使用python和pyqt5轻松上手人脸识别系统(含代码)
使用python和pyqt5轻松上手人脸识别系统(含代码)
- 一、 环境配置
-
- 1.1 python环境配置
-
- 1.1.1 安装 anaconda
- 1.1.2 安装pycharm
- 1.1.3 配置pip源
- 1.2 mysql数据库安装
- 1.3 相关依赖安装
- 二、 人脸识别模块测试
-
- 2.1 使用opencv从摄像头中读取图片
-
- 2.1.1 opencv读取图片/摄像头的视频帧
- 2.1.2 opencv将图像保存为gif和视频
- 2.2 使用不同人脸识别算法进行检测和识别
-
- 2.2.1 模型加载
- 2.2.2 读取图片
- 2.2.3 人脸检测和关键点提取
- 2.2.4 描述子匹配
- 三、 基于sqlite3的数据库设计
-
- 3.1 简单定义数据库类
-
- 3.1.1 CardRecord 打卡信息表
- 3.1.2 Course 课程表
- 3.1.3 Relation 选课关系表
- 3.1.4 Student 学生表
- 3.2 封装常用的sql查询到数据库类成员函数中
- 四、 基于PyQt5的GUI设计
-
- 4.1 框架和文件夹结构设计
- 4.2 开始界面设计
- 4.3 验证界面设计
- 4.4 自定义的listwidget设计
- 4.4 主界面设计
- 4.5 如何有效组织不同的UI界面类
- 五、效果展示
-
- 5.1 检测和识别效果展示
- 5.2 数据库导出和查看
- 六、代码获取和下载
最近在做一个人脸识别考勤系统,已经总结和记录了大部分内容,算是比较完善啦!后续把剩下的搞完,感兴趣的同学可以关注一下哦~ 文末给出了代码获取方式,请自行获取食用~
B站:马上就更!!!_bilibili
CSDN:使用python和pyqt5轻松上手人脸识别系统(含代码)_百年后封笔-CSDN博客
公众号:百年后封笔
一、 环境配置
这里我们使用的环境主要包括一下三个方面:
- 首先是开发所需要的
python环境、包管理工具和IDE等。这里我们主要需要安装的就是anaconda和pycharm专业版,以及pip镜像源。需要注意的是,pycharm专业版是付费软件,如果你不想后续查看数据库的详细信息等,那么社区版也足够了,但专业版是可以通过学生作科研用途申请的。 - 本项目使用到了
sqlite3数据库,但我们最好也配置mysql数据库,然后方便在pycharm专业版中查看数据库的表和信息。 - 最后是人脸识别和开发过程中依赖的python包,后面我们展示了几种使用python进行人脸识别的方法,除了
opencv-python,其他的基本都需要dlib这个库,后面我会说具体所依赖的库,不过对于No Module Error的情况,直接pip install xxx就也可以轻松解决。
1.1 python环境配置
这里我们只提供windows下python环境的配置方法,其实都大同小异。
1.1.1 安装 anaconda
anaconda是一个python的包管理软件,可以方便的管理你的虚拟环境和依赖的包
-
首先去官网下载安装包
-
按照要求一步步进行安装即可,一直next就行。如果不清楚怎么安装的话,可以直接搜一下
anaconda的安装方法,参考其他博主的详细安装指导,这里我们不再赘述。
-
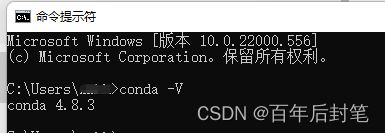
检查anaconda是否安装成功
打开cmd,输入conda -V,一般会有两种情况,下面这种就是安装好了的。
如果报错了,那么需要你将anaconda的安装路径先找到,比如,是在C:\Users\xxx\anaconda3,那么接着你就需要在你的系统环境变量里面,把下面几个路径加入到path里面,也就是把anaconda的bin和Scripts路径加入到环境变量里面去,如下:
C:\Users\xxx\anaconda3\bin
C:\Users\xmhh\anaconda3\Scripts
C:\Users\xmhh\anaconda3


操作完之后,再检验一下conda有没有安装好就行了,一般出问题就是环境变量没加入进去,其他没啥问题。
- 下面罗列一些常用的conda命令
# 建立新环境
conda create -n new env_name python=3.8
# conda初始化
conda init
# 激活虚拟环境
conda activate env_name 或者 activate env_name
# 查看虚拟环境
conda env list
# 删除虚拟环境
conda remove -n env_name --all
1.1.2 安装pycharm
- 去官网下载安装包
- 需要注意的是,左边专业版安装包可以免费用30天,或者可以认证一下教育优惠延期用,右边社区版是免费的。专业版可以查看数据库,远程连接等,功能更加全面,社区版也勉强够用吧。
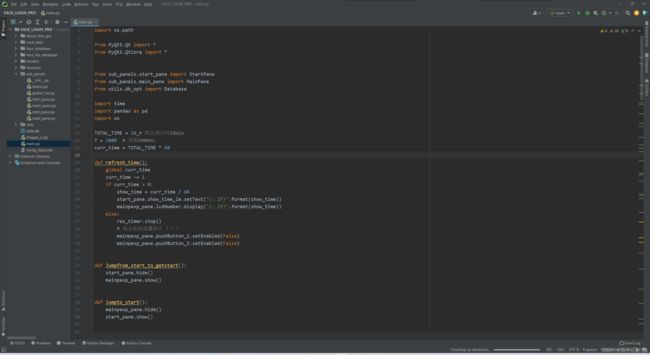
- 安装的话,就也是一直next就行了,没什么好说的。好了并打开项目后的效果如下:
1.1.3 配置pip源
由于我们后续需要配置虚拟环境,安装相关依赖包,国内下载python非常慢,因此我们需要先配置一下pip镜像源,具体做法如下:
- 在
C:\Users\xxx中创建一个名为pip的文件夹,然后在里面创建一个pip.ini文件,注意后续需要修改这个文件内容,因此可以先把名字改成pip.txt,后续再改成pip.ini

- 修改
pip.ini文件内容,然后保存就可以了,如下:如果还不是很明白的,可以参考一下其他博主的,例如这个教程
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
- 后面pip install
1.2 mysql数据库安装
mysql数据库很多时候会用到,所以最好是安装配置一下,下面给一个大致的安装教程
-
下载mysql数据库的安装包
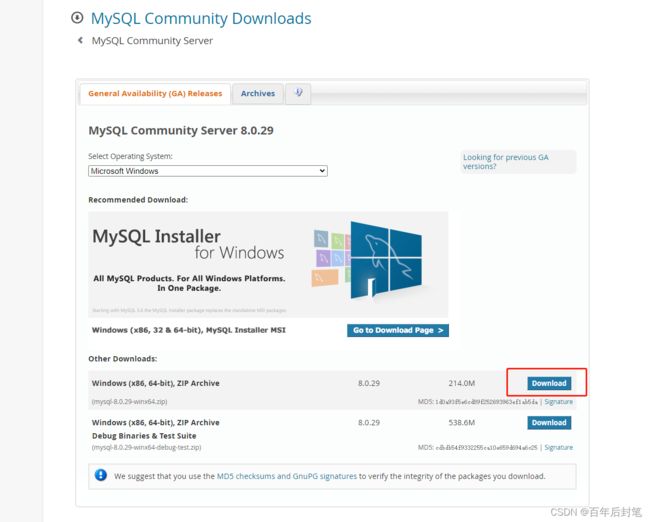
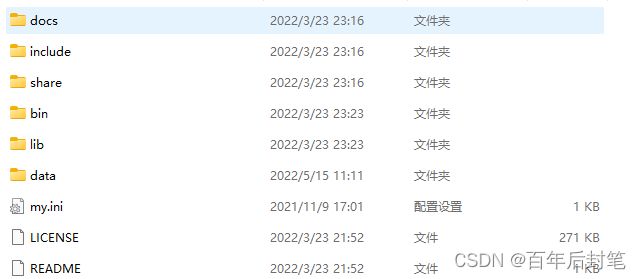
