sklearn中的逻辑回归
1 概述
1.1 名为“回归”的分类器
逻辑回归是一种名为“回归”的线性分类器,它的本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法。要理解逻辑回归从何而来,得先理解线性回归。线性回归是机器学习中最简单的回归算法,写作一个几乎人人熟悉的方程:
z = a 0 + a 1 x 1 + a 2 x 2 + . . . + a n x n z=a_0+a_1x_1+a_2x_2+...+a_nx_n z=a0+a1x1+a2x2+...+anxn
其中, a a a被统称为模型的参数,其中 a 0 a_0 a0被称为截距(intercept), a 1 a_1 a1~ a n a_n an被称为系数(coefficient)。使用矩阵来表示这个方程,其中 x x x和 a a a都可以被看做时一个列矩阵,则有:
z = ( a 0 a 1 a 2 . . . a n ) ∗ ( x 0 x 1 x 2 . . . x n ) = a T x ( x 0 = 1 ) z=\begin{pmatrix}a_0&a_1&a_2&...&a_n\end{pmatrix}*\begin{pmatrix}x_0\\x_1\\x_2\\...\\x_n\end{pmatrix}=\textbf{a}^T\textbf{x}(x_0=1) z=(a0a1a2...an)∗⎝⎜⎜⎜⎜⎛x0x1x2...xn⎠⎟⎟⎟⎟⎞=aTx(x0=1)
线性回归的任务,就是构造一个预测函数 z z z来映射输入的特征矩阵 x x x和标签值 y y y的线性关系,而构造预测函数的核心就是找出模型的参数: a T a^T aT和 a 0 a_0 a0,著名的最小二乘法就是用来求解线性回归中参数的数学方法。
通过函数 z z z,线性回归使用输入的特征矩阵 x x x来输出一组连续型的标签值y_pred,以完成各种预测连续型变量的任务(如预测产品销量,预测股价等)。如果标签是离散型变量,尤其是,如果是满足0-1分布的离散型变量,可以通过引入联系函数(link function),将线性回归方程 z z z变换为 g ( z ) g(z) g(z),并且令 g ( z ) g(z) g(z)的值分布在 ( 0 , 1 ) (0,1) (0,1)之间,且当 g ( z ) g(z) g(z)接近为0时样本的标签为类别0,当 g ( z ) g(z) g(z)接近为1时样本的标签为类别1,这样就得到一个分类模型,而这个联系函数对于逻辑回归来说,就是Sigmoid函数:
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
Sigmoid函数的公式和性质:Sigmoid函数是一个S型的函数,当自变量 z z z趋近正无穷时,因变量 g ( z ) g(z) g(z)趋近于1,而当 z z z趋近负无穷时, g ( z ) g(z) g(z)趋近于0,它能够将任何实数映射到 ( 0 , 1 ) (0,1) (0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。因为这个性质,Sigmoid函数也被当作是归一化的一种方法,与之前学过的MinMaxScaler同理,是属于数据预处理中的“缩放”功能,可以将数据压缩到 [ 0 , 1 ] [0,1] [0,1]之内。区别在于,MinMaxScaler归一化之后,是可以取到0和1的(最大值归一化后就是1,最小值归一化后就是0),但Sigmoid函数只是无限趋近于0和1。
线性回归中 z = a T x z=\textbf{a}^T\textbf{x} z=aTx,将 z z z带入,就得到了二元逻辑回归模型的一般形式:
g ( z ) = y ( x ) = 1 1 + e − a T x g(z)=y(x)=\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}} g(z)=y(x)=1+e−aTx1
而 g ( z ) g(z) g(z)就是逻辑回归返回的标签值。此时, y ( x ) y(x) y(x)的取值都在 [ 0 , 1 ] [0,1] [0,1]之间,因此 y ( x ) y(x) y(x)和 1 − y ( x ) 1-y(x) 1−y(x)相加必然为1。如果令 y ( x ) y(x) y(x)除以 1 − y ( x ) 1-y(x) 1−y(x)可以得到形似几率(odds)的 y ( x ) 1 − y ( x ) \frac{y(x)}{1-y(x)} 1−y(x)y(x),在此基础上取对数,可以很容易得到:
l n y ( x ) 1 − y ( x ) = l n ( 1 1 + e − a T x 1 − 1 1 + e − a T x ) = l n ( 1 1 + e − a T x e − a T x 1 + e − a T x ) = l n ( 1 e − a T x ) = l n ( e a T x ) = a T x ln\frac{y(x)}{1-y(x)}=ln(\frac{\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}}{1-\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}})=ln(\frac{\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}}{\frac{e^{-\textbf{a}^T\textbf{x}}}{1+e^{-\textbf{a}^T\textbf{x}}}})=ln(\frac{1}{e^{-\textbf{a}^T\textbf{x}}})=ln(e^{\textbf{a}^T\textbf{x}})=\textbf{a}^T\textbf{x} ln1−y(x)y(x)=ln(1−1+e−aTx11+e−aTx1)=ln(1+e−aTxe−aTx1+e−aTx1)=ln(e−aTx1)=ln(eaTx)=aTx
不难发现, y ( x ) y(x) y(x)的形似几率对数的本质其实就是线性回归 z z z,实际上是在对线性回归模型的预测结果取对数几率来让其结果无限逼近0和1。因此,其对应的模型被称为“对数几率回归”(logistic regression),也就是逻辑回归,这个名为“回归”的模型是用来做分类工作的分类器。
线性回归的核心任务是通过求解 a \textbf{a} a构建 z z z这个预测函数,并希望预测函数 z z z能够尽量拟合数据,因此逻辑回归的核心任务也是类似的:求解 a \textbf{a} a来构建一个能够尽量拟合数据的预测函数 y ( x ) y(x) y(x),并通过向预测函数中输入特征矩阵来获取相应的标签值 y y y。
思考: y ( x ) y(x) y(x)代表了样本为某一类标签的概率吗?: l n y ( x ) 1 − y ( x ) ln\frac{y(x)}{1-y(x)} ln1−y(x)y(x)是形似对数几率的一种变化。而几率odds的本质其实是 p 1 − p \frac{p}{1-p} 1−pp,其中 p p p是事件A发生的概率,而 1 − p 1-p 1−p是事件A不会发生的概率,并且 p + ( 1 − p ) = 1 p+(1-p)=1 p+(1−p)=1。因此,在理解逻辑回归时,认为 y ( x ) y(x) y(x)是某样本 i i i的标签被预测为1的概率,而 1 − y ( x ) 1-y(x) 1−y(x)是某样本 i i i的标签被预测为0的概率, y ( x ) 1 − y ( x ) \frac{y(x)}{1-y(x)} 1−y(x)y(x)是某样本 i i i的标签被预测为1的相对概率。基于这种理解,使用最大似然法和概率分布函数推导出逻辑回归的损失函数,并且把返回样本在标签取值上的概率当成是逻辑回归的性质来使用。但是这种理解是否正确无法确定。
1.2 为什么需要逻辑回归
线性回归对数据的要求很严格,但往往真实情境的数据无法满足这些要求,因此线性回归在很多现实情景的应用效果有限。逻辑回归是线性回归变换而来的,因此它对数据也有一定的要求,并且逻辑回归的与原理并不简单。而分类模型决策树和随机森林,它们的分类能力很强,并且不需要对数据做任何预处理。因此,在数据挖掘、人工智能所涉及到的医疗、教育、人脸识别、语音识别等领域,逻辑回归没有太多的出场机会。但是,无论机器学习领域如何,逻辑回归依然是一个受工业商业热爱,且使用广泛的模型,因为其有以下优点:
- 逻辑回归对线性关系的拟合效果很好,特征与标签之间的线性关系极强的数据,如金融领域中的信用卡欺诈、评分卡制作、电商中的营销预测等相关的数据,都是逻辑回归的强项。虽然现在有梯度提升数GDBT,比逻辑回归效果好,也被许多数据咨询公司使用,但逻辑回归在金融领域,尤其是银行业中的统治地位依然是不可动摇的。
- 逻辑回归计算快,对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,尤其在大型数据上。
- 逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字,可以把逻辑回归返回的结果当成连续型数据来利用,如在评分卡制作时,不仅需要判断客户是否会违约,还需要给出确定的“信用分”,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类器,可以产出分类结果,但无法计算分数(当然,在sklearn中,决策华也可以产生概率,使用接口predict_proba调用就好,但一般而言,正常的决策树无此功能)。
另外,逻辑回归还有抗噪能力强的优点,并且逻辑回归在小数据集上表现更好,在大型的数据集上,树模型有更好的模型。
逻辑回归是一个返回对数几率的,在线性数据上表现优异的分类器。主要被应用在金融领域。其数学目的是求解能够让模型对数据拟合程度更高的参数 a \textbf{a} a的值,以此构建预测函数 y ( x ) y(x) y(x),然后将特征矩阵输入预测函数来计算出逻辑回归的结果 y y y。虽然熟悉的逻辑回归通常被用于处理二分类问题,但逻辑回归也可以做多分类。
1.3 sklearn中的逻辑回归
逻辑回归相关的类:
linear_model.LogisticRegression:逻辑回归分类器(又叫logit,最大熵分类器)
linear_model.LogisticRegressionCV:带交叉验证的逻辑回归分类器
linear_model.logistic_regression_path:计算Logistic回归模型以获得正则化参数的列表
linear_model.SGDClasiifier:利用梯度下降求解的线性分类器(SVM,逻辑回归等)
linear_model.SGDRegressor:利用梯度下降最小化正则化后的损失函数的线性回归模型
metrics.log_loss:对数损失,又称逻辑损失或交叉熵损失
注:linear_model.RandomizedLogisticsRegression(随机的逻辑回归)在sklearn0.21版本中即将被移除
其他会涉及的类:
metrics.confusion_matrix:混淆矩阵,模型评估指标之一
metrics.roc_auc_score:ROC曲线,模型评估指标之一
metrics.accuracy_score:精确性,模型评估指标之一
2 linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression(penalty = ‘l2’, dual = False, tol = 0.001, C = 1.0, fit_intercept = True, intercept_scaling = 1, class_weight = None, random_state = None, solver = ‘warn’, max_iter = 100, multi_class = ‘warn’, verbose = 0, warm_start = False, n_jobs = None)
2.1 二元逻辑回归的损失函数
2.1.1 损失函数的概念与解惑
建模是追求模型在测试集上的表现最优,因此模型的评估指标往往是用来衡量模型在测试集上的表现的。然而,逻辑回归有着基于训练数据求解参数 a \textbf{a} a的需求,并且希望训练出来的模型能够尽可能地拟合训练数据,即模型在训练集上的预测准确率越靠近100%越好。
因此,使用“损失函数”这个评估指标,来衡量参数为 a \textbf{a} a的模型拟合训练集时产生的讯息损失的大小,并以此衡量参数 a \textbf{a} a的优劣。如果用一组参数建模后,模型在训练集上表现良好,可以认为模型拟合过程中的损失很小,损失函数的值很小,参数是优异的;相反,如果模型在训练集上表现糟糕,损失函数就会很大,模型就训练不足,效果较差,参数也就比较差。也就是说,在求解参数 a \textbf{a} a时,追求损失函数最小,让模型在训练数据上的拟合效果最优,即预测准确率尽量靠近100%。
损失函数:衡量参数 a a a优劣的评价指标,是用来求解最优参数的工具。损失函数小,模型在训练集上表现优异,拟合充分,参数优异;损失函数大,模型在训练集上表现差劲,拟合不足,参数糟糕。寻找能够让损失函数最小化的参数组合。
注:没有“求解参数”需求的模型没有损失函数,如KNN、决策树。
逻辑回归的损失函数是由极大似然估计推导出来的,具体推导如下:
J ( a ) = − ∑ i = 1 m ( y i ∗ l o g ( y a ( x i ) ) + ( 1 − y i ) ∗ l o g ( 1 − y a ( x i ) ) J(a)=-\sum_{i=1}^{m}(y_i*log(y_a(x_i))+(1-y_i)*log(1-y_a(x_i)) J(a)=−∑i=1m(yi∗log(ya(xi))+(1−yi)∗log(1−ya(xi))
