onnxruntime-gpu + windows + vs2019 cuda加速推理C++样例超详细
一、环境配置
全是windows 下的版本
cuda:11.1 11.4 11.7 三个版本都试过,都是ok的
cudnn:8.5.0
onnxruntime:1.12.1 relase版本
onnxruntime-gpu下载完后可以看到里面的头文件和静态库动态库,onnxruntime不需要安装,下载完之后需要把头文 件和库文件配置到工程中,下面有具体方法
PS D:\tools\onnxruntime-win-x64-gpu-1.12.1> tree /f
D:.
│ CodeSignSummary-e54fd8c5-34c1-462b-a8b2-0761efa3159d.md
│ GIT_COMMIT_ID
│ LICENSE
│ Privacy.md
│ README.md
│ ThirdPartyNotices.txt
│ VERSION_NUMBER
│
├─include
│ cpu_provider_factory.h
│ onnxruntime_cxx_api.h
│ onnxruntime_cxx_inline.h
│ onnxruntime_c_api.h
│ onnxruntime_run_options_config_keys.h
│ onnxruntime_session_options_config_keys.h
│ provider_options.h
│ tensorrt_provider_factory.h
│
└─lib
onnxruntime.dll
onnxruntime.lib
onnxruntime.pdb
onnxruntime_providers_cuda.dll
onnxruntime_providers_cuda.lib
onnxruntime_providers_cuda.pdb
onnxruntime_providers_shared.dll
onnxruntime_providers_shared.lib
onnxruntime_providers_shared.pdb
onnxruntime_providers_tensorrt.dll
onnxruntime_providers_tensorrt.lib
onnxruntime_providers_tensorrt.pdb
二、使用vs2019创建cmake工程或者解决方案工程,都行,这里我用的是cmake工程
1、创建vs2019创建cmake工程会自动创建build文件夹,就不需要单独创建了,创建完结果如下:

2、配置项目文件下的CMkaeLists.txt
将onnxruntime和opencv的静态库和头文件配置到CMakeLists.txt中,opencv的安装方式网上一大把,这里不在多说
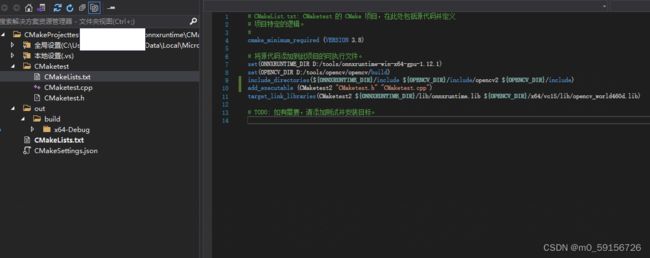
此外将onnxruntime.dll、 onnxruntime_providers_cuda.dll、onnxruntime_providers_shared.dll、 onnxruntime_providers_tensorrt.dll放到C:\windows\system32中或者放到程序执行目录下,也就是.exe所在目录下
3、工程下的CMakeList.txt配置就很简单了

三、代码
模型文件,测试图片,标签获取请参考
https://blog.csdn.net/qq_44747572/article/details/120820964
头文件
CMaketest.h
// CMaketest.h: 标准系统包含文件的包含文件
// 或项目特定的包含文件。
#pragma once
#include 源文件
CMaketest.cpp
#include "CMaketest.h"
bool CheckStatus(const OrtApi* g_ort, OrtStatus* status) {
if (status != nullptr) {
const char* msg = g_ort->GetErrorMessage(status);
std::cerr << msg << std::endl;
g_ort->ReleaseStatus(status);
throw Ort::Exception(msg, OrtErrorCode::ORT_EP_FAIL);
}
return true;
}
using namespace cv;
using namespace std;
using namespace Ort;
using namespace cv::dnn;
// 图像处理 标准化处理
void PreProcess(const Mat& image, Mat& image_blob)
{
Mat input;
image.copyTo(input);
//数据处理 标准化
std::vector<Mat> channels, channel_p;
split(input, channels);
Mat R, G, B;
B = channels.at(0);
G = channels.at(1);
R = channels.at(2);
B = (B / 255. - 0.406) / 0.225;
G = (G / 255. - 0.456) / 0.224;
R = (R / 255. - 0.485) / 0.229;
channel_p.push_back(R);
channel_p.push_back(G);
channel_p.push_back(B);
Mat outt;
merge(channel_p, outt);
image_blob = outt;
}
int main()
{
const OrtApi* g_ort = NULL;
const OrtApiBase* ptr_api_base = OrtGetApiBase();
g_ort = ptr_api_base->GetApi(ORT_API_VERSION);
OrtEnv* env;
CheckStatus(g_ort, g_ort->CreateEnv(ORT_LOGGING_LEVEL_WARNING, "test", &env));
OrtSessionOptions* session_options;
CheckStatus(g_ort, g_ort->CreateSessionOptions(&session_options));
CheckStatus(g_ort, g_ort->SetIntraOpNumThreads(session_options, 1));
CheckStatus(g_ort, g_ort->SetSessionGraphOptimizationLevel(session_options, ORT_ENABLE_BASIC));
//CUDA option set
OrtCUDAProviderOptions cuda_option;
cuda_option.device_id = 0;
cuda_option.arena_extend_strategy = 0;