如上图,选第一个就行啦,解压之后,就ok,如下图,最开始是没有这个my.ini和data的好像,不过不重要,官网下下来解压就完事了,后面再配。
-
配置环境变量,也就是mysql文件夹下的
bin文件夹
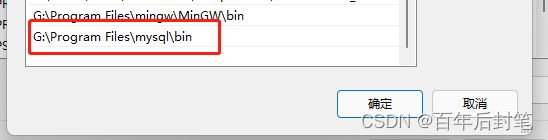
-
在mysqll文件根目录下创建并配置
my.ini
my.ini的配置信息如下,注意把里面的路径设置成你自己的就可以了,其他不用改。
[mysqld]
explicit_defaults_for_timestamp=true
character-set-server=utf8mb4
#绑定IPv4和3306端口
bind-address = 0.0.0.0
port = 3306
sql_mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
default_storage_engine=innodb
innodb_buffer_pool_size=1000M
innodb_log_file_size=50M
# 设置mysql的安装目录
basedir=G:\Program Files\mysql
# 设置mysql数据库的数据的存放目录
datadir=G:\Program Files\mysql\data
# 允许最大连接数
max_connections=200
# skip_grant_tables
[mysql]
default-character-set=utf8mb4
[mysql.server]
default-character-set=utf8mb4
[mysql_safe]
default-character-set=utf8mb4
[client]
port = 3306
default-character-set=utf8mb4
plugin-dir=G:\Program Files\mysql\lib\plugin
- 打开
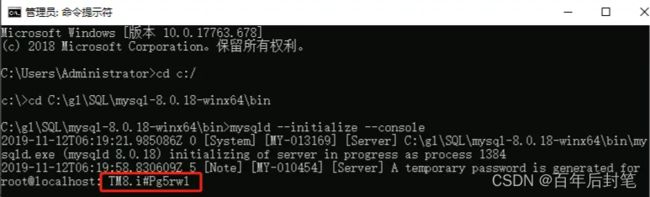
cmd,输入mysqld --initialize完成初始化。在根目录就出现了data文件夹,这下就齐活了。注意初始化的时候,会有一个初始密码,记得记一下,后面登录和修改密码需要用到。
- 相关使用
# 安装mysql服务
mysqld -install
# 启动mysql服务
net start mysql
# 登录数据库
mysql -u root -p
# 修改 root 密码为 root123
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root123';
1.3 相关依赖安装
这里我们介绍一下本次项目所需要的依赖和环境吧。这里我们主要需要用到:首先,numpy和pandas是数据处理的基本库;其次,一些图像处理的python库,cv2和Pillow;接着,gui的库,pyqt5;最后人脸识别的库,cmake, dlib和face_recognition。基本上就是这些吧,如果有问题的话,大家根据报错再安装吧。下面给出一般配置步骤:
- 首先在你的项目路径下
cmd中使用conda命令创建虚拟环境,然后激活一下
# 创建虚拟环境 名字是face_login python版本是3.8
conda create -n new face_login python=3.8
# 激活虚拟环境
activate face_login 或者 conda activate face_login
- 在你的项目路径下创建一个文件名叫做
requirements.txt,在里面填写如下信息,版本上似乎是没有什么大的问题的,按顺序装就可以了,dlib装起来可能会有些慢如果嫌太慢的话,也可以最后单独使用pip install dlib去安装,但是需要先pip安装cmake包,不然会出错的。
numpy
pandas
pyqt5
cmake
opencv-python
Pillow
dlib
face_recognition
- 运行
pip install -r requirements.txt安装依赖
二、 人脸识别模块测试
作为人脸识别系统中最重要的模块,我们需要首先对人脸识别的功能进行测试,然后将其作为一个模块嵌入到我们的系统中即可。人脸识别功能按照流程主要分为两步,首先是读取图片(本地文件夹或者摄像头);其次是使用人脸识别算法(基于opencv的dnn或者其他深度学习框架的人脸识别模型)进行人脸检测和识别。下面分别就上述的两部分来分别说明。
2.1 使用opencv从摄像头中读取图片
从opencv中读取图片主要分为三种,下面分别给出三种方式的代码:
2.1.1 opencv读取图片/摄像头的视频帧
- 读取单张图片
# 单张图片读取
import cv2
img_filename = 'demo.png'
img = cv2.imread(img_filename, cv2.IMREAD_COLOR) # 彩色图像
# img = cv2.imread(img_filename, cv2.IMREAD_GRAYSCALE) # 灰度图像
- 读取文件夹中的图片
# 从文件夹读取
import glob
import cv2
img_dir = r'path/to/your/database'
for img_filename in glob.glob(img_dir + '/*.jpg' ) # 针对jpg图片
img = cv2.imread(img_filename, cv2.IMREAD_COLOR)
- 读取摄像头中的视频帧
import cv2
def get_cap():
cap = cv2.VideoCapture(0)
return cap
cap = get_cap() # 获取摄像头视频流
id = 1
while True:
ret, frame = cap.read()
if cv2.waitKey(1) == ord('q'):#按Q退出
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (480, 480))
# img = np.array(img)
break