其中, a a a表示求解出来的一组参数, m m m是样本的个数, y i y_i yi是样本 i i i上真实的标签, y a ( x i ) y_a(x_i) ya(xi)是样本 i i i上基于参数 a a a计算出来的逻辑回归返回值, x i x_i xi是样本 i i i各个特征的取值。目标是求解出使 J ( a ) J(a) J(a)最小的 a a a取值。注意,在逻辑回归的本质函数 y ( x ) y(x) y(x)里,特征矩阵 x x x是自变量,参数是 a a a。但在损失函数中,参数 a a a是损失函数的自变量, x x x和 y y y都是已知的特征矩阵和标签,相当于是损失函数的参数。不同的函数中,自变量和参数各有不同。
追求损失函数的最小值,让模型在训练集上表现最优,可能会引发:如果模型在训练集上表示优秀,却在测试集上表现糟糕,模型就会过拟合。虽然逻辑回归和线性回归是天生欠拟合的模型,但还是需要控制过拟合的技术来帮助调整模型,对逻辑回归中过拟合的控制,可以通过正则化来实现。
2.1.2 二元逻辑回归损失函数的数学解释、公式推导与解惑
2.2 重要参数penalty&C
2.2.1 正则化
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数量 a \textbf{a} a的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为“惩罚项”。损失函数于损失函数的最优化来求解的参数取值必然改变,以此来调节模型拟合的程度。其中L1范数的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开放值。
J ( a ) L 1 = C ∗ J ( a ) + ∑ j = 1 n ∣ a j ∣ ( j > = 1 ) J(a)_{L1}=C*J(a)+\sum_{j=1}^n|a_j|(j>=1) J(a)L1=C∗J(a)+∑j=1n∣aj∣(j>=1)
J ( a ) L 1 = C ∗ J ( a ) + ∑ j = 1 n ( a j ) 2 ( j > = 1 ) J(a)_{L1}=C*J(a)+\sqrt{\sum_{j=1}^n(a_j)^2}(j>=1) J(a)L1=C∗J(a)+∑j=1n(aj)2(j>=1)
其中 J ( a ) J(a) J(a)是损失函数, C C C是用来控制正则化程度的超参数, n n n是方程中特征的总数,也是方程中参数的总数, j j j代表每个参数,且 j j j要大于等于1,是因为参数向量 a \textbf{a} a中,第一个参数是 a 0 a_0 a0,是截距,它通常是不参与正则化的。
也可以写作/:
J ( a ) L 1 = J ( a ) + 1 2 b 2 ∑ j ∣ a j ∣ J(a)_{L1}=J(a)+\frac{1}{2b^2}\sum_j|a_j| J(a)L1=J(a)+2b21∑j∣aj∣
J ( a ) L 1 = J ( a ) + a T a 2 σ 2 J(a)_{L1}=J(a)+\frac{a^Ta}{2σ^2} J(a)L1=J(a)+2σ2aTa
在大多数情况下,常数项是乘以正则项,通过调控正则项来调节对模型的惩罚。在sklearn中,常数项 C C C是在损失函数前面的,通过调控损失函数本身的大小来调节对模型的惩罚。
- penalty:可以输入“l1”或“l2”来指定使用哪一种正则化方式,不填写默认“l2”。注意:若选择“l1”正则化,参数solver仅能够使用求解方式“liblinear”和“saga”,若使用“l2”正则化,参数solver中所有的求解方式都可以使用。
- C: C C C正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。 C C C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数 a a a会逐渐被压缩得越来越小。
L1正则化和L2正则化虽然都可以控制过拟合,但是效果并不相同。当正则化强度逐渐增大(即 C C C逐渐变小),参数 a a a的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
在L1正则化逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。L1正则化越强,参数向量中就越多参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。因此,如果特征量很大、数据维度很高,会倾向于使用L1正则化。由于L1正则化的这个性质,逻辑回归的特征选择可以由Embedded嵌入法来完成。相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0。通常来说,主要目的是为了防止过拟合,选择L2正则化足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。两种正则化下 C C C的取值,都可以通过学习曲线来进行调整。
通过两个逻辑回归,来观察L1正则化和L2正则化的差别:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
x = data.data
y = data.target
data.data.shape
#结果:(569, 30)
lrl1 = LR(penalty = 'l1',solver = 'liblinear',C = 0.5,max_iter = 1000)
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = 0.5,max_iter = 1000)
#逻辑回归的重要属性coef_,查看每个特征所对应的参数
lrl1 = lrl1.fit(x,y)
lrl1.coef_
#结果:array([[ 4.00032682, 0.03166875, -0.1370455 , -0.01621622, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.50461921, 0. , -0.07127911, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , -0.24565067, -0.12856333, -0.01441737, 0. ,
0. , -2.04220443, 0. , 0. , 0. ]])
(lrl1.coef_ != 0).sum(axis = 1)
#结果:array([10])
lrl2 = lrl2.fit(x,y)
lrl2.coef_
#结果:array([[ 1.61541411e+00, 1.02300859e-01, 4.79634999e-02,
-4.45030890e-03, -9.43136469e-02, -3.01439405e-01,
-4.56192113e-01, -2.22484448e-01, -1.35800316e-01,
-1.93953254e-02, 1.60057189e-02, 8.84862500e-01,
1.19637597e-01, -9.46955296e-02, -9.82838672e-03,
-2.36327058e-02, -5.71011111e-02, -2.70319142e-02,
-2.77745541e-02, 2.15950986e-04, 1.26261246e+00,
-3.01767368e-01, -1.72676431e-01, -2.21705021e-02,
-1.73511093e-01, -8.79035647e-01, -1.16340871e+00,
-4.27935079e-01, -4.21045045e-01, -8.69853368e-02]])
当选择L1正则化时,许多特征的参数都被设置为0,这些特征在真正建模时,都不会出现在模型中,而L2正则化是对所有特征都给出了参数。
l1 = []
l2 = []
l1test = []
l2test = []
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
for i in np.linspace(0.05,1,19):
lrl1 = LR(penalty = 'l1',solver = 'liblinear',C = i,max_iter = 1000)
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = i,max_iter = 1000)
lrl1 = lrl1.fit(xtrain,ytrain)
l1.append(accuracy_score(lrl1.predict(xtrain),ytrain))
l1test.append(accuracy_score(lrl1.predict(xtest),ytest))
lrl2 = lrl2.fit(xtrain,ytrain)
l2.append(accuracy_score(lrl2.predict(xtrain),ytrain))
l2test.append(accuracy_score(lrl2.predict(xtest),ytest))
graph = [l1,l2,l1test,l2test]
color = ['green','black','lightgreen','gray']
label = ['L1','L2','L1test','L2test']
plt.figure(figsize = [6,6])
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label = label[i])
plt.legend(loc = 4)#图例的位置,4表示右下角
plt.show()
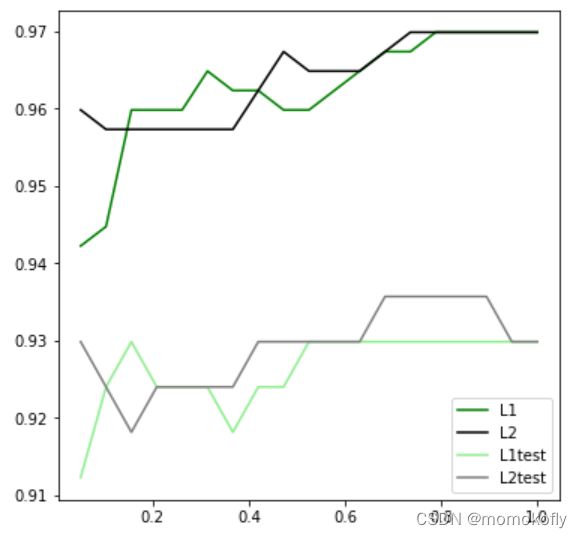
在乳腺癌数据集上,两种正则化的结果区别不大,但随着 C C C的逐渐变大,正则化的强度越来越小,模型在训练集和测试集上的表现都呈上升趋势,直到 C = 0.8 C=0.8 C=0.8左右,训练集上的表现依然在走高,但模型在未知数据集上的表现开始下跌,这时出现了过拟合。可以认为, C C C设定为0.9会比较好。在实际使用时,基本就默认使用l2正则化,如果感觉到模型的效果不好,那就换l1试试。
2.2.2 逻辑回归中的特征工程
当特征的数量很多的时候,出于业务考虑,也出于计算量的考虑,通过对逻辑回归进行特征选择选择来降维。
- 业务选择
降维和特征选择,首先是利用业务能力进行选择,明显和标签有关的特征是要留下的。当然,如果不了解业务,或者有成千上万的特征,那也可以使用算法来筛选过一遍特征,然后在少量的特征中,再根据业务常识来选择更少量的特征。 - PCA和SVD一般不用
说到降维,首先想到的是高效降维算法,PCA和SVD,但这两种方法大多数时候不适用于逻辑回归。逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征x与标签y之间的关系,而逻辑回归也继承了这个性质,想要通过逻辑回归的结果来判断哪些特征与分类结果相关,因此需要保留特征的原貌。而PCA和SVD的降维结果是不可解释的,因此一旦降维,就无法解释特征和标签之间的关系。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。 - 统计方法可以使用,但不是非常必要
既然降维算法不能使用,就要用特征选择方法。逻辑回归对数据的要求低于线性回归,由于不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果确实需要使用一些统计方法,如方差、卡方、互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。
对于线性回归来说,多重共线性会影响比较大,所以需要使用方差过滤和方差膨胀因子VIF(variance inflation factor)来消除共线性。但对逻辑回归而言,其实不是非常必要,甚至有时需要多一些互相关联的特征来增强模型的表现。当然,如果无法通过其他方式提升模型表现,并且模型中的共线性影响了模型效果,那可以试试用VIF方法消除共线性,但在sklearn中并没有提供VIF功能。 - 高效的嵌入法embedded
由于L1正则化会使得部分特征对应的参数为0,因此L1正则化可以用来做特征选择,结合嵌入法的模块SelectFromModel,可以很容易就筛选出让模型十分高效的特征。注意,目的是尽量保留原数据上的信息,让模型在降维后的数据上的拟合效果保持优秀,因此不考虑训练集测试集的问题,把所有数据都放入模型进行降维。
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectFromModel
data = load_breast_cancer()
data.data.shape
#结果:(569, 30)
LR_ = LR(solver = 'liblinear',C = 0.9,random_state = 420)
cross_val_score(LR_,data.data,data.target,cv = 10).mean()
#结果:0.9490601503759398
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
#norm_order = 1表示使用L1范式
x_embedded.shape
#结果:(569, 9)
cross_val_score(LR_,x_embedded,data.target,cv = 10).mean()
#结果:0.9368107769423559
虽然特征数量被减少到个位数,但模型的效果并没有下降太多,因此,如果要求不高,这一方法是可以的。但是否具有让模型的拟合效果更好的调整方法呢?
