其他算法-非线性降维t-SNE
目录
- t-SNE
-
- 流形学习
- SNE算法原理
- SNE求解
- 对称SNE
- t-SNE
- 基于sklearn的t-SNE
t-SNE
流形学习
流形(manifold)是几何中的一个概念,它是高维空间中的几何结构,即空间中的点构成的集合。可以简单的将流形理解成二维空间的曲线,三维空间的曲面以及在更高维空间的推广;
流形学习,全称流形学习方法(Manifold Learning),流形学习就是从高维采样数据中恢复低维流形结构,即找到高维空间中的低维流形,并求出相应的嵌入映射,以实现维数约简或者数据可视化。它是从观测到的现象中去寻找事物的本质,找到产生数据的内在规律;
比如下图的三维数据,可以降维至二维,去除数据的冗余:

SNE算法原理
对于一个包含大量特征的数据集,降维是探索数据内隐藏模式的一种方式,虽然SVD和PCA可以降维(回顾:SVD奇异值分解和PCA主成分分析),但它们属于线性降维;不能合理地处理特征之间的复杂非线性关系;因此,出现了非线性降维算法SNE(stochastic neighbor embedding);
假设输入的高维空间变量为 X ∈ R n X\in\mathbb{R}^{n} X∈Rn,输出低维空间变量为 Y ∈ R t Y\in\mathbb{R}^{t} Y∈Rt,其中 t ≪ n t\ll n t≪n,假设样本数量为 m m m,则输入到输出为 ( x 1 , . . . , x m ) , x ∈ X , ( y 1 , . . . , y m ) , y ∈ Y (x_{1},...,x_{m}),x\in X,(y_{1},...,y_{m}),y\in Y (x1,...,xm),x∈X,(y1,...,ym),y∈Y;
SNE先计算高维空间中,样本间的相似度,用条件概率表示,比如对于样本 x i x_{i} xi,计算 x i x_{i} xi和 x j x_{j} xj的相似度 p j ∣ i p_{j|i} pj∣i:
p j ∣ i = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 σ i 2 ) ∑ k ≠ i e x p ( − ∣ ∣ x i − x k ∣ ∣ 2 2 σ i 2 ) p_{j|i}=\frac{exp(-\frac{||x_{i}-x_{j}||^{2}}{2\sigma_{i}^{2}})}{\sum_{k\neq i}exp(-\frac{||x_{i}-x_{k}||^{2}}{2\sigma_{i}^{2}})} pj∣i=∑k=iexp(−2σi2∣∣xi−xk∣∣2)exp(−2σi2∣∣xi−xj∣∣2)
高维空间引入参数 σ i \sigma_{i} σi与每个样本 x i x_{i} xi对应,增加泛化能力,另外,目标是刻画不同样本之间的相似度,所以设置同一个样本的相似度为 p i ∣ i = 0 p_{i|i}=0 pi∣i=0,使之不参与计算;
对于低维空间,进行类似的表达,对于样本 y i y_{i} yi, y i y_{i} yi和 y j y_{j} yj的相似度 q j ∣ i q_{j|i} qj∣i为:
q j ∣ i = e x p ( − ∣ ∣ y i − y j ∣ ∣ 2 ) ∑ k ≠ i e x p ( − ∣ ∣ y i − y k ∣ ∣ 2 ) q_{j|i}=\frac{exp(-||y_{i}-y_{j}||^{2})}{\sum_{k\neq i}exp(-||y_{i}-y_{k}||^{2})} qj∣i=∑k=iexp(−∣∣yi−yk∣∣2)exp(−∣∣yi−yj∣∣2)
同样的, q i ∣ i = 0 q_{i|i}=0 qi∣i=0;
降维的目的是在减少特征维度的同时,保持数据分布的相似,即希望 p j ∣ i = q j ∣ i p_{j|i}=q_{j|i} pj∣i=qj∣i,KL散度可以衡量两个分布的相似程度(分布越相似,KL散度越小),因此损失函数定义为两个分布的KL散度:
