三、python中pandas_numpy_数据处理、合并与分组
三、数据处理、合并与分组
#导包
import pandas as pd
import numpy as np
# 读取pandas120数据文件
df = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
df.head()

补充缺失值
import random
df['value'] = [random.randint(1,100) for i in range(len(df))]
df.loc[[2,10,45,87], 'value'] = np.nan
1. 缺失值处理
1.1 判断缺失值
df.isnull().values.any()
True
df.isnull().sum()
createTime 0
education 0
salary 0
value 4
dtype: int64
# 查看每列非缺失值数:
df.notnull().sum()
df.shape[0] - df.isnull().sum()
1.2 缺失值填充
# 用上下平均值填充value列:
df['value'] = df['value'].fillna(df['value'].interpolate())
df.head()
# df (注意赋值,如果不赋值,原始序列未改变)
# 将value列缺失值全部替换为1.0:
df.fillna(value =1.0, inplace = True)
1.3 更改缺失值
## 将value列第10行到13行设置为缺失值:
df.loc[9:12,'value'] = np.nan
## 将第三行设置为缺失值:
df.loc[:2] = np.nan
1.4 删除缺失值
# 删除所有存在缺失值的行:
df.dropna(axis=0, how='any', inplace=True)
# 删除所有有缺失值的行
df.dropna() # -- 默认axis=0
# 删除所有有缺失值的列
df.dropna(axis='columns')
df.dropna(axis=1)
# 删除所有值缺失的行
df.dropna(how='all')
# 删除至少有两个非缺失值的行
df.dropna(thresh=2)
# 指定判断缺失值的列范围
df.dropna(subset=['education', 'value'])
# 使删除和的结果生效
df.dropna(inplace=True)
# 指定列的缺失值删除
df.value.dropna()
2. 数据去重
# drop_duplicates()
df.drop_duplicates(['createTime'])
3. 添加/删除数据
3.1 添加一行数据[‘2020-03-16 10:48:36’, ‘硕士’, ‘20k-40k’, ‘43.0’]
# 方法一:字典
df2 = pd.DataFrame({
'createTime':['2020-03-16 10:48:36'],
'education':['硕士'],
'salary':['20k-40k'],
'value':[43.0]
})
df = df.append(df2, ignore_index=True)
df.tail()
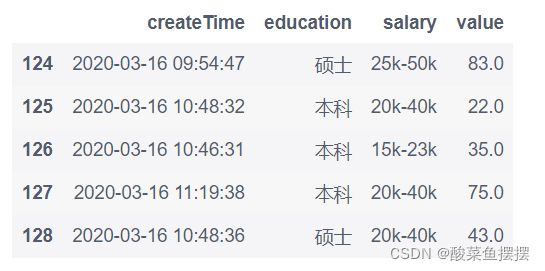
# 方法二:loc
df.loc[len(df)] = ['2020-03-16 11:20:41', '硕士', '25k-45k', 29.0]
df.tail()
3.2 删除最后两行数据
df.drop(index=[len(df)-1,len(df)-2], inplace=True)
4. 数据排序
# 按照value列值大小进行排序
df.sort_values(by=['value'], ascending=True) #注:ascending:True升序,False降序
5. 数据类型转换
# 随机生成一列0.01到1之间的浮点数
df['value2'] = [random.uniform(0.01, 1) for i in range(len(df))] # 注:uniform产生1到100之间的随机浮点数,区间可以不是整数
# 方法一:round()函数
df['value2'].round(2)
# 方法二:map + lambda
df['value2'].map(lambda x : ('%.2f') % x)
# 方法三:map + lambda + format
df['value2'] = df['value2'].map(lambda x : format(x, '.2f'))
df.head()
5.2 将value2列小数转换为百分数
#由于value2上一步转换为小数时,会自动将浮点类型变为object类型,
df['value2'] = df['value2'].astype('float')
# 方法一:style + 格式化处理
df.style.format({'value2' : '{0:.2%}'.format})
# 方法二:自定义函数+格式化处理
df['value2'] = df['value2'].map(lambda x : format(x, '.2%'))
df.head()
5.3 将value2列数据转换为浮点类型
# 方法一:
df['value2'].str.strip('%').astype('float') # 如果该列存在%符号
5.4 Series类型转list
# 将value列转换为List类型,只显示10条数据
df['value'].tolist()[:10] # 或者to_list()
5.5 将时间戳类型转换为datatime类型
注:采用Timestamp.to_pydatetime()函数将给定的时间戳转换为本地python datetime对象; strftime()用来格式化datetime 对象
# 将createTime(第一列)列时间转换为月-日:
for i in range(len(df)):