1)第一种调节方法:调节SelectFromModel类中的参数threshold,这是嵌入法的阈值,表示删除所有参数的绝对值低于这个阈值的特征。threshold默认为None,所以SelectFromModel只根据L1正则化的结果来选择特征,即选择了所有L1正则化后参数不为0的特征。只要调整threshold的值(画出threshold的学习曲线),就可以观察出不同的threshold下模型的效果如何变化。
fullx = []
fsx = []
threshold = np.linspace(0,(LR_.fit(data.data,data.target).coef_).max(),20)
k = 0
for i in threshold:
x_embedded = SelectFromModel(LR_,threshold = i,norm_order = 1).fit_transform(data.data,data.target)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 5).mean())
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 5).mean())
print((threshold[k],x_embedded.shape[1]))
k += 1
plt.figure(figsize=[20,5])
plt.plot(threshold,fullx,label = 'full')
plt.plot(threshold,fsx,label = 'feature selection')
plt.xticks(threshold)
plt.legend()
plt.show()
#结果:
(0.0, 30)
(0.10649103899794485, 17)
(0.2129820779958897, 12)
(0.3194731169938345, 11)
(0.4259641559917794, 8)
(0.5324551949897243, 8)
(0.638946233987669, 6)
(0.7454372729856139, 5)
(0.8519283119835588, 5)
(0.9584193509815037, 5)
(1.0649103899794485, 5)
(1.1714014289773933, 4)
(1.277892467975338, 2)
(1.384383506973283, 2)
(1.4908745459712278, 2)
(1.5973655849691728, 1)
(1.7038566239671176, 1)
(1.8103476629650623, 1)
(1.9168387019630073, 1)
(2.023329740960952, 1)

然而这种方法在该数据集上是无效的。因为当threshold越来越大,被删除的特征越来越多,模型的效果越来越差,模型最好的情况下需要保证有17个以上的特征,而细化的学习曲线显示,如果要保证模型的效果比降维前更好,需要保留25个特征,这对于实际情况而言,是一种无效的降维:降维前后的特征数量区别不大,并不能通过降维带来很好的特征数量的降低。
2)第二种调节方法:调整逻辑回归的类LR_,通过画C的学习曲线来实现:
fullx = []
fsx = []
C = np.arange(0.01,10.01,0.5)
for i in C:
LR_ = LR(solver = 'liblinear',C = i,random_state = 420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 10).mean())
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 10).mean())
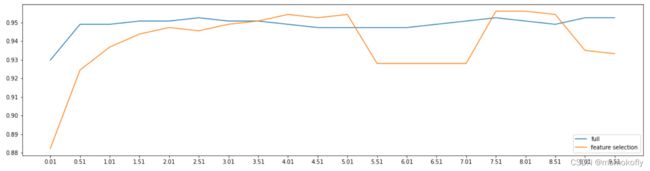
print(max(fsx),C[fsx.index(max(fsx))])
#结果:0.9561090225563911 7.51
plt.figure(figsize = [20,5])
plt.plot(C,fullx,label = 'full')
plt.plot(C,fsx,label = 'feature selection')
plt.xticks(C)
plt.legend()
plt.show()
fullx = []
fsx = []
C = np.arange(7.01,8.01,0.005)
for i in C:
LR_ = LR(solver = 'liblinear',C = i,random_state = 420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 10).mean())
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 10).mean())
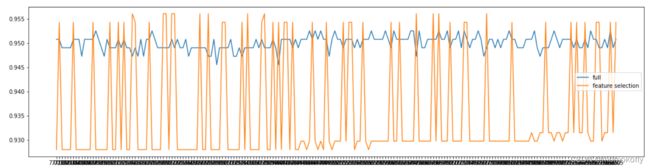
print(max(fsx),C[fsx.index(max(fsx))])
#结果:0.9561090225563911 7.144999999999997
plt.figure(figsize = [20,5])
plt.plot(C,fullx,label = 'full')
plt.plot(C,fsx,label = 'feature selection')
plt.xticks(C)
plt.legend()
plt.show()
LR_ = LR(solver = 'liblinear',C = 7.144999999999997,random_state = 420)
cross_val_score(LR_,data.data,data.target,cv = 10).mean()
#结果:0.9473057644110275
LR_ = LR(solver = 'liblinear',C = 7.144999999999997,random_state = 420)
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
cross_val_score(LR_,x_embedded,data.target,cv = 10).mean()
#结果:0.9561090225563911
x_embedded.shape
#结果:(569, 9)
此时就实现了在特征选择的前提下,保持模型拟合的高效。当然,除了嵌入法之外,系数累加法或者包装法也可以使用。
- 比较麻烦的系数累加法
系数累加法的原理非常简单,coef_虽然返回的是特征的系数,但是系数的大小和决策树中的feature_importances_以及降维算法中的可解释性方差explained_variance_概念相似,都是衡量特征的重要程度和贡献度的。在PCA中,通过绘制累积可解释性方差贡献率曲线来选择超参数,在逻辑回归中其实也可以,并且逻辑回归也是类似的:找出曲线由锐利变平滑的转折点,转折点之前被累加的特征都是需要的,转折之后的不需要。不过这种方法相对比较麻烦,因为要先对特征系数进行从大到小的排序,还要确保知道排序后的每个系数对应的原始特征的位置,才能正确找出重要的特征。如果使用这样的方法,不如直接使用嵌入法来得方便。 - 简单快速的包装法
相对的,包装法可以直接设定需要的特征个数,逻辑回归在现实中运用时,可能会有“需要5-8个变量”这种需求,包装法此时就比较方便了。不过逻辑回归的包装法的使用和其他算法一样,并不具有特别之处。
2.3 梯度下降:重要参数max_iter
逻辑回归的数学目的是求解能够让模型最优化,拟合程度最好的参数 a a a的值,即求解能够让损失函数 J ( a ) J(a) J(a)最小化的 a a a值。对于二元逻辑回归来说,有多种方法可以用来求解参数 a a a,最常见的有梯度下降法(Gradient Descent)、坐标下降法(Coordinate Descent)、牛顿法(Newton-Raphson method)等,其中以梯度下降法最为著名,每种方法背后都涉及复杂的数学原理,但这些计算在执行的任务是类似的。
2.3.1 梯度下降求解逻辑回归
以最著名也最常用的梯度下降法为例。
**在sklearn中逻辑回归参数max_iter,代表着梯度下降能走的最大步数,即最大迭代次数。**所以,梯度下降其实就是在众多参数的可能取值中遍历,一次次求解坐标点的梯度向量,不断让损失函数的取值 J J J逐渐逼近最小值,再返回这个最小值对应的参数取值的过程。
2.3.2 梯度下降的概念与解惑
理解梯度下降法是在损失函数上对损失函数自身的自变量(逻辑回归预测函数的参数)求偏导。
在逻辑回归中,损失函数为:
J ( a ) = − ∑ i = 1 m ( y i ∗ l o g ( y a ( x i ) ) + ( 1 − y i ) ∗ l o g ( 1 − y a ( x i ) ) J(a)=-\sum_{i=1}^{m}(y_i*log(y_a(x_i))+(1-y_i)*log(1-y_a(x_i)) J(a)=−∑i=1m(yi∗log(ya(xi))+(1−yi)∗log(1−ya(xi))
对这个函数上的自变量 a \textbf{a} a求偏导,就可以得到梯度向量在第 j j j组 a a a的坐标点上的表示形式:
d j = ∑ i = 1 m ( y a ( x i ) − y i ) x i j d_j=\sum_{i=1}^m(y_a(x_i)-y_i)x_{ij} dj=∑i=1m(ya(xi)−yi)xij
在这个公式下,只要给定一组 a \textbf{a} a的取值 a j \textbf{a}_j aj,再带入特征矩阵 x x x,就可以求得这一组 a \textbf{a} a取值下的预测结果 y a ( x i ) y_a(x_i) ya(xi),结合真实标签向量 y y y,就可以获得这一组 a j \textbf{a}_j aj取值下的梯度向量,其大小表示为 d j d_j dj。目的是要在可能的 a \textbf{a} a取值上进行遍历,一次次计算梯度向量,并在梯度向量的方向上让损失函数 J J J下降至最小值。在这个过程中, a \textbf{a} a和梯度向量的大小 d d d都会不断改变,而遍历 a \textbf{a} a的过程可以描述为:
a j + 1 = a j − α ∗ d j = a j − α ∗ ∑ i = 1 m ( y a ( x i ) − y i ) x i j a_{j+1}=a_j-\alpha*d_j=a_j-\alpha*\sum_{i=1}^m(y_a(x_i)-y_i)x_{ij} aj+1=aj−α∗dj=aj−α∗∑i=1m(ya(xi)−yi)xij
