python subprocess 实时输出_Python标准库初探之subprocess
一
subprocess简介
人生苦短,我用Python。今天给大家带来一个在Python脚本中启动进程的利器--subprocess。人们都说Python是一个胶水语言,可以方便地在多平台上调用其他指令,从而把它们联系在一起。subprocess就是其中一个强力粘合剂。
subprocess能够为linux/windows平台指令创建子过程(子进程),从而去执行这些指令。并且能够与子过程的标准输出(stdout)、标准输入(stdin)、标准错误输出(stderr)通信,待子过程结束后还可以得到子过程的return code。
subprocess提供了使用起来非常方便的高级接口,以及功能强大的底层接口,下面我们针对Version3.6.11来分别说一说。
二
subprocess的高级接口:run()
从Python3.5版本开始,subprocess加入了run()这个高级接口,目的是替代之前旧的三个高级接口:
v call()
v check_call()
v check_output()
上面这3个老接口在这里就不细说了,如果想了解,可以看下面的文档:
https://docs.python.org/3.6/library/subprocess.html#older-high-level-api
之所以成为高级接口,自然是使用便利。
run()方法的内部封装了底层的subprocess.popen对象,很多参数被传递给subprocess.popen对象,通过subprocess.popen对象的若干方法实现子过程创建及执行结果返回功能。
下面来看看run()接口的声明:
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False,
cwd=None, timeout=None, check=False, encoding=None, errors=None, env=None)
run()被调用后会一直等待被执行的外部指令执行完毕,即子过程完毕。完毕后返回一个CompletedProcess类型实例,从这个返回实例中可以得到子过程的return code、子过程的stdout的内容、子过程的stderr的内容(如果需要的话)等等。可以发现run()是一个同步调用,会一直等待子过程结束后,主进程才会进行执行。(关于CompletedProcess类型的具体细节可以参考后续章节)
run()声明中的参数是比较常用的参数,下面我们来看看这些常用的参数是如何使用的:
1、args
args是要被执行的指令,一般是一个列表,也可以是一个字符串(此时后面的shell必须被设置为True,或者字符串中只包含指令而没有参数)
>>> subprocess.run("ls")
kafka package_list.txt
CompletedProcess(args='ls', returncode=0)
第一行中的"ls"是要被执行的指令,第二行是ls指令的标准输出,第三行是run()方法返回的CompletedProcess实例内容。可以看到由于run()没给其他的任何参数,因此返回的CompletedProcess实例包含的内容是最小集合,仅包含指令和指令的返回值。(即程序的执行结果,linux上可以通过$?查看)
>>> subprocess.run(["ls","-l"])
total 3204
drwxrwxrwx 1 biekanbiekan 512 Jul 2 19:26 kafka
-rw-rw-rw- 1 biekanbiekan3279795 May 23 15:28 package_list.txt
CompletedProcess(args=['ls', '-l'], returncode=0)
第一行的参数是个列表(list),其中包含指令和指令的参数,第二行到第四行是ls指令的标准输出。
上面两个例子是run()方法最基本的使用场景,同步执行外部指令,获得指令的执行返回结果。
2、input
input参数允许用户向子过程传递数据,默认是字节序,也可以是字符串(此时必须给encoding或者error参数,告诉subprocess以何种编码解析字符串)。input参数携带的数据会传递给popen.comunicater,由popen来处理父过程与子过程的交互。
#include
int main()
{
char recv_buf[256] = {0};
std::cin >> recv_buf;
std::cout << recv_buf << std::endl;
return 0;
}
上面是一个测试小程序的代码,从标准输入获得字符串,然后打印出来。编译后的可执行程序为a.out。我们先用默认的字节序向子过程传递数据:
>>> subprocess.run(["./a.out"], input=b"1234567890")
1234567890
CompletedProcess(args=['./a.out'], returncode=0)
第二行是子过程接收父过程传递进来的字节序数据。然后,我们再尝试以字符串的形式向子过程传递数据:
>>> import subprocess
>>> subprocess.run(["./a.out"], input="1234567890", encoding="utf-8")
1234567890
CompletedProcess(args=['./a.out'], returncode=0)
第三行是子过程接收父过程传递进来的字符串数据。
3、stdout
stdout参数的默认值是None,一旦赋值为subprocess.PIPE便允许父过程获取子过程的标准输出。子过程的标准输出内容会在CompletedProcess实例的stdout属性中返回。
