
// 删除
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head);
Span* prev = pos->_prev;
Span* next = pos->_next;
next->_prev = prev;
prev->_next = next;
}
// 头删
Span* PopFront()
{
Span* front = _head->_next;
Erase(front);
return front;
}
private:
Span* _head;
public:
std::mutex _mtx;// 桶锁
};
central cache的框架
central cache要满足thread cache申请的内存。当central cache中没有Span时需要向下一层PageCache申请。当有内存还回来时,要能够把它连接到哈希桶对应的SpanList自由链表上方便下次使用。
static const size_t NFREELIST = 208;// central cache中有208个哈希桶
class CentralCache
{
public:
// 单例模式
static CentralCache* GetInstance()
{
return &_sInst;
}
// 获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
// 将一定数量的对象释放到span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
};
为了让每次访问到的是同一个CentralCache我们把它设置成单例模式。
central cache申请内存
当thread cache中没有内存时,就会批量向central cache申请一些内存对象,这里的批量获取对象的数量使用了类似网络tcp协议拥塞控制的慢开始算法;central cache从span中取出对象给thread cache,这个过程需要加锁的,这里使用的是一个桶锁,尽可能提高效率。
central cache从中心缓存获取对象给thread cache
从central cache获取n个指定大小的对象,找到对应的哈希桶,将自由链表SpanList头删n个内存块。
这里需要加桶锁,防止多个线程在central cache的自由链表中访问同一内存块,产生线程竞争问题。
// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();// 桶锁
//在对应哈希桶中获取一个非空的span
Span* span = GetOneSpan(_spanLists[index], size);
// 获得的页和页中的自由链表不能为空
assert(span);
assert(span->_freeList);
// 从span中获取batchNum个对象
// 如果不够batchNum个,有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
// 截取n个内存块
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
++i;
++actualNum;
}
span->_freeList = NextObj(end);//取完后剩下的对象继续放到自由链表
NextObj(end) = nullptr;//取出的一段链表的表尾置空
span->_useCount += actualNum;//更新被分配给thread cache的计数
_spanLists[index]._mtx.unlock();// 解锁
return actualNum;
}
central cache获取页
// 计算一次向系统获取几个页
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size);
size_t npage = num*size;
npage >>= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
}
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 查看当前的spanlist中是否有还有未分配对象的span
Span* it = list.Begin();
while (it != list.end())
{
if (it->_freeList)
{
return it;
}
else
{
it = it->_next;
}
}
// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞
list._mtx.unlock();
// 走到这里说没有空闲span了,只能找page cache要
PageCache::GetInstance()->_pageMtx.lock();
Span* span=PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_isUse = true;
span->_objSize = size;
PageCache::GetInstance()->_pageMtx.unlock();
// 对获取span进行切分,不需要加锁,因为这会其他线程访问不到这个span
// 计算span的大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
// 把大块内存切成自由链表链接起来
// 先切一块下来去做头,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
//尾插
while (start < end)
{
NextObj(tail) = start;
tail = start;
start += size;
}
NextObj(tail) = nullptr;
// 切好span以后,需要把span挂到桶里面去的时候,再加锁
list._mtx.lock();
list.PushFront(span);
return span;
}
page cache
page cache整体框架
page cache和Central Cache它们的核心结构都是spanlist的哈希桶,但是他们还是有区别的,central cache中哈希桶,是按跟thread cache一样的大小对齐关系映射的,他的spanlist中挂的span中的内存都被按映射关系切好链接成小块内存的自由链表。而page cache 中的spanlist则是按下标桶号映射的,也就是说第i号桶中挂的span都是i页内存。
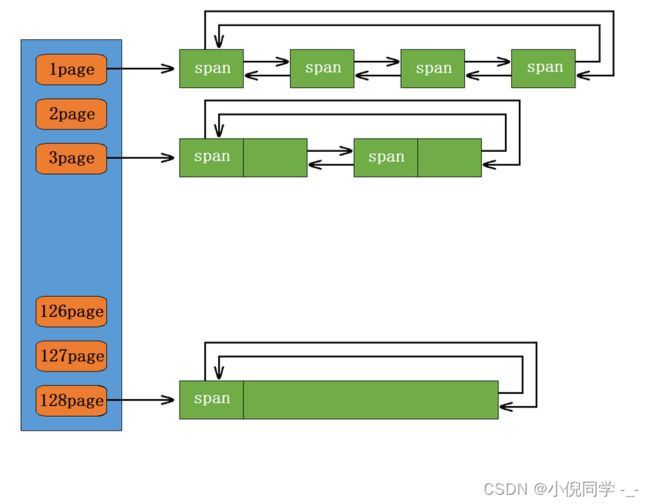
