mysq 主从同步错误之 Error_code 1032 handler error HA_ERR_KEY_NOT_FOUND
方法一:
1.Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND 是主从更新时丢失数据,导致主从不一致,在从库上mysql> show slave status\G;结果如下

2.在master上,用mysqlbinlog 分析下出错的binlog日志在干什么:
/usr/local/mysql/bin/mysqlbinlog --no-defaults -v -v --base64-output=DECODE-ROWS mysql-bin.013934 | grep -A '10' 975912206
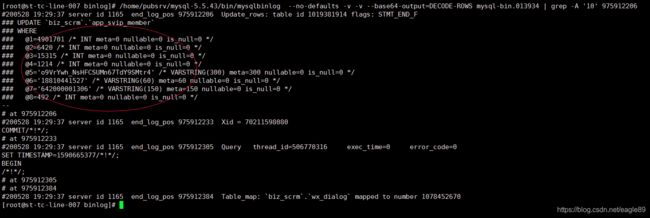
/usr/local/mysql/bin/mysqlbinlog --no-defaults -v -v --base64-output=DECODE-ROWS mysql-bin.013934 > 20200528.log
查找对应POS,发现是这么一条SQL操作
3.查询master和slave上对应的数据,主库有而从库没有
select * from log_silver where id=1019381914\G;
4.把丢失的数据在slave上填补,然后跳过报错
mysql> insert into t1 values();mysql> stop slave ;set global sql_slave_skip_counter=1;start slave;5.查看同步结果
mysql> show slave status\G;方法二:
1.如果用方法一还是不能主从同步,查询到这个错误是mysql的bug导致的
2.解决的办法:
1.最好的办法是升级数据库 保证bug不会重现。
2.利用配置参数 来躲避这个bug vi /etc/my.cnf
slave-skip-errors = 1032,xxxx,xxxx ....
3.临时逃避此次错误。
set global sql_slave_skip_counter=1; stop slave; start slave;
[MySQL] SQL_ERROR 1032解决办法
一、缘由:
在主主同步的测试环境,由于业务侧没有遵循同一时间只写一个点的原则,造成A库上删除了一条数据,B库上在同时更新这条数据。
由于异步和网络延时,B的更新event先到达A端执行,造成A端找不到这条记录,故SQL_THREAD报错1032,主从同步停止。
二、错误说明:
MySQL主从同步的1032错误,一般是指要更改的数据不存在,SQL_THREAD提取的日志无法应用故报错,造成同步失败
(Update、Delete、Insert一条已经delete的数据)。
1032的错误本身对数据一致性没什么影响,影响最大的是造成了同步失败、同步停止。
如果主主(主从)有同步失败,要第一时间查看并着手解决。因为不同步,会造成读取数据的不一致。应在第一时间恢复同步,
尽量减少对业务的影响。然后再具体分析不同步的原因,手动或者自动修复数据,并做pt-table-checksum数据一致性检查。
目前业务一般是做主主同步,主主同步由于是异步更新,存在更新冲突的问题,且很容易引起SQL ERROR 1032错误。这个应该在业务侧解决,
保证同一时间只更新数据库的一个点,类似单点写入。我们的解决办法是:写一个底层数据库调用库,可能涉及到更新冲突的操作,都调用这个库。
在配置文件里,配2个点的数据库A、B,保证一直都更新A库,如果A库不可用,就去更新B库。
另外,如果是对数据一致性要求较高的场景,比如涉及到钱,建议用PXC(强一致性、真正同步复制)。
三、解决办法:
MySQL5.6.30版本,binlog模式为ROW。
show slave status\G,可以看到如下报错:
Slave_SQL_Running: NO
Last_SQL_Errno: 1032
Last_SQL_Error: Worker 3 failed executing transaction '' at master log mysql-bin.000003, end_log_pos 440267874;
Could not execute Delete_rows event on table db_test.tbuservcbgolog; Can't find record in 'tbuservcbgolog', Error_code: 1032;
handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000003, end_log_pos 440267874从上可以看出,是SQL_THREAD线程出错,错误号码1032。是在应用delete db_test.tbuservcbgolog 表中一行数据的事件时,由于这条数据
不存在而出错。此事件在主服务器Master binlog中的位置是 mysql-bin.000003, end_log_pos 440267874。(当然可以在从服务器Slave的Relay
log中查找,具体方法见最后)
方法1:跳过错误Event
先跳过这一条错误(event),让主从同步恢复正常。(或者N条event,一条一条跳过)
stop slave;
set global sql_slave_skip_counter=1;
start slave;
方法2:跳过所有1032错误
更改my.cnf文件,在Replication settings下添加:
slave-skip-errors = 1032
并重启数据库,然后start salve。
注意:因为要重启数据库,不推荐,除非错误事件太多。
方法3:还原被删除的数据
根据错误提示信息,用mysqlbinlog找到该条数据event SQL并逆向手动执行。如delete 改成insert。
本例中,此事件在主服务器Master binlog中的位置是 mysql-bin.000003, end_log_pos 440267874。
1)利用mysqlbinlog工具找出440267874的事件
/usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 |grep -A 20 '440267874'
或者/usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 --stop-position=440267874 | tail -20
或者usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 > decode.log
( 或者加上参数-d, --database=name 来进一步过滤)
