【LDF】线性判别函数(二)
感知准则函数
- 线性可分性
- 现有 n n n 个 样本: y 1 , y 2 , … , y n \mathbf{y}_1, \mathbf{y}_2, \ldots, \mathbf{y}_n y1,y2,…,yn, 这些样本来自于两个类别 ω 1 \omega_1 ω1 或 ω 2 \omega_2 ω2 。
- 任务: 寻找一个线性判别函数 g ( x ) = a T y g(\mathbf{x})=\mathbf{a}^T \mathbf{y} g(x)=aTy, 使对这 n n n 个样本的错分概率最小。
- 如果存在一个权向量 a \mathbf{a} a, 对所有 y ∈ ω 1 \mathbf{y} \in \omega_1 y∈ω1, 均有 a T y > 0 \mathbf{a}^T \mathbf{y}>0 aTy>0, 且对 所有 y ∈ ω 2 \mathbf{y} \in \omega_2 y∈ω2, 均有 a T y < 0 \mathbf{a}^T \mathbf{y}<0 aTy<0, 则这组样本集为线性可分的; 否则为线性不可分的。 (广义判别函数意义下)
- 样本规范化
- 如果样本集是线性可分的, 将属于 ω 2 \omega_2 ω2 的所有样本由 y \mathbf{y} y 变成 − y -\mathbf{y} −y, 对所有 n n n 样本, 将得到 a T y > 0 \mathbf{a}^T \mathbf{y}>\mathbf{0} aTy>0 。
- 经过上述处理之后, 在训练的过程中就不必考虑原来的样本类别。这一操作过程称为对样本的规范化(normalization) 处理。
- 规范化增广样本: 首先将所有样本写成齐次坐标形式,然后将属于 ω 2 \omega_2 ω2 的所有样本由 y \mathbf{y} y 变成 − y -\mathbf{y} −y
- 后面主要将集中于 “规范化增广样本”。“增广” 是指 “齐次坐标表示” 的含义, 即 y = ( x T , 1 ) T ∈ R d + 1 \mathbf{y}=\left(\mathbf{x}^T, 1\right)^T \in R^{d+1} y=(xT,1)T∈Rd+1 。
- 解区与解向量
- 在线性可分的情形下, 满足 a T y i > 0 , i = 1 , 2 , … , n \mathbf{a}^T \mathbf{y}_i>0, i=1,2, \ldots, n aTyi>0,i=1,2,…,n 的权向量 a \mathbf{a} a 称为解向量。
- 权向量 a \mathbf{a} a 可以理解为权空间中的一点, 每个样本 y i \mathbf{y}_i yi 对 a \mathbf{a} a 的位置均可能起到限制作用, 即要求 a T y i > 0 \mathbf{a}^T \mathbf{y}_i>0 aTyi>0 。
- 任何一个样本点 y i \mathbf{y}_i yi 均可以确定一个超平面 H i : a T y i = 0 H_i: \mathbf{a}^T \mathbf{y}_i=0 Hi:aTyi=0, 其法向量为 y i \mathbf{y}_i yi 。如果解向量 a ∗ \mathbf{a}^* a∗ 存在, 它必定在 H i H_i Hi 的正侧, 因为只有在正侧才能满足 ( a ∗ ) T y i > 0 \left(\mathbf{a}^*\right)^T \mathbf{y}_i>0 (a∗)Tyi>0 。
- 按上述方法, n n n 个样本将产生 n n n 个超平面。每个超平面将空间分成两个半空间。如果解向量存在, 它必定在所有这些正半空间的交集区域内。这个区域内的所有向量均是一个 可行的解向量 a ∗ \mathbf{a}^* a∗ 。

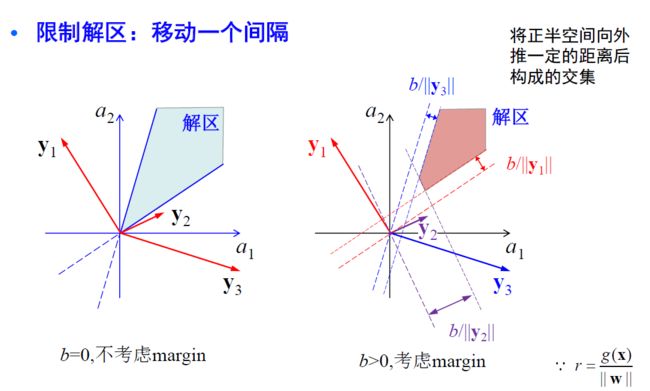
- 限制解区
- 可行的解向量不是唯一的, 有无穷多个。
- 经验: 越靠近区域中间的解向量, 越能对新的样本正确分类;可以引入一些条件来限制解空间
- 比如: 寻找一个单位长度的解向量 a \mathbf{a} a, 能最大化样本到分界面的最小距离
- 比如: 寻找一个最小长度的解向量 a \mathbf{a} a, 使 a T y i ≥ b > 0 \mathbf{a}^T \mathbf{y}_i \geq b>0 aTyi≥b>0 。此时可以将 b b b 称为间隔 (margin)。
- 感知准则函数
- 感知准则函数
任务: 设有一组样本 y 1 , y 2 , … , y n \mathbf{y}_1, \mathbf{y}_2, \ldots, \mathbf{y}_n y1,y2,…,yn, 各样本均规范化表示。我们的目的是要寻找一个解向量 a \mathbf{a} a , 使