static const size_t NPAGES = 129;// page cache中一共有128个哈希桶
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
// 获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
// 释放空闲span回到Pagecache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
// 获取一个K页的span
Span* NewSpan(size_t k);
std::mutex _pageMtx;// page cache大锁
private:
SpanList _spanLists[NPAGES];
ObjectPool<Span> _spanPool;
// 建立页号和地址间的映射
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
PageCache()
{}
PageCache(const PageCache&) = delete;
static PageCache _sInst;
};
page cache申请内存
当central cache向page cache申请内存时,page cache先检查对应位置有没有span,如果没有则向更大页寻找一个span,如果找到则切分成两部分。比如:申请的是4页page,4页page后面没有挂span,则向后面寻找更大的span,假设在10页page位置找到一个span,则将10页pagespan分裂为一个4页page span和一个6页page span,将4页的page span分配出去,将6页的page span插入到对应的哈希桶。
如果找到_spanList[128]都没有合适的span,则向系统申请128页page span挂在自由链表中,再重复1中的过程。
建立页号跟span的映射
页号和地址有关,而计算机在不同位下地址长度不同(32位下4字节,64位下8字节),如何确定页号的大小呢?
我们可以利用如下程序。因为_WIN64包含了32位和64位,而_WIN32只包含了32位,所以我们可以先判断当前计数机是否为64位,再判断其是否为32位。
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
// linux
#endif
这里我们先建立页号跟span的映射关系,方便释放内存对象回来查找对应位置
static const size_t PAGE_SHIFT = 13;
Span* PageCache::MapObjectToSpan(void* obj)
{
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);//右移13位,找到对应的id
std::unique_lock<std::mutex> lock(_pageMtx); //加锁,RAII,出了作用域,自己解锁
auto ret = _idSpanMap.find(id);//查找对应的span
if (ret != _idSpanMap.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}
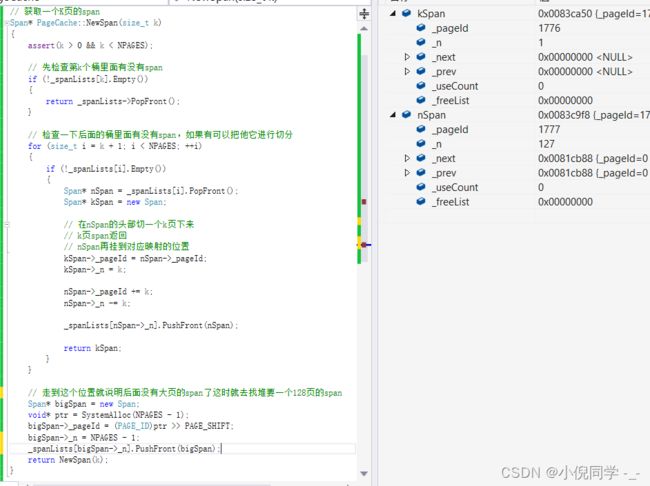
获取一个K页的span
// 获取一个K页的span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 );
// 如果申请的页大于128,直接去堆上申请
if (k > NPAGES - 1)
{
void* ptr = SystemAlloc(k);
Span* span = _spanPool.New();
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_n = k;
// 建立页号和地址的映射
_idSpanMap[span->_pageId] = span;
return span;
}
// 先检查第k个桶里面有没有span
if (!_spanLists[k].Empty())
{
// 第k个桶里面有span直接头切一个块
Span* kSpan = _spanLists[k].PopFront();
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; ++i)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
return kSpan;
}
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
Span* kSpan = _spanPool.New();
// 在nSpan的头部切一个k页下来
// k页span返回
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;
nSpan->_pageId += k;
nSpan->_n -= k;
// nSpan再挂到对应映射的位置
_spanLists[nSpan->_n].PushFront(nSpan);
// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时进行的合并查找
_idSpanMap[nSpan->_pageId] = nSpan;
_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; ++i)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
return kSpan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
Span* bigSpan = _spanPool.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[bigSpan->_n].PushFront(bigSpan);
// 调用自己,下次将128页进行拆分
return NewSpan(k);
}
申请内存流程
申请一部分内存,通过调试查看申请流程
void TestConcurrentAlloc1()
{
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
}
当线程第一次申请内存时,该线程需要通过TLS获取到自己专属的thread cache对象,然后通过这个thread cache对象进行内存申请。
当我们申请6个字节的内存时,6字节会被映射成8字节,对应的哈希桶下标为0。我们去thread cache的哈希桶申请内存时,如果该哈希桶中自由链表为空,就要向下一层central cache申请内存块。