#160923 20:01:27 server id 1223307 end_log_pos 440267874 CRC32 0x134b2cbc Delete_rows: table id 319 flags: STMT_END_F
### DELETE FROM `db_99ducj`.`tbuservcbgolog`
### WHERE
### @1=10561502 /* INT meta=0 nullable=0 is_null=0 */
### @2=1683955 /* INT meta=0 nullable=0 is_null=0 */
### @3=90003 /* INT meta=0 nullable=0 is_null=0 */
### @4=0 /* INT meta=0 nullable=0 is_null=0 */
### @5='2016-09-23 17:02:24' /* DATETIME(0) meta=0 nullable=1 is_null=0 */
### @6=NULL /* DATETIME(0) meta=0 nullable=1 is_null=1 */
# at 440267874以上为检索出来的结果,事务语句为:delete from db_99ducj.tbuservcbgolog where @1=10561502 and @2=1683955 ...
其中@1 @2 @3...分别对应表tbuservcbgolog的列名,填补上即可。
我们可以逆向此SQL 将deleter 变成Insert,手动在从库上执行此Insert SQL,之后restart slave就好了。
M-S监控脚本
#!/bin/bash
#
#check_mysql_slave_replication_status
#
#
#
parasum=2
help_msg(){
cat << help
+---------------------+
+Error Cause:
+you must input $parasum parameters!
+1st : Host_IP
+2st : Host_Port
help
exit
}
[ $# -ne ${parasum} ] && help_msg #若参数不够打印帮助信息并退出
export HOST_IP=$1
export HOST_PORt=$2
MYUSER="root"
MYPASS="123456"
MYSQL_CMD="mysql -u$MYUSER -p$MYPASS"
MailTitle="" #邮件主题
Mail_Address_MysqlStatus="root@localhost.localdomain" #收件人邮箱
time1=$(date +"%Y%m%d%H%M%S")
time2=$(date +"%Y-%m-%d %H:%M:%S")
SlaveStatusFile=/tmp/salve_status_${HOST_PORT}.${time1} #邮件内容所在文件
echo "--------------------Begin at: "$time2 > $SlaveStatusFile
echo "" >> $SlaveStatusFile
#get slave status
${MYSQL_CMD} -e "show slave status\G" >> $SlaveStatusFile #取得salve进程的状态
#get io_thread_status,sql_thread_status,last_errno 取得以下状态值
IOStatus=$(cat $SlaveStatusFile|grep Slave_IO_Running|awk '{print $2}')
SQLStatus=$(cat $SlaveStatusFile|grep Slave_SQL_Running |awk '{print $2}')
Errno=$(cat $SlaveStatusFile|grep Last_Errno | awk '{print $2}')
Behind=$(cat $SlaveStatusFile|grep Seconds_Behind_Master | awk '{print $2}')
echo "" >> $SlaveStatusFile
if [ "$IOStatus" == "No" ] || [ "$SQLStatus" == "No" ];then #判断错误类型
if [ "$Errno" -eq 0 ];then #可能是salve线程未启动
$MYSQL_CMD -e "start slave io_thread;start slave sql_thread;"
echo "Cause slave threads doesnot's running,trying start slsave io_thread;start slave sql_thread;" >> $SlaveStatusFile
MailTitle="[Warning] Slave threads stoped on $HOST_IP $HOST_PORT"
elif [ "$Errno" -eq 1007 ] || [ "$Errno" -eq 1053 ] || [ "$Errno" -eq 1062 ] || [ "$Errno" -eq 1213 ] || [ "$Errno" -eq 1032 ]\
|| [ "Errno" -eq 1158 ] || [ "$Errno" -eq 1159 ] || [ "$Errno" -eq 1008 ];then #忽略此些错误
$MYSQL_CMD -e "stop slave;set global sql_slave_skip_counter=1;start slave;"
echo "Cause slave replication catch errors,trying skip counter and restart slave;stop slave ;set global sql_slave_skip_counter=1;slave start;" >> $SlaveStatusFile
MailTitle="[Warning] Slave error on $HOST_IP $HOST_PORT! ErrNum: $Errno"
else
echo "Slave $HOST_IP $HOST_PORT is down!" >> $SlaveStatusFile
MailTitle="[ERROR]Slave replication is down on $HOST_IP $HOST_PORT ! ErrNum:$Errno"
fi
fi
if [ -n "$Behind" ];then
Behind=0
fi
