机器学习基础——分类算法之朴素贝叶斯算法(Bayes)、分类模型评估、选择和调优
目录
1 概率论知识
2 贝叶斯公式
3 sklearn包中的API(MultinomialNB)
4 朴素贝叶斯算法案例——文本分类
4.1 案例流程
4.2 代码及结论
4.3 案例缺点
5 朴素贝叶斯的优缺点
5.1 优点
5.2 缺点
6 分类模型的评估
6.1 混淆矩阵
6.2 精确率和召回率和F值
6.2.1 定义
6.2.2 分类模型评估API
7 模型选择与调优
7.1 交叉验证
7.1.1 交叉验证过程
7.2 超参数搜索——网格搜索
7.2.1 网格搜索调参
7.2.2 网格搜索API
7.2.3 knn算法运用实例
1 概率论知识
条件概率的计算公式如下:
P(white|B)=P(white and B)/P(B)
条件:所有特征之间是条件独立。 也就是“朴素”。
朴素贝叶斯中的朴素一词的来源就是假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。
2 贝叶斯公式
首先给出贝叶斯公式: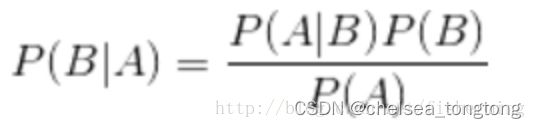
换成分类任务的表达式:
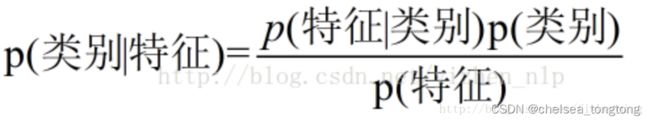
3 sklearn包中的API(MultinomialNB)
- sklearn.naive_bayes.MultinomialNB(alpha=1.0)
- 朴素贝叶斯分类
- alpha:阿普拉斯平滑系数
4 朴素贝叶斯算法案例——文本分类
4.1 案例流程

- 加载20类新闻数据(fetch_20newsgroups),并进行分割(train_test_split)
- 生成文章特征词(特征工程之特征抽取TfidfVectorizer)
- 朴素贝叶斯estimstor流程进行预估()
4.2 代码及结论
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def naivebayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news=fetch_20newsgroups(subset="all")
#进行数据分割
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25)
#对数据集进行特征抽取
tf=TfidfVectorizer()
#以训练集集中词的列表进行每篇文章的重要性统计["a","b","c","d“]
x_train=tf.fit_transform(x_train)
x_test=tf.transform(x_test)
#进行朴素贝叶斯算法的预测
mlt=MultinomialNB(alpha=1.0)
mlt.fit(x_train,y_train)
y_predict=mlt.predict(x_test)
print("预测的文章类别为:",y_predict)
#得出准确率
print("准确率为:",mlt.score(x_test,y_test))
return None
if __name__ == '__main__':
naivebayes()
结果:预测的文章类别为: [12 3 1 ... 7 14 7]
准确率为: 0.8597198641765704
4.3 案例缺点
- 假设了文章当中一些词语与另外一些独立没关系(不太靠谱)
- 训练集当中去进行统计词这些工作( 会对结果造成干扰)
- 神经网络模型效果要好
5 朴素贝叶斯的优缺点
- 朴素贝叶斯不需要调参。决策树、随机森林需要调参。
- 训练集误差大,结果肯定不好
5.1 优点
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度搞高,速度快
5.2 缺点
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果不好。
6 分类模型的评估
评估标准:准确率、精确率、召回率
- estimator.score()
- 一般最常见使用的是准确率,即预测结果正确的百分比
6.1 混淆矩阵
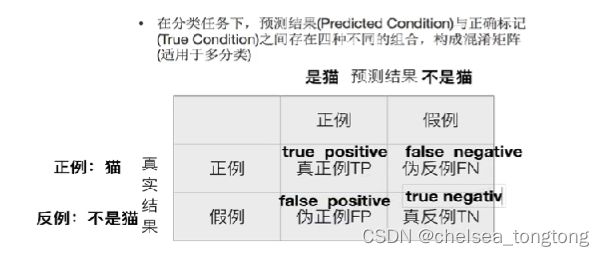
6.2 精确率和召回率和F值
6.2.1 定义
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。