通过NumMoveSize函数计算得出,thread cache一次向central cache申请8字节大小对象的个数是512,申请的内存块太多了,我们使用慢开始算法。取出自由链表的_maxSize的值和NumMoveSize函数计算得出值的较小值。_maxSize的初始值为1,所以向central cache申请1个8字节内存块。完成后再将_maxSize的加1,让下一次申请更多的内存块。
向central cache申请内存时需要给桶加锁,避免在自由链表中产生竞争。然后再从该桶获取一个非空的span。

遍历对应哈希桶的span双链表,如果存在不为空的span就将该span返回,否则就向下一层page cache申请。注意这里需要将先前加在central cache上的锁释放掉,而且向page cache申请内存需要加一个大锁。

通过计算求得申请的页数为1页

此时page cache没有span,它要去堆上申请128页的span,再将128页的span拆分成1页和127页的span,返回1页的span给central cache,把127页的span挂到page cache的第127号桶上。
从page cache返回后,将获取到的1页span切分一个个8字节的内存块挂到central cache的0号哈希桶上。

central cache再分配给thread cache所需求的内存块

此时thread cache已经申请到了内存块,完成了一次申请内存。
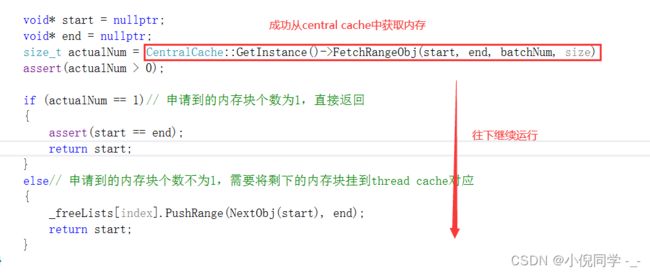
当线程第二次申请内存块时就不会再创建thread cache了,因为第一次申请时就已经创建好了,此时该线程直接获取到对应的thread cache进行内存块申请即可。
第二次申请8字节大小的对象时,此时thread cache的0号桶中还是没有对象的,因为第一次thread cache只向central cache申请了一个8字节对象,因此这次申请时还需要再向central cache申请对象。

因为慢增长算法,这一次thread cache会向central cache申请2个8字节大小的内存块
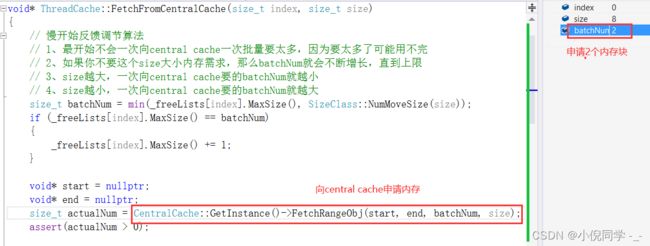
因为第一次central cache向page cache申请了一页的内存块,并将其切成了1024个8字节大小的内存块,所以此次thread cache会向central cache申请2个8字节大小的内存块时,central cache可以从0号哈希桶中直接返回,而不用再向page cache申请内存了。
注意:这里申请了两个8字节内存块,但只使用了一个,我们需要将剩下的一个内存块挂入哈希桶中

