深度学习实战——基于pytorch写的一个猫狗分类的模型——学习总结
写在前面
本学习总结主要目的
1.怕以后忘记,到时候翻来看看,
2.梳理一下项目过程,便于工业化生产(哈哈)
3.敲一遍代码加深记忆
4.帮助他人,方便入门同学能够容易入门
本过程主要设计到的内容
1.torch.nn,nn模块下的Module类,组件类,neture network
2.tensor,巩固tensor的方法
3.torch.utils.data里面DataLoader的用法
4.torchvision里面transforms的用法
5.torchvision.datasets里面ImageFolder的用法
ImageFolder是主要的,我做这个主要目的就是学习这个类的使用方法
项目结构
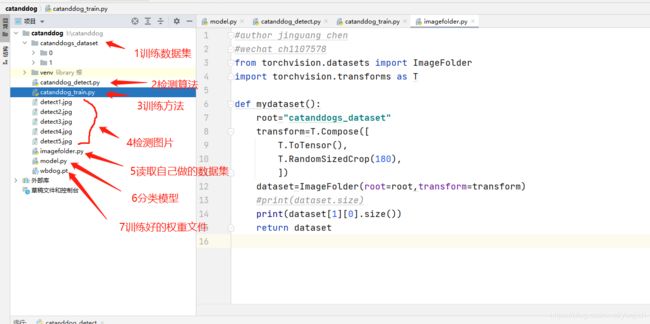
上面这个是我的项目结构文件,主要有四个py文件,
序号6是model模型文件,里面定义了一个2分类模型
序号5是数据集制作文件,怎么把自己收集的猫狗图片整理成可以供torch训练的数据集形式
序号3是训练算法,直接开始训练,训练完成后会生成一个pt的权重文件,这里的权重文件是wbdog.pt
序号2是检测算法,我下载了序号4的几张图片,训练完毕后,检测一下输出结果
序号1是数据集,是我从网上找的70多张猫狗图片,下面分了两个文件夹0和1,其中0是猫,1是狗
到这里基本所有的结构介绍完毕,下面我就贴一下代码,代码中难理解的部分都注释有print,可以打印看一下具体语句的输出,另外所有代码几乎是一句,没有嵌套,也是为了以后方便阅读。
数据集结构
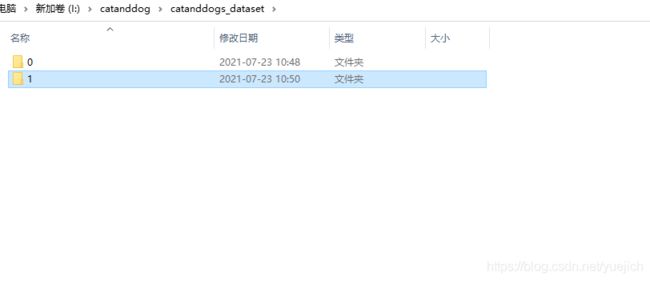
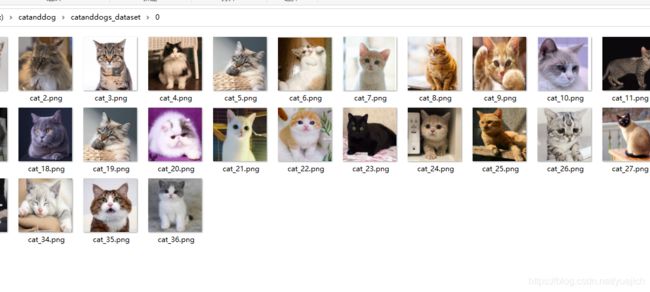
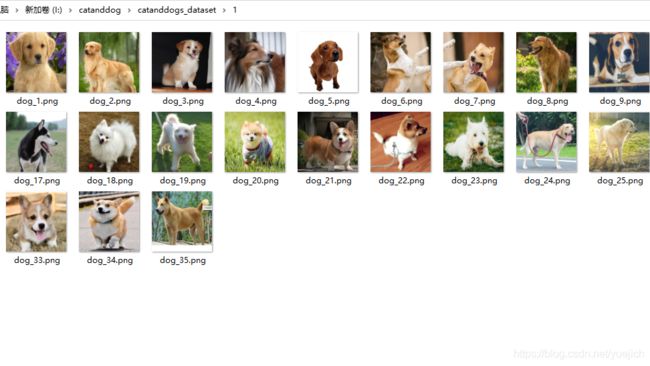
这里有35和36张图片,总共是71张训练集图片,这里有一个疑问,png是三通道的,我也不是很清楚之后训练怎么变成3通道了。
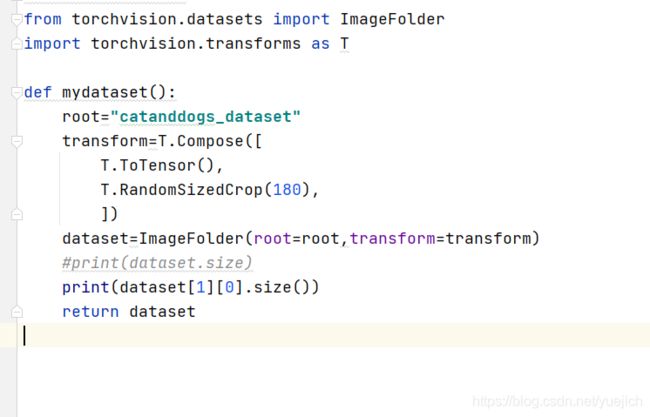
也就是这里的代码ImageFolder怎么把png四个通道转成3通道的,因为模型的第一层的卷积我的in_channel是3.
贴代码
1 imagefolder.py
#author jinguang chen
#wechat ch1107578
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
def mydataset():
root="catanddogs_dataset"
transform=T.Compose([
T.ToTensor(),
T.RandomSizedCrop(180),
])
dataset=ImageFolder(root=root,transform=transform)
#print(dataset.size)
print(dataset[1][0].size())
return dataset
2 catanddog_train.py
#author jinguang chen
#wechat ch1107578
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from imagefolder import mydataset
from model import Net
dataset=mydataset()
def train(EPOCH):
train_loader = DataLoader(dataset, batch_size=24, shuffle=True)
# 选择使用的设备
device = 'cuda'
print(device)
model = Net()
model.to(device)
# 训练模式
model.train()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 由命令行参数决定是否从之前的checkpoint开始训练
loss = 0.0
epoch = 0
while epoch < EPOCH:
running_loss = 0.0
for i, data in enumerate(train_loader):
# 这里取出的数据就是 __getitem__() 返回的数据
#print(i)
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outs = model(inputs)
#print(outs.shape)
#print(labels.shape)
loss = criterion(outs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 3 == 1: # every 200 steps
print('epoch %5d: batch: %5d, loss: %f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
# 保存 checkpoint
if epoch % 10 == 9:
print('Save checkpoint...')
