PyTorch分布式DPP涉及的基本概念与问题
PyTorch分布式DPP涉及的基本概念与问题
- 1 分布式引入的参数
-
- 1.1 rank、local_rank、node等的概念
- 1.2 通信参数与模式
- 1.3 分布式任务中常用的函数
- 2 提速参数与隐藏的简单问题
-
- 2.1 dataloader提速的参数
- 2.2 checkpoint的保存与加载
- 2.3 dist.init_process_group的init_method 方式
- 2.4 进程内指定显卡
- 2.5 CUDA初始化的问题
本篇主要讲解DDP的一些概念和问题,主要涵盖如下:
1、参数rank、local_rank、node、gpu的含义,以及它们之间的关系?一个rank/local_rank是否就是对应一个gpu?
2、checkpoint保存与加载有什么不一样?
3、单卡到分布式,有些什么地方能帮助提速?
如果需要了解DDP使用请看上一篇
PyTorch分布式DPP启动方式(包含完整用例)
1 分布式引入的参数
1.1 rank、local_rank、node等的概念
- rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
- node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。 - nnodes、node_rank与nproc_per_node: nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
- word size : 全局(一个分布式任务)中,rank的数量。
上一个运算题: 每个node包含16个GPU,且nproc_per_node=8,nnodes=3,机器的node_rank=5,请问word_size是多少?
答案:word_size = 3*8 = 24
为了方便理解举个例子,比如分布式中有三台机器,每台机器起4个进程,每个进程占用1个GPU,如下图所示:
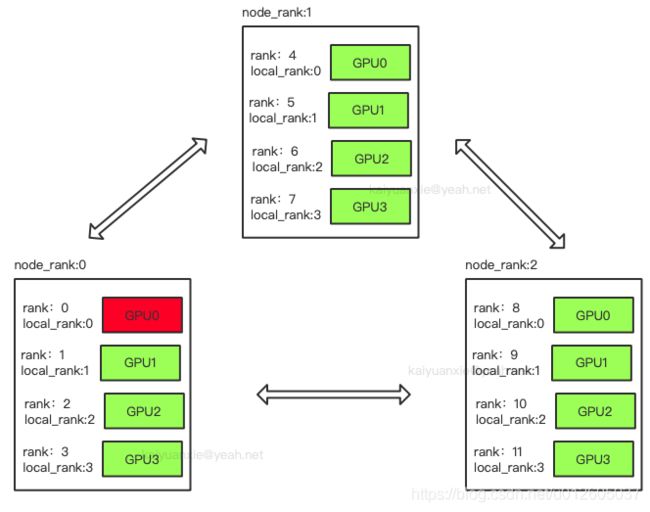
图中:一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都一个对应的node_rank。
Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group。
注意:
1、rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU)。
这一点在理解分布式通信原理的时候比较重要。因为很多资料里面对RingAllReduce、PS-WorK 等模式解释时,习惯默认一个rank对应着一个GPU,导致了很多人认为rank就是对GPU的编号。
2、“为什么程序里面的进程用rank表示而不用proc表示?”
这是因为pytorch是在不断迭代中开发出来的,有些名词或者概念并不是一开始就设计好的。所以,会发现node_rank 跟软节点的rank没有直接关系。
1.2 通信参数与模式
通信过程主要是完成模型训练过程中参数信息的传递,主要考虑通信后端和通信模式选择,后端与模式对整个训练的收敛速度影响较大,相差可达2~10倍。 在DDP中支持了几个常见的通信库,而数据处理的模式写在PyTorch底层,供用户选择的主要是后端。 在初始化时需要设置:
-
backend :通信后端,可选的包括:nccl(NVIDIA推出)、gloo(Facebook推出)、mpi(OpenMPI)。从测试的效果来看,如果显卡支持nccl,建议后端选择nccl,,其它硬件(非N卡)考虑用gloo、mpi(OpenMPI)。
-
master_addr与master_port:主节点的地址以及端口,供init_method 的tcp方式使用。 因为pytorch中网络通信建立是从机去连接主机,运行ddp只需要指定主节点的IP与端口,其它节点的IP不需要填写。 这个两个参数可以通过环境变量或者init_method传入。
# 方式1:
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl",
rank=rank,
world_size=world_size)
# 方式2:
dist.init_process_group("nccl",
init_method="tcp://localhost:12355",
rank=rank,
world_size=world_size)
1.3 分布式任务中常用的函数
在分布式中有许多功能函数,可以参看torch分布式API, 这里例举一些最常用的函数:
- 功能函数:
判断底层通信库是否可用:
torch.distributed.is_nccl_available() # 判断nccl是否可用
torch.distributed.is_mpi_available() # 判断mpi是否可用
torch.distributed.is_gloo_available() # 判断gloo是否可用
获取当前进程的rank
torch.distributed.get_rank(group=None) # group=None,使用默认的group
获取任务中(或者指定group)中,进程的数量
torch.distributed.get_rank(group=None) # group=None,使用默认的group
获取当前任务(或者指定group)的后端。
torch.distributed.get_backend(group=None) # group=None,使用默认的group
- 通信函数:
分布式的梯度聚合工作在DDP中完成,一般用户不需要去修改,但是对于一些需要多机进程之间交流的信息,用户就需要调用一些后端操作的API。后端对一些操作的支持方式:

对于上述的一些操作,可以参照NCCL库来理解原理,这里例举常用的操作:
- reduce操作:

torch.distributed.reduce(tensor, dst, op=<ReduceOp.SUM: 0>, group=None, async_op=False)
# op:元素进行reduce计算的方式。
# async_op: 是否进行异步操作。
- all_reduce操作函数: 将不同rank进程的数据进行操作。比如sum操作。

torch.distributed.all_reduce(tensor, op=<ReduceOp.SUM: 0>, group=None, async_op=False)
# op:元素进行reduce计算的方式。
# async_op: 是否进行异步操作。
举例:

all_gather操作:
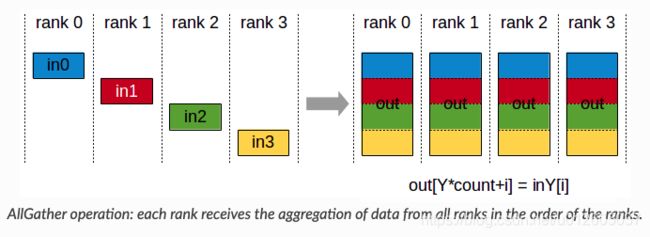
torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)
举例:

- 等待/同步操作
对所有的进程进行同步,比如利用rank0进行数据的拷贝,而其他进程等待rank0完成操作。
torch.distributed.barrier(group=None, async_op=False, device_ids=None)
2 提速参数与隐藏的简单问题
2.1 dataloader提速的参数
num_workers: 加载数据的进程数量,默认只有1个,增加该数量能够提升数据的读入速度。(注意:该参数>1,在低版本的pytorch可能会触发python的内存溢出) pin_memory: 锁页内存,加快数据在内存上的传递速度。 若数据加载成为训练速度的瓶颈,可以考虑将这两个参数加上。
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=32,num_workers=16,pin_memory=True)
2.2 checkpoint的保存与加载
保存: 一般情况下,我们只需要保存一份ckpt即可。 可以用rank来指定一个进程保存:
if torch.distributed.get_rank() == 0: #一般用0,当然,可以选任意的rank保存。
torch.save(net, “net.pth”)
加载: 加载不同于保存,可以让每个进程独立的加载,也可以让某个rank加载后然后进行广播。值得注意的是,当模型大的情况下,独立加载最好将模型映射到cpu上,不然容易出现加载模型的OOM。
torch.load(model_path, map_location='cpu')
2.3 dist.init_process_group的init_method 方式
init_method支持tcp和共享文件两种,一般情况下我们使用tcp方式来分享信息,也可以用共享文档,但必须要保证共享文件在每个进程都能访问到,文件系统需要支持锁定。
# 方式一:
dist.init_process_group(
init_method='tcp://10.1.1.20:23456',
rank=args.rank,
world_size=4)
# 方式二:
dist.init_process_group(
init_method='file:///mnt/nfs/sharedfile',
rank=args.rank,
world_size=4)
2.4 进程内指定显卡
目前很多场景下使用分布式都是默认一张卡对应一个进程,所以通常,我们会设置进程能够看到卡数: 下面例举3种操作的API,其本质都是控制进程的硬件使用。
# 方式1:在进程内部设置可见的device
torch.cuda.set_device(args.local_rank)
# 方式2:通过ddp里面的device_ids指定
ddp_model = DDP(model, device_ids=[rank])
# 方式3:通过在进程内修改环境变量
os.environ['CUDA_VISIBLE_DEVICES'] = loac_rank
如果不设置显存可见的参数,那么节点内的rank会调用所用的显卡。这样的话一张显卡内可能加载多份模型进行了多份计算,对于大一点的模型或者batch_size设置大的情况下,会导致OOM;
对于显存占用小的模型,跑多份的结果有可能提速或者降速,取决于显卡的算力。 当一张显卡跑多个模型时,对于算力的压榨方式可以考虑用MPS提速,有兴趣可以看一下:MPS提速
2.5 CUDA初始化的问题
多进程中,防止cuda被初始化多次。错误日志如下:
torch1.8.0:
"Cannot re-initialize CUDA in forked subprocess. To use CUDA with
RuntimeError: Cannot re-initialize CUDA in forked subprocess.
To use CUDA with multiprocessing, you must use the 'spawn' start method
torch1.3.0:
RuntimeError: cuda runtime error (3) : initialization error at /pytorch/aten/src/THC/THCGeneral.cpp:50
导致错误的原因:在主进程里面使用了torch.cuda操作函数,导致了cuda多次初始化。 复现代码:
import torch
from torch.multiprocessing import Process
def test(rank):
torch.cuda.set_device(rank) #子进程中使用torch.cuda的API
if __name__ == "__main__":
world_size = torch.cuda.device_count() # 主进程中使用torch.cuda的API
processes = []
for rank in range(world_size):
p = Process(target=test, args=(rank,))
p.start()
processes.append(p)
for p in processes:
p.join()
解决方案:要么将cuda操作移入子进程,要么使用spawn函数。
原文首发于:PyTorch分布式训练基础–DDP使用
参考:
https://developer.nvidia.com/nccl
https://pytorch.apachecn.org/docs
https://pytorch.org/docs/stable/distributed.html#launch-utility
https://pytorch.org/docs/master/notes/ddp.html
https://discuss.pytorch.org/t/cuda-error-out-of-memory-when-load-models/38011