Python中回归(分类)结果的两种情况
【小白从小学Python、C、Java】
【Python全国计算机等级考试】
【Python数据分析考试必会题】
● 标题与摘要
Python中回归(分类)结果的两种情况:
(1)回归结果为具体数值:
predict()
(2)回归结果为所属类别的概率:
predict_proba()
● 选择题
以下关于预测函数predict()说法正确的是:
选项:
A predict()返回预测数据类别
B predict()返回的是原始数据
C predict()返回的是类别概率
D predict()返回原始数据类别
欢迎大家转发,一起传播知识和正能量,帮助到更多人。期待大家提出宝贵改进建议,互相交流,收获更大。辛苦大家转发时注明出处(也是咱们公益编程交流群的入口网址),刘经纬老师共享知识相关文件下载地址为:http://liujingwei.cn
● 问题解析
1.predict()函数是Python中预测函数,常用于预测测试集数据,返回的是样本所属的类别标签。
2.predict_proba()函数也是预测函数,但是与predict()函数不同的是,predict_proba()函数返回的是数组,是预测该样本为某个标签的概率值,并且每一行的概率和为1。
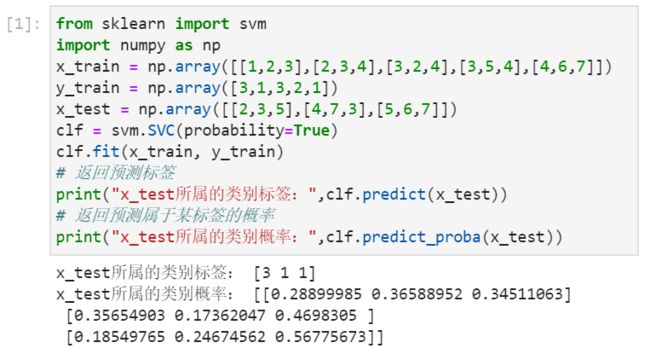
3.参照图1解释:predict()函数输出结果表示:测试集[2,3,5]属于3类别;测试集[4,7,3]属于1类别;测试集[5,6,7]属于3类别。predict_proba()函数输出结果表示:测试集[2,3,5]属于1类别的概率是0.28899985,属于2类别的概率是0.36588952,属于3类别的概率是0.34511063;测试集[4,7,3]属于1类别的概率是0.35654903,属于2类别的概率是0.17362047,属于3类别的概率是0.4698305;测试集[5,6,7]属于1类别的概率是0.18549765,属于2类别的概率是0.24674562,属于3类别的概率是0.56775673。
● 附图
图1 predict()函数与predict_proba()函数对比
● 附图代码
from sklearn import svm
import numpy as np
x_train = np.array([[1,2,3],[2,3,4],[3,2,4],[3,5,4],[4,6,7]])
y_train = np.array([3,1,3,2,1])
x_test = np.array([[2,3,5],[4,7,3],[5,6,7]])
clf = svm.SVC(probability=True)
clf.fit(x_train, y_train)
# 返回预测标签
print("x_test所属的类别标签:",clf.predict(x_test))
# 返回预测属于某标签的概率
print("x_test所属的类别概率:",clf.predict_proba(x_test))
● 正确答案
A
● 温馨期待
期待大家提出宝贵建议,互相交流,收获更大,助教:zjq[太阳]