>>> import subprocess
>>> subprocess.run(["ls", "-l"], stdout=subprocess.PIPE)
CompletedProcess(args=['ls', '-l'], returncode=0, stdout=b'total 0\n-rw-rw-rw- 1 biekanbiekan202 Jul 12 17:42 callSleep.py\n-rw-rw-rw- 1 biekanbiekan 70 Jul 12 16:35 sleep.py\n')
第四行中的stdout是子过程ls的标准输出,其中的值为字节序(或者说binary mode)
下面我们再看一个例子:
>>> subprocess.run(["ls", "-l"], stdout=subprocess.PIPE, encoding="utf-8")
CompletedProcess(args=['ls', '-l'], returncode=0, stdout='total 0\n-rw-rw-rw- 1 biekanbiekan202 Jul 12 17:42 callSleep.py\n-rw-rw-rw- 1 biekanbiekan 70 Jul 12 16:35 sleep.py\n')
由于encoding参数被赋予了“utf-8”,stdout的值不再是字节序,而是utf-8编码的字符串。通过上面的例子我们发现父过程可以通过run()的CompletedProcess返回实例,获得子过程的标准输出(CompletedProcess.stdout)。
4、stderr
stderr参数的默认值为None,一旦被赋值为subprocess.PIPE便允许父过程获取子过程的标准错误输出。子过程的标准错误输出内容会在CompletedProcess实例的stderr属性中返回。我们来看一个例子:
>>> subprocess.run(["ls", "file.txt"], stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding="ascii")
CompletedProcess(args=['ls', 'file.txt'], returncode=2, stdout='', stderr="ls: cannot access 'file.txt': No such file or directory\n")
上面的例子是通过run()方法执行了“ls file.txt”指令,由于当前目录下没有file.txt文件,因此ls会输出错误信息。run()的stdout参数被赋予了subprocess.PIPE,但是由于ls的标准输出为空,因此CompletedProcess实例的stdout属性也是空。run()的stderr参数被赋予了subprocess.PIPE,因此CompletedProcess实例的stderr属性返回了ls的标准错误信息。
5、check
check入参默认是False,当被设置为True时且子过程的返回值不是0的时候,subprocess会抛出CalledProcessError异常。从CalledProcessError中我们可以得到run()的入参列表、返回值、stdout和stderr(前提是stdout和stderr入参被使用)。
如果要详细了解CalledProcessError中各属性的用法,可以参考下面的链接:
https://docs.python.org/3.6/library/subprocess.html#subprocess.CalledProcessError
下面是一个测试小程序,程序返回3:
#include
int main()
{
std::cout << "exit with 3." << std::endl;
return 3;
}
编译后生成的可执行程序为a.out。
我们来看看check被设置为True时是怎么样的结果:
>>> import subprocess
>>> subprocess.run(["./a.out"], check=True)
exit with 3.
Traceback (most recent call last):
File "", line 1, in
File "/usr/lib/python3.6/subprocess.py", line 418, in run
output=stdout, stderr=stderr)
subprocess.CalledProcessError: Command '['./a.out']' returned non-zero exit status 3.
第三行是测试程序的标准输出。第四行到第八行是subprocess抛出的异常,其中第八行可以看到CalledProcessError异常中携带的参数信息、返回值信息。如果上面的subprocess.run()是在某个脚本中被调用,此时需要对subprocess抛出的异常进行捕捉并处理,不然脚本会被打断。
6、timeout
timeout参数允许用户给子过程设定超时时间(子过程的超时时间单位是秒),一旦超过超时时间,subprocess会抛出subprocess.TimeoutExpired异常;如果没有超时就执行完了子过程,则返回一个CompletedProcess类型实例。
subprocess.TimeoutExpired的具体属性如下:
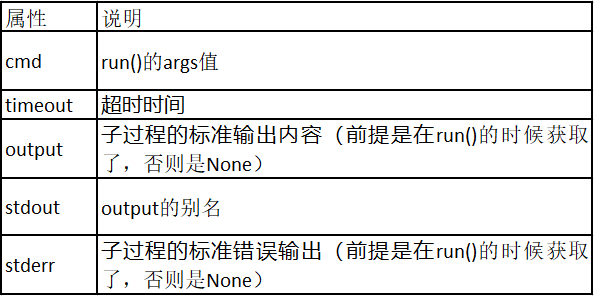
下面看一个子过程超时的例子:
biekan@PV-1:~$ cat sleep.py
import time
print("start sleep.")