echo "$Behind" >> $SlaveStatusFile
#delay behind master 判断延时时间
if [ $Behind -gt 300 ];then
echo `date +"%Y-%m%d %H:%M:%S"` "slave is behind master $Bebind seconds!" >> $SlaveStatusFile
MailTitle="[Warning]Slave delay $Behind seconds,from $HOST_IP $HOST_PORT"
fi
if [ -n "$MailTitle" ];then #若出错或者延时时间大于300s则发送邮件
cat ${SlaveStatusFile} | /bin/mail -s "$MailTitle" $Mail_Address_MysqlStatus
fi
#del tmpfile:SlaveStatusFile
> $SlaveStatusFile
测试:
[root@hong shell]# sh mon_mysql_.sh
+---------------------+
+Error Cause:
+you must input 2 parameters!
+1st : Host_IP
+2st : Host_Port
[root@hong shell]# sh mon_mysql_.sh 192.168.0.112 3306 #参数需要 IP 和 端口
修改后脚本
只做了简单的整理,修正了Behind为NULL的判断,但均未测试;
应可考虑增加:
对修复执行结果的判断;多条错误的循环修复、检测、再修复?
取消SlaveStatusFile临时文件。
Errno、Behind两种告警分别发邮件,告警正文增加show slave结果原文。
增加PATH,以便加到crontab中。
考虑crontab中周期执行(加锁避免执行冲突、执行周期选择)
增加执行日志?
#!/bin/sh
# check_mysql_slave_replication_status
# 参考:http://www.tianfeiyu.com/?p=2062
Usage(){
echo Usage:
echo "$0 HOST PORT USER PASS"
}
[ -z "$1" -o -z "$2" -o -z "$3" -o -z "$4" ] && Usage && exit 1
HOST=$1
PORT=$2
USER=$3
PASS=$4
MYSQL_CMD="mysql -h$HOST -P$PORT -u$USER -p$PASS"
MailTitle="" #邮件主题
Mail_Address_MysqlStatus="root@localhost.localdomain" #收件人邮箱
time1=$(date +"%Y%m%d%H%M%S")
time2=$(date +"%Y-%m-%d %H:%M:%S")
SlaveStatusFile=/tmp/salve_status_${HOST_PORT}.${time1} #邮件内容所在文件
echo "--------------------Begin at: "$time2 > $SlaveStatusFile
echo "" >> $SlaveStatusFile
#get slave status
${MYSQL_CMD} -e "show slave status\G" >> $SlaveStatusFile #取得salve进程的状态
#get io_thread_status,sql_thread_status,last_errno 取得以下状态值
IOStatus=$(cat $SlaveStatusFile|grep Slave_IO_Running|awk '{print $2}')
SQLStatus=$(cat $SlaveStatusFile|grep Slave_SQL_Running |awk '{print $2}')
Errno=$(cat $SlaveStatusFile|grep Last_Errno | awk '{print $2}')
Behind=$(cat $SlaveStatusFile|grep Seconds_Behind_Master | awk '{print $2}')
echo "" >> $SlaveStatusFile
if [ "$IOStatus" = "No" -o "$SQLStatus" = "No" ];then
case "$Errno" in
0)
# 可能是slave未启动
$MYSQL_CMD -e "start slave io_thread;start slave sql_thread;"
echo "Cause slave threads doesnot's running,trying start slsave io_thread;start slave sql_thread;" >> $SlaveStatusFile
;;
1007|1053|1062|1213|1032|1158|1159|1008)
# 忽略这些错误
$MYSQL_CMD -e "stop slave;set global sql_slave_skip_counter=1;start slave;"
echo "Cause slave replication catch errors,trying skip counter and restart slave;stop slave ;set global sql_slave_skip_counter=1;slave start;" >> $SlaveStatusFile
MailTitle="[Warning] Slave error on $HOST:$PORT! ErrNum: $Errno"
;;
*)
echo "Slave $HOST:$PORT is down!" >> $SlaveStatusFile
MailTitle="[ERROR]Slave replication is down on $HOST:$PORT! Errno:$Errno"
;;
esac
fi
if [ "$Behind" = "NULL" -o -z "$Behind" ];then
Behind=0
fi
echo "Behind:$Behind" >> $SlaveStatusFile
#delay behind master 判断延时时间
if [ $Behind -gt 300 ];then
echo `date +"%Y-%m%d %H:%M:%S"` "slave is behind master $Bebind seconds!" >> $SlaveStatusFile
MailTitle="[Warning]Slave delay $Behind seconds,from $HOST $PORT"