a T y i > 0 , i = 1 , 2 , … , n \mathbf{a}^T \mathbf{y}_i>0, \quad i=1,2, \ldots, n aTyi>0,i=1,2,…,n
在线性可分情形下, 满足上述不等式的 a \mathbf{a} a 是无穷多的, 因此需要引入一个准则。 - Frank Rosenblatt 于50年代提出的感知学习机思想
考虑如下准则函数:
J p ( a ) = ∑ y ∈ Y ( − a T y ) , 其中, Y 为错分样本集合 J_p(\mathbf{a})=\sum_{\mathbf{y} \in Y}\left(-\mathbf{a}^T \mathbf{y}\right) \text {, 其中, } Y \text { 为错分样本集合 } Jp(a)=y∈Y∑(−aTy), 其中, Y 为错分样本集合 - 当 y \mathbf{y} y 被错分时, a T y ≤ 0 \mathbf{a}^T \mathbf{y} \leq 0 aTy≤0, 则 − a T y ≥ 0 -\mathbf{a}^T \mathbf{y} \geq 0 −aTy≥0 。因此 J p J_p Jp (a) 总是大于等于 0 。在可分情形下, 当且仅当 Y Y Y 为空集时 J p ( a ) J_p(\mathbf{a}) Jp(a) 将等于零, 这时将不存在错分样本。
- 因此, 目标是最小化 J p ( a ) : min a J p ( a ) J_p(\mathbf{a}): \min _{\mathbf{a}} J_p(\mathbf{a}) Jp(a):minaJp(a)
- 求导
∂ J p ( a ) ∂ a = − ∑ y ∈ Y y \frac{\partial J_p(\mathbf{a})}{\partial \mathbf{a}}=-\sum_{\mathbf{y} \in Y} \mathbf{y} ∂a∂Jp(a)=−y∈Y∑y - 根据梯度下降,有如下更新准则
a k + 1 = a k + η k ∑ y ∈ Y k y \mathbf{a}_{k+1}=\mathbf{a}_k+\eta_k \sum_{\mathbf{y} \in Y_k} \mathbf{y} ak+1=ak+ηky∈Yk∑y
这里, a k + 1 \mathbf{a}_{k+1} ak+1 是当前迭代的结果, a k \mathbf{a}_k ak 是前一次迭代的结果, Y k Y_k Yk 是被 a k \mathbf{a}_k ak 错分的样本集合, η k \eta_k ηk 为步长因子 (更新动力因子, 学习率)。 - 感知准则算法(Batch Perceptron)(伪代码)
begin initialize: a , η , certain θ (small value), k = 0 do k ← k + 1 a = a + η k ∑ y ∈ Y ( k ) y / / Y ( k ) = Y k until ∣ η k ∑ y ∣ < θ , y ∈ Y k / / 一个较松的停止条件 return a end \begin{aligned} & \text { begin initialize: } \mathbf{a}, \eta \text {, certain } \theta \text { (small value), } k=0 \\ & \qquad \begin{array}{ll} \text { do } k \leftarrow k+1 & \\ \qquad \mathbf{a}=\mathbf{a}+\eta_k \sum_{\mathbf{y} \in Y(k)} \mathbf{y} & / / Y(k)=Y_k \\ \text { until }\left|\eta_k \sum \mathbf{y}\right|<\theta, \quad \mathbf{y} \in Y_k & / / \text { 一个较松的停止条件 } \\ \text { return } \mathbf{a} \end{array} \\ & \text { end } \end{aligned} begin initialize: a,η, certain θ (small value), k=0 do k←k+1a=a+ηk∑y∈Y(k)y until ∣ηk∑y∣<θ,y∈Yk return a//Y(k)=Yk// 一个较松的停止条件 end
- 之所以称为 “batch perception” 是因为在迭代过程中同时考虑多个样本(每一步所有错分样本都参与更新)。计算复杂度低, 能以较快的速度收敛到极小值点
- 可变增量批处理修正方法(Batch Variable-Increment Perceptron)