其中 a j + 1 \textbf{a}_{j+1} aj+1是第 j j j次迭代后的参数向量, a j \textbf{a}_j aj是第 j j j次迭代的参数向量, α \alpha α被称为步长,控制着每走一步(每迭代一次)后 a a a的变化,并以此来影响每次迭代后的梯度向量的大小和方向。
2.3.3 步长的概念与解惑
步长不是任何物理距离,它甚至不是梯度下降过程中任何距离的直接变化,它是梯度向量的大小 d d d上的比例,影响着参数向量 a a a每次迭代后改变的部分。
既然参数迭代是靠梯度向量的大小 d d d*步长 α \alpha α来实现的,而 J ( a ) J(a) J(a)的降低又是靠调节 a \textbf{a} a来实现的,所以步长可以调节损失函数下降的速率。在损失函数降低的方向上,步长越长, a \textbf{a} a的变动就越大。相对的,步长如果很短, a \textbf{a} a的每次变动就很短。具体地说,如果步长太长,损失函数下降得就非常快,需要的迭代次数就很少,但梯度下降过程可能跳过损失函数的最低点,无法获取最优值。而步长太小,虽然函数会逐渐逼近需要的最低点,但迭代的速度却很缓慢,迭代次数就需要很多。
在sklearn中,设置参数max_iter最大迭代次数来代替步长,以控制模型的迭代速度并适时地让模型停下,max_iter越大,代表步长越小,模型迭代时间越长,反之,则代表步长设置很大,模型迭代时间很短。
迭代结束,获取到 J ( a ) J(a) J(a)的最小值后,就可以找出最小值对应的参数向量 a \textbf{a} a,逻辑回归的预测函数也就可以根据这个参数向量 a \textbf{a} a来建立。
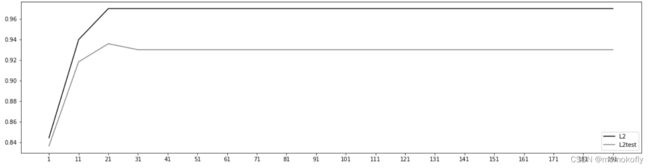
如在乳腺癌数据集下,max_iter的学习曲线为:
l2 = []
l2test = []
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
for i in np.arange(1,201,10):
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = i)
lrl2 = lrl2.fit(xtrain,ytrain)
l2.append(accuracy_score(lrl2.predict(xtrain),ytrain))
l2test.append(accuracy_score(lrl2.predict(xtest),ytest))
graph = [l2,l2test]
color = ['black','gray']
label = ['L2','L2test']
plt.figure(figsize = [20,5])
for i in range(len(graph)):
plt.plot(np.arange(1,201,10),graph[i],color[i],label = label[i])
plt.legend(loc = 4)
plt.xticks(np.arange(1,201,10))
plt.show()
#可以使用属性.n_iter_来调用本次求解中真正实现的迭代次数
lr = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = 300).fit(xtrain,ytrain)
lr.n_iter_
#结果:array([24], dtype=int32)
当max_iter中限制的步数已经走完,逻辑回归却还没有找到损失函数的最小值,参数 a a a的值还没有被收敛,sklearn就会弹出红色的警告:
lr = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = 10).fit(xtrain,ytrain)
lr.n_iter_
当参数solver = ‘liblinear’:

当参数solver = ‘sag’:

虽然写法不同,但其实都是一个含义:参数没有收敛,需要增大max_iter中输入的数字。但也不一定要完全避免出现红色警告。max_iter很大,意味着步长短,模型运行得会更加缓慢。虽然在梯度下降中追求的是损失函数最小值,但这也可能意味着模型会过拟合(在训练集上表现得太好,在测试集上却不一定),因此,如果max_iter报红条的情况下,模型的训练和预测效果都已经不错了,那就不需要再增大max_iter中的数目了。
2.4 二元回归与多元回归:重要参数solver&multi_class
sklearn提供了多种可以使用逻辑回归处理多分类问题的选项。比如,可以把某种分类类型都看作1,其余的分类类型都看作0,和“数据预处理”中的二值化的思维类似,这种方法被称为“一对多”(One-vs-rest),简称OvR。在sklearn中表示为‘ovr’;或者把好几个分类类型划为1,剩下的几个分类类型划为0,这是一种“多对多”(Many-vs-Many)的方法,简称MvM,在sklearn中表示为“multinominal”。每种方式都配合L1或L2正则项来使用。
在sklearn中,使用参数multi-class来告诉模型,预测标签是何种类型。输入“ovr”、“multinominal”、“auto”来表示不同类型,默认为“ovr”(默认值在sklearn的0.22版本中从“ovr”更改为“auto”)。“ovr”表示分类问题是二分类,或让模型使用“一对多”的形式来处理分类问题;“multinominal”表示处理多分类问题,这种输入在参数solver是“liblinear”时不可用;“auto”表示会根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型。
梯度下降法只是求解逻辑回归参数 a a a的一种方法,sklearn提供了多种选择,可以使用不同的求解器来计算逻辑回归。求解器的选择,由参数“solver”控制,共有五种选择。其中“liblinear”是二分类专用,也是现在的默认求解器。(表格中灰色单元格表示缺点)
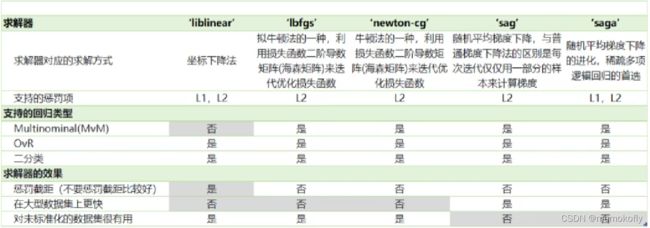
以鸢尾花数据集为例,观察multinominal和ovr的区别:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
for multi_class in ("multinomial","ovr"):
lr = LogisticRegression(solver = 'sag',max_iter = 100,random_state = 42,multi_class = multi_class).fit(iris.data,iris.target)
#打印两种multi_class模式下的训练分数
#%的用法,用%来代替打印的字符串中,想由变量替换的部分。%.3f表示,保留三个小数的浮点数。%s表示,字符串。
#字符串后的%后使用元组来容纳变量,字符串中有几个%,元组中就需要有几个变量。
print("training score : %.3f (%s) " % (lr.score(iris.data,iris.target),multi_class))
#结果:training score : 0.987 (multinomial)
# training score : 0.960 (ovr)
2.5 样本不平衡与参数class_weight
样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例,或误分类的代价很高。如要对潜在犯罪者和普通人进行分类,以及银行要判断一个新客户是否会违约。因此需要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向于少数类,向捕获少数类的方向建模。该参数默认为None,此模式表示自动给于数据集中的所有标签相同的权重,即自动1:1。当误分类的代价很高的时候,使用“balance”模式,只是希望对标签进行均衡的时候,什么都不填就可以解决样本不均衡问题。
但是对于sklearn当中的参数class_weight,很难找出这个参数引导的模型趋势,或者画出学习曲线来评估参数的效果,因此非常难使用。有处理样本不均衡的各种方法,其中主流的是采样法,是通过重复样本的方式来平衡标签,可以进行上采样(增加少数类的样本),如SMOTE,或者下采样(减少多数类的样本)。对于逻辑回归来说,上采样是最好的方法。
3 案例:用逻辑回归制作评分卡
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行)可能造成经济损失的可能性。一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
“向别人借钱的人”可能是个人,可能是有需求的公司和企业。对于企业而言,按照融资主体的融资用途分别使用企业融资模型、现金流融资模型、项目融资模型等模型。对于个人来说,有“四张卡”来判断个人的信用程度:A卡、B卡、C卡和F卡。常说的“评分卡”就是指A卡,又称为申请者评级模型,主要是用于评估新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,可以拒绝贷款。
一个完整的模型开发,需要以下的流程:
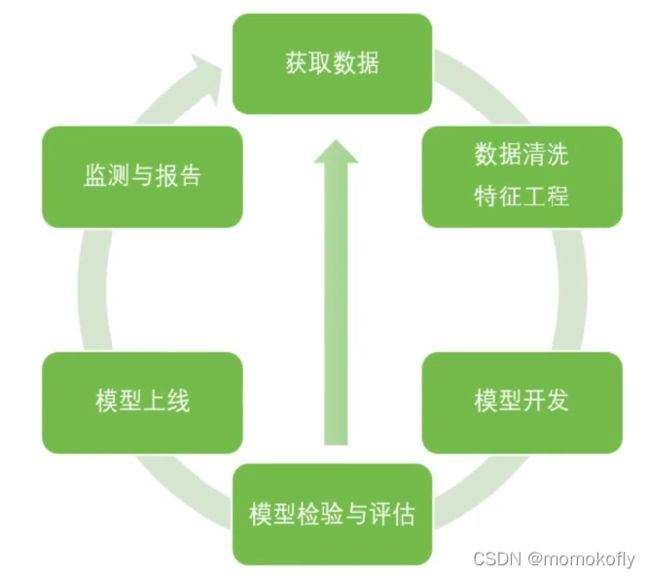
以个人消费类贷款数据为例,介绍A卡的建模和制作流程。核心主要介绍“数据清洗”和“模型开发”。
3.1 导库,获取数据
使用的数据集是kaggle中的give me some credit数据集
%matplotlib inline
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
data = pd.read_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\Give_me_some_credit_Data_cs-training.csv",index_col = 0)
需要了解每个指标项代表何种含义,通常,当特征非常多的时候,一个个去了解要花很多时间,所以如果特征很多,建议先做降维。
3.2 探索数据与数据预处理
这一步要了解样本总体的大概情况,如查看缺失值、量纲是否统一、是否适合做哑变量等等。其实数据的探索和数据预处理并不是完全分开的,不一定要先做哪个。
#观察数据类型
data.head()
#观察数据结构
data.shape
#结果:(150000, 11)
data.info()


3.2.1 去除重复值
