【Python学习】--pythonf笔记
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、Python代码规范(编码、代码格式)
-
- 1. 编码
- 2. 代码格式
- 3. import 语句
- 4. 空格
- 二、Python代码注释(块注释、行注释、文档注释)
-
- 1. 块注释
- 2. 行注释
- 3. 建议
- 4. 文档注释
- 三、Python命名规范(模块、类名、函数、变量名、常量)
-
- 1. 模块
- 2. 类名
- 3. 函数
- 4. 变量名
- 四、Python正则表达式
-
- 1. Python正则表达式|re模块
- 2. Python正则表达式|字符集
- 3. Python正则表达式|数量词
- 4. Python正则表达式|边界匹配符和组
- 5. Python正则表达式|re.sub
- 6. Python正则表达式|re.match,re.search
- 五、Pandas简介
-
- 1. Pandas官网
- 2. Pandas库的介绍
- 3. Pandas库的安装
- 4. Pandas数据结构
- 六、Python hashlib库的使用
-
- 1. 为什么需要hashlib库?
- 2. hashlib库使用方法
- 七、Python random模块的使用
-
- 1. 生成随机数
- 2. 生成随机的小数
- 3. 从字符串、列表、元组中随机返回一个值
- 4. 从字符串、列表、元组中随机返回一次或多次,且设置权重
- 5. 从字符串、列表、元组中随机获取一个或多个值
- 6. 随机打乱顺序
- 八、Python 读写yaml文件
-
- 1. pyyaml
- 九、Python MongoDB
-
- 1. PyMongo
- 2. PyMongo pip 安装
- 十、Python 日期和时间
-
- 1. Python的time模块
- 2. 什么是时间元组?
- 3. 获取当前时间
- 4. 获取格式化的时间
- 5. 格式化日期
- 5. python中时间日期格式化符号:
- 6. python 获取某月日历
- 十一、Python JSON数据
-
- 1. Python 编码为 JSON 类型转换对应表:
- 2. JSON 解码为 Python 类型转换对应表:
- 3. json.dumps与json.loads实例:
- 十二、Python 多线程
-
- 1. 学习python线程
- 2. 线程模块
- 3. 使用 threading 模块创建线程
- 3. 线程同步
- 4. 线程优先级队列(Queue)
- 十三、Python 迭代器与生成器|iter()、next()
-
- 1. 迭代器
- 十四、Python 标准库
-
- 1. 操作系统模块
- 2. 文件通配符
- 3. 命令行参数
- 4. 错误输出重定向和程序终止
- 5. 字符串正则匹配
- 6. 数学
- 6. 访问互联网
- 十五、Python File(文件)方法|open、close、file对象常用函数
-
- 1. open()方法
- 十六、Python 输入输出
-
- 1. 输出格式美化
- 十七、Python 的异步IO编程
-
- 1. 创建第一个协程
- 2. 可等待对象(awaitables)
- 总结
前言
一、Python代码规范(编码、代码格式)
1. 编码
如无特殊情况,文件一律使用UTF-8编码,文件头部必须加入
#-*-coding:utf-8-*-
2. 代码格式
- 缩进:
统一使用4个空格进行缩进
- 行宽
每行代码尽量不超过80个字符(特殊情况下可以略微超过80,但最长不得超过120个)
理由:
1)在查看side-by-side的diff时很有帮助
2)方便在控制台下查看代码
3)太长可能是设计有缺陷
- 引号
简单说,自然语言使用双引号,机器标识使用单引号,因此代码里多数应使用单引号
1)自然语言,使用双引号,例如错误信息,很多情况还是unicode,使用u" 你好python"
2)机器标识,使用单引号,例如dict里的key
3)正则表达式,使用原生的双引号,例如r"…"
4)文档字符串,(docstring)使用三个双引号"“”…“”"
- 空行
1、模块级函数和类定义之间空两行
2、类成员函数之间空一行
class A:
def __init__(self):
pass
def hello(self):
pass
def main():
pass
可以使用多个空行分隔多组相关的函数
函数中可以使用空行分隔出逻辑相关的代码
3. import 语句
1、import语句应该分行书写
# 正确的写法
import sys
import time
from subprocess import Popen,PIPE
# 不推荐写法
import sys,time
2、import语句应该使用absolute import
# 正确的写法
from foo.bar import Bar
# 不推荐的写法
from ..bar import Bar
3、import 语句应该放在文件头部,置于模块说明及docstring之后,于全局变量之前;
4、import 语句应该按照顺序排列,每组之间用一个空行分隔
import os
import sys
import msgpack
import zmq
import foo
5、导入其它模块的类定义时,可以使用相对导入
from myclass import Myclass
6、如果发生命名冲突,则可使用命名空间
import bar
import foo.bar
bar.Bar()
foo.bar.Bar()
4. 空格
- 在二元运算符两边各空一格[=,-,+=,==,>,in ,is not,and]
- 函数的参数列表中,","之后要有空格
- 函数的参数列表中,默认值等号两边不要添加空格
- 左括号之后,右括号之前不要加多余的空格
- 字典对象的左括号之前不要多余的空格
- 不要为对齐赋值语句而使用额外的空格
二、Python代码注释(块注释、行注释、文档注释)
1. 块注释
"#"号后空一格,段落间用空行分开(同样需要“#”)
# 块注释
# 块注释
#
# 块注释
# 块注释
2. 行注释
至少使用两个空格和语句分开,注意不要使用无意义的注释
# 例如:
interval = 0.1 # 爬取图片的间隔时间
3. 建议
1、在代码的关键部分(或比较复杂的地方),能写注释的要尽量写注释;
2、比较重要的注释段,使用多个等号隔开,可以更加醒目,突出重要性
...python代码...
# ========================================
# 请在法律允许的范围内使用本代码!!!
# ========================================
...python代码...
4. 文档注释
作为文档的Docstring一般出现在模块头部,函数和类的头部,这样在python中可以通过对象的__doc__对象获取文档,编辑器和IDE也可以根据Docstring给出自动提示。
文档注释以三引号开头和结尾,首行不换行,如有多行,末行必须换行。
# -*- coding: utf-8 -*-
"""Example docstrings.
This module demonstrates documentation as specified by the `Google Python
Style Guide`_. Docstrings may extend over multiple lines. Sections are created
with a section header and a colon followed by a block of indented text.