else:
cv2.imshow('win', frame)
cv2.waitKey(10) # 可以理解为控制帧率
2.1.2 opencv将图像保存为gif和视频
有的时候,我们甚至还需要展示,那么就需要一个视频流保存为视频文件、图片转gif或者图像转视频的需求,下面同样给出这几种操作的示例代码:
- 视频流保存视频文件参考
需要注意的是,尽量按照摄像头的编码来保存视频,否则可能会出问题。
cv2.VideoWriter_fourcc('I','4','2','0'):YUV编码,4:2:0色度子采样。这种编码广泛兼容,但会产生大文件。文件扩展名应为.avi。
cv2.VideoWriter_fourcc('P','I','M','1'):MPEG-1编码。文件扩展名应为.avi。
cv2.VideoWriter_fourcc('X','V','I','D'):MPEG-4编码。如果要限制结果视频的大小,这是一个很好的选择。文件扩展名应为.avi。
cv2.VideoWriter_fourcc('m', 'p', '4', 'v'):较旧的MPEG-4编码。如果要限制结果视频的大小,这是一个很好的选择。文件扩展名应为.m4v。
cv2.VideoWriter_fourcc('X','2','6','4'):较新的MPEG-4编码。如果你想限制结果视频的大小,这可能是最好的选择。文件扩展名应为.mp4。
cv2.VideoWriter_fourcc('T','H','E','O'):这个选项是Ogg Vorbis。文件扩展名应为.ogv。
cv2.VideoWriter_fourcc('F','L','V','1'):此选项为Flash视频。文件扩展名应为.flv。
def save_video(video_name):
cap = cv2.VideoCapture(video_name)
# setting
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取原视频的宽
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取原视频的搞
fps = int(cap.get(cv2.CAP_PROP_FPS)) # 帧率
fourcc = int(cap.get(cv2.CAP_PROP_FOURCC)) # 视频的编码
# 定义视频保存的输出属性
out = cv2.VideoWriter('out.mp4', fourcc, fps, (width, height))
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('fame', frame)
key = cv2.waitKey(25)
out.write(frame)
if key == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()
- 图片转gif
import cv2
import imageio
def save_gif(video_name):
cap = cv2.VideoCapture(video_name)
# 定义视频保存的输出属性
out = []
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('fame', frame)
key = cv2.waitKey(15)
if not ret: continue
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
out.append(cv2.resize(frame, (w//2, h//2))) # 适当缩放,防止gif过大
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
imageio.mimsave('demo.gif', out, fps=30) # 调整保存的帧率
- 图片转视频
import cv2
import os
def img2video(img_dir, save_name):
# setting
width = 1080 # 获取原视频的宽
height = 720 # 获取原视频的搞
fps = 30 # 帧率
fourcc = cv2.VideoWriter_fourcc(*'DIVX') # 视频的编码
# 定义视频保存的输出属性
out = cv2.VideoWriter(save_name, fourcc, fps, (width, height))
for r, ds, fs in os.walk(img_dir):
for f in fs:
file_name = os.path.join(r, f)
img = cv2.imread(file_name)
out.write(img)
return
2.2 使用不同人脸识别算法进行检测和识别
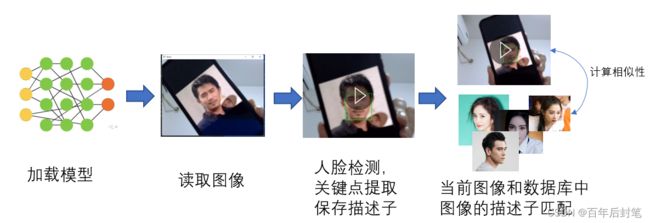
人脸识别最简单的就是使用dlib框架,其检测流程如下图所示:
2.2.1 模型加载
这里需要加载三个模型,分别是人脸检测模型、人脸关键点预测模型、描述子特征计算模型,人脸检测模型直接调用dlib的dlib.get_frontal_face_detector()即可,另外两个可以直接从dlib的官网下载对应的两个模型:
- shape_predictor_68_face_landmarks.dat
- dlib_face_recognition_resnet_model_v1.dat
2.2.2 读取图片
读取图片直接使用2.1所讲的就可以了,不再赘述。
2.2.3 人脸检测和关键点提取
import dlib
def detect_img():
cap = cv2.VideoCapture(0)
detector = dlib.get_frontal_face_detector() # 检测模型
path_pre = "../models/shape_predictor_68_face_landmarks.dat" # 68点模型
pre = dlib.shape_predictor(path_pre)