begin initialize: a , η 0 , k = 0 do k ← k + 1 ( m o d n ) Y k = { } , j = 0 do j ← j + 1 if y j is misclassified, then append y j to Y k until j = n a = a + η k ∑ y ∈ Y ( k ) y //发现所有错分, 然后再修正 until Y k = { } /直到所有样本均正确分类 return a \begin{aligned} & \text { begin initialize: } \mathbf{a}, \eta_0, k=0 \\ & \qquad \begin{aligned} & \text { do } k \leftarrow k+1(\bmod n) \\ & \qquad Y_k=\{\}, j=0 \\ & \qquad \text { do } j \leftarrow j+1 \\ & \qquad \qquad \text { if } \mathbf{y}_j \text { is misclassified, then append } \mathbf{y}_j \text { to } Y_k \\ & \qquad \text { until } j=n \\ & \qquad \mathbf{a}=\mathbf{a}+\eta_k \sum_{\mathbf{y} \in Y(k)} \mathbf{y} \text { //发现所有错分, 然后再修正 } \\ & \text { until } Y_k=\{\} \text { /直到所有样本均正确分类 } \\ & \text { return } \mathbf{a}\\ \end{aligned} \end{aligned} begin initialize: a,η0,k=0 do k←k+1(modn)Yk={},j=0 do j←j+1 if yj is misclassified, then append yj to Yk until j=na=a+ηky∈Y(k)∑y //发现所有错分, 然后再修正 until Yk={} /直到所有样本均正确分类 return a - 区别就是每一次都要重新计算错分样本
- 由于所有被 a k \mathbf{a}_k ak 错分的样本必然位于以 a k \mathbf{a}_k ak 为法向量的超平面的负侧, 所以这些样本的和也必然在该侧
- a k + 1 \mathbf{a}_{k+1} ak+1 在更新的过程中, 会向错分类样本之和靠近, 因而朝着有利的方向移动(旋转)。一旦这些错分样本点穿过超平面, 就正确分类了。
- 对于线性可分的样本集, 算法可以在有限步内找到最优解。收敛速度取决于初始权向量和步长

-
固定增量单样本修正方法(Fixed-Increment Single-Sample Perceptron)
begin initialize: a , k = 0 do k ← k + 1 ( m o d n ) if y k is misclassified by a, then a = a + y k until all patterns properly classified return a end \begin{aligned} & \text { begin initialize: }\mathbf{a}, k=0 \\ & \qquad \text { do } k \leftarrow k+1(\bmod n) \\ & \qquad \qquad \text { if } \mathbf{y}^k \text { is misclassified by a, then } \mathbf{a}=\mathbf{a}+\mathbf{y}^k \\ & \qquad\text { until all patterns properly classified } \\ & \qquad\text { return } \mathbf{a} \\ & \text { end } \end{aligned} begin initialize: a,k=0 do k←k+1(modn) if yk is misclassified by a, then a=a+yk until all patterns properly classified return a end -
每次迭代只考虑一个错分样本 y k \mathbf{y}^k yk, 梯度下降法可以写成: a k + 1 = a k + η k y k \mathbf{a}_{k+1}=\mathbf{a}_k+\eta_k \mathbf{y}^k ak+1=ak+ηkyk 。考虑固定增量, 即令 η k = 1 \eta_k=1 ηk=1 :“固定增量” 并不改变分类决策, 相当于将样本作了一个 1 / η k 1 / \eta_k 1/ηk 的缩放。