Example:
Examples can be given using either the ``Example`` or ``Examples``
sections. Sections support any reStructuredText formatting, including
literal blocks::
$ python example_google.py
Section breaks are created by resuming unindented text. Section breaks
are also implicitly created anytime a new section starts.
"""
不要在文档注释复制函数定义原型,而是具体描述其具体内容,解释具体参数和返回值等
对函数参数,返回值等的说明采用numpy标准:
def func(arg1,arg2):
"""总结:计算平均值
arg1:
arg2:
返回值
"""
三、Python命名规范(模块、类名、函数、变量名、常量)
1. 模块
模块尽量使用小写命名,首字母保持小写,尽量不要用下划线(除非多个单词,且数量不多的情况)
#推荐的模块名
import sys
import numpy
import html_parser
#不推荐的模块名
import Decoder
2. 类名
类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头
class Func():
pass
class ListFunc(num):
pass
class _PrimeFunc(num):
pass
将相关的类和顶级函数放在同一个模块里,和Java不同,没有限制一个类一个模块。
3. 函数
1、函数名一律小写,如有多个单词,用下划线隔开;
def func():
pass
def get_html_address():
pass
2、私有函数在函数前加一个下划线;
def _Prime_num():
pass
4. 变量名
变量名尽量小写,如有多个单词,用下划线隔开
if __name__ == '__main__':
s = Solution()
print(s.func(input()))
常量采用全大写,如有多个单词,使用下划线隔开
MAX_LIMIT = 520
MAX_CONNECTION = 1314
四、Python正则表达式
1. Python正则表达式|re模块
正则表达式是一个特殊的字符序列,用于判断一个字符是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
Python 自 1.5 版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
下面通过实例,一步一步来初步认识正则表达式。
比如在一段字符串中寻找是否含有某个字符或某些字符,通常我们使用内置函数来实现,如下:
#设定一个常量
x = '壁纸|wallpaper|bizhi|电脑高清图片|demotest'
#判断是否有"壁纸"这个字符串:
print('是否含有"壁纸"这个字符串:{0}'.format(x.index('壁纸') > -1))
print('是否含有"壁纸"这个字符串:{0}'.format('壁纸' in x))
输出:
是否含有"壁纸"这个字符串:True
是否含有"壁纸"这个字符串:True
使用正则表达式:(re模块)
re.findall(pattern, string[, flags])
该函数实现了在字符串中找到正则表达式所匹配的所有子串,并组成一个列表返回,具体操作如下:
import re
#设定一个常量
x = '壁纸|wallpaper|bizhi|电脑高清图片|demotest'
#正则表达式
findall = re.findall('壁纸',x)
print(findall)
if len(findall) > 0:
print('x 含有"壁纸"这个字符串')
else:
print('x 不含有"壁纸"这个字符串')
输出:
['壁纸']
x 含有"壁纸"这个字符串
正则表达式规则:
找出字符串中所有的小写字母:
import re
#设定一个常量
x = '壁纸|wallpaper|bizhi|电脑高清图片|demotest'
#选择x 里面所有的小写字母
re_findall = re.findall('[a-z]',x)
print(re_findall)
输出:
['w', 'a', 'l', 'l', 'p', 'a', 'p', 'e', 'r', 'b', 'i', 'z', 'h', 'i', 'd', 'e', 'm', 'o', 't', 'e', 's', 't']
2. Python正则表达式|字符集
字符集是由一对方括号[]括起来的字符集合。使用字符集,可以匹配多个字符中的一个。
提示:[]内的字符关系是或的关系!!!
我们使用C[ET]O匹配到的是CEO或CTO,也就是说[ET]代表的是一个E或T,像上面提到的[a-z],就是小写字母中的其中一个,这里使用了连字符"-"定义了一个连续字符的字符范围。当然像这种写法,里面可以包含多个字符范围的,比如[0-9a-fA-F],匹配单个的十六进制数字,且不分大小写,注意:字符和范围定义的先后顺序 对匹配结果没有影响。
import re
a = 'uav,ubv,ucv,uwv,uzv,ucv,uov'
# 字符集
# 取 u 和 v 中间是 a 或 b 或 c 的字符
findall = re.findall('u[abc]v', a)
print(findall)
# 如果是连续的字母,数字可以使用 - 来代替
l = re.findall('u[a-c]v', a)
print(l)
# 取 u 和 v 中间不是 a 或 b 或 c 的字符
re_findall = re.findall('u[^abc]v', a)
print(re_findall)
输出:
['uav', 'ubv', 'ucv', 'ucv']
['uav', 'ubv', 'ucv', 'ucv']
['uwv', 'uzv', 'uov']
提示:取反字符集,q[^u],代表q后面跟一个不是u的字符。
正则表达式本身就定义了一些规则:
比如\d,匹配所有数字字符,其实它是等价于[0-9],下面通过字符集的形式解释这些特殊字符。
3. Python正则表达式|数量词
如果我们要匹配很多字符时,就需要数量词
数量词的词法:{min,max},min和max都是非负整数。如果逗号有而max被忽略了,则max没有限制。如果逗号和max都被忽略了,则重复min次。
\b[1-9][0-9]{3}\b # 匹配的是1000-9999之间的数字("\b"表示单词边界)
\b[1-9][0-9]{2,4}\b # 匹配的是一个在100-99999之间的数
实例:
import re
x = '[email protected]@@python'
# 数量词
findall = re.findall('[a-z]{4,7}',x)
print(findall)
输出:
['study', 'python']
注意:这里有贪婪和非贪婪之分:
贪婪模式:它的特性是一次性读入整个字符串,如果不匹配就吐掉最右边的一个字符再匹配,直到找到匹配的字符串或字符串的长度为0为止。它的宗旨是读尽可能多的字符,所以当读到第一个匹配时就立刻返回。
懒惰模式:它的特性是从字符串的左边开始,试图读入字符串中的字符进行匹配。失败则多读一个字符,再匹配,如此循环,当找到一个匹配时会返回该匹配的字符串,然后再次进行匹配直到结束。
上面的例子就是贪婪模式,如果使用非贪婪模式要用"?",例子如下:
import re
x = '[email protected]@@python'
# 数量词
re_findall = re.findall('[a-z]{4,7}?',x)
print(re_findall)
输出:
['stud', 'pyth']
从结果看,study,python只打印了stud,prth,因为使用了懒惰模式。
还有一些特殊字符可以表示数量比如:
?:告诉引擎匹配前导字符0次或1次
+: 告诉引擎匹配前导字符1次或多次
*: 告诉引擎匹配前导字符0次或多次
| 贪婪 | 惰性 | 描述 |
|---|---|---|
| ? | ?? | 零次或一次出现,等价于{0,1} |
| + | +? | 一次或多次出现,等价于{1,} |
| * | *? | 零次或多次出现,等价于{0,} |
| {n} | {n}? | 恰好n次出现 |
| {n,m} | {n,m}? | 至少n次至多m次出现 |
| {n,} | {n,}? | 至少n次出现 |
4. Python正则表达式|边界匹配符和组
边界匹配符:
| 语法 | 描述 |
|---|---|
| ^ | 匹配字符串开头(在有多行的情况中匹配每行的开头) |