# 定义视频保存的输出属性
out = []
while cap.isOpened():
ret, frame = cap.read()
key = cv2.waitKey(15)
if not ret: continue
rects = detector(frame, 0)
for obj in rects: # 绘制所有的人脸
# print(dir(obj))
pt1, pt2 = rect2bb(obj)
cv2.rectangle(frame, pt1, pt2, (0, 255, 0), 2)
shapes = pre(frame, obj) # 对当前的人脸框做68点特征点预测
shapes = shape_to_np(shapes)
for (x, y) in shapes:
cv2.circle(frame, (x, y), 1, (255, 0, 0), -1)
cv2.imshow('fame', frame)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, c = frame.shape
out.append(cv2.resize(frame, (w//2, h//2)))
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
imageio.mimsave('demo.gif', out, fps=20)
可以发现,上述代码中有两个函数没有定义,rect2bb和shape_to_np。由于dlib的输出是个自定义的类,虽然print可以获取他的rect信息,但是我们不能直接传给cv2.rectangle,因此我们需要对dlib推理得到的rects和shapes重新处理从而方便处理:
def rect2bb(rect):
x1 = rect.left()
y1 = rect.top()
x2 = rect.right()
y2 = rect.bottom()
return (x1, y1), (x2, y2)
def shape_to_np(shape):
coords = np.zeros((68, 2), dtype=int)
for i in range(0, 68):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
通过这个demo,我们可以获取到下面的检测结果,看起来还可以hhh。
2.2.4 描述子匹配
通过上述例子,我们已经完成了人脸检测和关键点估计,那么如何进行人脸的匹配,也就是说怎么将当前人脸和我们数据库里面的人脸进行匹配呢?我认为主要分为以下几个步骤:
- 创建一个人脸数据集
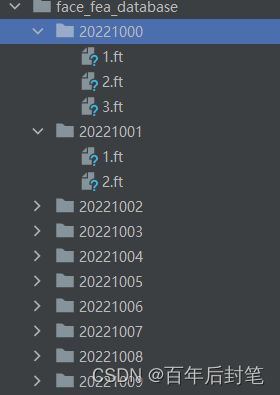
这里我们可以按照学号或者按照人名将人脸数据分文件夹放置,如下图所示:
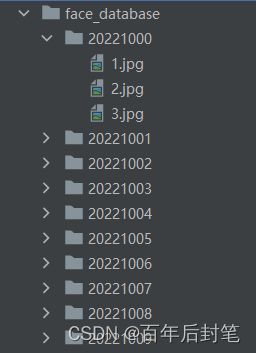

每个人的文件夹下放置该人不同姿态下的人脸图片,用来作为原始的图片数据集,但其实匹配的过程中我们往往不太直接用数据库中的原图,因为计算特征是耗时的,因此更为合适的做法是,将数据库中的图片提前进行人脸识别、特征点检测和特征提取,产生一个特征数据集替代这一原始图片的数据集,如下图所示:
-
分别计算未知人脸特征和数据库中的人脸特征
顾名思义,我们需要在2.2.3中的代码的基础上,完成人脸特征提取,代码如下:
def load_model():
detector = dlib.get_frontal_face_detector()
path_pre = "../models/shape_predictor_68_face_landmarks.dat" # 68点模型
pre = dlib.shape_predictor(path_pre)
path_model = "../models/dlib_face_recognition_resnet_model_v1.dat" # resent模型
model = dlib.face_recognition_model_v1(path_model)
return detector, pre, model
def get_describe_for_face(detector, pre, model, img):
det_img = detector(img, 0)
try:
shape = pre(img, det_img[0])
know_encode = model.compute_face_descriptor(img, shape)
except:
return -1
return know_encode
# 获取待检测图片的encode
unknown_encod = get_describe_for_face(detector, pre, model, unknown_img)
上面我们给出了计算未知人脸特征的代码,而数据库中的已知人脸数据我们同样需要进行特征提取,正如前面2.2.4第一步所说,我们需要提前预处理数据集中的特征,保存为一个类似face_fea_database的数据集备用。这里给出批处理获取特征的参考代码:
import os
import pickle
import numpy as np
from PIL import Image
def Eu(a, b): # 距离函数
return np.linalg.norm(np.array(a) - np.array(b), ord=2)
face_dir = '../face_database'
face_feature_dir = '../face_fea_database'
unknown_img = np.array(Image.open('../face_database/20221000/1.jpg'))
detector, pre, model = load_model()
unknown_fea = get_describe_for_face(detector, pre, model, unknown_img)
for id in os.listdir(face_dir):