现实数据,尤其是银行业数据,可能会存在的一个问题就是样本重复,即有超过一行的样本所显示的所有特征都一样。有时可能是系统录入重复,有时可能是人为输入重复,总之必须对数据进行去重处理。虽然有可能出现两个样本的特征一模一样,但这种可能性微乎其微,尤其是银行业数据经常是几百个特征,即便真的出现了极端的情况,也可能当做是少量信息损失,将记录当作重复值除去。
#去除重复值
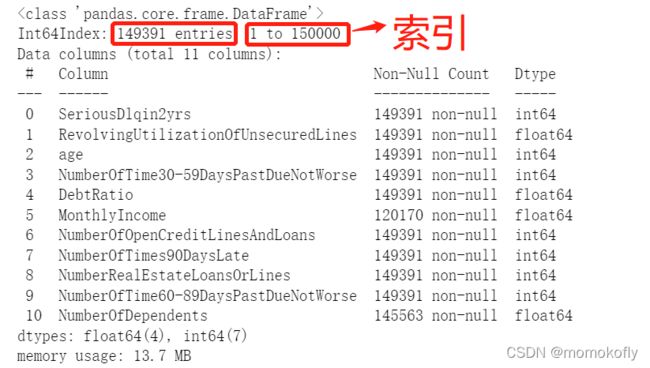
data.drop_duplicates(inplace = True)
data.info()
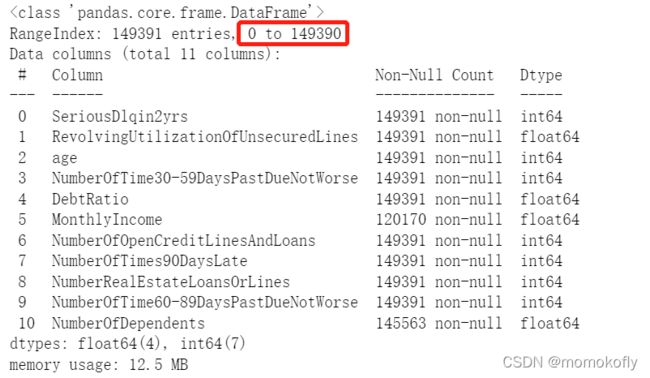
#删除之后,需要恢复索引
data.index = range(data.shape[0])
data.info()
3.2.2 填补缺失值
#探索缺失值
data.info()
data.isnull().sum()/data.shape[0]
#data.insull().mean()
#结果:
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 0.000000
age 0.000000
NumberOfTime30-59DaysPastDueNotWorse 0.000000
DebtRatio 0.000000
MonthlyIncome 0.195601
NumberOfOpenCreditLinesAndLoans 0.000000
NumberOfTimes90DaysLate 0.000000
NumberRealEstateLoansOrLines 0.000000
NumberOfTime60-89DaysPastDueNotWorse 0.000000
NumberOfDependents 0.025624
dtype: float64
存在缺失值的特征是“MonthlyIncome”和“NumberOfDependents”。“NumberOfDependents”缺失数量很少,仅缺失了大约2.56%,可以考虑直接删除,或者使用均值来填补。“MonthlyIncome”缺失了几乎20%,并且这一特征也是影响信用评分的重要因素,因此,这个特征必须要进行填补。首先使用均值来填补“NumberOfDependents”。
data["NumberOfDependents"].fillna(data["NumberOfDependents"].mean(),inplace = True)
#如果选择删除缺失值所在的行,记得恢复索引
data.info()
#结果:
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 0.000000
age 0.000000
NumberOfTime30-59DaysPastDueNotWorse 0.000000
DebtRatio 0.000000
MonthlyIncome 0.195601
NumberOfOpenCreditLinesAndLoans 0.000000
NumberOfTimes90DaysLate 0.000000
NumberRealEstateLoansOrLines 0.000000
NumberOfTime60-89DaysPastDueNotWorse 0.000000
NumberOfDependents 0.000000
dtype: float64
对于银行数据来说,有这样的推断:一个借钱的人应该是会知道,“高收入”或者“稳定收入”于自己而言会是申请贷款过程中的一个助力,因此收入稳定良好的人,肯定会倾向于写上自己的收入情况,那么这些“MonthlyIncome”特征值缺失的人,更可能是收入状态不稳定或收入比较低的人。基于这种判断,可以用四分位数来填补缺失值,把所有“MonthlyIncome”字段值为空的客户都当成是低收入人群。当然,这些确实也可能是银行数据收集过程中的失误,并无法判断为什么该特征会缺失,所以以上的推断也可能是不正确的。具体采用什么手段填补缺失值,要和业务人员沟通,观察缺失值是如何产生的。这里使用随机森林填补“MonthlyIncome”。
随机森林利用“既然可以用A、B、C预测Z,也可以使用A、C、Z预测B”的思想来填补缺失值。对于一个有n个特征的数据来说,其中特征T有缺失值,就把特征T当作标签,其他的n-1个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是Y_train,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是需要预测的部分。
特征T不缺失的值对应的其他n-1个特征+本来的标签:X_train
特征T不缺失的值:Y_train
特征T缺失的值对应的其他n-1个特征+本来的标签:X_test
特征T缺失的值:未知,是需要预测的Y_predict
这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用。接下来写一个能够填补任何列的函数,但一次只能填补一列:
def fill_missing_rf(x,y,to_fill):
"""
使用随机森林填补一个特征的缺失值的函数
参数:
x:要填补的特征矩阵
y:完整的、没有缺失值的标签
to_fill:字符串,要填补的那一列的名称
"""
#构建新特征矩阵和新标签
df = x.copy()
fill = df.loc[:,to_fill]
df = pd.concat([df.loc[:,df.columns != to_fill],pd.DataFrame(y)],axis = 1)
#找出训练集和测试集
ytrain = fill[fill.notnull()]
ytest = fill[fill.isnull()]
xtrain = df.iloc[ytrain.index,:]
xtest = df.iloc[ytest.index,:]
#用随机森林回归来填补缺失值
from sklearn.ensemble import RandomForestRegressor as rfr
rfr = rfr(n_estimators = 100)
rfr = rfr.fit(xtrain,ytrain)
ypredict = rfr.predict(xtest)
return ypredict
将该数据集对应的参数代入函数中
x = data.iloc[:,1:]
y = data["SeriousDlqin2yrs"]
#y = data[:,0]
x.shape
#结果:(149391, 10)
y_pred = fill_missing_rf(x,y,"MonthlyIncome")
y_pred
#结果:array([0.13, 0.38, 0.13, ..., 0.22, 0.13, 0. ])
#确认结果合理之后,可以将数据覆盖
data.loc[data.loc[:,"MonthlyIncome"].isnull(),"MonthlyIncome"] = y_pred
data.info()

3.2.3 描述性统计处理异常值
现实数据永远都会有一些异常值,首先要去捕捉出来,然后观察其性质。注意:异常值很多时候却是重点研究对象。日常处理异常值,使用箱线图或者KaTeX parse error: Undefined control sequence: \lsigma at position 2: 3\̲l̲s̲i̲g̲m̲a̲法则来找到异常值(不要依赖于眼睛看,除了业务理解,还要注重方法)。但在银行数据中,希望排除的“异常值”不是一些超高或者超低的数据,而是一些不符合常理的数据,如收入不能为负数,但是一个超高水平的收入却是合理的,可以存在。因此在银行业中,往往就使用普通的描述性统计来观察数据的异常与否与数据的分布情况。注意,这种方法只能在特征数量有限的情况下进行,如果有几百个特征又无法成功降维或者特征选择无效,还是用 3 σ 3\sigma 3σ比较好。
#描述性统计
data.describe([0.01,0.1,0.25,0.5,0.75,0.9,0.99]).T
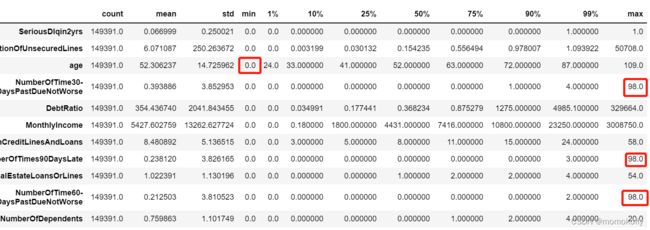
#异常值被观察到,年龄的最小值居然有0,这显然不符合银行的业务需求,即便是儿童账户也要至少8岁,因此可以查看年龄为0的人有多少
(data["age"] == 0).sum()
#结果:1
#发现只有一个人年龄为0,可以判断这肯定是录入失误造成的,可以当成缺失值处理,直接删除这个样本
data = data[data["age"] != 0]
"""
另外,有三个指标看起来很奇怪:
"NumberOfTime30-59DaysPastDueNotWorse"
"NumberOfTime60-89DaysPastDueNotWorse"
"NumberOfTimes90DaysLate"
这三个指标分别是“过去两年内出现35-59天逾期但是没有发展的更坏的次数”,“过去两年内出现60-89天逾期但是没有发展的更坏的次数”,“过去两年内出现90天逾期的次数”。这三个指标,在99%的分布的时候依然是2,最大值却是98,看起来非常奇怪。一个人在过去两年内逾期35-59天98次,一年6个60天,两年内逾期98次理论上无法实现
可以咨询业务人员,这个逾期次数是如何计算的。如果这个指标是正常的,那么两年内逾期了98次的客户都是坏客户。而在无法询问他们的情况下,先查看一下有多少样本存在这种异常。
"""
#data[data.loc[:,"NumberOfTimes90DaysLate"] > 90]
data[data.loc[:,"NumberOfTimes90DaysLate"] > 90].count()
#结果 :
#SeriousDlqin2yrs 225
#RevolvingUtilizationOfUnsecuredLines 225
#age 225
#NumberOfTime30-59DaysPastDueNotWorse 225
#DebtRatio 225
#MonthlyIncome 225
#NumberOfOpenCreditLinesAndLoans 225
#NumberOfTimes90DaysLate 225
#NumberRealEstateLoansOrLines 225
#NumberOfTime60-89DaysPastDueNotWorse 225
#NumberOfDependents 225
#dtype: int64
#有225个样本存在这种情况,并且通过对这些样本的观察,标签并不都是1,也就并不都是坏客户。因此,基本可以判断,这些样本是某种异常,应该删除
data = data[data.loc[:,"NumberOfTimes90DaysLate"] < 90]
#恢复索引
data.index = range(data.shape[0])
data.info()
3.2.4 为什么不统一量纲,也不标准化数据分布?