| $ | 匹配字符串的末尾(在有多行的情况中匹配每行的末尾) |
| \A | 仅匹配字符串开头 |
| \Z | 仅匹配字符串末尾 |
| \b | 匹配\w和\W之间 |
| \B | \b |
分组,被括号括起来的表达式就是分组。分组表达式(…)其实就是把这部分字符作为一个整体,当然,可以有多分组的情况,每遇到一个分组,编号就会加1,而且分组后面也是可以加数量词的。
5. Python正则表达式|re.sub
实战过程中,我们很多时候需要替换字符串中的字符,这时候就可以用到 def sub(pattern, repl, string, count=0, flags=0) 函数了,re.sub 共有五个参数。其中三个必选参数:pattern, repl, string ; 两个可选参数:count, flags
具体参数意义如下:
| 参数 | 描述 |
|---|---|
| pattern | 表示正则中的模式字符串 |
| repl | repl,就是replacement,被替换的字符串的意思 |
| string | 即表示要被处理,要被替换的那个 string 字符串 |
| count | 对于pattern中匹配到的结果,count可以控制对前几个group进行替换 |
| flags | 正则表达式修饰符 |
具体使用可以看下下面的这个实例,注释都写的很清楚的了,主要是注意一下,第二个参数是可以传递一个函数的,这也是这个方法的强大之处,例如例子里面的函数 convert ,对传递进来要替换的字符进行判断,替换成不同的字符。
import re
a = 'zhanghao*:[email protected]*study@@python'
# 把字符串中的 * 字符替换成 & 字符
sub1 = re.sub('\*', '&', a)
print(sub1)
# 把字符串中的第一个 * 字符替换成 & 字符
sub2 = re.sub('\*', '&', a, 1)
print(sub2)
# 把字符串中的 * 字符替换成 & 字符,把字符 - 换成 |
# 1、先定义一个函数
def convert(value):
group = value.group()
if (group == '*'):
return '&'
elif (group == '-'):
return '|'
# 第二个参数,要替换的字符可以为一个函数
sub3 = re.sub('[\*-]', convert, a)
print(sub3)
输出:
zhanghao&:2231625934@qq.com-&study@@python
zhanghao&:2231625934@qq.com-*study@@python
zhanghao&:2231625934@qq.com|&study@@python
6. Python正则表达式|re.match,re.search
re.match函数:
re.match(pattern,string,flag=0)
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.search()函数:
re.search(pattern,string,flags=0)
re.search扫描整个字符串并返回第一个成功的匹配。
re.match和re.search的参数,基本一致的,具体描述如下:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写 |
二者区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配;
下面实例,对比re.search和re.findall的区别:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
# 提取图片的地址
import re
a = ' '
# 使用 re.search
search = re.search('
'
# 使用 re.search
search = re.search(') ', a)
# group(0) 是一个完整的分组
print(search.group(0))
print(search.group(1))
# 使用 re.findall
findall = re.findall('', a)
print(findall)
# 多个分组的使用(比如我们需要提取 img 字段和图片地址字段)
re_search = re.search('<(.*) src="(.*)">', a)
# 打印 img
print(re_search.group(1))
# 打印图片地址
print(re_search.group(2))
# 打印 img 和图片地址,以元祖的形式
print(re_search.group(1, 2))
# 或者使用 groups
print(re_search.groups())
', a)
# group(0) 是一个完整的分组
print(search.group(0))
print(search.group(1))
# 使用 re.findall
findall = re.findall('', a)
print(findall)
# 多个分组的使用(比如我们需要提取 img 字段和图片地址字段)
re_search = re.search('<(.*) src="(.*)">', a)
# 打印 img
print(re_search.group(1))
# 打印图片地址
print(re_search.group(2))
# 打印 img 和图片地址,以元祖的形式
print(re_search.group(1, 2))
# 或者使用 groups
print(re_search.groups())
输出:
<img src="https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343">
https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343
['https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343']
img
https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343
('img', 'https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343')
('img', 'https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343')
正则表达式可以用来解决字符串内置函数无法解决的问题,在python爬虫和数据分析应用很广泛。
五、Pandas简介
1. Pandas官网
Pandas是一款开放源码的BSD许可的Python库,为python编程语言提供了高性能,易于使用的数据结构和数据分析工具。Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域。
Pandas官网
2. Pandas库的介绍
Pandas是一个开放源码的Python库,它使用强大的数据结构提供高性能的数据操作和分析工具。它的名字:Pandas是从Panel Data - 多维数据的计量经济学(an Econometrics from Multidimensional data)。
2008年,为满足需要高性能,灵活的数据分析工具,开发商Wes McKinney开始开发Pandas。
在Pandas之前,Python主要用于数据迁移和准备。对数据分析的贡献小。 Pandas解决了这个问题。 使用Pandas可以完成数据处理和分析的五个典型步骤,而不管数据的来源 - 加载,准备,操作,模型和分析。
Python Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域。
Pandas的主要特点
- 快速高效的DataFrame对象,具有默认和自定义的索引。
- 将数据从不同文件格式加载到内存中的数据对象的工具。
- 丢失数据的数据对齐和综合处理。
- 重组和摆动日期集。
- 基于标签的切片,索引和大数据集的子集。
- 可以删除或插入来自数据结构的列。
- 按数据分组进行聚合和转换。
- 高性能合并和数据加入。
- 时间序列功能。
3. Pandas库的安装
pip install pandas
4. Pandas数据结构
Pandas处理以下三个数据结构
- 系列(Series)
- 数据帧(DataFrame)
- 面板(Panel)
这些数据结构构建在Numpy数组之上,这意味着它们很快。
六、Python hashlib库的使用
1. 为什么需要hashlib库?