cuda_option.cudnn_conv_algo_search = OrtCudnnConvAlgoSearchExhaustive;
cuda_option.gpu_mem_limit = SIZE_MAX;
cuda_option.do_copy_in_default_stream = 1;
//CUDA 加速
CheckStatus(g_ort, g_ort->SessionOptionsAppendExecutionProvider_CUDA(session_options, &cuda_option));
//load model and creat session
//模型文件路径
const wchar_t* model_path = L"D:\\xx\\onnxruntimetest\\vgg16.onnx";
printf("Using Onnxruntime C++ API\n");
OrtSession* session;
CheckStatus(g_ort, g_ort->CreateSession(env, model_path, session_options, &session));
OrtAllocator* allocator;
CheckStatus(g_ort, g_ort->GetAllocatorWithDefaultOptions(&allocator));
//**********输入信息**********//
size_t num_input_nodes; //输入节点的数量
CheckStatus(g_ort, g_ort->SessionGetInputCount(session, &num_input_nodes));
std::vector<const char*> input_node_names; //输入节点的名称
std::vector<std::vector<int64_t>> input_node_dims; //输入节点的维度
std::vector<ONNXTensorElementDataType> input_types; //输入节点的类型
std::vector<OrtValue*> input_tensors; //输入节点的tensor
input_node_names.resize(num_input_nodes);
input_node_dims.resize(num_input_nodes);
input_types.resize(num_input_nodes);
input_tensors.resize(num_input_nodes);
for (size_t i = 0; i < num_input_nodes; i++) {
// Get input node names
char* input_name;
CheckStatus(g_ort, g_ort->SessionGetInputName(session, i, allocator, &input_name));
input_node_names[i] = input_name;
// Get input node types
OrtTypeInfo* typeinfo;
CheckStatus(g_ort, g_ort->SessionGetInputTypeInfo(session, i, &typeinfo));
const OrtTensorTypeAndShapeInfo* tensor_info;
CheckStatus(g_ort, g_ort->CastTypeInfoToTensorInfo(typeinfo, &tensor_info));
ONNXTensorElementDataType type;
CheckStatus(g_ort, g_ort->GetTensorElementType(tensor_info, &type));
input_types[i] = type;
// Get input shapes/dims
size_t num_dims;
CheckStatus(g_ort, g_ort->GetDimensionsCount(tensor_info, &num_dims));
input_node_dims[i].resize(num_dims);
CheckStatus(g_ort, g_ort->GetDimensions(tensor_info, input_node_dims[i].data(), num_dims));
size_t tensor_size;
CheckStatus(g_ort, g_ort->GetTensorShapeElementCount(tensor_info, &tensor_size));
if (typeinfo) g_ort->ReleaseTypeInfo(typeinfo);
}
//---------------------------------------------------//
//***********输出信息****************//
size_t num_output_nodes;
std::vector<const char*> output_node_names;
std::vector<std::vector<int64_t>> output_node_dims;
std::vector<OrtValue*> output_tensors;
CheckStatus(g_ort, g_ort->SessionGetOutputCount(session, &num_output_nodes));
output_node_names.resize(num_output_nodes);
output_node_dims.resize(num_output_nodes);
output_tensors.resize(num_output_nodes);
for (size_t i = 0; i < num_output_nodes; i++) {
// Get output node names
char* output_name;
CheckStatus(g_ort, g_ort->SessionGetOutputName(session, i, allocator, &output_name));
output_node_names[i] = output_name;
OrtTypeInfo* typeinfo;
CheckStatus(g_ort, g_ort->SessionGetOutputTypeInfo(session, i, &typeinfo));
const OrtTensorTypeAndShapeInfo* tensor_info;
CheckStatus(g_ort, g_ort->CastTypeInfoToTensorInfo(typeinfo, &tensor_info));
// Get output shapes/dims
size_t num_dims;
CheckStatus(g_ort, g_ort->GetDimensionsCount(tensor_info, &num_dims));