在描述性统计结果中,可以观察到数据量纲明显不统一,而且存在一部分极偏的分布,虽然逻辑回归没有分布要求,但是如果数据服从正态分布的话,梯度下降可以收敛得更快。而这里不进行标准化处理,也不进行量纲统一,主要是因为:
无论算法有什么样的规定或者统计学中有什么样的要求,最终目的都是要为业务服务。制作评分卡是需要对数据进行“分档”,如年龄20-30岁为一档,年龄30-50岁为一档,月收入1w以上为一档,5000-1w为一档,每档的分数不同。一旦将数据统一量纲,或者标准化之后,数据大小和范围都会改变,统计结果漂亮了,但是对于业务人员来说,可能完全无法理解,标准化后的年龄在0.00328-0.00467之间为一档是什么含义。并且,新客户填写的信息,本身就是量纲不统一的。虽然可以将所有的信息录入之后,统一进行标准化,然后导入算法计算,但是最终落到业务人员手上去判断的时候,他们可能完全不理解为什么录入的信息变成了一串统计上很美但实际上根本看不懂的数字。
因此,由于业务要求,在制作评分卡的时候,要尽量保持数据的原貌,年龄就是8-110的数字,收入就是大于0,最大值可以是无限大的数字,即便量纲不统一,也不需要对数据进行标准化处理。
3.2.5 样本不均衡问题
x = data.iloc[:,1:]
y = data.iloc[:,0]
y.value_counts()
#结果:
#0 139292
#1 9873
#Name: SeriousDlqin2yrs, dtype: int64
n_sample = x.shape[0]
n_1_sample = y.value_counts()[1]
n_0_sample = y.value_counts()[0]
print('样本个数:{};1占{:.2%};0占{:.2%}'.format(n_sample,n_1_sample/n_sample,n_0_sample/n_sample))
#结果:样本个数:149165;1占6.62%;0占93.38%
可以看出,样本严重不均衡,实际违约的人并不多。并且银行不会真的一棒子打死所有会违约的恶人,很多人是会还钱的,只是忘记了还款日,很多人是不愿意欠钱的,但是当时真的资金周转困难,所以发生逾期,但一旦有钱就会把钱还上。对于银行来说,最后只要能够把钱还上,就愿意借出,因为借出就会有收入(利息)。因此,银行真正想要判别出来的其实是“恶意违约”的人,而这部分人非常非常少,样本就会出现不平衡现象。这也是银行业建模的一个痛点:永远希望捕捉到少数类。
逻辑回归中使用最多的是上采样方法来平衡样本:
import imblearn
#如果报错,就先安装:pip install imblearn
#imblearn是专门用来处理不平衡数据集的库,在处理样本不平衡问题中性能高过sklearn很多
#imblearn里面也是一个个的类,也需要进行实例化,fit拟合,和sklearn用法相似
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state = 42)#实例化
x, y = sm.fit_resample(x, y)#返回已经上采样完毕过后的特征矩阵和标签
#fit_sample返回DataFrame(报错),fit_resample返回Series类型
n_sample_ = x.shape[0]
n_1_sample_ = y.value_counts()[1]
n_0_sample_ = y.value_counts()[0]
print('样本个数:{};1占{:.2%};0占{:.2%}'.format(n_sample_,n_1_sample_/n_sample_,n_0_sample_/n_sample_))
#结果:样本个数:278584;1占50.00%;0占50.00%
3.2.6 分训练集和测试集
from sklearn.model_selection import train_test_split
x = pd.DataFrame(x)
y = pd.DataFrame(y)
x_train,x_vali,y_train,y_vali = train_test_split(x,y,test_size = 0.3)
model_data = pd.concat([y_train,x_train],axis = 1)
model_data.index = range(model_data.shape[0])
model_data.columns = data.columns
vali_data = pd.concat([y_vali,x_vali],axis = 1)
vali_data.index = range(vali_data.shape[0])
vali_data.columns = data.columns
model_data.to_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\model_data.csv")
vali_data.to_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\mvali_data.csv")
3.3 分箱
要制作评分卡,是要给各个特征进行分档,以便业务人员能够根据新客户填写的信息为新客户进行打分。因此在评分卡制作过程中,重要的步骤之一就是分箱。可以说,分箱是评分卡最难,也是最核心的部分。分箱的本质其实就是离散化连续变量,让拥有不同属性的人被分成不同的类别(打上不同的分数),其本质类似于聚类。
- 分多少箱子才合适
最开始并不知道,但是既然是将连续型变量离散化,箱子个数必然不能太多,最好控制在十个以下。而用来制作评分卡,最好能在4-5个最佳。离散化连续型变量必然伴随着信息的损失,并且箱子越少,信息损失越大。为了衡量特征上的信息量以及特征对预测函数的贡献,银行业定义了概念Information Value(IV):
I V = ∑ i = 1 N ( g o o d % − b a d % ) ∗ W O E i IV=\sum_{i=1}^N(good\%-bad\%)*WOE_i IV=∑i=1N(good%−bad%)∗WOEi
其中 N N N是这个特征上箱子的个数, i i i代表每个箱子, g o o d % good\% good%是这个箱内的优质客户(标签为0的客户)占整个特征中所有优质客户的比例, b a d % bad\% bad%是这个箱子里的坏客户(标签为1的客户)占整个特征中所有坏客户的比例,而 W O E i WOE_i WOEi则定义为:
W O E i = l n ( g o o d % b a d % ) WOE_i=ln(\frac{good\%}{bad\%}) WOEi=ln(bad%good%)
这是在银行业中用来衡量违约概率的指标,中文称为证据权重(weight of Evidence),本质其实就是优质客户比坏客户的比例的对数。WOE是对一个箱子来说,WOE越大代表这个箱子里面的优质客户越多,而IV是对整个特征来说,IV的意义如下表所示:

可见,IV并非越大越好,要找到IV的大小和箱子个数的平衡点。所以会对特征进行分箱,然后计算每个特征在每个箱子数目下的WOE值,利用IV值的曲线,找出合适的分箱个数。 - 分箱要达成什么样的效果?
希望不同属性的人有不同的分数,因此在同一个箱子内的人的属性是尽量相似的,而不同箱子的人的属性是尽量不同的,即常说的“组间差异大,组内差异小”。对于评分卡来说,希望一个箱子内的人违约概率是类似的,而不同箱子的人的违约概率差距很大,即WOE差距要大,并且每个箱子中坏客户所占的比重( b a d % bad\% bad%)也要不同。可以使用卡方检验来对比两个箱子之间的相似性,如果两个箱子之间卡方检验的P值很大,则说明他们非常相似,可以将两个箱子合并为一个箱子。
基于这样的思想,总结出以下对一个特征进行分箱的步骤:
1)首先把连续型变量分成一组数量较多的分类型变量,如将几万个样本分成100组,或50组;
2)确保每一个组中都要包含两种类别的样本,否则IV值会无法计算;
3)对相邻的组进行卡方检验,卡方检验的P值很大的组进行合并,直到数据中的组数小于设定的 N N N箱为止;
4)让一个特征分别分成[2,3,4,…,20]箱,观察每个分箱个数下的IV值如何变化,找出最合适的分箱个数;
5)分箱完毕后,计算每个箱的WOE值, b a d % bad\% bad%,观察分箱效果。
以上步骤都完成后,可以对各个特征都进行分箱,然后观察每个特征的IV值,以此来挑选特征。
以“age”为例,实现分箱过程。
3.3.1 等频分箱
#按照等频对需要分箱的列进行分箱,以“age”为例
model_data["qcut"],updown = pd.qcut(model_data["age"],retbins = True, q =20)
"""
pd.qcut,基于分位数的分箱函数,本质是将连续型变量离散化。只能够处理一维数据,返回箱子的上限和下限
参数q:要分箱的个数
参数retbins = True要求同时返回结构是索引为样本的索引,元素为分到的箱子的Series
现在返回两个值:每个样本属于哪个箱子,以及所有箱子的上限和下限
"""
#让model_data新添加一列叫做“qcut”,这一列其实就是每个样本所对应的箱子
model_data["qcut"]
#所有箱子的上限和下限
updown
#统计每个分箱0,1的数量
#使用数据透视表的功能groupby
count_y0 = model_data[model_data["SeriousDlqin2yrs"] == 0].groupby(by = "qcut").count()["SeriousDlqin2yrs"]
count_y1 = model_data[model_data["SeriousDlqin2yrs"] == 1].groupby(by = "qcut").count()["SeriousDlqin2yrs"]
#num_bins值分别为每个区间的上界、下界,0出现的次数,1出现的次数
num_bins = [*zip(updown,updown[1:],count_y0,count_y1)]
#注意:zip会按照最短的那一个列表进行组合,zip可以将列表变成一对对相应的元组
num_bins
#结果:
#[(21.0, 28.0, 4241, 7581),
# (28.0, 31.0, 3487, 5986),
# (31.0, 34.0, 3981, 6750),
# (34.0, 36.0, 2942, 4696),
# (36.0, 39.0, 5119, 7492),
# (39.0, 41.0, 3984, 5761),
# (41.0, 43.0, 4017, 5610),
# (43.0, 45.0, 4368, 5915),
# (45.0, 47.0, 4701, 6397),
# (47.0, 48.0, 2485, 3084),
# (48.0, 50.0, 4884, 6091),
# (50.0, 52.0, 4621, 5800),
# (52.0, 54.0, 4671, 5067),
# (54.0, 56.0, 4645, 4125),
# (56.0, 58.0, 4561, 3439),
# (58.0, 61.0, 6656, 4935),
# (61.0, 64.0, 6961, 3260),
# (64.0, 68.0, 6655, 2353),
# (68.0, 74.0, 6778, 1897),
# (74.0, 109.0, 7666, 1346)]
3.3.2 确保每个箱中都有0和1(选学)
for i in range(20):
#如果第一个组没有包含正样本或负样本,向后合并
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
"""
合并之后,第一行的组是否一定有两种样本呢?不一定
如果原本的第一组和第二组都没有包含正样本,或者都没有包含负样本,那么合并之后,第一行的组也还是没有包含两种样本
所以在每次合并完毕之后,需要再检查,第一组是否已经包含了两种样本
这里使用continue跳出了本次循环,开始下一次循环,所以回到了最开始的for i in range(20),让i+1
这就跳过了下面的代码,又从头开始检查第一组是否包含两种样本
如果第一组中依然没有包含两种样本,则if通过,继续合并,每合并一次就会循环检查一次,最多合并20次
如果第一组中已经包含两种样本,则if不通过,就开始执行下面的代码
"""
#确认第一组中肯定包含两种样本了,如果其他组没有包含两种样本,就向前合并
#此时num_bins已经被上面的代码处理过了,可能被合并过,也可能没有被合并
#无论如何,要在num_bins中遍历,所以写成in range(len(num_bins))
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1]=[(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
#如果对第一组和后面所有组的判断中,都没有进入if去合并,则提前结束所有循环
else:
break
"""
倒数第二个break,只有在if被满足的条件下才会被触发
也就是说,只有发生了合并,才会打断for i in range(len(num_bins))这个循环
为什么要打断这个循环?因为是在range(len(num_bins))中遍历
但合并发生后,len(num_bins)发生了改变,但循环却不会重新开始,循环就会因为超出取值边界而报错
因此,一旦if被触发,即一旦合并发生,就让循环被破坏,使用break跳出当前循环
循环就会回到最开始的for i in range(20)中