任何允许用户登录的网站或app都会存储用户登录的用户名和口令。密码一般都不会以明文的方式进行存储,防止数据泄露。
2. hashlib库使用方法
python里面的hashlib模块提供了很多加密算法:
- md5()加密算法
import hashlib
hash = hashlib.md5() # 创建了一个md5算法的对象(md5不能反解),即造出hash工厂
hash.update(bytes('password',encoding='utf-8')) # 运送原材料,要对哪个字符串进行加密就放在这
print(hash.hexdigest()) # 产出hash值,拿到加密字符串
输出:
5f4dcc3b5aa765d61d8327deb882cf99
我们可以看出生成结果是一个32位的16进制的字符串,生成结果是固定的128bit字节(需要注意的是加密是固定的,就是关系是一一对应的),是存在缺陷的,可以被对撞出来,特备是一些使用123456类似作为密码的用户。
- sha1()算法
import hashlib
hash2 = hashlib.sha1()
hash2.update(bytes('password',encoding='utf-8'))
print(hash2.hexdigest())
输出:
5baa61e4c9b93f3f0682250b6cf8331b7ee68fd8
sha1()加密算法的结果是160bit字节,通常用一个40位的16进制字符串表示。
- sha256()算法
import hashlib
hash3 = hashlib.sha256()
hash3.update(bytes('password',encoding='utf-8'))
print(hash3.hexdigest())
输出:
5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8
比sha1更安全的是sha256和sha512,不过约安全算法越慢,而且摘要长度更长。
七、Python random模块的使用
python的random模块包含很多随机数生成器
1. 生成随机数
# coding=utf-8
import random
print(random.randint(1,5))
print(random.randrange(0,51,5))
输出:
5
25
randint(start, end)会返回一个start到end之间的整数,这里是左闭右闭区间。也就是说可能会返回end值,在Python中,这个是一个比较特殊的地方,一般来说都是左闭右开的区间。
randrange(start, end, step)返回一个range(start, end, step)生成的列表中的随机一个值。这里是左闭右开区间,如果上面代码的51如果换成50,则不可能返回50。
每次运行的结果是不同的,因为是随机返回其中一个。
2. 生成随机的小数
# coding=utf-8
import random
print(random.random())
print(random.uniform(2, 5))
输出:
0.5941935811452218
2.52478420398092
3. 从字符串、列表、元组中随机返回一个值
# coding=utf-8
import random
choice_str = 'python'
print(random.choice(choice_str))
choice_list = [i for i in range(1, 6)]
print('choice_list:', choice_list)
print(random.choice(choice_list))
choice_tuple = (10, 20, 30, 40, 50)
print(random.choice(choice_tuple))
输出:
n
choice_list: [1, 2, 3, 4, 5]
2
10
choice()返回可迭代对象中的一个值。可以是列表、元组、字符串、不能是字典和集合。
4. 从字符串、列表、元组中随机返回一次或多次,且设置权重
import random
choice_list = [i for i in range(1, 6)]
print('choice_list:', choice_list)
print(random.choices(choice_list))
choice_tuple = (10, 20, 30, 40, 50)
print(random.choices(choice_tuple, k=2))
choice_str = 'python'
print(random.choices(choice_str, weights=[0.5, 0, 0.5, 0, 0, 0],k=7))
print(random.choices(choice_str, cum_weights=[0, 0.5, 0.5, 1, 1, 1],k=7))
输出:
choice_list: [1, 2, 3, 4, 5]
[1]
[50, 20]
['p', 't', 't', 't', 't', 'p', 't']
['y', 'y', 'y', 'y', 'y', 'h', 'y']
choices(population, weights=None, cum_weights=None, k=1)从可迭代对象中返回一次或多次值,返回结果是一个列表。
weights是每一个值对应的权重列表,默认是None,所有元素权重相等。传入权重列表时,列表长度必须与可迭代对象的长度相等,值与权重按索引一一对应。传入的值可以是任何数字,只要能对比出不同值之间的权重大小就可以,系统会按权重大小来计算返回每个值的可能性,如上面的例子中只会返回“python”中的p和t,因为其他字符的权重为0。
cum_weights是每一个值对应的累计权重列表,默认是None,所有元素权重相等。传入权重列表时,列表长度必须与可迭代对象的长度相等。权重是累计的,每一个位置的累计权重是前面所有元素的权重之和加上当前位置元素的权重,也就是说这个列表后面的值不可能小于前面的值。系统会根据累计权重值计算出每个元素的权重,然后计算返回每个值的可能性,如上面的例子中只会返回“python”中的y和h,因为其他字符的权重是0。
注意:weights和cum_weights不能同时有值,即使计算结果一样。
k值是从可迭代对象中获取值的次数,每次只取其中的一个,重复k次,所以,理论上,有可能k次都取到同一个元素。
5. 从字符串、列表、元组中随机获取一个或多个值
import random
sample_list = [i for i in range(1, 6)]
print("sample_list: ", sample_list)
print(random.sample(sample_list, 1))
sample_tuple = (10, 20, 30, 40, 50)
print(random.sample(sample_tuple, 2))
sample_str = 'python'
print(random.sample(sample_str, 3))
输出:
sample_list: [1, 2, 3, 4, 5]
[1]
[40, 30]
['o', 'p', 'y']
sample(population, k)从可迭代对象中随机返回k个元素,返回一个列表。
k表示返回元素的个数,这个参数没有默认值,必须传值。并且,是一次从可迭代对象中返回k个值,不是分k次,每个元素不会重复被取。此外,k值不可以大于可迭代对象的长度,否则报错,而上面choices中的k可以无限大,只要需要。使用场景不同,要注意区别。
6. 随机打乱顺序
import random
cards = ['%s-%s' % (a, b) for a in ['Spade', 'Heart', 'Diamond', 'Club'] for b in
([str(i) for i in range(3, 11)] + [j for j in 'JQKA2'])] + ['Black joker', 'Red joker']
print("Before: ", cards)
random.shuffle(cards)
print("After: ", cards)
输出:
Before: ['Spade-3', 'Spade-4', 'Spade-5', 'Spade-6', 'Spade-7', 'Spade-8', 'Spade-9', 'Spade-10', 'Spade-J', 'Spade-Q', 'Spade-K', 'Spade-A', 'Spade-2', 'Heart-3', 'Heart-4', 'Heart-5', 'Heart-6', 'Heart-7', 'Heart-8', 'Heart-9', 'Heart-10', 'Heart-J', 'Heart-Q', 'Heart-K', 'Heart-A', 'Heart-2', 'Diamond-3', 'Diamond-4', 'Diamond-5', 'Diamond-6', 'Diamond-7', 'Diamond-8', 'Diamond-9', 'Diamond-10', 'Diamond-J', 'Diamond-Q', 'Diamond-K', 'Diamond-A', 'Diamond-2', 'Club-3', 'Club-4', 'Club-5', 'Club-6', 'Club-7', 'Club-8', 'Club-9', 'Club-10', 'Club-J', 'Club-Q', 'Club-K', 'Club-A', 'Club-2', 'Black joker', 'Red joker']
After: ['Diamond-A', 'Diamond-3', 'Diamond-5', 'Spade-8', 'Diamond-10', 'Heart-5', 'Heart-K', 'Club-A', 'Heart-3', 'Club-2', 'Spade-7', 'Club-3', 'Black joker', 'Spade-K', 'Club-6', 'Heart-A', 'Diamond-9', 'Club-8', 'Spade-Q', 'Diamond-4', 'Heart-J', 'Spade-10', 'Diamond-K', 'Club-4', 'Club-9', 'Red joker', 'Heart-4', 'Club-K', 'Diamond-6', 'Heart-10', 'Spade-3', 'Heart-7', 'Heart-8', 'Club-5', 'Spade-2', 'Club-7', 'Diamond-2', 'Club-Q', 'Spade-9', 'Club-J', 'Spade-J', 'Diamond-Q', 'Club-10', 'Heart-9', 'Spade-6', 'Spade-A', 'Spade-4', 'Heart-2', 'Heart-Q', 'Diamond-7', 'Spade-5', 'Diamond-J', 'Diamond-8', 'Heart-6']
shuffle()将可迭代对象的顺序随机打乱,上面例子中我们模拟了一副扑克牌,然后用shuffle()完成“洗牌”。注意:shuffle()没有返回值,是直接对可迭代对象进行修改。
random除了上面的方法外,还有一些按数学分布随机生成数据的方法,如正太分布,指数分布等,这里就不继续举例了,其实random源码也不是很多,里面的方法数量是人工可数的,需要的话您可以在Pycharm中按住Ctrl点进去看看。
八、Python 读写yaml文件
yaml是一个专门用来写配置文件的语言。
1. pyyaml
- yaml文件规则
- 区分大小写
- 使用缩进表示层级关系
- 使用空格键缩进,而非Tab键
- 缩进的空格数目不固定,只需要相同层级的元素左对齐即可
- 文件中的字符串不需要使用引号标注,但若字符串包含有特殊字符则需要用引号标注
- 注释符为#
- yaml文件数据结构
- 对象:键值对的集合(简称“映射或字典”),键值对用冒号“:”,冒号与值之间需要用空格分隔
- 数组:一组按序排列的值(简称“序列或列表”),数组前加有“-”符号,符号与值之间需要用空格分隔
- 纯量(scalars):单个的,不可再分的值(如:字符串、bool值、整数、浮点数、时间、日期、null等)
- None值可用null可~表示
- python的yaml库
安装:pip install pyyaml
使用:from ruamel import yaml
在我们做自动化测试中,可用作配置文件,配置一些服务器域名,mysql配置,登录信息,toekn等很方便获取。
将字典写入yaml文件
ModuleNotFoundError: No module named ‘ruamel’
解决方式:
pip install ruamel.yaml
from ruamel import yaml
desired_caps = {
'platformName':'Android哈哈哈',#移动设备系统IOS或Android
'platformVersion':'7.1.2',#Android手机系统版本号
'deviceName':'852',#手机唯一设备号
'app':'C:\\Users\\wangli\\Desktop\\kbgz-v5.9.0-debug.apk',#APP文件路径
'appPackage':'com',#APP包名
'appActivity':'cui.setup.SplashActivity',#设置启动的Activity
'noReset':'True',#每次运行不重新安装APP
'unicodeKeyboard':'True', #是否使用unicode键盘输入,在输入中文字符和unicode字符时设置为true
'resetKeyboard':'True',#隐藏键盘
'autoGrantPermissions':'True',
'autoAcceptAlerts':["python","c++","java"],
'chromeOptions': {'androidProcess': 'com.tencent.mm:tools'}
}
with open("test.yaml","w",encoding="utf-8") as f:
yaml.dump(desired_caps,f,Dumper=yaml.RoundTripDumper)
结果如下:
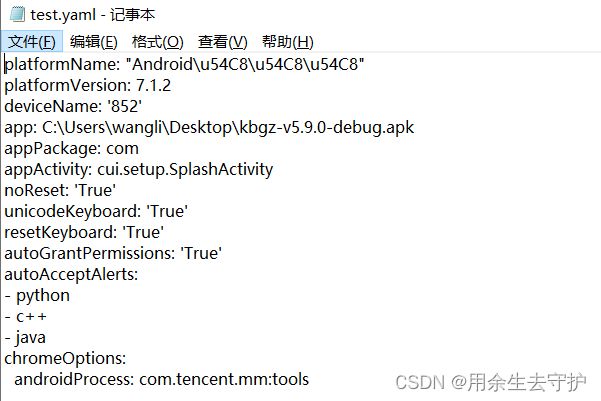
读取yaml文件
from ruamel import yaml
with open('test.yaml', 'r', encoding='utf-8') as f:
print(yaml.load(f.read(),Loader=yaml.Loader))
输出:
{'platformName': 'Android哈哈哈', 'platformVersion': '7.1.2', 'deviceName': '852', 'app': 'C:\\Users\\wangli\\Desktop\\kbgz-v5.9.0-debug.apk', 'appPackage': 'com', 'appActivity': 'cui.setup.SplashActivity', 'noReset': 'True', 'unicodeKeyboard': 'True', 'resetKeyboard': 'True', 'autoGrantPermissions': 'True', 'autoAcceptAlerts': ['python', 'c++', 'java'], 'chromeOptions': {'androidProcess': 'com.tencent.mm:tools'}}
九、Python MongoDB
MongoDB是目前最流行的NoSQL数据库之一,使用的数据类型BSON(类似JSON)。
1. PyMongo
python要连接MongoDB需要MongoDB驱动,这里我们使用驱动来连接。
2. PyMongo pip 安装
安装pymongo: python3 -m pip3 install pymongo
指定版本安装:python3 -m pip3 install pymongo==3.5.1
更新pymongo命令:python3 -m pip3 install --update pymongo
十、Python 日期和时间
- python提供了一个time和calendar模块可以用于格式化日期和时间。
- 时间间隔是以秒为单位的浮点小数。
- 每个时间都是以自1970年1月1日经历了多长时间来表示。
1. Python的time模块
python的time模块下有很多函数可以转换常见的日期。如time.time()用于获取当前时间戳:
# !/usr/bin/python3
import time
ticks = time.time()
print("当前时间为:", ticks)
输出:
当前时间为: 1659331239.0492644
时间戳单位最适合做日期运算。但是1970年之前的日期就无法用此表示。太遥远的也不行,unix和windows只支持到2038年。
2. 什么是时间元组?