fi
if [ -n "$MailTitle" ];then #若出错或者延时时间大于300s则发送邮件
cat ${SlaveStatusFile} | /bin/mail -s "$MailTitle" $Mail_Address_MysqlStatus
fi
#del tmpfile:SlaveStatusFile
> $SlaveStatusFile
check mysql slave状态并跳过相应错误(守护模式)
|
|
3分钟解决MySQL 1032主从错误
Part1:写在最前
1032错误----现在生产库中好多数据,在从库误删了,生产库更新后找不到了,现在主从不同步了,再跳过错误也没用,因为没这条,再更新还会报错
解决方案
Part1:临时方案
mysql> stop slave;
Query OK, 0 rows
affected (0.00 sec)
mysql> set global sql_slave_skip_counter=1;
Query OK, 0 rows
affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows
affected (0.00 sec)
Part2:永久方案
end_log_pos 有了它,根据pos值,直接就能找到,找到delete那条数据,反做(变成insert)
故障模拟
HE1从库误删
mysql> delete from helei where id=3;
Query OK, 1 row
affected (0.29 sec)
mysql> select * from helei;
+----+------+
| id | text |
+----+------+
| 1 | aa
|
| 2 | bb
|
| 4 | ee
|
| 5 | ff
|
| 6 | gg
|
| 7 | hh
|
+----+------+
6 rows in set (0.00
sec)
mysql> show slave status\G;
***************************
1. row ***************************
Slave_IO_State: Waiting for
master to send event
Master_Host: 192.168.1.250
Master_User: mysync
Master_Port: 2503306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 3711
Relay_Log_File:
HE1-relay-bin.000007
Relay_Log_Pos: 484
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
此时从库状态是正常的,但一旦主库对该条记录进行操作
HE3主库更新从库刚刚误删的数据
mysql> update helei set text='ccc' where id=3;
Query OK, 1 row
affected (0.01 sec)
Rows matched: 1 Changed: 1
Warnings: 0
mysql> select * from helei;
+----+------+
| id | text |
+----+------+
| 1 | aa
|
| 2 | bb
|
| 3 | ccc
|
| 4 | ee
|
| 5 | ff
|
| 6 | gg
|
| 7 | hh
|
+----+------+
7 rows in set (0.00
sec)
HE1从库报错
mysql> show slave status\G;
***************************
1. row ***************************
Slave_IO_State: Waiting for
master to send event
Master_Host: 192.168.1.250
Master_User: mysync
Master_Port: 2503306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 3918
Relay_Log_File:
HE1-relay-bin.000007
Relay_Log_Pos: 484
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not
execute Update_rows event on table test.helei; Can't find record in 'helei',
Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log
mysql-bin.000005, end_log_pos 3887
Skip_Counter: 0
Exec_Master_Log_Pos: 3711
Relay_Log_Space: 1626
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert:
No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.helei;
Can't find record in 'helei', Error_code: 1032; handler error
HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000005, end_log_pos 3887(这个mysql-bin.000005,end_log_pos
3887是主库的)
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2503306
Master_UUID:
f7c96432-f665-11e5-943f-000c2967a454
Master_Info_File:
/data/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 160331 09:25:02
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00
sec)
此时主从又不同步了,如果还去执行跳过错误操作,主从恢复同步,而且状态均为yes,但!这并不能解决该问题,如果主库又更新该条记录,那么还是会报相同错误,而且pos号还会变,这就导致了恢复时你不知道前一条的pos号,导致丢失数据。
mysql> stop slave;
Query OK, 0 rows
affected (0.00 sec)