此时判断第一组是否有两种标签的代码不会被触发,但for i in range(len(num_bins))却会被重新运行
这样就更新了i的取值列表,循环也就不会报错
"""
3.3.3 定义WOE和IV函数
#计算WOE和BAD RATE
#BAD RATE与bad%不是一个东西
#BAD RATE是一个箱中,坏的样本所占的比例(bad/total);而bad%是一个箱中的坏样本占整个特征中的坏样本的比例
def get_woe(num_bins):
#通过num_bins数据计算woe
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns = columns)
df["total"] = df.count_0 + df.count_1#一个箱子当中所有的样本数
df["percentage"] = df.total/df.total.sum()#一个箱子里的样本数,占所有样本数的比例
df["bad_rate"] = df.count_1/df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_0.sum()
df["woe"] = np.log(df["good%"]/df["bad%"])
return df
#计算IV值
def get_iv(bins_df):
rate = bins_df["good%"] - bins_df["bad%"]
iv = np.sum(rate * bins_df.woe)
return iv
get_iv(get_woe(num_bins))
#结果:0.35654189808715486
3.3.4 卡方检验,合并箱体,画出IV曲线,选出最佳分箱个数
num_bins_ = num_bins.copy()
import matplotlib.pyplot as plt
import scipy
IV = []
axisx = []
while len(num_bins_) > 2:
pvs = []
#获取num_bins_两两之间的卡方检验的置信度(或卡方值)
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
# 0返回chi2值,1返回p值
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
#通过p值进行处理,合并p值最大的两组
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
bins_df = get_woe(num_bins_)
axisx.append(len(num_bins_))
IV.append(get_iv(bins_df))
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.show
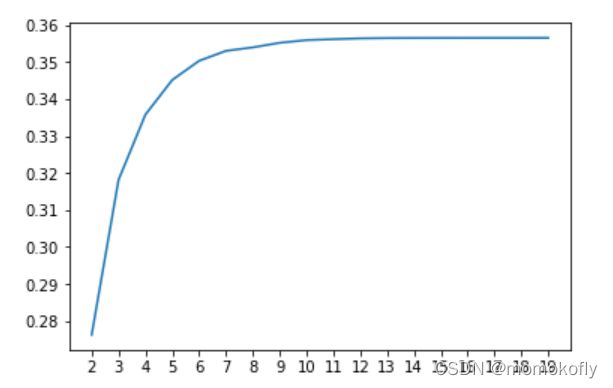
3.3.5 用最佳分箱个数分箱,并验证分箱结果
将合并箱体的部分定义为函数,并实现分箱:
def get_bin(num_bins_,n):
while len(num_bins_) > n:
pvs = []
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
return num_bins_
afterbins = get_bin(num_bins,6)
afterbins
#结果:
#[(21.0, 36.0, 14651, 25013),
# (36.0, 54.0, 38850, 51217),
# (54.0, 61.0, 15862, 12499),
# (61.0, 64.0, 6961, 3260),
# (64.0, 74.0, 13433, 4250),
# (74.0, 109.0, 7666, 1346)]
bins_df = get_woe(afterbins)
bins_df

注:观察上表,其中每个箱的bad_rate应该有明显差距,说明组间差异大,woe应该是单调的。在上例中,每个bad_rate之间差距比较明显,并且woe由正变负,说明分箱的效果还是不错的。
3.3.6 将选取最佳分箱个数的过程包装为函数
def graphforbestbin(df, x, y,n = 5,q = 20,graph = True):
"""
自动最优分箱函数,基于卡方检验的分箱
参数:
df:需要输入的数据
x:需要分箱的列名
y:分箱数据对应的标签Y的列名
n:保留分箱个数
q:初始分箱的个数
graph:是否要画出IV图像
"""
df = df[[x,y]].copy()
df["qcut"],bins = pd.qcut(df[x],retbins = True,q = q,duplicates = "drop")
count_y0 = df.loc[df[y] == 0].groupby(by = 'qcut').count()[y]
count_y1 = df.loc[df[y] == 1].groupby(by = 'qcut').count()[y]
num_bins = [*zip(bins,bins[1:],count_y0,count_y1)]
for i in range(q):
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
else:
break
def get_woe(num_bins):
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns = columns)
df["total"] = df.count_0 + df.count_1#一个箱子当中所有的样本数
df["percentage"] = df.total/df.total.sum()#一个箱子里的样本数,占所有样本数的比例
df["bad_rate"] = df.count_1/df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_0.sum()
df["woe"] = np.log(df["good%"]/df["bad%"])
return df
def get_iv(bins_df):
rate = bins_df["good%"] - bins_df["bad%"]
iv = np.sum(rate * bins_df.woe)
return iv
IV = []
axisx = []
while len(num_bins) > n:
pvs = []
#获取num_bins_两两之间的卡方检验的置信度(或卡方值)
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
# 0返回chi2值,1返回p值
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
#通过p值进行处理,合并p值最大的两组
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(
num_bins[i][0],
num_bins[i+1][1],
num_bins[i][2]+num_bins[i+1][2],
num_bins[i][3]+num_bins[i+1][3])]
bins_df = get_woe(num_bins)
axisx.append(len(num_bins))
IV.append(get_iv(bins_df))
if graph:
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.show()
model_data.columns
#结果:
# Index(['SeriousDlqin2yrs', 'RevolvingUtilizationOfUnsecuredLines', 'age',
# 'NumberOfTime30-59DaysPastDueNotWorse', 'DebtRatio', 'MonthlyIncome',
# 'NumberOfOpenCreditLinesAndLoans', 'NumberOfTimes90DaysLate',
# 'NumberRealEstateLoansOrLines', 'NumberOfTime60-89DaysPastDueNotWorse',
# 'NumberOfDependents', 'qcut'],
# dtype='object')
for i in model_data.columns[1:-1]:
print(i)
graphforbestbin(model_data,i,"SeriousDlqin2yrs",n = 2,q = 20)
绘制的图像中,有部分变量的图像有明显异常,可能是无法进行自动分箱,需要手动分箱。
3.3.7 对所有特征进行分箱选择
#可以使用自动分箱的变量
auto_col_bins = {"RevolvingUtilizationOfUnsecuredLines":6
,"age":5
,"DebtRatio":4
,"MonthlyIncome":3
,"NumberOfOpenCreditLinesAndLoans":5}
#不能使用自动分箱的变量
hand_bins = {"NumberOfTime30-59DaysPastDueNotWorse":[0,1,2,13]
,"NumberOfTimes90DaysLate":[0,1,2,17]
,"NumberRealEstateLoansOrLines":[0,1,2,4,54]
,"NumberOfTime60-89DaysPastDueNotWorse":[0,1,2,8]
,"NumberOfDependents":[0,1,2,3]}
#保证区间覆盖使用使用np.inf替换最大值,用-np.inf替换最小值
hand_bins={k:[-np.inf,*v[:-1],np.inf] for k,v in hand_bins.items()}
hand_bins
#结果:
#{'NumberOfTime30-59DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfTimes90DaysLate': [-inf, 0, 1, 2, inf],
# 'NumberRealEstateLoansOrLines': [-inf, 0, 1, 2, 4, inf],
# 'NumberOfTime60-89DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfDependents': [-inf, 0, 1, 2, inf]}
bins_of_col = {}
#生成自动分箱的分箱区间和分箱后的IV值
for col in auto_col_bins:
bins_df = graphforbestbin(model_data,col
,"SeriousDlqin2yrs"
,n = auto_col_bins[col]#使用字典的性质来取出每个特征所对应的箱的数量
,q = 20
,graph = False)
bins_list = sorted(set(bins_df["min"]).union(bins_df["max"]))
#保证区间覆盖使用np.inf替换最大值,-np.inf替换最小值
bins_list[0],bins_list[-1] = -np.inf,np.inf
bins_of_col[col] = bins_list
#合并手动分箱数据
bins_of_col.update(hand_bins)
bins_of_col
#结果:
#{'RevolvingUtilizationOfUnsecuredLines': [-inf,
# 0.0989579085,
# 0.29729511700000005,
# 0.724130660095638,
# 0.9826874216115066,
# 0.9999999,
# inf],
# 'age': [-inf, 36.0, 54.0, 61.0, 74.0, inf],
# 'DebtRatio': [-inf,
# 0.017195179893425287,
# 0.360410730948662,
# 1.505985184207865,
# inf],
# 'MonthlyIncome': [-inf, 0.1, 6896.729169638697, inf],
# 'NumberOfOpenCreditLinesAndLoans': [-inf, 1.0, 3.0, 5.0, 15.0, inf],
# 'NumberOfTime30-59DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfTimes90DaysLate': [-inf, 0, 1, 2, inf],
# 'NumberRealEstateLoansOrLines': [-inf, 0, 1, 2, 4, inf],
# 'NumberOfTime60-89DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfDependents': [-inf, 0, 1, 2, inf]}
3.4 计算各箱的WOE并映射到数据中
接下来需要计算各箱的WOE,并且把WOE替换到原始数据model_data中。因为将使用WOE覆盖后的数据来建模,所以希望获取的是“各个箱”的分类结果,即评分卡上各个评分项目的分类结果。
data = model_data.copy()