df.iloc[i,0] = df.iloc[i,0].to_pydatetime().strftime("%m-%d")
df.head()
6. 数据拆分
6.1 将salary列按照’-'拆分
df['salary'].str.split('-')
6.2 删除salary列开头和结尾的任何字符,默认为空格
df['salary'].str.strip()
7. 将value列数据开根号
# 方法一:apply() + np.sqrt()
df[['value']].apply(np.sqrt)
# 方法二:map + math.sqrt()
import math
pd.DataFrame(df['value'].map(lambda x : math.sqrt(x)))
8. 数据合并:concat, merge, append, join
# 创建两个dataframe
data1 = {"course":['Python', 'C', 'Java', 'R', 'SQL'],
"grade":[6, 2, 6, 4, 5],
"cycle":[4, 2, 6, 2, 1]}
data2 = {'course':['Python', 'C', 'PHP', 'R', 'SQL'],
"grade":[6, 2, 6, 4, 5],
'count':[30, 25, 14, 20, 29]}
df = pd.DataFrame(data1)
df1 = pd.DataFrame(data2)
8.1 DataFrame.concat()
语法:
concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
参数:
objs: series,dataframe或者是panel构成的序列lsit
axis:需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定合并的轴是行还是列,axis默认是0。
# 将第一行与最后一行拼接:
pd.concat([df[:1], df[-2:-1]])
# 将两个dataframe按列合并:
list_ = [random.randint(1, 100) for i in range(len(df))]
df2 = pd.DataFrame(list_, columns=['value'])
pd.concat([df,df2], axis=1) # 按行合并,则axis=0

8.2 DataFrame.merge()
df = pd.merge(left, right, how = “inner”,on = “None”)
参数:
left: 左表。也就是第一个df。
right:右表。也就是第二个df。
how: 和concat里面的"join"类似,表示“如何合并两表。
1)left: 只使用左表的键。
2)right:只使用右表的键。
3)inner: 使用左右表键的交集。
4)outer:使用左右表键的并集。
on: 表示按照哪一个键来进行合并。
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
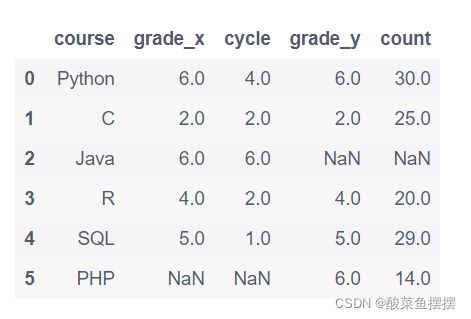
# 按照单列合并数据:
pd.merge(df, df1, on='course')

# 按照多列合并数据:多列用列表
pd.merge(df, df1, how='left', on=['course', 'grade'])

#内外连接合并:
pd.merge(df, df1, how='outer', on='course') # inner内连接,outer外连接
8.3 DataFrame.append()
语法:
DataFrame.append(other,ignore_index=False, verify_integrity=False, sort=None)
参数:
other: DataFrame、series、dict、list这样的数据结构
ignore_index:默认值为False,如果为True则不使用index标签
verify_integrity :默认值为False,如果为True当创建相同的index时会抛出ValueError的异常o sort: boolean,默认是None,该属性在pandas的0.23.0的版本才存在。
功能说明:
向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
# 将第3行数据添加至末尾:
df.append(df.iloc[2])
8.4 DataFrame.join()
语法:
DataFrame.join(other, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False)
参数:
other:【DataFrame,或者带有名字的Series,或者DataFrame的list】如果传递的是Series,那么其name属性应当是一个集合,并且该集合将会作为结果DataFrame的列名
on:【列名称,或者列名称的list/tuple,或者类似形状的数组】连接的列,默认使用索引连接
how:【{‘left’, ‘right’, ‘outer’, ‘inner’}, default:‘left’】连接的方式,默认为左连接
lsuffix:【string】左DataFrame中重复列的后缀
rsuffix:【string】右DataFrame中重复列的后缀
sort:【boolean, default:False】按照字典顺序对结果在连接键上排序。如果为False,连接键的顺序取决于连接类型(关键字)。
主要用于索引上的合并,其参数的意义与merge方法中的参数意义基本一样。该方法最为简单,主要用于索引上的合并
df.join(df1, lsuffix='_left', rsuffix='_right')
8.5 总结
join 最简单,主要用于基于索引的横向合并拼接
merge 最常用,主要用于基于指定列的横向合并拼接
concat最强大,可用于横向和纵向合并拼接