time.sleep(10)
print("end sleep.")
sleep.py是一个测试用脚本,脚本中有一个sleep 10秒的等待。
biekan@PV-1:~$ cat callSleep.py
import subprocess
try:
ret = subprocess.run(["python3", "sleep.py"], timeout=1)
except subprocess.TimeoutExpired as e:
print("cmd:")
print(e.cmd)
print("timeout:")
print(e.timeout)
callSleep.py调用sleep.py,调用时设定了超时时间为1秒。脚本中捕捉了subprocess抛出的TimeoutExpired异常,并且输出了run()的cmd参数和超时的时间。
biekan@PV-1:~$ python3 callSleep.py
start sleep.
cmd:
['python3', 'sleep.py']
timeout:
0.9998359999999593
第二行是子过程的标准输出内容,执行完“start sleep.”的输出后发生了子过程超时。第三行到第六行是捕捉到的异常中的信息由父过程输出出来。
7、env
首先在当前用户下设置环境变量ENV_TESTING的值为ON:
biekan@PV-1:~$ env|grep ENV_TESTING
ENV_TESTING=ON
然后再创建一个小程序,在程序中获取环境变量ENV_TESTING的值并打印:
biekan@PV-1:~$ cat getEnv.py
import os
#print(os.environ)
# 取得ENV_TESTING环境变量的值
env_testing_value = os.environ["ENV_TESTING"]
print(env_testing_value)
我们在python3的交互环境下通过subprocess.run()执行一下这个小程序:
>>> subprocess.run("python3 getEnv.py", shell=True)
ON
CompletedProcess(args='python3 getEnv.py', returncode=0)
我们发现子过程确实能获取到已经设定好的ENV_TESTING环境变量。但是当我们想要这个子过程临时获得ENV_TESTING环境变量时值为OFF,我们可以这样做:
>>> import subprocess
>>> subprocess.run("python3 getEnv.py", shell=True, env={"ENV_TESTING":"OFF"})
OFF
CompletedProcess(args='python3 getEnv.py', returncode=0)
我们使用env参数给子过程传递指定的环境变量值,
biekan@PV-1:~$ env|grep ENV_TESTING
ENV_TESTING=ON
而当前用户的环境变量值却保持不变。
这就是subprocess.run()的env参数的作用,它可以向子过程传递指定的环境变量值。但是要注意,一旦使用了env参数,就必须将子过程需要的全部环境变量都传递进去,否则子过程将找不到某些需要但是又没有通过env参数传递进去的环境变量的值。
三
subprocess的低层接口:popen创建
使用subprocess的run()方法能够解决子过程同步调用额问题,如果想要子过程异步与主过程,甚至在异步过程中精确控制、查看子过程的状态,就要用到subprocess的低层接口popen对象了。下面我们来看看popen对象的构造函数:
class subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=(), *, encoding=None, errors=None)
参数非常复杂,我们结合例子说说几个常用参数的用法,进而快速掌握popen对象的基本使用。
如果想要更加深入的了解,可以参考下面的文档:
https://docs.python.org/3.6/library/subprocess.html#popen-constructor
1、args
args参数是最重要最常用的参数之一,与run()的args一样,args参数建议传入一个序列(sequence),代表要作为子过程执行的指令。同样,args也可以传入字符串,此时shell参数必须为True。
下面看一个Popen对象创建的最简单的例子,只使用了args参数。testPopen.py是一个测试Popen的python3脚本,里面先后以子过程的方式分别执行了“firstProcess.py”和“secondProcess.py”。然后主进程等待了10秒后退出。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat testPopen.py
import subprocess
import time
print("call firstProcess.")
subprocess.Popen(["python3","firstProcess.py"])
print("call secondProcess.")
subprocess.Popen(["python3","secondProcess.py"])
time.sleep(10)
print("mainProcess end.")
下面是“firstProcess.py”的内容,这个子过程能活30秒。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat firstProcess.py
import time
time.sleep(30)
print("first process end.")