output_node_dims[i].resize(num_dims);
CheckStatus(g_ort, g_ort->GetDimensions(tensor_info, (int64_t*)output_node_dims[i].data(), num_dims));
size_t tensor_size;
CheckStatus(g_ort, g_ort->GetTensorShapeElementCount(tensor_info, &tensor_size));
if (typeinfo) g_ort->ReleaseTypeInfo(typeinfo);
}
//---------------------------------------------------//
printf("Number of inputs = %zu\n", num_input_nodes);
printf("Number of output = %zu\n", num_output_nodes);
std::cout << "input_name:" << input_node_names[0] << std::endl;
std::cout << "output_name: " << output_node_names[0] << std::endl;
//加载图片
Mat img = imread("D:\\xx\\onnxruntimetest\\dog.jpg");
Mat det1, det2, det3;
resize(img, det1, Size(224, 224), INTER_AREA);
det1.convertTo(det1, CV_32FC3);
PreProcess(det1, det2); //标准化处理
//cvtColor(det2, det3, CV_BGR2RGB);
//size_t input_data_length0 = det2.step * det2.rows;
Mat blob = dnn::blobFromImage(det2, 1., Size(224, 224), Scalar(0, 0, 0), false, true);
size_t input_data_length = blob.total() * blob.elemSize();
printf("Load success!\n");
clock_t startTime, endTime;
//创建输入tensor
OrtMemoryInfo* memory_info;
CheckStatus(g_ort, g_ort->CreateCpuMemoryInfo(OrtArenaAllocator, OrtMemTypeDefault, &memory_info));
CheckStatus(g_ort, g_ort->CreateTensorWithDataAsOrtValue(
memory_info, reinterpret_cast<void*>(blob.data), input_data_length,
input_node_dims[0].data(), input_node_dims[0].size(), input_types[0], &input_tensors[0]));
g_ort->ReleaseMemoryInfo(memory_info);
//循环推理看效果
for (int i = 0; i < 10; i++)
{
startTime = clock();
CheckStatus(g_ort, g_ort->Run(session, nullptr, input_node_names.data(), (const OrtValue* const*)input_tensors.data(),
input_tensors.size(), output_node_names.data(), output_node_names.size(),
output_tensors.data()));
endTime = clock();
cout << i << ": " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
}
void* output_buffer;
CheckStatus(g_ort, g_ort->GetTensorMutableData(output_tensors[0], &output_buffer));
float* float_buffer = reinterpret_cast<float*>(output_buffer);
size_t output_data_size = output_node_dims[0][1];
auto max = std::max_element(float_buffer, float_buffer + output_data_size);
std::vector<float> optu(float_buffer, float_buffer + output_data_size);
int max_index = static_cast<int>(std::distance(float_buffer, max));
//标签文件加载
std::fstream label_file("D:\\xx\\onnxruntimetest\\classification_classes_ILSVRC2012.txt", std::ios::in);
std::unordered_map<int, std::string> label_table;
label_table.reserve(output_data_size);
int i = 0;
std::string line;
while (std::getline(label_file, line)) {
label_table.emplace(i++, line);
}
printf("%d, %f, %s \n", max_index, *max, label_table[max_index].c_str());
printf("Done!\n");
return 0;
}
四、结果
第一次推理时间很长,原因推测GPU唤醒需要时间,也跟模型有关

五、说一下遇到的坑
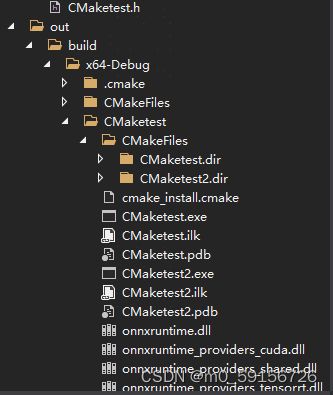
1、onnxruntime的动态库其实需要onnxruntime.dll、 onnxruntime_providers_cuda.dll、onnxruntime_providers_shared.dll这3个,而且一定要放对位置,否则会出各种内存异常的问题,可以看一下debug模式下,加载所需的dll,上文也已经说过也可以放在windows\system32下,优先从cmake可执行文件目录里面找dll。
 、
、
2、提示找不到zlibwapi.dll文件,导致gpu推理失败
nvidia官网提供下载链接
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#prerequisites-windows