face_path = os.path.join(face_dir, id)
face_fea_path = os.path.join(face_feature_dir, id)
os.makedirs(face_fea_path, exist_ok=True)
for img_name in os.listdir(face_path):
img_path = os.path.join(face_path, img_name)
fea_path = os.path.join(face_fea_path, img_name.replace('.jpg', '.ft'))
img = np.array(Image.open(img_path))
img_feature = get_describe_for_face(detector, pre, model, img)
with open(fea_path, 'wb') as f:
pickle.dump(img_feature, f)
with open(fea_path, 'rb') as f:
data = pickle.load(f)
print("save and load result is same? ", Eu(img_feature, unknown_fea) == Eu(data, unknown_fea))
- 将未知人脸和数据库中的人脸进行匹配
匹配这部分我们需要定义我们自己的匹配规则,这里我使用的是将未知了双阈值筛选,如果两个人脸特征差距太大,那么就跳过;如果两个人脸的差距很小,那么直接返回结果;介于俩个阈值之间的,就放在一个list中,最后按照距离排序,返回距离最小的人脸所对应的人员属性。
下面给出macth部分的函数代码:
def record_status(status, name=None):
f = open('../recog_status.txt', 'w', encoding='utf-8')
if status == 3: # 打卡成功
info = STATUS_DICT[status] + name
else:
info = STATUS_DICT[status]
f.write(info)
f.close()
def match_face_by_face_recognize(unknown_img, face_dir, stu_lists, thres=0.4, min_thres=0.55):
MODEL_STATUS = 1
record_status(MODEL_STATUS)
# detector, pre, model = load_model()
MODEL_STATUS = 2
record_status(MODEL_STATUS)
# 获取待检测图片的encode
unknown_encod = face_recognition.face_encodings(unknown_img)
if unknown_encod == []:
record_status(4)
print('无法识别摄像头中的人脸')
return -1, 'Unknown'
else:
unknown_encod = unknown_encod[0]
stus_conf = {stu[0]:[stu[1], 2] for stu in stu_lists}
for id, name in stu_lists:
# 获取当前学生的人脸地址
stu_face_dir = os.path.join(face_dir, str(id))
for img_name in os.listdir(stu_face_dir):
img_path = os.path.join(stu_face_dir, img_name)
# func1. use dlib to get encode if necessary
# img = np.array(Image.open(img_path))
# know_encode = get_describe_for_face(detector, pre, model, img)
# func2. use feature prepared by utils.prepare_feature.py
f = open(img_path, 'rb')
know_encode = pickle.load(f)
# func3. use face recognize
# img = face_recognition.load_image_file(img_path)
# know_encode = face_recognition.face_encodings(img)
if know_encode == []:
record_status(4)
print('无法识别人脸库中的人脸')
return -1, 'Unknown' # 人脸库一般不存在这种情况!!!必须保证高质量人脸
else:
know_encode = know_encode[0]
# 如果检测到差距小于阈值,认为检测成功, 退出
distance = Eu(know_encode, unknown_encod)
if distance > min_thres: break # 这个人必然不是
else:
if distance < thres: # 阈值很小了
MODEL_STATUS = 3
record_status(MODEL_STATUS, name)
return id, name
else: # 阈值一般
stus_conf[id][1] = min(stus_conf[id][1], distance)
# print(stus_conf)
res = sorted(stus_conf.items(), key=lambda x:x[1][1])[0]
print(res)
id, (name, conf) = res
if conf > min_thres:
MODEL_STATUS = 4
record_status(MODEL_STATUS)
return -1, 'Unknown'
else:
MODEL_STATUS = 3
record_status(MODEL_STATUS, name)
return id, name