很多python函数用一个元组装起来的9组数字处理时间。
| 字段 | 值 |
|---|---|
| 4位数年 | 2008 |
| 月 | 1 到 12 |
| 日 | 1到31 |
| 小时 | 0到23 |
| 分钟 | 0到59 |
| 秒 | 0到61 (60或61 是闰秒) |
| 一周的第几日 | 0到6 (0是周一) |
| 一年的第几日 | 1到366 (儒略历) |
| 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述也就是struct_time元组。这种结构具有如下属性:
| 属性 | 值 |
|---|---|
| tm_year | 2008 |
| tm_mon | 1 到 12 |
| tm_mday | 1 到 31 |
| tm_hour | 0 到 23 |
| tm_min | 0 到 59 |
| tm_sec | 0 到 61 (60或61 是闰秒) |
| tm_wday | 0到6 (0是周一) |
| tm_yday | 一年中的第几天,1 到 366 |
| tm_isdst | 是否为夏令时,值有:1(夏令时)、0(不是夏令时)、-1(未知),默认 -1 |
3. 获取当前时间
从返回浮点数的时间戳方式向时间元组转换,只要将浮点数传递给如localtime之类的函数。
#!/usr/bin/python3
import time
localtime = time.localtime(time.time())
print("本地时间为:", localtime)
输出:
本地时间为: time.struct_time(tm_year=2022, tm_mon=8, tm_mday=1, tm_hour=14, tm_min=15, tm_sec=16, tm_wday=0, tm_yday=213, tm_isdst=0)
4. 获取格式化的时间
我们可以根据需求选取各种格式,到那时最简单的获取可读的时间模式的函数是asctime():
#!/usr/bin/python3
import time
localtime = time.asctime(time.localtime(time.time()))
print("本地时间为:", localtime)
输出:
本地时间为: Mon Aug 1 14:18:09 2022
5. 格式化日期
我们可以使用time模块的strftime方法来格式化日期:
time.strftime(format[, t])
#!/usr/bin/python3
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
输出:
2022-08-01 14:19:55
Mon Aug 01 14:19:55 2022
1459175064.0
5. python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
6. python 获取某月日历
calendar 模块有广泛的方法用来处理年历和月历:
#!/usr/bin/python3
import calendar
cal = calendar.month(2022, 8)
print ("以下输出2022年8月份的日历:")
print (cal)
输出:
以下输出2022年8月份的日历:
August 2022
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6 7
8 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
29 30 31
十一、Python JSON数据
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于ECMA Script的一个子集。
python3中可以使用json模块来对JSON数据进行编码和解码,它包含两个函数:
- json.dumps():对数据进行编码
- json.loads():对数据进行解码
在json的编码解码过程中,python的原始类型与json类型会相互转换,具体对照关系如下:
1. Python 编码为 JSON 类型转换对应表:
| Python | JSON |
|---|---|
| dict | object |
| list, | tuple array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
2. JSON 解码为 Python 类型转换对应表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
3. json.dumps与json.loads实例:
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data = {
'no' : 1,
'name' : 'Pythonf',
'url' : 'https://www.pythonf.cn'
}
json_str = json.dumps(data)
print ("Python 原始数据:", repr(data))
print ("JSON 对象:", json_str)
输出:
Python 原始数据: {'no': 1, 'name': 'Pythonf', 'url': 'https://www.pythonf.cn'}
JSON 对象: {"no": 1, "name": "Pythonf", "url": "https://www.pythonf.cn"}
通过输出的结果可以看出,简单的类型通过编码后跟其原始的repr()输出结果非常相似。
将JSON编码的字符串转换回一个python数据结构:
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data1 = {
'no' : 1,
'name' : 'Pythonf',
'url' : 'https://www.pythonf.cn'
}
json_str = json.dumps(data1)
print ("Python 原始数据:", repr(data1))
print ("JSON 对象:", json_str)
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print ("data2['name']: ", data2['name'])
print ("data2['url']: ", data2['url'])
输出:
Python 原始数据: {'no': 1, 'name': 'Pythonf', 'url': 'https://www.pythonf.cn'}
JSON 对象: {"no": 1, "name": "Pythonf", "url": "https://www.pythonf.cn"}
data2['name']: Pythonf
data2['url']: https://www.pythonf.cn
十二、Python 多线程
多线程类似于同时执行多个不同程序,多线程运行有以下优点:
- 使用线程可以把占据长时间爱你的程序中的任务放到后台去处理;
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理进度;
- 程序的运行速度可能加快;
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口,顺序执行序列和程序的出口,但是线程不能够给独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有它自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断);
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠),这就是线程的退让;
线程可以分为:
- 内核线程:由操作系统内核创建和撤销;
- 用户线程:不需要内核支持而在用户程序中实现的线程;
python3线程中常用的两个模块为:
- _thread
- threading
thread 模块已被废弃,我们可以使用threading模块代替,为了兼容性,python3将thread重命名为_thread。
1. 学习python线程
python中使用线程有两种方式:函数或用类来包装线程对象。
函数式:调用_thread模块中的start_new_thread()函数来产生新线程,语法如下:
_thread.start_new_thread(function, args[, kwargs])
参数说明:
- function :线程函数;
- args: 传递给线程函数的参数,必须是个tuple类型。
- kwargs: 可选参数
示例:
#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass
输出:
Thread-1: Mon Aug 1 15:06:48 2022
Thread-2: Mon Aug 1 15:06:50 2022
Thread-1: Mon Aug 1 15:06:50 2022
Thread-1: Mon Aug 1 15:06:52 2022
Thread-2: Mon Aug 1 15:06:54 2022
Thread-1: Mon Aug 1 15:06:54 2022
Thread-1: Mon Aug 1 15:06:56 2022
Thread-2: Mon Aug 1 15:06:58 2022
Thread-2: Mon Aug 1 15:07:02 2022