mysql> set global sql_slave_skip_counter=1;
Query OK, 0 rows
affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows
affected (0.00 sec)
mysql> select * from helei;
+----+--------+
| id | text |
+----+--------+
| 1 | aa
|
| 2 | bb
|
| 4 | ee
|
| 5 | ff
|
| 6 | gg
|
| 7 | hh
|
| 8 | helei1 |
+----+--------+
7 rows in set (0.00 sec)
mysql> show slave status\G;
***************************
1. row ***************************
Slave_IO_State: Waiting for
master to send event
Master_Host: 192.168.1.250
Master_User: mysync
Master_Port: 2503306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 4119
Relay_Log_File:
HE1-relay-bin.000008
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
这里虽然通过跳过错误达到恢复主从同步,但如果主库又对该条记录更新
mysql> update helei set text='cccc' where id=3;
Query OK, 1 row
affected (0.00 sec)
mysql> show slave status\G;
***************************
1. row ***************************
Slave_IO_State: Waiting for
master to send event
Master_Host: 192.168.1.250
Master_User: mysync
Master_Port: 2503306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 4328
Relay_Log_File:
HE1-relay-bin.000008
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows event on table test.helei;
Can't find record in 'helei', Error_code: 1032; handler error
HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000005, end_log_pos 4297
Skip_Counter: 0
Exec_Master_Log_Pos: 4119
Relay_Log_Space: 1435
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert:
No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.helei;
Can't find record in 'helei', Error_code: 1032; handler error
HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000005, end_log_pos 4297
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2503306
Master_UUID:
f7c96432-f665-11e5-943f-000c2967a454
Master_Info_File:
/data/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 160331 09:33:34
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
如何快速解决MySQL 1032 主从错误
GTID跳过SQL错误的脚本
#!/bin/bash
#Author:wwa
USER=
PWD=
HOST=
PORT=
REP=
REPPWD=
REPH=
REPP=
GTID=$2
GTID_START=$3
GTID_END=$4
GTID_PURGE(){
echo "GTID_UUID:$GTID, GTID_START:$GTID_START, GTID_END=%GTID_END"
mysql -u$USER -p$PWD -h$HOST -P$PORT -e "stop slave;reset slave;reset master;set global gtid_purged='$GTID:$GTID_START-$GTID_END';CHANGE MASTER TO MASTER_HOST='$REPH', MASTER_PORT=$REPP, MASTER_USER='$REP',MASTER_PASSWORD='$REPPWD', master_auto_position=1;start slave;"
sleep 1
mysql -u$USER -p$PWD -h$HOST -P$PORT -e "show slave status\G;"
}
GTID_SKIP(){
mysql -u$USER -p$PWD -h$HOST -P$PORT -e "stop slave;set session gtid_next='$GTID:$GTID_START';begin;commit;set session gtid_next="AUTOMATIC";start slave;"
}
case "$1" in
GTID_PURGE)
echo "Start GTID_PURGE, transaction in $GTID between $GTID_START-$GTID_END will be skipped......"
GTID_PURGE
echo "GTID_PURGE success......"
;;
GTID_SKIP)
echo "Start GTID_SKIP, transaction $GTID:$GTID_START will be skipped......"
GTID_SKIP
echo "GTID_SKIP success......"