append,主要用于纵向追加
9. 常见统计函数
print('grade列均值:',df['grade'].mean()) # 均值
print('全体平均数:',df.mean().mean()) # 全体平均数
print('grade列中位数:',df['grade'].median()) # 中位数
print('grade列方差:',df['grade'].var()) # 方差
print('grade列标准差:',df['grade'].std()) # 标准差
print('grade列最大值:',df['grade'].max()) # 最大值
print('grade列最小值:',df['grade'].min()) # 最小值
10. diff()函数:计算上下行差值
# 方法一:Series.diff()
df['grade'].diff()
# 方法二:shift(1)
diff = df['grade'] - df['grade'].shift(1)
diff
11. pct_change()函数:计算上下行变化率
# 方法一:Series.pct_change()
df['grade'].pct_change()
# 方法二:shift(1)
df['grade']/df['grade'].shift(1) - 1
12. shift()函数:将数据往后(前)移动x天
df['grade'].shift(2) # 往前移2
df['grade'].shift(-2) # 往后移2
13. rolling()函数:以2个数据作为滑动窗口,取均值/总和
df['grade'].rolling(2).mean()
df['grade'].rolling(2).sum()
14. expanding()函数
DataFrame.expanding(min_periods = 1,center = False,axis = 0)
rolling()函数,是固定窗口大小,进行滑动计算;
expanding()函数只设置最小的观测值数量,不固定窗口大小,实现累计计算,即不断扩展;
# 计算某列的移动窗口均值:
df['grade'].expanding(min_periods = 1).mean()
15. agg()函数
聚合函数,对分组后数据进行聚合,默认情况对分组后其他列进行聚合;
15.1 同时对grade, cycle两列进行计算总和、均值、中位数、最小/大值,标准差、方差
# 方法一:
df[['grade', 'cycle']].agg([np.sum, np.mean, np.median, np.min, np.max, np.std, np.var])
# 方法二:
df[['grade', 'cycle']].agg(['sum', 'mean', 'median', 'min', 'max', 'std', 'var'])
15.2 对grade列求平均,对cycle列求和
# 方法一:分开再汇总
grade_mean = df['grade'].mean()
cycle_sum = df['cycle'].sum()
grade_mean, cycle_sum
# 方法二:agg()函数
df.agg({'grade' : np.mean, 'cycle' : np.sum})
16. 分组计算
主要的作用是进行数据的分组以及分组后地组内运算;
16.1 根据course列元素分组后计算平均值/中位数
df.groupby('course').mean()
df.groupby('course').median()
16.2 按course列分组后,grade列元素最多的是?
# 方法一:head()取行
df[['course', 'grade']].groupby('course').sum().sort_values(by='grade', ascending=False).head(1)
# 方法二:iloc取行
pd.DataFrame(df[['course', 'grade']].groupby('course').sum().sort_values(by='grade', ascending=False).iloc[0,:])
# 方法三:分组后采用agg函数求和
df[['course', 'grade']].groupby('course').agg({'grade':'sum'}).sort_values(by='grade', ascending=False).head(1)
17. query()函数:使用布尔表达式查询帧的列
语法:
df.query(expr,inplace = False,** kwargs)
参数:
expr:str要评估的查询字符串。你可以在环境中引用变量,在它们前面添加一个’@'字符 。@a + b
inplace=False:是否修改数据或返回副本
kwargs:dict关键字参数
df = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
df['value'] = [random.randint(1, 100) for i in range(len(df))]
df.head()
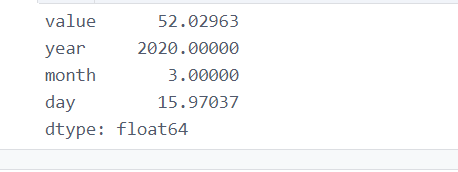
17.1 计算三月份(‘month ==3’)的平均值
f['year'] = df['createTime'].apply(lambda x: x.year)
df['month'] = df['createTime'].apply(lambda x: x.month)
df['day'] = df['createTime'].apply(lambda x: x.day)
january_df = df.query('month==3') #query等同于df[df.month==3]
january_df.mean()
df.query('month == 3 and day == 16')
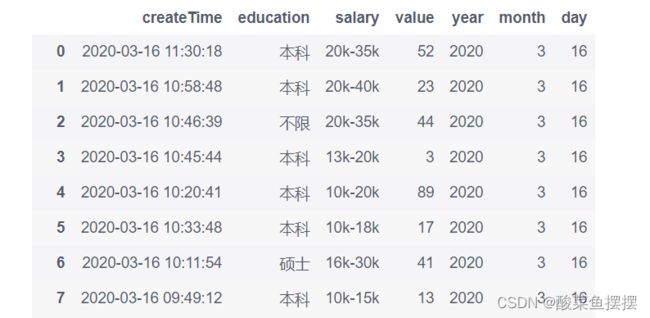
df.query('day == 16')