L = ∑ i K L ( P i ∣ ∣ Q i ) = ∑ i ( ∑ j p j ∣ i l o g ( p j ∣ i q j ∣ i ) ) L=\sum_{i}KL(P_{i}||Q_{i})=\sum_{i}(\sum_{j}p_{j|i}log(\frac{p_{j|i}}{q_{j|i}})) L=i∑KL(Pi∣∣Qi)=i∑(j∑pj∣ilog(qj∣ipj∣i))
其中, P i P_{i} Pi表示给定高维样本 x i x_{i} xi后,它与其他高维样本的相似度分布; Q i Q_{i} Qi表示给定低维样本 y i y_{i} yi后,它与其他低维样本的相似度分布;
SNE的目标就是找到合适的分布 Q i Q_{i} Qi, i ∈ { 1 , 2 , . . . , m } i\in \left\{1,2,...,m\right\} i∈{1,2,...,m},使损失变小,即:使得降维前后的数据分布相似;
SNE求解
对于每个样本 x i x_{i} xi,都对应着不同的 σ i \sigma_{i} σi,SNE引入困惑度,困惑度是人为取值,根据困惑度计算 σ i \sigma_{i} σi,困惑度定义为:
P e r p ( P i ) = 2 H ( P i ) Perp(P_{i})=2^{H(P_{i})} Perp(Pi)=2H(Pi)
其中, H ( P i ) H(P_{i}) H(Pi)为信息熵(信息熵回顾:图神经网络第六课-GNN的可解释性),困惑度的调整体现了泛化能力,通常取值在5到50之间,给定困惑度后可以计算得到 σ i \sigma_{i} σi;
随后,计算损失函数关于 y i y_{i} yi的梯度,基于梯度下降更新 y i y_{i} yi,一般会采用结合动量的梯度下降进行更新;
对称SNE
对称SNE意图使用联合概率分布替换条件概率分布,近似地,得到表达:
p i j = p i ∣ j + p j ∣ i 2 , q i j = e x p ( − ∣ ∣ y i − y j ∣ ∣ 2 ) ∑ k ≠ l e x p ( − ∣ ∣ y k − y l ∣ ∣ 2 ) p_{ij}=\frac{p_{i|j}+p_{j|i}}{2},q_{ij}=\frac{exp(-||y_{i}-y_{j}||^{2})}{\sum_{k\neq l}exp(-||y_{k}-y_{l}||^{2})} pij=2pi∣j+pj∣i,qij=∑k=lexp(−∣∣yk−yl∣∣2)exp(−∣∣yi−yj∣∣2)
此时概率具有对称性: p i j = p j i p_{ij}=p_{ji} pij=pji, q i j = q j i q_{ij}=q_{ji} qij=qji,损失函数变为:
L = ∑ i K L ( P i ∣ ∣ Q i ) = ∑ i ( ∑ j p i j l o g ( p i j q i j ) ) L=\sum_{i}KL(P_{i}||Q_{i})=\sum_{i}(\sum_{j}p_{ij}log(\frac{p_{ij}}{q_{ij}})) L=i∑KL(Pi∣∣Qi)=i∑(j∑pijlog(qijpij))
t-SNE
t-SNE(t-distributed stochastic neighbor embedding)在对称SNE的基础上,将低维空间的高斯分布变成 t t t分布,得到:
q i j = ( 1 + ∣ ∣ y i − y j ∣ ∣ 2 ) − 1 ∑ k ≠ l ( 1 + ∣ ∣ y k − y l ∣ ∣ 2 ) − 1 q_{ij}=\frac{(1+||y_{i}-y_{j}||^{2})^{-1}}{\sum_{k\neq l}(1+||y_{k}-y_{l}||^{2})^{-1}} qij=∑k=l(1+∣∣yk−yl∣∣2)−1(1+∣∣yi−yj∣∣2)−1
高维空间的分布不发生变化:
p j ∣ i = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 σ i 2 ) ∑ k ≠ i e x p ( − ∣ ∣ x i − x k ∣ ∣ 2 2 σ i 2 ) , p i j = p i ∣ j + p j ∣ i 2 m p_{j|i}=\frac{exp(-\frac{||x_{i}-x_{j}||^{2}}{2\sigma_{i}^{2}})}{\sum_{k\neq i}exp(-\frac{||x_{i}-x_{k}||^{2}}{2\sigma_{i}^{2}})},p_{ij}=\frac{p_{i|j}+p_{j|i}}{2m} pj∣i=∑k=iexp(−2σi2∣∣xi−xk∣∣2)exp(−2σi2∣∣xi−xj∣∣2),pij=2mpi∣j+pj∣i