“secondProcess.py”只能活5秒,比主进程和“firstProcess.py”活的都短。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat secondProcess.py
import time
time.sleep(5)
print("second process end.")
下面我们来看看testPopen.py的运行结果:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3 testPopen.py
call firstProcess.
call secondProcess.
second process end.
mainProcess end.
biekan@LAPTOP-EJ8UHBOB:~/tmp$ ps -ef|grep python3
zhangti+ 80 1 0 15:39 tty1 00:00:00 python3 firstProcess.py
zhangti+ 83 4 0 15:40 tty1 00:00:00 grep --color=auto python3
biekan@LAPTOP-EJ8UHBOB:~/tmp$ first process end.
“firstProcess.py”和“secondProcess.py”在主进程中被分别执行,“firstProcess.py”先,“secondProcess.py”后。但是由于“firstProcess.py”能活30秒,比主进程和“secondProcess.py”都要久,所以“secondProcess.py”进程最先结束了,之后主进程也结束了(通过[ps -ef|grep python3]的结果可以看出)。最后“firstProcess.py”在活了30秒后终于结束了。
subprocess.Popen()会返回一个Popen对象,这里我们暂时没有去使用它。Popen对象被创建后,其子过程也就开始执行了。此时主进程不会等待子过程执行结束,甚至主进程没有管子过程是否结束自己就先结束了。
subprocess.Popen()真是“异步”得很彻底了。
2、stdin、stdout、stderr
stdin、stdout、stderr重定向了子过程的标准输入、标准输出和标准错误输出。
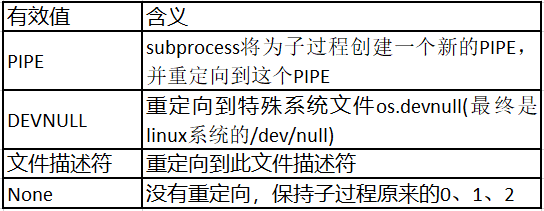
通过上述的三个参数可以实现主进程与子过程之间的信息交互。
3、cwd
cwd参数的作用是在启动子过程之前将当前working路径变更为cwd指定的路径。cwd接受字符串和like-path对象,关于like-path对象的内容请参见下面的链接,这里就不再详细说明了:
https://docs.python.org/3.6/glossary.html#term-path-like-object
下面我们看一个接收字符串working path的例子:
当前目录下有如下文件夹和文件:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ ll
total 12
drwxrwxrwx 1 biekanbiekan 512 Jul 30 16:48 ./
在dir_for_test_cwd/目下有一个我们本次测试用的Py脚本:
biekan@LAPTOP-EJ8UHBOB:~/tmp/dir_for_test_cwd$ ll
total 0
drwxrwxrwx 1 biekanbiekan512 Jul 30 16:49 ./
drwxrwxrwx 1 biekanbiekan512 Jul 30 16:48 ../
-rw-rw-rw- 1 biekanbiekan 18 Jul 30 16:49 targetPy.py
现在我们在当前目下进入python3的交互环境:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
下面我们使用cwd来改变一下执行子过程前的working path,看看能不能在当前的目录下调用到dir_for_test_cwd下的Py脚本。
>>> import subprocess
>>> subprocess.Popen(["python3","targetPy.py"],cwd="./dir_for_test_cwd")
>>> find it.
果然以子过程的方式调用到了targetPy.py,“find it.”就是子过程输出的信息。那么现在我们看看当前的工作路径改变了么?