-
算法解释:如果 a k \mathbf{a}_k ak 把 y k \mathbf{y}_k yk分错:
( a k ) T y k ≤ 0 \left(\mathrm{a}_k\right)^T \mathrm{y}^k \leq 0 (ak)Tyk≤0
a k + 1 = a k + y k \mathbf{a}_{k+1}=\mathbf{a}_k+\mathbf{y}^k ak+1=ak+yk
( a k + 1 ) T y k = ( a k ) T y k + ∥ y k ∥ ∣ 2 \left(\mathbf{a}_{k+1}\right)^T \mathbf{y}^k=\left(\mathbf{a}_k\right)^T \mathbf{y}^k+\left.\left\|\mathbf{y}^k\right\|\right|^2 (ak+1)Tyk=(ak)Tyk+ yk 2
( a k + 1 ) T y k \left(\mathbf{a}_{k+1}\right)^T \mathbf{y}^k (ak+1)Tyk 在原来的基础上增加了一个正数: ∥ y k ∥ 2 \left\|\mathbf{y}^k\right\|^2 yk 2。加着加着不就变正了吗,变正了不就正确分类了吗 -
可变增量单样本修正方法(Variable-Increment Perceptron with Margin)
a k + 1 = a k + η k y k \mathbf{a}_{k+1}=\mathbf{a}_k+\eta_k \mathbf{y}^k ak+1=ak+ηkyk
begin initialize: a, margin b , η 0 , k = 0 do k ← k + 1 ( m o d n ) if a T y k ≤ b , then a = a + η k y k until a T y k > b for all k return a end \begin{aligned} & \text { begin initialize: a, margin } b, \eta_0, k=0 \\ & \qquad \text { do } k \leftarrow k+1(\bmod n) \\ & \qquad \qquad \text { if } \mathbf{a}^T \mathbf{y}^k \leq \mathrm{b} \text {, then } \mathbf{a}=\mathbf{a}+\eta_k \mathbf{y}^k \\ & \qquad \text { until } \mathbf{a}^T \mathbf{y}^k>b \text { for all } k \\ & \qquad \text { return } \mathbf{a} \\ & \text { end } \end{aligned} begin initialize: a, margin b,η0,k=0 do k←k+1(modn) if aTyk≤b, then a=a+ηkyk until aTyk>b for all k return a end
- 感知准则函数的收敛性
- 在样本线性可分的情形下, 固定增量单样本权向量修正方法收敛, 并可得到一个可行解。
- 设 a \mathbf{a} a 是一个解向量, 只要证明 ∥ a k + 1 − a ∥ < ∥ a k − a ∥ \left\|\mathbf{a}_{k+1}-\mathbf{a}\right\|<\left\|\mathbf{a}_k-\mathbf{a}\right\| ∥ak+1−a∥<∥ak−a∥ 即可
【证明】设 a \mathbf{a} a 是一个解向量, 对于任意一个正的标量 α , α a \alpha, \alpha \mathbf{a} α,αa 也为一个可行解, 于是有:
a k + 1 − α a = ( a k − α a ) + y k ∥ a k + 1 − α a ∥ 2 = ∥ a k − α a ∥ 2 + 2 ( a k − α a ) T y k + ∥ y k ∥ 2 \begin{gathered} \mathbf{a}_{k+1}-\alpha \mathbf{a}=\left(\mathbf{a}_k-\alpha \mathbf{a}\right)+\mathbf{y}^k \\ \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2=\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2+2\left(\mathbf{a}_k-\alpha \mathbf{a}\right)^T \mathbf{y}^k+\left\|\mathbf{y}^k\right\|^2 \end{gathered} ak+1−αa=(ak−αa)+yk∥ak+1−αa∥2=∥ak−αa∥2+2(ak−αa)Tyk+ yk 2