损失函数还是:
L = ∑ i K L ( P i ∣ ∣ Q i ) = ∑ i ( ∑ j p i j l o g ( p i j q i j ) ) L=\sum_{i}KL(P_{i}||Q_{i})=\sum_{i}(\sum_{j}p_{ij}log(\frac{p_{ij}}{q_{ij}})) L=i∑KL(Pi∣∣Qi)=i∑(j∑pijlog(qijpij))
对于高维数据 X X X,t-SNE算法流程为:
- 给定困惑度,计算得到 σ i \sigma_{i} σi,然后计算 p j ∣ i p_{j|i} pj∣i;
- 计算 p i j = p i ∣ j + p j ∣ i 2 m p_{ij}=\frac{p_{i|j}+p_{j|i}}{2m} pij=2mpi∣j+pj∣i,使用正态分布 N ( 0 , 1 0 − 4 ) N(0,10^{-4}) N(0,10−4)初始化低维空间 Y Y Y;
- 迭代 T T T次,每次迭代内容为:根据低维空间 Y Y Y计算 q i j q_{ij} qij,计算损失 L L L,计算梯度 ∂ L ∂ y i \frac{\partial L}{\partial y_{i}} ∂yi∂L,结合动量的梯度下降更新 y i y_{i} yi;
基于sklearn的t-SNE
在sklearn中已经提供了t-SNE工具,可以方便地使用t-SNE对数据进行非线性降维,实例如下:
%matplotlib inline
from sklearn.manifold import TSNE
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
#在默认设置的matplotlib中图片分辨率不是很高,可以通过设置矢量图的方式来提高图片显示质量
%config InlineBackend.figure_format = "svg"
# 加载数据集
digits = load_digits()
print(digits.target,len(digits.target))
# t-SNE降维
X_tsne = TSNE(n_components=2, random_state=33).fit_transform(digits.data)
# PCA降维
X_pca = PCA(n_components=2).fit_transform(digits.data)
对结果进行可视化:
plt.figure(figsize=(8.5, 4))
# t-SNE降维结果可视化
plt.subplot(1, 2, 1)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10)) # 设置颜色和标签的映射,与关键字参数c对应
plt.title("t-SNE")
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value')
plt.clim(-0.5, 9.5) # 设置颜色条的范围
# PCA降维结果可视化
plt.subplot(1, 2, 2)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10)) # 设置颜色和标签的映射,与关键字参数c对应
plt.title("PCA")
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value')
plt.clim(-0.5, 9.5) # 设置颜色条的范围
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show()
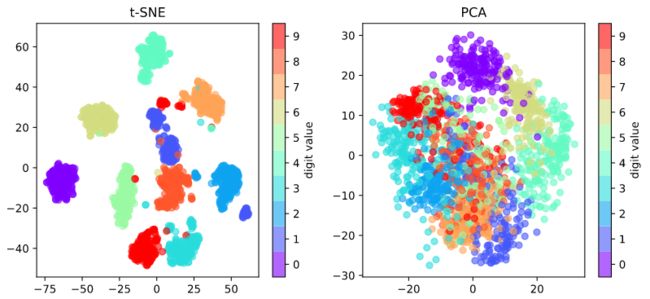
可以看出,使用非线性降维的结果明显优于线性降维