正确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
1. 正确率 = 提取出的正确信息条数 / 提取出的信息条数
2. 召回率 = 提取出的正确信息条数 / 样本中的信息条数
两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
3. F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
6.2.2 分类模型评估API
- sklearn.metrics.classification_report(y_true,y_pred,target_names=None)
- y_true:真实值
- y_pred:估计器预测目标值
- targret_names:目标类别名称
- return:每个类别精确率与召回率
用上述文本分类案例来计算每一个类别的精确率和召回率
from sklearn.metrics import classification_report
print("每个类别的精确率和召回率:",classification_report(y_test,y_predict,target_names=news.target_names))每个类别的精确率和召回率: precision recall f1-score support
alt.atheism 0.88 0.70 0.78 209
comp.graphics 0.85 0.72 0.78 243
comp.os.ms-windows.misc 0.82 0.88 0.85 220
comp.sys.ibm.pc.hardware 0.71 0.85 0.77 237
comp.sys.mac.hardware 0.94 0.85 0.89 247
comp.windows.x 0.94 0.90 0.92 238
misc.forsale 0.95 0.62 0.75 278
rec.autos 0.83 0.93 0.88 228
rec.motorcycles 0.95 0.96 0.95 251
rec.sport.baseball 0.96 0.96 0.96 241
rec.sport.hockey 0.94 0.98 0.96 237
sci.crypt 0.71 0.97 0.82 238
sci.electronics 0.91 0.74 0.82 266
sci.med 0.95 0.90 0.92 242
sci.space 0.92 0.93 0.93 264
soc.religion.christian 0.53 0.97 0.69 250
talk.politics.guns 0.77 0.97 0.86 233
talk.politics.mideast 0.91 0.97 0.94 237
talk.politics.misc 0.98 0.64 0.77 187
talk.religion.misc 0.96 0.15 0.26 166
7 模型选择与调优
7.1 交叉验证
7.1.1 交叉验证过程
目的:为了让被评估的模型更加准确

以上过程被称为4折交叉验证
7.2 超参数搜索——网格搜索
7.2.1 网格搜索调参
目的:不同的超参数设置,机器学习给出的结果也会不一样,因此,也会一定程度上影响到对结果的评价指标。而往往人们会追求一个“最好”的结果,因此,就需要在众多超参数的取值范围中选取一个“最优”的值进行设置。每组超参数都是用交叉验证进行评估。
因此,使用网格搜索等手段,均是为了寻找好的超参数。
网格搜索:调参 K-近邻:超参数K
7.2.2 网格搜索API
- sklearn.model_selection.GridSearchCV(estimator,param_grid=None,cv=None)

7.2.3 knn算法运用实例
- 注意:knn=KNeighborsClassifier()里面n_neighbors不能写具体的数字,不然就不能用网格搜索了
- cv=2,表示进行两次交叉验证,会有三组K的三组交叉验证准确率,最后一组是平均值,也是最后的准确率
from sklearn.model_selection import train_test_split,GridSearchCV
knn=KNeighborsClassifier()
#构造一些参数的值进行搜索
param={"n_neighbors":[3,5,10]}
#进行网格搜索
gc=GridSearchCV(knn,param_grid=param,cv=2)
gc.fit(x_train,y_train)
#预测准确率
print("在测试集上的准确率:", gc.score(x_test,y_test))
print("在交叉验证中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_score_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)结果:在测试集上的准确率: 0.4309692671394799
在交叉验证中最好的结果: 0.38627049180327866
选择最好的模型是: 0.38627049180327866
每个超参数每次交叉验证的结果: {'mean_fit_time': array([0.00965035, 0.0079993 , 0.00800002]), 'std_fit_time': array([6.49094582e-04, 5.96046448e-07, 1.00100040e-03]), 'mean_score_time': array([0.35052657, 0.38202989, 0.41253066]), 'std_score_time': array([0.00750113, 0.00600088, 0.0054996 ]), 'param_n_neighbors': masked_array(data=[3, 5, 10], mask=[False, False, False]