由于 y k \mathbf{y}^k yk 被错分, 有 ( a k ) T y k ≤ 0 \left(\mathbf{a}_k\right)^T \mathbf{y}^k \leq 0 (ak)Tyk≤0 。但 a T y k > 0 \mathbf{a}^T \mathbf{y}^k>0 aTyk>0, 于是:
∥ a k + 1 − α a ∥ 2 ≤ ∥ a k − α a ∥ 2 − 2 α a T y k + ∥ y k ∥ 2 \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2 \leq\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2-2 \alpha \mathbf{a}^T \mathbf{y}^k+\left\|\mathbf{y}^k\right\|^2 ∥ak+1−αa∥2≤∥ak−αa∥2−2αaTyk+ yk 2
因此, 寻找一个合适的 α \alpha α, 满足 ∥ a k + 1 − α a ∥ 2 ≤ ∥ a k − α a ∥ 2 \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2 \leq\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2 ∥ak+1−αa∥2≤∥ak−αa∥2 即可
回忆一下, a < b + c a
β 2 = max i = 1 , … , n ∥ y i ∥ 2 , γ = min i a T y i \beta^2=\max _{i=1, \ldots, n}\left\|\mathbf{y}_i\right\|^2, \quad \gamma=\min _i \mathbf{a}^T \mathbf{y}_i β2=i=1,…,nmax∥yi∥2,γ=iminaTyi
∥ a k + 1 − α a ∥ 2 ≤ ∥ a k − α a ∥ 2 − 2 α γ + β 2 \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2 \leq\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2-2 \alpha \gamma+\beta^2 ∥ak+1−αa∥2≤∥ak−αa∥2−2αγ+β2
令 α = β 2 / γ \alpha=\beta^2 / \gamma α=β2/γ
∥ a k + 1 − α a ∥ 2 ≤ ∥ a k − α a ∥ 2 − β 2 ∥ a k + 1 − α a ∥ 2 < ∥ a k − α a ∥ 2 \begin{aligned} & \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2 \leq\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2-\beta^2 \\ & \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2<\left\|\mathbf{a}_k-\alpha \mathbf{a}\right\|^2 \end{aligned} ∥ak+1−αa∥2≤∥ak−αa∥2−β2∥ak+1−αa∥2<∥ak−αa∥2
因此, 每次迭代, 当前解离可行解越来越近。经过 k + 1 k+1 k+1 次迭代后:
∥ a k + 1 − α a ∥ 2 ≤ ∥ a 1 − α a ∥ 2 − k β 2 \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\|^2 \leq\left\|\mathbf{a}_1-\alpha \mathbf{a}\right\|^2-k \beta^2 ∥ak+1−αa∥2≤∥a1−αa∥2−kβ2
由于 ∥ a k + 1 − α a ∥ \left\|\mathbf{a}_{k+1}-\alpha \mathbf{a}\right\| ∥ak+1−αa∥ 总是非负的, 所以至多经过如下次更正即可:
k 0 = ∥ a 1 − α a ∥ 2 / β 2 k_0=\left\|\mathbf{a}_1-\alpha \mathbf{a}\right\|^2 / \beta^2 k0=∥a1−αa∥2/β2