>>> import os
>>> os.listdir()
['a.out', 'blankFile.txt', 'dir_for_test_cwd', 'exit_no_zero.cpp', 'firstProcess.py', 'recv_string.cpp', 'secondProcess.py', 'testForPass_fds.py', 'testPopen.py']
>>> quit()
biekan@LAPTOP-EJ8UHBOB:~/tmp$ ll
total 12
drwxrwxrwx 1 biekanbiekan 512 Jul 30 16:48 ./
drwxr-xr-x 1 biekanbiekan 512 Jul 31 09:56 ../
-rwxrwxrwx 1 biekanbiekan9128 Jul 29 11:15 a.out*
-rw-rw-rw- 1 biekanbiekan 6 Jul 29 11:21 blankFile.txt
drwxrwxrwx 1 biekanbiekan 512 Jul 30 16:49 dir_for_test_cwd/
-rw-rw-rw- 1 biekanbiekan 90 Jul 7 14:48 exit_no_zero.cpp
-rw-rw-rw- 1 biekanbiekan 56 Jul 27 15:21 firstProcess.py
-rw-rw-rw- 1 biekanbiekan 135 Jul 7 10:34 recv_string.cpp
-rw-rw-rw- 1 biekanbiekan 56 Jul 27 15:22 secondProcess.py
-rw-rw-rw- 1 biekanbiekan 294 Jul 29 11:26 testForPass_fds.py
-rw-rw-rw- 1 biekanbiekan 227 Jul 27 15:38 testPopen.py
结果是没有改变,cwd只是临时改变了working path,调用完tartgetPy.py后又回到了原本的工作路径。
4、restore_signals
restore_signals的值范围为True/False,默认值为True。为True时表示在python中被加入到SIG_IGN中的信号,对于子过程来说都被重新加入到了SIG_DFL了中,这点在使用时要特别注意。那么有哪些信号是被这样处理的呢?
v SIGPIPE
v SIGXFZ
v SIGXFSZ
5、env
与subprocess.run()的env参数用法一致。
四
Popen对象
很多时候我们并不希望异步调用子过程时放任子过程随意的运行,我们总是希望能够查看子过程的运行状态,控制它的运行。我们可以通过subprocess.Popen()返回的Popen对象实现以上需求。
1、Popen.poll()
检查子过程是否执行完毕,如果执行完毕则返回子过程的returncode,否则返回None。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat watchCldProSts.py
import subprocess
watchCldProSts.py是一个测试脚本,脚本中以子过程的方式执行firtProcess.py,执行后立即检查子过程是否执行完毕。然后等待了35秒,再次检查子过程是否执行完毕。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3 watchCldProSts.py
call firstProcess.py
None
first process end.
0
由于firstProcess.py会活30秒,因此第一次检查时返回的是None(子过程没有执行完毕)。子过程执行完毕后进行了第二次检查,返回的是0,说明子过程正常结束。
2、wait(timeout=None)
等待子过程结束,参数timeout可以设置超时时间,默认是None(死等)。如果在超时时间内子过程结束,则返回returncode,否则抛出subprocess.TimeoutExpired异常,可以通过捕获异常的方式进行后续处理。
下面来看一个死等的例子:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat testDeadWait.py
import subprocess
import time
print('call firstProcess.py')
obj = subprocess.Popen(["python3","firstProcess.py"])
ret = obj.wait()
print(ret)
执行结果:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3 testDeadWait.py
call firstProcess.py
first process end.
0
一般的场景中死等不太友好,至少要输出一些日志来缓解用户的焦虑吧:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat testWait.py
import subprocess
import time
print('call firstProcess.py')
obj = subprocess.Popen(["python3","firstProcess.py"])
while True:
try:
ret = obj.wait(5) #wait 5s
print(ret)
break;
except:
print("child process is running.")
我们在上一个脚本中做了一点点改进,不再死等,而是循环等待5秒并输出日志的方式进行等待。这里面使用到了TimeoutExpired异常。下面来看看运行结果:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3 testWait.py
call firstProcess.py
child process is running.
child process is running.
child process is running.
child process is running.
child process is running.
child process is running.
first process end.