if __name__ == '__main__':
cap = get_cap()
id = 1
while True:
ret, frame = cap.read()
if cv2.waitKey(1) == ord('q'):#按Q退出
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (480, 480))
# img = np.array(img)
break
else:
cv2.imshow('win', frame)
stu_lists = [(20221001, '钱全'), (20221002, '葛娟'), (20221003, '卫雅'), (20221004, '王宁'), (20221005, '韩惠'),
(20221006, '邹慧')]
detector, pre, model = load_model()
result = match_face(img, '../face_fea_database', stu_lists, detector, pre, model)
print(result)
其实从上面的代码上可以看出,我们其实还有一种快速提取图像特征的方式,那就是使用face_recognize这个库,代码如下,但速度上肯定还是加载预处理得到的特征文件(第二种方法)更快。
func3. use face recognize
img = face_recognition.load_image_file(img_path)
know_encode = face_recognition.face_encodings(img)
三、 基于sqlite3的数据库设计
数据库本身不是这个项目的重点,因此这里浅浅地使用一下python自带的sqlite3数据库,这里我只简单地定义了一些必要的类,因为这是一个人脸打卡系统,因此不免就需要有学生、课程、打卡信息以及选课信息表。
3.1 简单定义数据库类
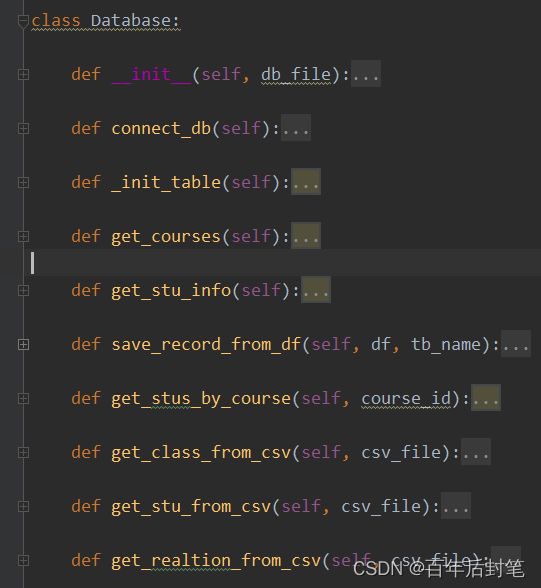
先定义一个数据库的类,用来管理我们的数据,包括数据的导入、数据的读取和数据的更新等等,通过一个类的方式来进行数据库的操作更为清晰和直观一些。E-R图这里就不画了,这个任务也比较简单吧,简化起见就设计了四个表,具体内容下面详细叙述。
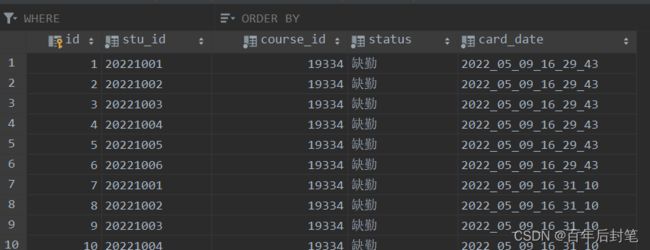
3.1.1 CardRecord 打卡信息表
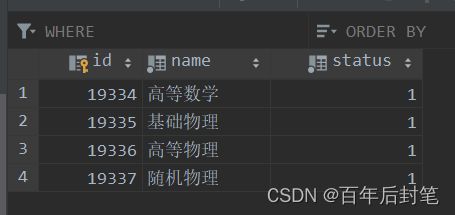
3.1.2 Course 课程表
3.1.3 Relation 选课关系表
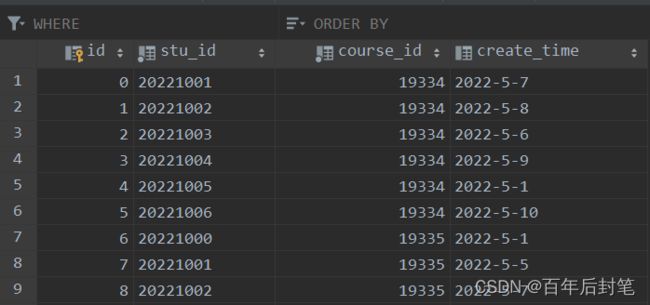
3.1.4 Student 学生表
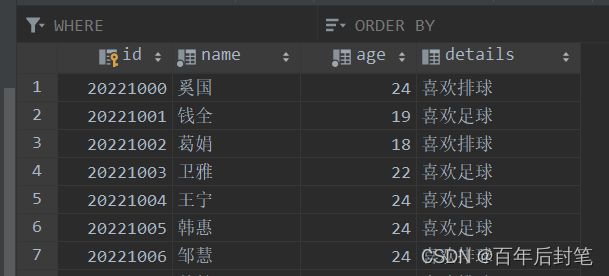
对于选择困难的人而言起名字真的很痛苦,为了快速生成不同学生名和课程名,我使用了随机拼接的方式生成csv文件,后面在导入数据库,这里只给出csv的生成代码,大家可以根据需要选择和修改:
def random_get_datas():
import random
start_id = 20221000
firstName = "赵钱孙李周吴郑王冯陈褚卫蒋沈韩陶姜戚谢邹喻水云苏潘葛奚范彭"
lastName = "秀娟英华慧巧美娜静淑惠珠翠雅力明永健宁贵福生龙元全国胜学祥才"
stu_infos, class_infos = [], []
with open('student.csv', 'w', encoding='utf-8') as f:
f.writelines('id,name,age,details\n')
for i in range(10):
id, name, age, details = start_id, \
random.choice(firstName) + random.choice(lastName), \
random.randint(18, 24), \
"喜欢" + random.choice(['足球', '篮球', '排球'])
start_id += 1
f.writelines("{},{},{},{}\n".format(id, name, age, details))
stu_infos.append((id, name, age, details))
with open('class.csv', 'w', encoding='utf-8') as f:
f.writelines('id,name,status\n')
start_id = 19334
firstName = ['高等','基础' ,'线性' ,'随机' ]
lastName = ['数学', '物理', '信号分析']
for i in range(4):
id, name, status = start_id, \
random.choice(firstName) + random.choice(lastName), \
1
start_id += 1
f.writelines("{},{},{}\n".format(id, name, status))
class_infos.append((id, name, status))
with open('relation.csv', 'w', encoding='utf-8') as f:
id = 0
f.writelines("id,stu_id,course_id,create_time\n")
for classes in class_infos:
a, b = random.randint(0, 4), random.randint(5, len(stu_infos))
for stu in stu_infos[a:b]:
time = "2022-5-" + str(random.randint(1, 10))
f.writelines("{},{},{},{}\n".format(id, stu[0], classes[0], time))
id += 1
print('random init success.')