;;
*)
echo $"Usage: $0 {GTID_PURGE args1 args2 args3|GTID_SKIP args1 args2}"
exit 1
;;
esac
GTID_PURGE() 当同步发生大量的错误时,使用flush table with read lock锁住主库,记录GTID的事务编号(最后那个,例如后面示例里面的142787),然后数据同步到从库,在参数中加上UUID(空格)起始事务编号(空格)中止事务编号
原理:purge掉master log中,同步数据的SCN之前的事务,从同步时间点以后开始读取binlog; 这样做的好处是不用去master操作,清理binlog(手抖清理了其他东西就不好了~)
GTID_SKIP() 当发生少量的错误时,使用show slave status\G;找到UUID和出错的事务编号,参数中加上 UUID(空格)事务编号
原理:生成一个空事务来跳过原本出错的事务,然后继续往下同步
关于如何判断GTID_SKIP()需要跳过的事务编号:
假设出错时,slave status是这个样子,
箭头所指的代表从主库拉去的日志中,包含哪些事务(以编号的形式);
方框所指的代表从库现在执行了哪些事务;这里的意思就是从库已经执行了编号1到编号139595的事务
如果出错了,说明139596事务出错了,这时候执行脚本里的事务编号写上139596就行
实际使用效果如图(截图时间截晚了,事务ID对不上,不过意思表达清楚了就好~)
结语:任何发生于数据库上的操作一定要三思而后回车,血的教训数不胜数,所以验证无误的固定操作,用脚本来实现是个不错的选择。
GTID 跳过脚本
跳过单个error
STOP SLAVE;
SET gtid_next = '3b977b7e-ed28-11e7-a8ff-b4969113b678:138609841';
BEGIN;COMMIT;
SET gtid_next = 'AUTOMATIC';
START SLAVE;
show slave status \G;
select * from performance_schema.replication_applier_status_by_worker;
同步事物工作状态查询
(root@localhost) 12:13:57 [(none)]> select * from performance_schema.replication_applier_status_by_worker;
+--------------+-----------+-----------+---------------+------------------------------------------------+-------------------+--------------------+----------------------+
| CHANNEL_NAME | WORKER_ID | THREAD_ID | SERVICE_STATE | LAST_SEEN_TRANSACTION | LAST_ERROR_NUMBER | LAST_ERROR_MESSAGE | LAST_ERROR_TIMESTAMP |
+--------------+-----------+-----------+---------------+------------------------------------------------+-------------------+--------------------+----------------------+
| | 1 | 1800788 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144139359 | 0 | | 0000-00-00 00:00:00 |
| | 2 | 1800789 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144139248 | 0 | | 0000-00-00 00:00:00 |
| | 3 | 1800790 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144138411 | 0 | | 0000-00-00 00:00:00 |
| | 4 | 1800791 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144128311 | 0 | | 0000-00-00 00:00:00 |
| | 5 | 1800792 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144108749 | 0 | | 0000-00-00 00:00:00 |
| | 6 | 1800793 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144108752 | 0 | | 0000-00-00 00:00:00 |
| | 7 | 1800794 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144108746 | 0 | | 0000-00-00 00:00:00 |
| | 8 | 1800795 | ON | 3b977b7e-ed28-11e7-a8ff-b4969113b678:144108747 | 0 | | 0000-00-00 00:00:00 |
+--------------+-----------+-----------+---------------+------------------------------------------------+-------------------+--------------------+----------------------+
8 rows in set (0.02 sec)
GTID_error 跳过脚本
#!/bin/bash
pass='iforgot'
#sql21=`mysql -uroot -p${pass} -e "show slave status\G;" 2>/dev/null|grep -v Last_Error | grep 'executing transaction'| awk '{print $21}'`
#Errno=`mysql -uroot -p${pass} -e "show slave status\G;" |grep 'Last_SQL_Errno' | awk -F ":" '{print $2}'`
#echo $sql21
#echo $Errno
for((i=1;i<100000;i++))
do
sql21=`mysql -uroot -p${pass} -e "show slave status\G;" 2>/dev/null|grep -v Last_Error | grep 'executing transaction'| awk '{print $21}'`
Errno=`mysql -uroot -p${pass} -e "show slave status\G;" 2>/dev/null|grep 'Last_SQL_Errno' | awk -F ":" '{print $2}'`
SBM=`mysql -uroot -p${pass} -e "show slave status\G;" 2>/dev/null|grep 'Seconds_Behind_Master' | awk -F ":" '{print $2}'`
#echo $sql21
#echo $Errno
#sleep 0.5
if [ $Errno -eq 1061 ] || [$Errno -eq 1062 ] || [$Errno -eq 1217 ] || [$Errno -eq 1050 ]
then
echo ${1} && echo $sql21 && echo $Errno
mysql -uroot -p${pass} -e "STOP SLAVE;SET @@SESSION.GTID_NEXT =${sql21};BEGIN; COMMIT;SET @@SESSION.GTID_NEXT = AUTOMATIC;START SLAVE;"
# mysql -uroot -p${pass} -e "STOP SLAVE;SET @@SESSION.GTID_NEXT =${sql21};BEGIN; COMMIT;SET @@SESSION.GTID_NEXT = AUTOMATIC;START SLAVE;SHOW SLAVE STATUS \G;"
echo mysql -uroot -p${pass} -e "STOP SLAVE;SET @@SESSION.GTID_NEXT =${sql21};BEGIN; COMMIT;SET @@SESSION.GTID_NEXT = AUTOMATIC;START SLAVE;SHOW SLAVE STATUS \G;"
else
sleep 3
echo "同步延迟 ${SBM} 秒"
fi
done
https://www.jb51.net/article/109107.htm
原脚本
#!/bin/bash
#
#check_mysql_slave_replication_status
#
#
#
parasum=2
help_msg(){
cat <<
help
+---------------------+
+Error
Cause:
+you
must input $parasum parameters!