print('loss', loss)
epoch += 1
torch.save(model.state_dict(), 'wbdog.pt')
print('Finish training')
# 主程序
if __name__ == '__main__':
EPOCH = 500
train(EPOCH)
3 model.py
#author jinguang chen
#wechat ch1107578
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# input 180*180
self.conv1 = nn.Conv2d(3, 20, 5) # 3个参数分别是in_channels,out_channels,kernel_size,还可以加padding
# output 20,180-5/1+1 =176
self.pool = nn.MaxPool2d(2, 2)
# 88*88 88-5/1+1=84
self.conv2 = nn.Conv2d(20, 16, 5)
# 84*84
#pool 42*42*16
self.fc1 = nn.Linear(28224, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 2) # 命令行参数,后面解释
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
# print("xshape",x.shape)
x = x.view(-1, 28224)
# print(x.shape)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
x = F.log_softmax(input=x, dim=1)
return x
4 catanddog_detect.py
#author jinguang chen
#wechat ch1107578
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from model import Net
import torch as t
from torchvision import transforms as T
def detect(model,image):
print("预测开始:")
model.eval()
wt='wbdog.pt'
model.load_state_dict(t.load(wt))
#image=t.from_numpy(image)
pred_labels=model(image.cuda())
predicted=t.max(pred_labels,1)[1].cpu()
print(type(predicted))
print(predicted.shape)
num=predicted.numpy()
print("num:",num[0])
str=num_to_string(num[0])
print(str)
def num_to_string(num):
numbers = {
0 : "cat",
1 : "dog",
}
return numbers.get(num, None)
def load_image(image_path):
image=Image.open(image_path)
print('channels',len(image.split()))
image=image.convert('RGB')
#plt.imshow(image)
#plt.show()
image = image.resize((180, 180))
plt.imshow(image)
plt.show()
print(image.size)
totensor=T.ToTensor()
image=totensor(image).reshape(1,3,180,180)
#image=np.array(image).reshape(1,3,180,180).astype('float32')
#image=image/255-0.5/0.5
print(image)
print(image.size())
return image
if __name__=="__main__":
model=Net().cuda()
image_path = r"detect2.jpg"
image=load_image(image_path)
detect(model=model,image=image)
写在最后
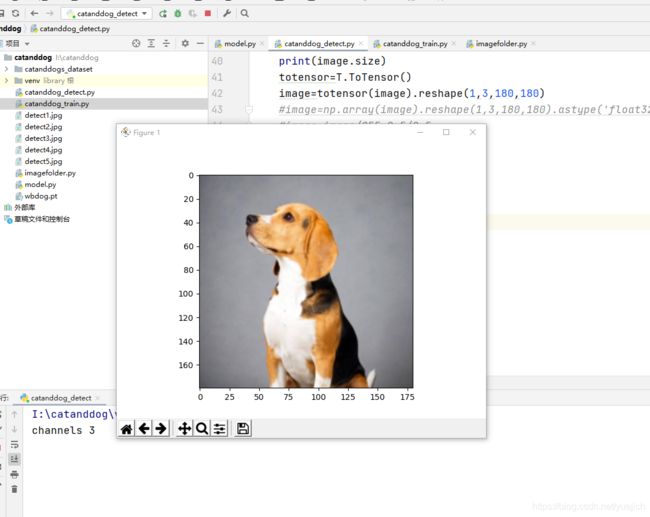
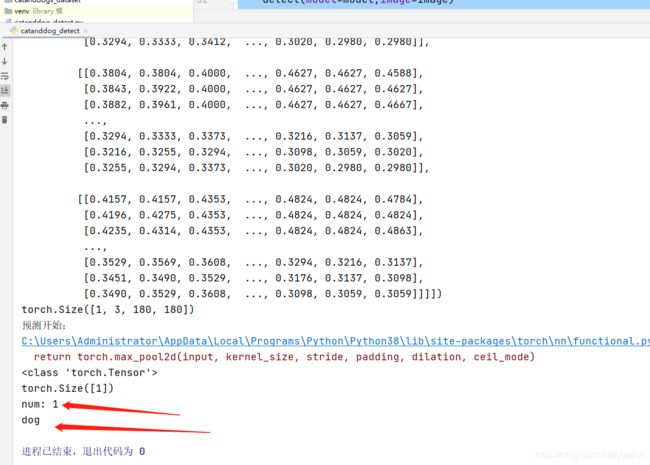
看一下效果
运行catanddog_detect.py
截图
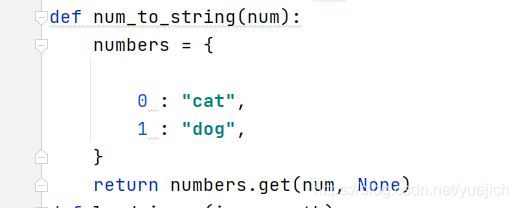
这里定义了一个方法,把数字映射到dog和cat