0
3、Popen.communicate(input=None, timeout=None)
communicate方法的功能是与子过程交互:
v 向子过程的标准输入发送信息
v 从子过程的标准输出和标准错误输出读取信息(直到文件末尾(end-of-file))
v 等待子过程结束
3.1、向子过程的标准输入发送信息
为了向子过程的标准输入传递信息,需要在构造Popen对象时指定stdin=PIPE。a.out是一个读取标准输入的信息,然后将读取到的信息输出到标准输出的小程序。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import subprocess
>>> obj = subprocess.Popen(["./a.out"], stdin=subprocess.PIPE, encoding="utf-8")
>>> obj.communicate(input="12345", timeout=10)
12345
(None, None)
调用communicate时我们传入了“12345”字符串,并设置了一个10秒的超时等待时间。a.out随后便在标准输出上写入了“12345”。最后一行的(None, None)是communicate()返回的tuple,第一个元素是子过程的标准输出内容,第二个元素是子过程的标准错误输出内容。
由于在构造Popen对象时没有指定stdout和stderr为PIPE,因此没有任何信息。
3.2、从子过程的标准输出和标准错误输出读取信息
现在我们在构造Popen对象时指定stdout为PIPE,再次调用a.out:
>>> newObj = subprocess.Popen(["./a.out"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, encoding="utf-8")
>>> newObj.communicate(input="12345", timeout=10)
('12345\n', None)
>>> newObj.poll()
0
可以看到,返回值tuple的第一个元素就是a.out的标准输出内容。stderr的用法与stdout相同,这里不再介绍。
3.3、等待子过程结束
功能与Popen.wait()方法类似,通过timeout设定等待超时的时间,默认为None(死等),单位是秒。当超时等待时间结束子过程仍未结束时,抛出TimeoutExpired异常。
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat timeToPrint.py
import time
lastTime = 0
cnt = 5
while cnt:
time.sleep(5)
lastTime = lastTime + 5
print("pass %ds." %lastTime)
cnt = cnt - 1
上面的脚本每隔5秒会在标准输出打印过去时间的日志,我们用这个脚本测试一下communicate是如何等待的。下面这个测试脚本会调用timeToPrint.py,并每隔6秒去取子过程的标准输出:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ cat testCommunicateWait.py
import subprocess
import time
print('call timeToPrint.py')
obj = subprocess.Popen(["python3","timeToPrint.py"], stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding="utf-8")
while True:
try:
outs, errs = obj.communicate(timeout=6) #wait 6s
print(outs)
break;
except subprocess.TimeoutExpired as e:
print("child process is running.")
print(e.timeout)
print(e.stdout)
print(e.stderr)
下面来看看执行结果:
biekan@LAPTOP-EJ8UHBOB:~/tmp$ python3 testCommunicateWait.py
call timeToPrint.py
child process is running.
6
None
None
child process is running.
6
None
None
child process is running.
6
None
None
child process is running.
6
None
None
pass 5s.
pass 10s.
pass 15s.
pass 20s.
pass 25s.
非常遗憾,中间的每次获取都没有拿到子过程的标准输出内容(都是None),只有等到子过程执行完毕时最后一次获取到了子过程的整体的标准输出信息。但是,如果就要获取子过程执行到此时的标准输出或标准错误输出呢?官方文档给我们提供了一个用法:
proc = subprocess.Popen(...)
try:
outs, errs = proc.communicate(timeout=15)
except TimeoutExpired:
proc.kill()
outs, errs = proc.communicate()
如果超时,会调用Popen对象的kill()方法将子过程杀死。之后立即调用Popen对象的communicate()方法来获取一直到被杀死为止的子过程的标准输出和标准错误输出。通过这个用法我们发现,即使子过程被杀死了或者结束了,Popen对象仍然存在且可以被访问的。
4、Popen.send_signal(signal)
向子过程发送信号(在Posix os上)。
5、Popen.terminate()
停止子过程。实际上是向子过程发送SIGTERM信号(在Posix os上)。
6、Popen.kill()
杀掉子过程。实际上是向子过程发送SIGKILL信号(在Posix os上)。
7、Popen.args
保存着Popen对象创建时传入的args,一个序列或者一个字符串。
8、Popen.stdin属性
只有当Popen对象被创建时stdin为PIPE时才会有效,否则为None。如果stdin有效,Popen.stdin会返回一个由open()产生的可写的流对象。如果定义了encoding,这个流是文本流,否则就是一个字节流。
9、Popen.stdout属性
只有当Popen对象被创建时stdout为PIPE时才会有效,否则为None。如果stdout有效,Popen.stdout会返回一个由open()产生的可读的流对象。如果定义了encoding,这个流是文本流,否则就是一个字节流。
10、Popen.stderr属性
与Popen.stdout类似。
11、Popen.pid
子过程的进程ID。注意,如果创建Popen对象时shell为True,此pid是执行shell的进程ID。
12、Popen.returncode
子过程的returncode。如果是None,表示子过程还没有结束(或者虽然结束了,但是没有通过poll/wait/communicate产生)。如果是-N,则表示子过程是被signal N结束的,N就是signal值。
五
参考文献
https://docs.python.org/3.6/library/subprocess.html
