一、python中Numpy_Pandas数据处理基础
Numpy(Numerical Python) 是 Python语言的一个第三方库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Numpy是一个运行速度非常快的数学库,主要用于数组计算。
Pandas是专门为处理表格和混杂数据设计的,相当于Python的Excel,而Numpy更适合处理统一的数组数据。
导包:
import pandas as pd
import numpy as np
1.将下面的字典创建为DataFrame
data = {"grammer":['python','c','java','go',np.NaN,'SQL','PHP','Python'],
"score":[1.0, 2.0, np.NaN, 4.0, 5.0, 6.0, 7.0, 10.0]}
df = pd.DataFrame(data)
df

2.提取含有字符串"Python"的行
#方法一:
df[df['grammer'] == 'Python']
#方法二:
results = df['grammer'].str.contains('y')#列表中文本包含某个字符
results.fillna(value=False, inplace=True)
df[results]
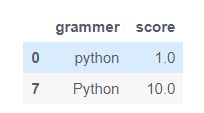
3.输出df的所有列名
df.columns
4.修改第二列列名为’popularity’
df.rename(columns = {'score':'popularity'},inplace=True)
df

5.统计grammer列中每种编程语言出现的次数
df['grammer'].value_counts()
6.将空值用上下值的平均值填充
df['popularity'] = df['popularity'].fillna(df['popularity'].interpolate())
df

7.提取popularity列中值大于3的行
df[df['popularity'] > 3]

8.按照grammer列进行去除重复值
df.drop_duplicates(['grammer'])

9.计算popularity列平均值
df['popularity'].mean()
10.将grammer列转换为list
df['grammer'].to_list()
[‘Python’, ‘C’, ‘Java’, ‘GO’, nan, ‘SQL’, ‘PHP’, ‘Python’]
11.将DataFrame保存为CSV
df.to_csv('test.csv')
12.查看数据行列数
df.shape
13.提取popularity列值大于3小于7的行
df[(df['popularity'] > 3) & (df['popularity'] < 7)]
14.交换两列位置
#方法一
temp = df['popularity']
df.drop(labels =['popularity'],axis=1,inplace=True)
df.insert(0,'popularity',temp)
#方法二
cols = df.columns[[1,0]]
cols = df[cols]
df

练习题:
已知10位同学的学号以及语数英三科成绩如下:(都是数值型数据)

要求:计算出每位同学的总成绩(SumScore)、平均成绩(MeanScore),最高成绩(MaxScore)、最低成绩(MinScore)、最高成绩与最低成绩的极差(PtpScore)、成绩方差(VarScore);并将所有数据保存到score数据框中;将多列数据(包括学生的ID)合并到一列中,列名设置为answer,最终只保留索引id(从0到100)和answer两列,统一保留整数;
未优化代码:
import pandas as pd
data = {'Id':['202001','202002','202003','202004','202005','202006','202007','202008','202009','202010'],
'Chinese':['98','67','84','88','78','90','93','75','82','87'],
'Math':['92','80','73','76','88','78','90','82','77','69'],
'English':['88','79','90','73','79','83','81','91','71','78'],}
df = pd.DataFrame(data).astype(int)
df['SumScore'] = df.apply(lambda x:x[1:4].sum(),axis=1).astype(int)
df['MeanScore'] = df.apply(lambda x:x[1:4].mean(),axis=1).astype(int)
df['MaxScore'] = df.apply(lambda x:x[1:4].max(),axis=1).astype(int)
df['MinScore'] = df.apply(lambda x:x[1:4].min(),axis=1).astype(int)
df['PtpScore'] = df.apply(lambda x:x[1:4].ptp(),axis=1).astype(int)
df['VarScore'] = df.apply(lambda x:x[1:4].var(),axis=1).astype(int)
df_result = pd.DataFrame()
df_result = [['id','answer']]
df_result
data_result = pd.concat([df.iloc[:,0],df.iloc[:,1],df.iloc[:,2],df.iloc[:,3],df.iloc[:,4],df.iloc[:,5],
df.iloc[:,6],df.iloc[:,7],df.iloc[:,8],df.iloc[:,9]])
df_result = pd.DataFrame(data_result,columns=['answer'])
df_result['id'] = range(len(df_result))
df_result = df_result[['id','answer']]
df_result.to_csv('answer_1.csv', index=False, encoding='utf-8-sig')
df_result
优化代码:
#通过字典形式创建数据表
import pandas as pd
data = {'Id':['202001','202002','202003','202004','202005','202006','202007','202008','202009','202010'],
'Chinese':['98','67','84','88','78','90','93','75','82','87'],
'Math':['92','80','73','76','88','78','90','82','77','69'],
'English':['88','79','90','73','79','83','81','91','71','78'],}
df = pd.DataFrame(data).astype(int)
#采用agg方式,求值
tmp = df[['Chinese','Math','English']].agg(['sum','mean','max','min','ptp','var'],axis=1).astype(int)
tmp.rename(columns={'sum':'SumScore','mean':'MeanScore','max':'MaxScore','min':'MinScore','ptp':'PtpScore','var':'VarScore'},inplace=True)
#连接两个数据表
df = pd.concat([df,tmp],axis=1)
data_result = pd.concat([df.iloc[:,i] for i in range(10)])
#得到数据结果
df_result = pd.DataFrame(data_result,columns=['answer'])
df_result['id'] = range(len(df_result))
df_result = df_result[['id','answer']]
df_result.to_csv('answer_1.csv', index=False, encoding='utf-8-sig')
中间图片:
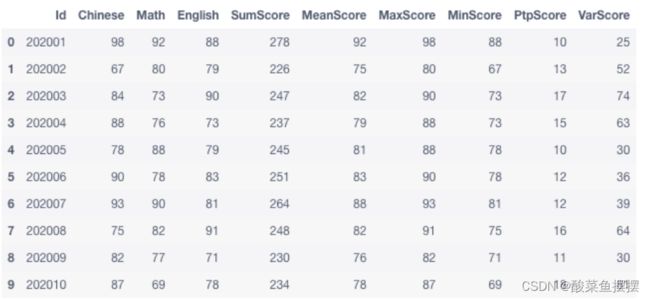
结果图片:

学习链接:https://www.heywhale.com/home/activity/detail/6154198bc270e400182b11f9