从csv导入sqlite还是挺容易的,示例代码如下,其中conn = sqlite3.connect(self.db_path):
def get_class_from_csv(self, csv_file):
df = pd.read_csv(csv_file)
try:
df.to_sql('Course', self.conn, if_exists='append', index=False)
except Exception as e:
print(e)
finally:
print("导入成功")
3.2 封装常用的sql查询到数据库类成员函数中
这个也比较基本,把一些常用的查询函数集成到database类里
def get_courses(self):
# 返回课程编号和名称
sql = '''
select * from Course where status == 1;
'''
curr = self.conn.cursor()
curr.execute(sql)
return [item[:2] for item in curr.fetchall()]
def get_stu_info(self):
sql = '''
select * from student;
'''
curr = self.conn.cursor()
curr.execute(sql)
return {item[0]:item[1:] for item in curr.fetchall()}
def get_stus_by_course(self, course_id):
# 返回课程编号和名称
sql = '''
select Student.id, Student.name from Student, Relation where Relation.course_id == ? and Student.id == Relation.stu_id
'''
curr = self.conn.cursor()
curr.execute(sql, [course_id])
其实这里面我写的也比较简单,抛砖引玉,大家可以参照类似的方式把一些功能sql语句写入函数中,方便调用。
四、 基于PyQt5的GUI设计
GUI设计这部分的话,主要就是一个交互的作用,大家根据自己的熟悉程度选择不同的框架,python客户端主要就是tkinter和pyqt5吧,熟悉前后端框架的也可以用html+css+js+django/flask之类的解决。我之前做过pyqt5的客户端,算是比较熟悉吧,这里也就用pyqt5为例来说明一下吧。
想使用pyqt5的同志们,处理要安装基本的pyqt5的python库,为了方便开展GUI设计,最好可以配置一下三件套,也就是:
qt designer:把GUI设计变得更简单,可以理解为可以把组件拖来拖去,完成框架设计的软件。pyrcc:把pyqt5界面所引用的多个资源转换为一个二进制文件,方便使用,不用在去一个个文件调用。pyuic:pyqt5的GUI文件是.ui文件,这个工具可以把ui文件转py文件,供我们做类的复用。
这里我就不赘述这三个玩意的配置和用法啦,如果大家感兴趣,我在专门搞一篇讲解吧 ~
4.1 框架和文件夹结构设计
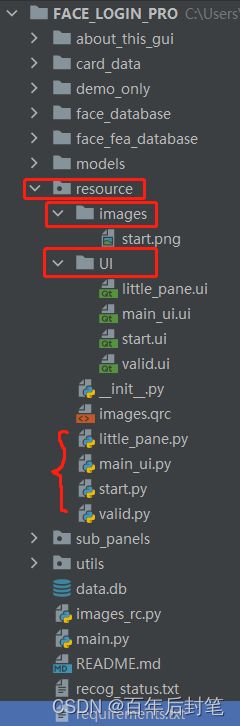
下面我讲一下gui文件的结构吧,其实做任何pyqt5的应用,都是大同小异的,在你的主目录下,可以创建一个resource文件夹,里面分别创建一个UI文件夹和一个images文件夹;