+1st
: Host_IP
+2st
: Host_Port
help
exit
}
[
$#
-ne ${parasum} ] && help_msg #若参数不够打印帮助信息并退出
export HOST_IP=$1
export HOST_PORt=$2
MYUSER="root"
MYPASS="123456"
MYSQL_CMD="mysql
-u$MYUSER -p$MYPASS"
MailTitle="" #邮件主题
Mail_Address_MysqlStatus="root@localhost.localdomain" #收件人邮箱
time1=$(date +"%Y%m%d%H%M%S")
time2=$(date +"%Y-%m-%d
%H:%M:%S")
SlaveStatusFile=/tmp/salve_status_${HOST_PORT}.${time1}
#邮件内容所在文件
echo "--------------------Begin
at: "$time2
> $SlaveStatusFile
echo "" >>
$SlaveStatusFile
#get
slave status
${MYSQL_CMD}
-e "show
slave status\G" >>
$SlaveStatusFile #取得salve进程的状态
#get
io_thread_status,sql_thread_status,last_errno 取得以下状态值
IOStatus=$(cat $SlaveStatusFile|grep Slave_IO_Running|awk '{print
$2}')
SQLStatus=$(cat $SlaveStatusFile|grep Slave_SQL_Running
|awk '{print
$2}')
Errno=$(cat $SlaveStatusFile|grep Last_Errno
| awk '{print
$2}')
Behind=$(cat $SlaveStatusFile|grep Seconds_Behind_Master
| awk '{print
$2}')
echo "" >>
$SlaveStatusFile
if [
"$IOStatus" ==
"No" ]
|| [ "$SQLStatus" ==
"No" ];then #判断错误类型
if [
"$Errno" -eq 0
];then #可能是salve线程未启动
$MYSQL_CMD
-e "start
slave io_thread;start slave sql_thread;"
echo "Cause
slave threads doesnot's running,trying start slsave io_thread;start slave sql_thread;" >>
$SlaveStatusFile
MailTitle="[Warning]
Slave threads stoped on $HOST_IP $HOST_PORT"
elif [
"$Errno" -eq 1007
] || [ "$Errno" -eq 1053
] || [ "$Errno" -eq 1062
] || [ "$Errno" -eq 1213
] || [ "$Errno" -eq 1032
]\
||
[ "Errno" -eq 1158
] || [ "$Errno" -eq 1159
] || [ "$Errno" -eq 1008
];then #忽略此些错误
$MYSQL_CMD
-e "stop
slave;set global sql_slave_skip_counter=1;start slave;"
echo "Cause
slave replication catch errors,trying skip counter and restart slave;stop slave ;set global sql_slave_skip_counter=1;slave start;" >>
$SlaveStatusFile
MailTitle="[Warning]
Slave error on $HOST_IP $HOST_PORT! ErrNum: $Errno"
else
echo "Slave
$HOST_IP $HOST_PORT is down!" >>
$SlaveStatusFile
MailTitle="[ERROR]Slave
replication is down on $HOST_IP $HOST_PORT ! ErrNum:$Errno"
fi
fi
if [
-n "$Behind" ];then
Behind=0
fi
echo "$Behind" >>
$SlaveStatusFile
#delay
behind master 判断延时时间
if [
$Behind -gt 300 ];then
echo `date +"%Y-%m%d
%H:%M:%S"`
"slave
is behind master $Bebind seconds!" >>
$SlaveStatusFile
MailTitle="[Warning]Slave
delay $Behind seconds,from $HOST_IP $HOST_PORT"
fi
if [
-n "$MailTitle" ];then #若出错或者延时时间大于300s则发送邮件
cat ${SlaveStatusFile}
| /bin/mail -s
"$MailTitle" $Mail_Address_MysqlStatus
fi
#del
tmpfile:SlaveStatusFile
>
$SlaveStatusFile
修改后脚本
只做了简单的整理,修正了Behind为NULL的判断,但均未测试;
应可考虑增加:
对修复执行结果的判断;多条错误的循环修复、检测、再修复?