Thread-2: Mon Aug 1 15:07:06 2022
执行上述进程后可以按ctrl+c 退出
2. 线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
3. 使用 threading 模块创建线程
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
输出:
开始线程:Thread-1
开始线程:Thread-2
Thread-1: Mon Aug 1 15:11:04 2022
Thread-2: Mon Aug 1 15:11:05 2022
Thread-1: Mon Aug 1 15:11:05 2022
Thread-1: Mon Aug 1 15:11:06 2022
Thread-2: Mon Aug 1 15:11:07 2022
Thread-1: Mon Aug 1 15:11:07 2022
Thread-1: Mon Aug 1 15:11:08 2022
退出线程:Thread-1
Thread-2: Mon Aug 1 15:11:09 2022
Thread-2: Mon Aug 1 15:11:11 2022
Thread-2: Mon Aug 1 15:11:13 2022
退出线程:Thread-2
退出主线程
3. 线程同步
4. 线程优先级队列(Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
十三、Python 迭代器与生成器|iter()、next()
1. 迭代器
- 迭代是python最强大的功能之一,是访问集合元素的一种方式。
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不能后退。
迭代器有两个基本的方法:iter()和next()
字符串、列表、或元组对象都可用于创建迭代器:
list = [1,2,3,4]
it = iter(list)
print(it)
print(next(it))
print(next(it))
print(next(it))
print(next(it))
print(next(it))
输出:
1
2
3
4
Traceback (most recent call last):
File ".\py_study.py", line 564, in <module>
print(next(it))
StopIteration
十四、Python 标准库
1. 操作系统模块
os模块提供了不少与操作系统相关联的函数。
import os
print(os.getcwd())
print(os.chdir(r'E:\py\python3.7\test2\test35shuati\new\test'))
print(os.system('mkdir today'))
输出:
E:\py\python3.7\test2\test35shuati\new
None
0
建议使用import os ,而非from os import * ,这样可以保证随操作系统不同而有所变化的os.open()不会覆盖内置函数open().
在使用os这样的大型模块时内置的dir()和help()函数非常有用:
import os
print(dir(os))
print("\n")
print(help(os))
输出:
['DirEntry', 'F_OK', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX', 'W_OK', 'X_OK', '_Environ', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_putenv', '_unsetenv', '_wrap_close', 'abc', 'abort', 'access', 'altsep', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve', 'execvp', 'execvpe', 'extsep', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable',
'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'linesep', 'link', 'listdir', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name', 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep', 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks',
'symlink', 'sys', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'walk', 'write']
Help on module os:
NAME
os - OS routines for NT or Posix depending on what system we're on.
DESCRIPTION
This exports:
- all functions from posix or nt, e.g. unlink, stat, etc.
- os.path is either posixpath or ntpath
- os.name is either 'posix' or 'nt'
- os.curdir is a string representing the current directory (always '.')
- os.pardir is a string representing the parent directory (always '..')
- os.sep is the (or a most common) pathname separator ('/' or '\\')
- os.extsep is the extension separator (always '.')
- os.altsep is the alternate pathname separator (None or '/')
- os.pathsep is the component separator used in $PATH etc
- os.linesep is the line separator in text files ('\r' or '\n' or '\r\n')
-- More --
针对日常的文件和目录管理任务,mod:shutil模块提供了一个易于使用的高级接口:
import shutil
print(shutil.copyfile('data.db', 'archive.db'))
print(shutil.move(r'E:\py\python3.7\test2\test35shuati\new\test', 'today'))
输出:
archive.db
today
2. 文件通配符
golb模块提供了一个函数用于从目录通配符搜索中生成文件列表:
import glob
print(glob.glob('*.py'))
输出:
['csdn.py', 'huaweijikao.py', 'NC.py', 'py_study.py', 'test.py']
3. 命令行参数
通用工具脚本经常调用命令行参数,这些命令行参数以链表的形式存于sys模块的argv变量。例如,在命令行中执行"python py_study.py one two three"
import sys
print(sys.argv)
输出:
['py_study.py', 'one', 'two', 'three']
4. 错误输出重定向和程序终止
sys 还有stdin,stdout,和stderr属性,即使在stdout被重定向时,后者也可以用于显示警告和错误信息。
import sys
print(sys.stderr.write('Warning, log file not found starting a new one \n'))
输出:
Warning, log file not found starting a new one
48
大多脚本的定向终止都使用“sys.exit()”
5. 字符串正则匹配
re模块为高级字符串提供了正则表达式工具,对于复杂的匹配和处理,正则表达式提供了简介、优化的方案:
6. 数学
math模块为浮点运算提供了对底层C函数库的访问:
import math
print(math.cos(math.pi/4))
print(math.log(1024, 2))
输出:
0.7071067811865476
10.0
random提供了生成随机数的工具:
6. 访问互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从urls接受的数据的urllib.request以及用于发送电子邮件的smtplib
十五、Python File(文件)方法|open、close、file对象常用函数
1. open()方法
python open()方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要用到这个函数,如果文件无法打开,会抛出OSError。
注意:使用open()方法一定要保证关闭对象,即调用close()方法。
open()函数常用形式是接受两个参数:文件名(file)和模式(mode).