第三次申请8字节内存时,直接向thread cache获取第二次申请剩下的内存块即可。

内存释放
threadcache释放内存
- 当释放内存小于256k时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push到对应的_freeLists[i]。
- 当链表的长度过长,则回收一部分内存对象到central cache。
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
// 找对映射的自由链表桶,对象插入进入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 当链表长度大于一次批量申请的内存时就开始还一段list给central cache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize())
{
ListTooLong(_freeLists[index], size);
}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
// 将该段自由链表从哈希桶中切分出来
list.PopRange(start, end, list.MaxSize());
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}
central cache回收内存
当thread_cache过长或者线程销毁,则会将内存释放回central cache中的,释放回来时 - - _useCount。当_useCount减到0时则表示所有对象都回到了span,则将span释放回page cache,page cache中会对前后相邻的空闲页进行合并。
// 将一定数量的对象释放到span跨度
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
while (start)
{
void* next = NextObj(start);
// 通过映射找到对应的span
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
// 内存块的链表头插入span结构的自由链表中
NextObj(start) = span->_freeList;
span->_freeList = start;
span->_useCount--;// 更新分配给thread cache的计数
// 说明span的切分出去的所有小块内存都回来了
// 这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并
if (span->_useCount == 0)
{
_spanLists[index].Erase(span);
span->_freeList = nullptr;
span->_next = nullptr;
span->_prev = nullptr;
_spanLists[index]._mtx.unlock();
// 释放span给page cache时,使用page cache的锁就可以了
// 这时把桶锁解掉
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}
pagecache回收内存
如果central cache释放回来一个span,则依次寻找span前后page id,看有没有未在使用的空闲span,如果有,将其合并。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。
void PageCache::ReleaseSpanToPageCache(Span* span)
{
if (span->_n > NPAGES - 1)
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
_spanPool.Delete(span);
return;
}
// 对span前后的页,尝试进行合并,缓解内存碎片问题
while (1)
{
// 与span链表相连的,上一个span的页号
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
// 前面的页号没有,不合并
if (ret == _idSpanMap.end())
{
break;
}
Span* prevSpan = ret->second;
// 前面相邻页的span在使用,不合并
if (prevSpan->_isUse == true)
{
break;
}
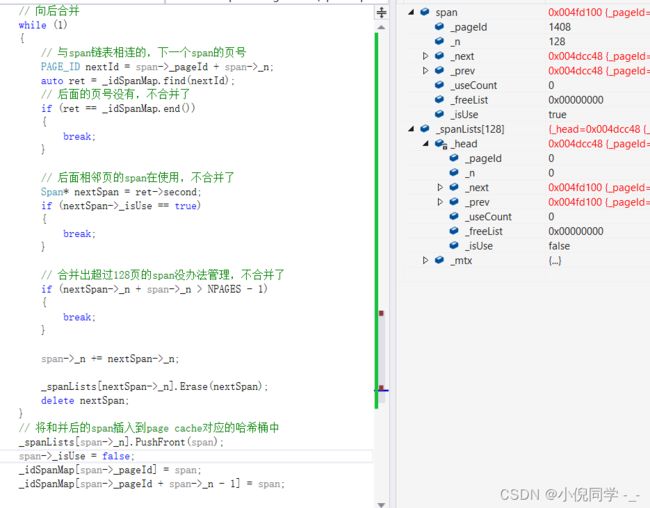
// 合并出超过128页的span没办法管理,不合并
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
_spanLists[prevSpan->_n].Erase(prevSpan);
_spanPool.Delete(prevSpan);
}
// 向后合并
while (1)
{
// 与span链表相连的,下一个span的页号
PAGE_ID nextId = span->_pageId + span->_n;
auto ret = _idSpanMap.find(nextId);
// 后面的页号没有,不合并
if (ret == _idSpanMap.end())
{
break;
}
// 后面相邻页的span在使用,不合并
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true)
{
break;
}
// 合并出超过128页的span没办法管理,不合并
if (nextSpan->_n + span->_n > NPAGES - 1)
{
break;
}
span->_n += nextSpan->_n;
_spanLists[nextSpan->_n].Erase(nextSpan);
_spanPool.Delete(nextSpan);
}
// 将和并后的span插入到page cache对应的哈希桶中
_spanLists[span->_n].PushFront(span);
span->_isUse = false;
_idSpanMap[span->_pageId] = span;
_idSpanMap[span->_pageId + span->_n - 1] = span;
}
内存释放流程
我们向外提供一个ConcurrentFree函数,用于释放内存块,释放内存块时每个线程通过自己的thread cache对象,调用thread cache中释放内存对象的接口即可。
static void ConcurrentFree(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
现在我们释放先前申请的三个内存块,通过调试,看看流程是什么样的。
void TestConcurrentAlloc1()
{
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
ConcurrentFree(p1, 6);
ConcurrentFree(p2, 8);
ConcurrentFree(p3, 1);
}
我们释放第一个对象后,对应的自由链表中的内存块只有一个,并不会将该自由链表当中的对象进一步还给central cache。