取消SlaveStatusFile临时文件。
Errno、Behind两种告警分别发邮件,告警正文增加show slave结果原文。
增加PATH,以便加到crontab中。
考虑crontab中周期执行(加锁避免执行冲突、执行周期选择)
增加执行日志?
#!/bin/sh
#
check_mysql_slave_replication_status
#
参考:http://www.tianfeiyu.com/?p=2062
Usage(){
echo Usage:
echo "$0
HOST PORT USER PASS"
}
[
-z "$1" -o
-z "$2" -o
-z "$3" -o
-z "$4" ]
&& Usage && exit 1
HOST=$1
PORT=$2
USER=$3
PASS=$4
MYSQL_CMD="mysql
-h$HOST -P$PORT -u$USER -p$PASS"
MailTitle="" #邮件主题
Mail_Address_MysqlStatus="root@localhost.localdomain" #收件人邮箱
time1=$(date +"%Y%m%d%H%M%S")
time2=$(date +"%Y-%m-%d
%H:%M:%S")
SlaveStatusFile=/tmp/salve_status_${HOST_PORT}.${time1}
#邮件内容所在文件
echo "--------------------Begin
at: "$time2
> $SlaveStatusFile
echo "" >>
$SlaveStatusFile
#get
slave status
${MYSQL_CMD}
-e "show
slave status\G" >>
$SlaveStatusFile #取得salve进程的状态
#get
io_thread_status,sql_thread_status,last_errno 取得以下状态值
IOStatus=$(cat $SlaveStatusFile|grep Slave_IO_Running|awk '{print
$2}')
SQLStatus=$(cat $SlaveStatusFile|grep Slave_SQL_Running
|awk '{print
$2}')
Errno=$(cat $SlaveStatusFile|grep Last_Errno
| awk '{print
$2}')
Behind=$(cat $SlaveStatusFile|grep Seconds_Behind_Master
| awk '{print
$2}')
echo "" >>
$SlaveStatusFile
if [
"$IOStatus" =
"No" -o
"$SQLStatus" =
"No" ];then
case "$Errno" in
0)
#
可能是slave未启动
$MYSQL_CMD
-e "start
slave io_thread;start slave sql_thread;"
echo "Cause
slave threads doesnot's running,trying start slsave io_thread;start slave sql_thread;" >>
$SlaveStatusFile
;;
1007|1053|1062|1213|1032|1158|1159|1008)
#
忽略这些错误
$MYSQL_CMD
-e "stop
slave;set global sql_slave_skip_counter=1;start slave;"
echo "Cause
slave replication catch errors,trying skip counter and restart slave;stop slave ;set global sql_slave_skip_counter=1;slave start;" >>
$SlaveStatusFile
MailTitle="[Warning]
Slave error on $HOST:$PORT! ErrNum: $Errno"
;;
*)
echo "Slave
$HOST:$PORT is down!" >>
$SlaveStatusFile
MailTitle="[ERROR]Slave
replication is down on $HOST:$PORT! Errno:$Errno"
;;
esac
fi
if [
"$Behind" =
"NULL" -o
-z "$Behind" ];then
Behind=0
fi
echo "Behind:$Behind" >>
$SlaveStatusFile
#delay
behind master 判断延时时间
if [
$Behind -gt 300 ];then
echo `date +"%Y-%m%d
%H:%M:%S"`
"slave
is behind master $Bebind seconds!" >>
$SlaveStatusFile
MailTitle="[Warning]Slave
delay $Behind seconds,from $HOST $PORT"
fi
if [
-n "$MailTitle" ];then #若出错或者延时时间大于300s则发送邮件
cat ${SlaveStatusFile}
| /bin/mail -s
"$MailTitle" $Mail_Address_MysqlStatus
fi
#del
tmpfile:SlaveStatusFile
>
$SlaveStatusFile