open(file, mode=‘r’)
完整的语法格式为:
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上b.
file 对象
file 对象使用open函数来创建,下表列出了file对象常用的函数:
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.read([size]) | f从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 “\n” 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 移动文件读取指针到指定位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
十六、Python 输入输出
1. 输出格式美化
python 有两种输出值的方式:表达式语句和print()函数。
第三种方式是使用文件对象的write()方法,标准输出文件可以用sys.stdout引用。
如果我们希望输出的形式更加多样,可以使用str.format()函数来格式化输出值,如果我们希望将输出的值转换成字符串,可以使用repr()或str()函数来实现。
- str():函数返回一个用户易读的表达形式。
- repr():产生一个解释器易读的形式。
repr()函数可以转义字符串中的特殊字符;
repr()函数的参数可以是python的任何对象;
这里有两种输出一个平方与立方表方式:
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# 注意前一行'end'的使用
print(repr(x*x*x).rjust(4))
for x in range(1, 11):
print('{0:2d}{1:4d}{2:6d}'.format(x, x*x, x*x*x))
输出:
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
注意:在第一个例子中,每列间的空格由print()添加。第二个例子展示了字符串对象的rjust()方法,它可以将字符串靠右,并在左边填充空格。还有类似的方法,如ljust()和center()。这些方法不会写任何内容,仅仅返回新的字符串。
另一个方法zfill(),它会在数字的左边填充0,如下:
print('12'.zfill(5))
print('-3.14'.zfill(7))
print('3.14159265359'.zfill(5))
输出:
00012
-003.14
3.14159265359
str.format()使用如下:
print('{}网址:"{}!"'.format('Python教程','https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343'))
输出:
Python教程网址:"https://blog.csdn.net/qq_45365214?spm=1011.2415.3001.5343!"
括号及其里面的字符称为格式化字段,将会被format()中的参数替换。还可以通过使用关键字参数控制传入对象在format()中的位置。
!a (使用 ascii() ), !s (使用 str() ) 和 !r (使用 repr() ) 可以用于在格式化某个值之前对其进行转化:
十七、Python 的异步IO编程
1. 创建第一个协程
python3.7 推荐使用async/await语法来声明协程,来编写异步应用程序。
例如:首先打印一行"你好,若竹",等待一秒后再打印"用余生去守护"。
import asyncio
async def sayhi():
print("你好,若竹")
await asyncio.sleep(1)
print("用余生去守护")
asyncio.run(sayhi())
输出:
你好,若竹
用余生去守护
sayhi()函数通过async声明为协程函数,较之前的修饰器声明更简洁。
在实践中,那些能发挥异步IO性能的函数,比如读写文件,读写网络,读写数据库,这些都是浪费时间的IO 操作,把它们协程化,异步优化从而提高程序的整体效率(速度)。
sayhi()函数是通过asyncio.run()来运行的,而不是直接调用这个函数(协程)。因为直接调用并不会把它加入调度日程,而只是简单的返回一个协程对象。
那么如何真正运行一个协程呢?asyncio提供了三种机制:
- asyncio.run()函数,这是异步程序的主入口,相当于C语言中的main函数
- 用await等待协程,比如上例中的await asyncio.sleep(1)
顺序运行两个协程:
import asyncio
import time
async def say_delay(msg, delay):
await asyncio.sleep(delay)
print(msg)
async def main():
print(f"begin at {time.strftime('%H:%M:%S')}")
await say_delay('你好,若竹', 1)
await say_delay('用余生去守护', 2)
print(f"end at {time.strftime('%H:%M:%S')}")
asyncio.run(main())
输出:
begin at 15:28:41
你好,若竹
用余生去守护
end at 15:28:44
从起始时间看,两个协程是顺序执行的,总耗时3秒。
- 通过asyncio.create_task()函数并发运行作为asyncio任务(Task)的多个线程。
并发运行两个协程
import asyncio
import time
async def say_delay(msg, delay):
await asyncio.sleep(delay)
print(msg)
async def main():
task1 = asyncio.create_task(say_delay("你好,若竹", 1))
task2 = asyncio.create_task(say_delay("用余生去守护", 2))
print(f"begin at {time.strftime('%H:%M:%S')}")
await task1
await task2
print(f"end at {time.strftime('%H:%M:%S')}")
asyncio.run(main())
输出:
begin at 15:39:43
你好,若竹
用余生去守护
end at 15:39:45
从运行结果的起止时间可以看出,两个协程并行,总耗时等于最大耗时2秒。
asyncio.create_task()是一个很有用的函数,在爬虫中它可以帮助我们实现大量并发去下载网页。在python3.6中对应的是ensure_future()。
2. 可等待对象(awaitables)
可等待对象,就是可以在await表达式中使用的对象,前面我们已经接触了两种可等待对象的类型:协程和任务,还有一个是低层级的Future。
asyncio模块的许多API都需要传入可等待对象,比如run(),create_task()等等。
- 协程
协程是可等待对象,可以在其它协程中被等待。
- 协程函数:通过async def 定义的函数;
- 协程对象:调用协程函数返回的对象;
import asyncio
import time
async def waittime():
return time.time()
async def main():
# 直接调用协程函数,返回的是协程对象
co = waittime()
print('co is ', type(co))
now = await co
print(f'now is {now}')
now2 = await waittime()
print(f'now is {now2}')
asyncio.run(main())
输出:
co is <class 'coroutine'>
now is 1659426624.157212
now is 1659426624.157212
可以看出,直接运行协程函数waittime()得到co 是一个协程对象,因为协程对象时可等待的,所以通过await得到真正的当前时间。now2是直接await协程函数,也得到了当前时间的返回值。
- 任务
前面我们讲到,任务是用来调度协程的,以便并发执行协程。当一个协程通过asyncio.create_task()被打包为一个任务,该协程将自动加入程序调度日程准备立即运行。
总结
分享:
严格地说,写作是一项非常个人化的事。作为一个现代科技工作者,要想在事业上有所成就,不但要在专业知识上打下坚实的基础,具有出众的创造才能,而且还要善于用语言文字清晰地阐述自己的思想、观点和科研成果。一个只会创造不会表达的人,他的发展肯定是会受到限制的。