释放第二个对象和第一个对象情况类似,并不满足将内存块还给central cache的条件。
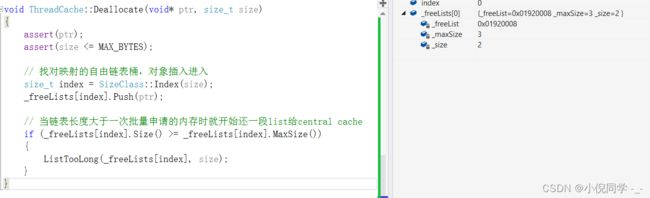
释放第三个对象时,就需要将内存块还给central cache了。
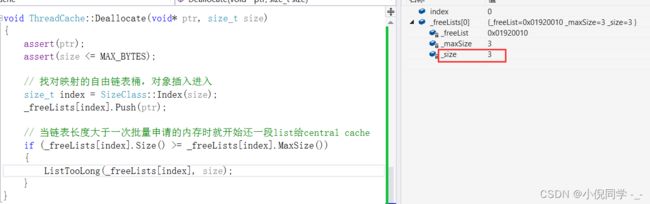
将内存块还给central cache首先要将内存块的自由链表切分出来

通过映射找到内存块对应的span,再将内存块链表依次头插入span结构的自由链表中。当span的切分出去的所有小块内存都还回来时,这个span就可以再回收给page cache。
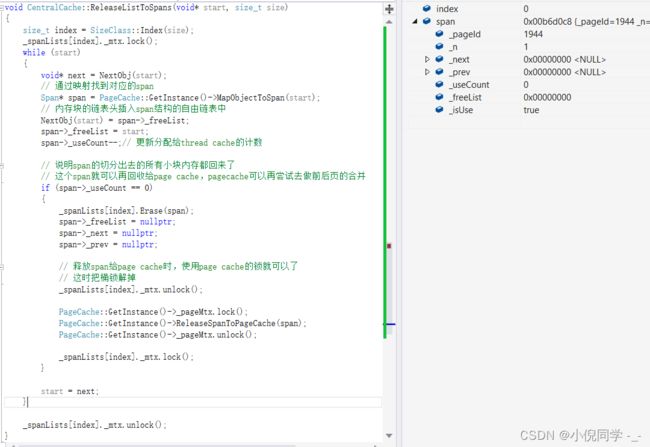
因为申请内存时将128页span分成了1页span和127页span,所以central cache释放合成的1页span应该向后合并。这里重新将1页span和127页span合并成128页span,并将这128页的span插入到page cache对应的哈希桶(128号桶)中。之后再建立该span与其首尾页的映射,完成释放流程。
使用定长内存池配合脱离使用new
tcmalloc是要在高并发场景下替代malloc进行内存申请的,因此tcmalloc在实现的时,其内部是不能调用malloc函数的,我们当前的代码中存在通过new获取到的内存,而new在底层实际上就是封装了malloc。
我们当前的代码中用到new的地方就是page cache层向内存申请Span结构,我们可以利用一开始实现的定长内存池,来申请Span结构。为此需要在page cache类中添加如下成员变量
//单例模式
class PageCache
{
public:
//...
private:
ObjectPool<Span> _spanPool;
};
然后将代码中使用new的地方替换为调用定长内存池当中的New函数,将代码中使用delete的地方替换为调用定长内存池当中的Delete函数
//申请span对象
Span* span = _spanPool.New();
//释放span对象
_spanPool.Delete(span);
此外,每个线程第一次申请内存时都会创建其专属的thread cache,而这个thread cache目前也是new出来的,我们也需要对其进行替换,其次如果申请的内存大于256kb,可以交付page cache处理,就不需要创建ThreadCache了
// 原版
static void* ConcurrentAlloc(size_t size)
{
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
return pTLSThreadCache->Allocate(size);
}
// 优化后的版本
static void* ConcurrentAlloc(size_t size)
{
// 如果申请的内存大于256kb,直接向page cache要
if (size > MAX_BYTES)
{
size_t alignSize = SizeClass::RoundUp(size);
size_t kpage = alignSize >> PAGE_SHIFT;
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(kpage);
span->_objSize = size;
PageCache::GetInstance()->_pageMtx.unlock();
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
return ptr;
}
else
{
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
//pTLSThreadCache = new ThreadCache;
static ObjectPool<ThreadCache> tcPool;
pTLSThreadCache = tcPool.New();
}
return pTLSThreadCache->Allocate(size);
}
}
SpanList的构造函数中也用到了new,因为SpanList是带头循环双向链表,所以在构造期间我们需要申请一个span对象作为双链表的头结点。
//带头双向循环链表
class SpanList
{
public:
SpanList()
{
_head = _spanPool.New();
_head->_next = _head;
_head->_prev = _head;
}
private:
Span* _head;
static ObjectPool<Span> _spanPool;
};
释放对象时优化为不传对象大小
malloc在释放对象时只需要传入对象的指针即可,但是我们当前实现的高并发内存池还需要传入释放对象的大小,能不能优化一下呢?
当我们释放对象时,通过映射可以直接从对象的span中获取到该对象的大小,准确来说获取到的是对齐以后的大小。那我们可以将传入的地址映射到对应的span,通过span的成员变量获取释放对象的大小。
// 原版
static void ConcurrentFree(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
// 优化后的版本
static void ConcurrentFree(void* ptr)
{
// 通过地址映射到span
Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);
// 获取释放内存的大小
size_t size = span->_objSize;
if (size > MAX_BYTES)// 大于256KB的对象,直接交付page cache判断
{
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
}
else
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
}
多线程环境下对比malloc测试
之前我们只是对代码进行了一些基础的单元测试,下面我们在多线程场景下对比malloc进行测试。
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
//v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(ConcurrentAlloc(16));
//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
int main()
{
size_t n = 10000;
cout << "==========================================================" <<
endl;
BenchmarkConcurrentMalloc(n, 4, 10);
cout << endl << endl;
BenchmarkMalloc(n, 4, 10);
cout << "==========================================================" <<
endl;
return 0;
}
函数的参数含义如下
- ntimes:单轮次申请和释放内存的次数。
- nworks:创建的线程数。
- rounds:申请和释放几轮。
在测试函数中,我们记录每轮次申请和释放所花费的时间,然后将其累加到对应的malloc_costtime和free_costtime上。最后我们获得数据:nworks个线程跑rounds轮,每轮申请和释放ntimes次,这个过程申请所消耗的时间、释放所消耗的时间、申请和释放总共消耗的时间。
注意:为了保证线程安全,我们在定义变量时用了atomic类模板,保证操作是原子性的。
固定大小内存的申请和释放
v.push_back(malloc(16));
v.push_back(ConcurrentAlloc(16));
我们让4个线程执行10轮操作,每轮申请释放1000次(使用Release版)
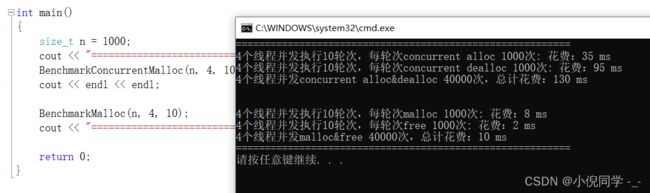
从结果中我们看到还是malloc效率更高一些。
不同大小内存的申请和释放
我们利用随机函数来申请和释放不同大小的内存
v.push_back(malloc((16 + i) % 8192 + 1));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));