#函数pd.cut可以根据已知的分箱间隔把数据分箱
#参数为pd.cut(数据,以列表表示的分箱间隔)
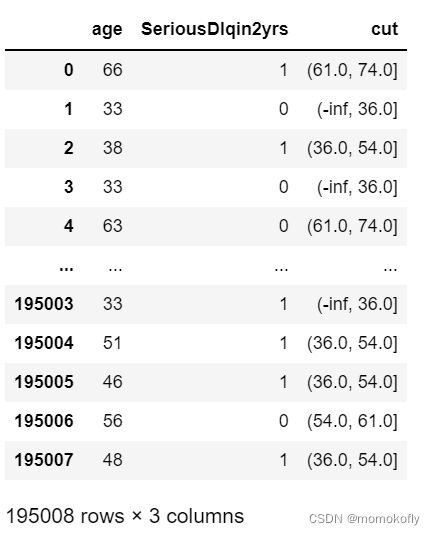
data = data[["age","SeriousDlqin2yrs"]].copy()
data["cut"] = pd.cut(data["age"],[-np.inf, 36.0, 54.0, 61.0, 74.0, np.inf])
data
#将数据按分箱结果聚合,并取出其中的标签值
data.groupby("cut")["SeriousDlqin2yrs"].value_counts()
#结果:
#cut SeriousDlqin2yrs
#(-inf, 36.0] 1 25013
# 0 14651
#(36.0, 54.0] 1 51217
# 0 38850
#(54.0, 61.0] 0 15862
# 1 12499
#(61.0, 74.0] 0 20394
# 1 7510
#(74.0, inf] 0 7666
# 1 1346
#Name: SeriousDlqin2yrs, dtype: int64
#使用unstack()来将树状结构变成表装结构
data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
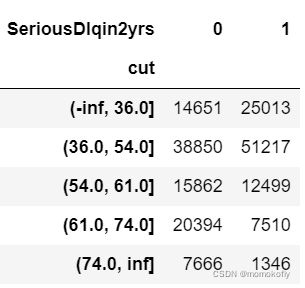
bins_df = data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
bins_df

把以上过程包装成函数:
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
woe = bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
return woe
#将所有特征的WOE存储到字典当中
woeall = {}
for col in bins_of_col:
woeall[col] = get_woe(model_data,col,"SeriousDlqin2yrs",bins_of_col[col])
woeall
"""
结果:
{'RevolvingUtilizationOfUnsecuredLines': cut
(-inf, 0.099] 2.224258
(0.099, 0.297] 0.661049
(0.297, 0.724] -0.496930
(0.724, 0.983] -1.353231
(0.983, 1.0] -0.468322
(1.0, inf] -2.074375
dtype: float64,
'age': cut
(-inf, 36.0] -0.533226
(36.0, 54.0] -0.274702
(54.0, 61.0] 0.239939
(61.0, 74.0] 1.000667
(74.0, inf] 1.741319
dtype: float64,
'DebtRatio': cut
(-inf, 0.0172] 1.454800
(0.0172, 0.36] 0.057854
(0.36, 1.506] -0.349860
(1.506, inf] 0.179866
dtype: float64,
'MonthlyIncome': cut
(-inf, 0.1] 1.416447
(0.1, 6896.729] -0.200153
(6896.729, inf] 0.313653
dtype: float64,
'NumberOfOpenCreditLinesAndLoans': cut
(-inf, 1.0] -0.846486
(1.0, 3.0] -0.341287
(3.0, 5.0] -0.058515
(5.0, 15.0] 0.120179
(15.0, inf] 0.370470
dtype: float64,
'NumberOfTime30-59DaysPastDueNotWorse': cut
(-inf, 0.0] 0.355435
(0.0, 1.0] -0.883450
(1.0, 2.0] -1.375498
(2.0, inf] -1.535304
dtype: float64,
'NumberOfTimes90DaysLate': cut
(-inf, 0.0] 0.235365
(0.0, 1.0] -1.756769
(1.0, 2.0] -2.281914
(2.0, inf] -2.388741
dtype: float64,
'NumberRealEstateLoansOrLines': cut
(-inf, 0.0] -0.401039
(0.0, 1.0] 0.199083
(1.0, 2.0] 0.631953
(2.0, 4.0] 0.382872
(4.0, inf] -0.335461
dtype: float64,
'NumberOfTime60-89DaysPastDueNotWorse': cut
(-inf, 0.0] 0.123312
(0.0, 1.0] -1.381946
(1.0, 2.0] -1.772126
(2.0, inf] -1.652897
dtype: float64,
'NumberOfDependents': cut
(-inf, 0.0] 0.658801
(0.0, 1.0] -0.519028
(1.0, 2.0] -0.529047
(2.0, inf] -0.499650
dtype: float64}
"""
接下来,把所有WOE映射到原始数据中:
#不希望覆盖掉原本的数据,创建一个新的DataFrame,索引和原始数据model_data一模一样
model_woe = pd.DataFrame(index = model_data.index)
#将原数据分箱后,按箱的结果把WOE结果用map函数映射到数据中
model_woe["age"] = pd.cut(model_data["age"],bins_of_col["age"]).map(woeall["age"])
#对所有特征操作,可以写成:
for col in bins_of_col:
model_woe[col] = pd.cut(model_data[col],bins_of_col[col]).map(woeall[col])
#将标签补充到数据中
model_woe["SeriousDlqin2yrs"] = model_data["SeriousDlqin2yrs"]
#这就是最终的建模数据了
model_woe.head()#原来的数据都变成分箱后归属于那一个箱的WOE值
3.5 建模与模型验证
以上处理完训练集,接下来处理测试集,在已经有分箱的情况下,测试集的处理就非常简单,只需要将已经计算好的WOE映射到测试集中去即可。
#处理测试集
vali_woe = pd.DataFrame(index = vali_data.index)
for col in bins_of_col:
vali_woe[col] = pd.cut(vali_data[col],bins_of_col[col]).map(woeall[col])
vali_woe["SeriousDlqin2yrs"] = vali_data["SeriousDlqin2yrs"]
vali_x = vali_woe.iloc[:,:-1]
vali_y = vali_woe.iloc[:,-1]
接下来,就可以开始建模了。
x = model_woe.iloc[:,:-1]
y = model_woe.iloc[:,-1]
from sklearn.linear_model import LogisticRegression as LR
lr = LR().fit(x,y)
lr.score(vali_x,vali_y)
#结果:0.771286015123959
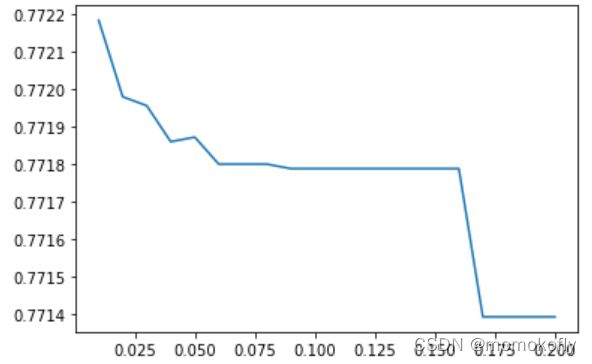
返回的效果一般,可以试着使用C和max_iter的学习曲线把逻辑回归的效果调上去。
c_1 = np.linspace(0.01,1,20)
c_2 = np.linspace(0.01,0.2,20)
score = []
for i in c_2:
lr = LR(solver = "liblinear",C = i).fit(x,y)
score.append(lr.score(vali_x,vali_y))
plt.figure()
plt.plot(c_2,score)
plt.show()
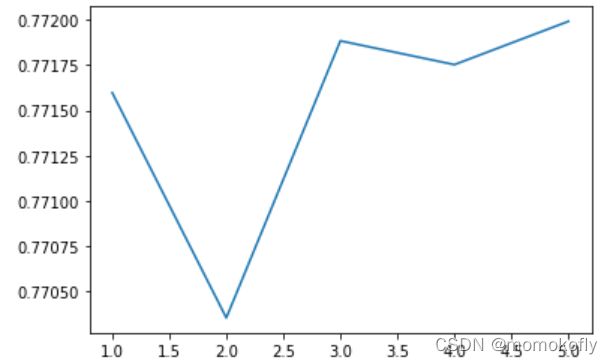
lr.n_iter_
#结果:array([5], dtype=int32)
score = []
for i in [1,2,3,4,5]:
lr = LR(solver = "liblinear",C = 0.025,max_iter = i).fit(x,y)
score.append(lr.score(vali_x,vali_y))
plt.figure()
plt.plot([1,2,3,4,5],score)
plt.show()
lr = LR(solver = "liblinear",C = 0.025,max_iter = 5).fit(x,y)
lr.score(vali_x,vali_y)
#结果:0.7719919594141859
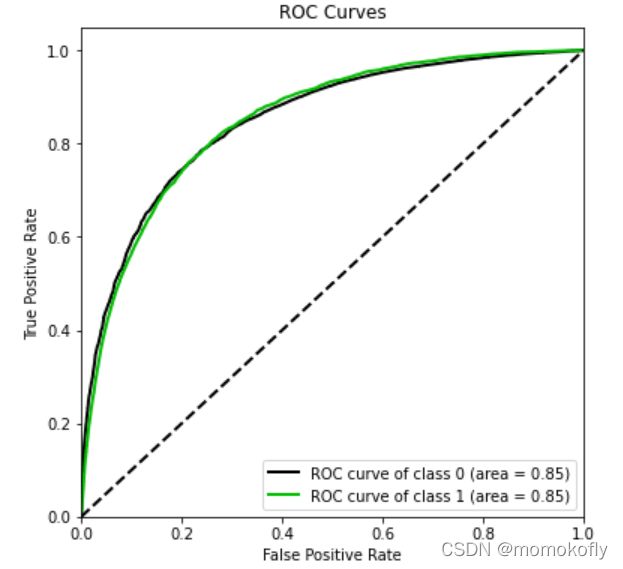
尽管从准确率来看,模型效果属于一般,但可以看看ROC曲线上的结果。
import scikitplot as skplt
#如果报错,先安装scikit-plot:pip install scikit-plot
vali_proba_df = pd.DataFrame(lr.predict_proba(vali_x))
skplt.metrics.plot_roc(vali_y,vali_proba_df
,plot_micro = False,figsize = (6,6)
,plot_macro = False)
3.6 制作评分卡
建模完毕,使用准确率和ROC曲线验证了模型的预测能力(效果不太好)。接下来就是要将逻辑回归转换为标准评分卡了。评分卡中的分数,由以下公式计算:
S c o r e = A − B ∗ l o g ( o d d s ) Score=A-B*log(odds) Score=A−B∗log(odds)
其中 A A A与 B B B是常数, A A A叫做“补偿”, B B B叫做“刻度”, l o g ( o d d s ) log(odds) log(odds)代表了一个人违约的可能性。其实逻辑回归的结果取对数几率形式会得到 a T x \textbf{a}^T\textbf{x} aTx,即参数*特征矩阵,所以 l o g ( o d d s ) log(odds) log(odds)其实就是参数。两个常数可以通过两个假设的分值代入公式求出,这两个假设分别是:
(1)某个特征的违约概率下的预期分值
(2)指定的违约概率翻倍的分数(PDO)
本文中假设 B B B和 A A A分别为(28.85390081777927, 481.8621880878296)。有了 B B B和 A A A,分数就很容易得到了。其中不受评分卡中各特征影响的基础分,就是将截距作为 l o g ( o d d s ) log(odds) log(odds)代入公式进行计算,而其他各个特征各个分档的分数,也是将系数代入进行计算:
base_score = A - B*lr.intercept_
base_score
#结果:array([481.75070042])
score_age = woeall["age"] * (-B*lr.coef_[0][1])
score_age
#结果:
#cut
#(-inf, 36.0] -11.588079
#(36.0, 54.0] -5.969833
#(54.0, 61.0] 5.214366
#(61.0, 74.0] 21.746526
#(74.0, inf] 37.842413
#dtype: float64
可以通过循环,将所有特征的评分卡内容全部一次性写入一个本地文件ScoreData.csv:
file = "C:/Users/86188/Desktop/coding/Kaggle-give me some credit/ScoreData.csv"
#open是用来打开文件的python命令,第一个参数是文件的路径+文件名,如果文件是放在根目录下,则只需要文件名就好
#第二个参数是打开文件后的用途,“w”表示用于写入,通常使用的是“r”,表示打开来阅读
#首先写入基准分数
#之后使用循环,每次生成一组score_age类似的分档和分数,不断写入文件之中
with open(file,"w") as fdata:#若本身不存在这个文件,会新建该文件
fdata.write("base_score,{}\n".format(base_score))
for i,col in enumerate(x.columns):
score = woeall[col] * (-B*lr.coef_[0][i])
score.name = "Score"
score.index.name = col
score.to_csv(file,header = True,mode = "a")
参考资料:https://www.bilibili.com/video/BV1Ch411x7xB?p=87&spm_id_from=pageDriver