相比之下还是malloc更高一些。
性能瓶颈分析
通过前面的测试,我们实现的tcmalloc效率还是有待提高的,我们可以通过VS编辑器的性能分析的工具来查看项目的瓶颈在哪。

做如下选项,再点下一步
继续下一步
 点击完成,等待片刻后就可得到报告了
点击完成,等待片刻后就可得到报告了

从报告中可看出释放函数中的锁消耗了大量时间

使用基数树进行优化
当前项目在页号跟span的映射上面消耗占比很大(因为map使用时需要加锁解锁),为此tcmalloc设计者针对这一点使用了基数树进行优化,使得在读取映射关系时可以做到不加锁。
基数树
基数树实际上就是一个分层的哈希表,根据所分层数不同可分为单层基数树、二层基数树、三层基数树等。
单层基数树实际采用的就是直接定址法,每一个页号对应span的地址就存储数组中在以该页号为下标的位置。

单层基数树
template <int BITS>
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS;//页的数目
void** array_;//存储映射关系的数组
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap1() {
size_t size = sizeof(void*) << BITS;// 开辟的数组大小
size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);// 按页对齐后的大小
array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);// 向堆申请空间
memset(array_, 0, sizeof(void*) << BITS);// 对申请到的内存进行清理
}
void* get(Number k) const {
if ((k >> BITS) > 0) {
return NULL;
}
return array_[k];// 返回该页号对应的span
}
void set(Number k, void* v) {
assert((k >> BITS) == 0); // 确保k的范围在[0, 2^BITS-1]
array_[k] = v; // 建立映射
}
};
代码中的非类型模板参数BITS表示存储页号最多需要比特位的个数。在32位下我们传入的是32-PAGE_SHIFT,在64位下传入的是64-PAGE_SHIFT。
但是一层基数树只能用于32位平台下,在64位平台下,如果一页为8k也就是213 字节,此时存储页号需要264÷213 = 2 51,51个比特位。而且64位平台下指针的大小是8字节,基数数组的大小为 2 51 * 8 = 2 54 字节,远远超出了计算机能接受的范围,在64位平台下我们使用3层以上的基数树。
二层基数树
二层基数树相对于单层基数树是分两次映射,将数据先取一部分比特位在基数树的第一层进行映射,映射后得到对应的第二层,然后用剩下的比特位在基数树的第二层进行映射。

// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const int ROOT_BITS = 5; // 第一层对应页号的前5个比特位
static const int ROOT_LENGTH = 1 << ROOT_BITS; // 第一层存储元素的个数
static const int LEAF_BITS = BITS - ROOT_BITS;// 第二层对应页号的其余比特位
static const int LEAF_LENGTH = 1 << LEAF_BITS;// 第二层存储元素的个数
// 第一层数组中存储的元素类型
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // 第一层数组
void* (*allocator_)(size_t); // Memory allocator
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap2() {
memset(root_, 0, sizeof(root_));// 将第一层的空间进行清理
PreallocateMoreMemory();// 直接将开辟第二层
}
void* get(Number k) const {
const Number i1 = k >> LEAF_BITS;//第一层对应的下标
const Number i2 = k & (LEAF_LENGTH - 1);//第二层对应的下标
if ((k >> BITS) > 0 || root_[i1] == NULL) {//页号值不在范围或没有建立过映射
return NULL;
}
return root_[i1]->values[i2];//返回该页号对应span的指针
}
void set(Number k, void* v) {
const Number i1 = k >> LEAF_BITS;// 第一层对应的下标
const Number i2 = k & (LEAF_LENGTH - 1);// 第二层对应的下标
ASSERT(i1 < ROOT_LENGTH);
root_[i1]->values[i2] = v;// 建立该页号与对应span的映射
}
// 确保映射[start,start_n-1]页号的空间是开辟好了的
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)// 页号超出范围
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {// 第一层i1下标指向的空间未开辟
//开辟对应空间
static ObjectPool<Leaf> leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;//继续后续检查
}
return true;
}
void PreallocateMoreMemory() {
// Allocate enough to keep track of all possible pages
Ensure(0, 1 << BITS);// 将第二层的空间全部开辟好
}
};
三层基数树
三次基数树就是做三次映射

// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:
// How many bits should we consume at each interior level
static const int INTERIOR_BITS = (BITS + 2) / 3; //第一、二层对应页号的比特位个数
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;//第一、二层存储元素的个数
// How many bits should we consume at leaf level
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;//第三层对应页号的比特位个数
static const int LEAF_LENGTH = 1 << LEAF_BITS;//第三层存储元素的个数
// Interior node
struct Node {
Node* ptrs[INTERIOR_LENGTH];
};
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Node* root_; // Root of radix tree
void* (*allocator_)(size_t); // Memory allocator
Node* NewNode() {
Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));
if (result != NULL) {
memset(result, 0, sizeof(*result));
}
return result;
}
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {
allocator_ = allocator;
root_ = NewNode();
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);//第一层对应的下标
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);//第二层对应的下标
const Number i3 = k & (LEAF_LENGTH - 1); //第三层对应的下标
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];//返回该页号对应span的指针
}
void set(Number k, void* v) {
ASSERT(k >> BITS == 0);
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;//建立该页号与对应span的映射
}
//确保映射[start,start+n-1]页号的空间是开辟好了的
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);//第一层对应的下标
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);//第二层对应的下标
// Check for overflow
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_->ptrs[i1] == NULL) {
Node* n = NewNode();
if (n == NULL) return false;
root_->ptrs[i1] = n;
}
// Make leaf node if necessary
if (root_->ptrs[i1]->ptrs[i2] == NULL) {
Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
}
};
利用基数树修改原代码
下面就要根据基数树对原先我们实现的代码进行一些修改。
我们需要PageCache类当中的unorder_map用基数树进行替换
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
// 替换为
TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;
对需要建立页号与span的映射的地方,修改为调用基数树当中的set函数。
_idSpanMap[span->_pageId] = span;
// 修改为
_idSpanMap.set(span->_pageId, span);
对需要读取某一页号对应的span时,修改为调用基数树当中的get函数
auto ret = _idSpanMap.find(nextId);
// 修改为
auto ret = (Span*)_idSpanMap.get(nextId);
并且现在PageCache类向外提供的,用于读取映射关系的MapObjectToSpan函数内部就不需要加锁了。
为什么读取基数树映射关系时不需要加锁?
当某个线程在读取映射关系时,可能有另外一个线程正在建立其他页号的映射关系,因为map的底层数据结构是红黑树,unordered_map的底层数据结构是哈希表,它们在建立映射关系时可能会改变原先的结构(红黑树会旋转,哈希表会扩容),从而导致数据不一致的问题,所以在映射读取时需要加锁。
基数树就不一样了,基数树的空间一旦开辟好了就不会发生变化,因此无论什么时候去读取页的映射,都是对应在一个固定的位置进行读取的,并且我们不会同时对同一个页进行读取映射和建立映射的操作。
修改后的性能测试
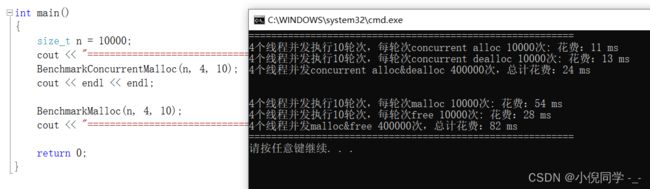
申请和释放固定内存
申请和释放动态内存
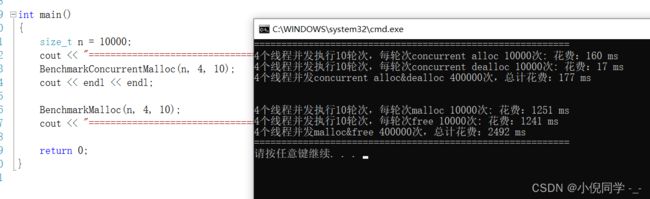
性能相对之前有了很大的提高。
打包成动静态库
我们可以把当前的项目打包成动静态库,方便之后的使用
打包成动静态库方法如下
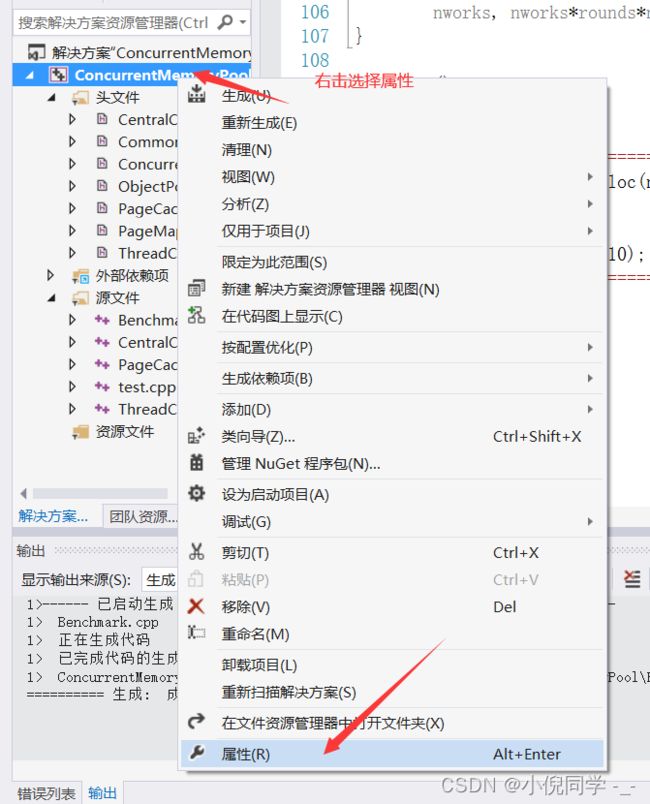
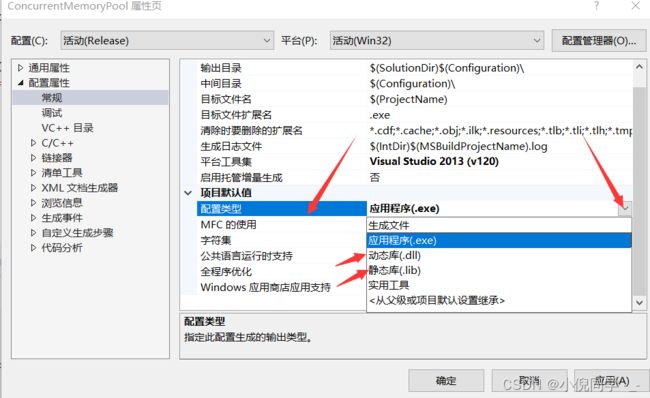
在弹出的窗口下进行选择。
项目源码
tcmalloc