UI主要就存放了你的不同界面的ui源文件,以及你用pyuic转换好的py文件(花括号括起来的),转换后的py文件其实就是你在qt designer中设计的那个面板对应的py类定义和实现,你后面可以直接继承这个类然后再做一些逻辑,包括信号和槽函数的实现。images主要存一些你的图片资源文件,资源文件最后保存在.qrc中,后面通过pyrcc可以将资源文件转为images_rc.py,方便后面使用。当然,如果你有一些音频数据,也可以按照类似的方式创建。
剩下的文件夹和定义就随意啦 ~ 最好是整一个main文件,然后在里面完成不同界面的跳转和交互,这样比较清晰直观,界面之间尽量解耦,依赖低一些。
4.2 开始界面设计
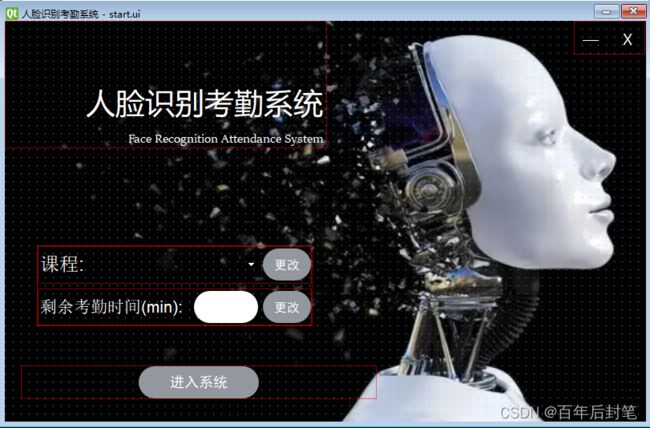
如上图所示,其实可以看出,开始界面的组成比较简单,就是一些按钮、label和组合框的堆叠,主要就是为了显示我们的软件名,增加选择框对课程进行选择,考勤时间的选择,界面切换按钮和自定义的最小化,最大化按钮(qt自带的很丑hhh)
你只需要选择合适的widget(布局),把这些组织在一起就好啦。对于初学的同学不需要关心太多,我觉得你只要把想要的组件放进去,然后哪怕是固定他们的位置呢,只要能用,就是胜利;这里要说的话就有点多了哈哈哈。如果你要自己设计的话,那么就就点击左上角的file,按如下的创建就可以啦,然后在左边选则不同的组件,拖过去就ok啦。
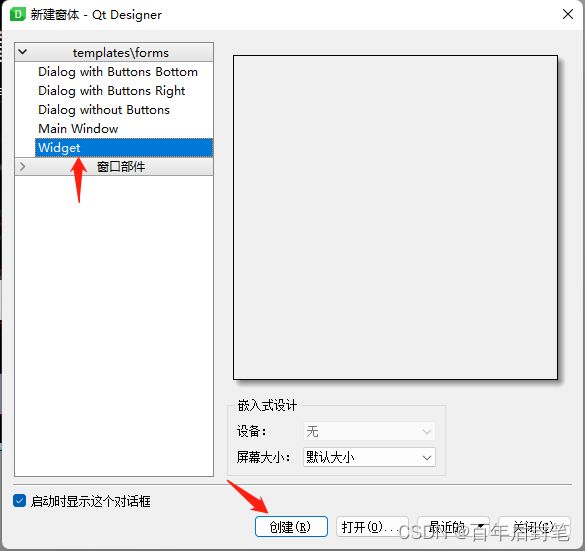
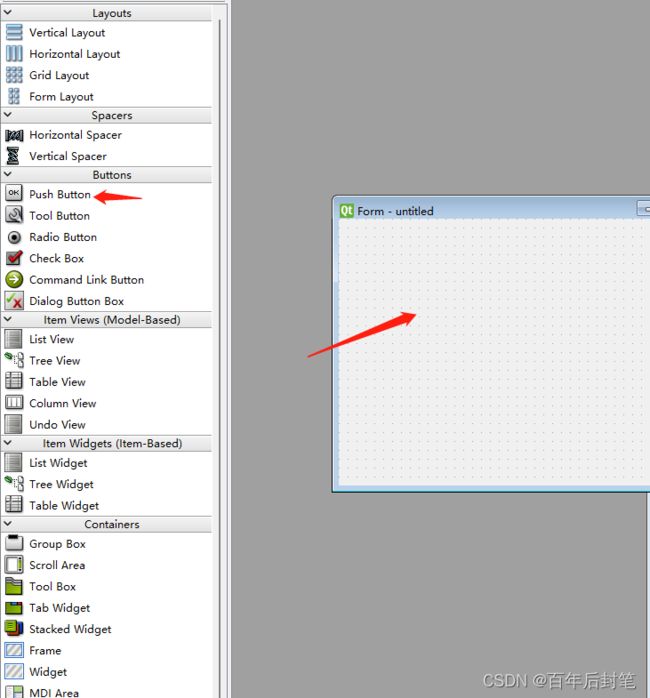
大家回头配置好了qt designer,可以打开我的ui文件,看看具体的布局设计等等,其实想要把qt弄得好看一些还是需要费一些功夫的,qt的qss感觉相比于css还是差点意思,所以一些圆角设计、配色和鼠标事件下,控件的变化想变得丝滑还是需要大家费点心思。
4.3 验证界面设计
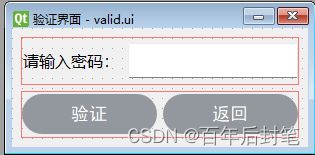
验证界面还是挺简单的,其实就是为了防止同学们或者非管理员瞎玩开始界面和导出打开数据,因此需要验证身份,也比较简单吧,就只需要输入密码,然后验证或者返回就ok。
4.4 自定义的listwidget设计
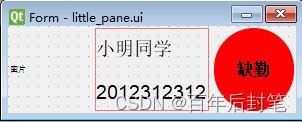
这里设计这个listwidget的目的其实是为了显示打卡人的头像、姓名、学号和打卡信息,把他放在一个listwidget里面,但是qt并没有一个基本组件可以满足这一需求,因此我们可以设计一个form,然后把他嵌入到listwidget里面就ok啦,当然后面如何对listwidget的元素进行状态更新和排序,也是有一些细节的,这里不赘述,大家感兴趣可以从我的代码中找到答案。
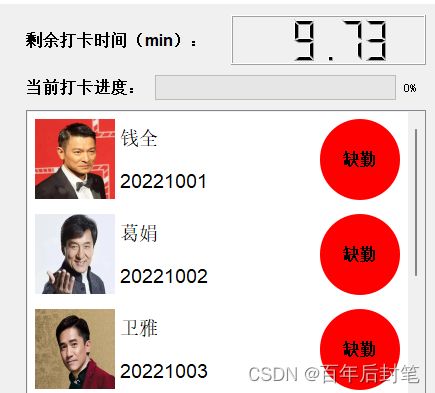
4.4 主界面设计
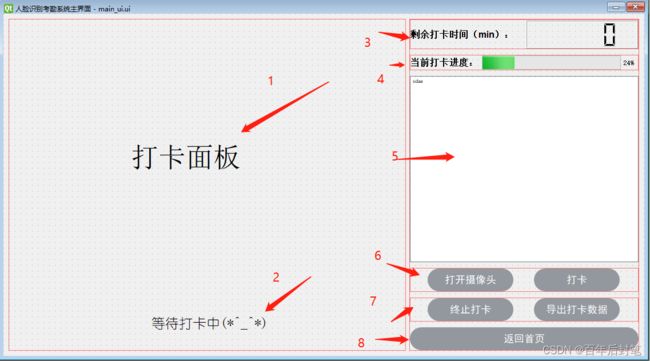
主界面应该是最复杂的,但其实也只是相对复杂,我按照上述的8部分来叙述吧:
- 打卡面板:
- 状态显示栏
- 剩余时间显示:
- 打卡进度更新:
- 自定义打卡人物和状态显示:
- 摄像头和打卡:
- 数据导出:
- 界面跳转:
4.5 如何有效组织不同的UI界面类
五、效果展示
5.1 检测和识别效果展示
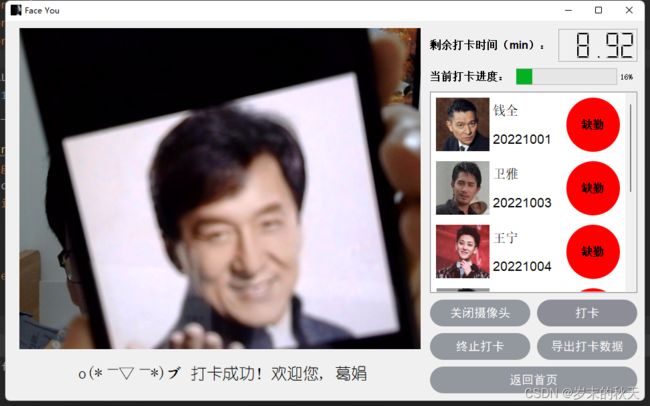
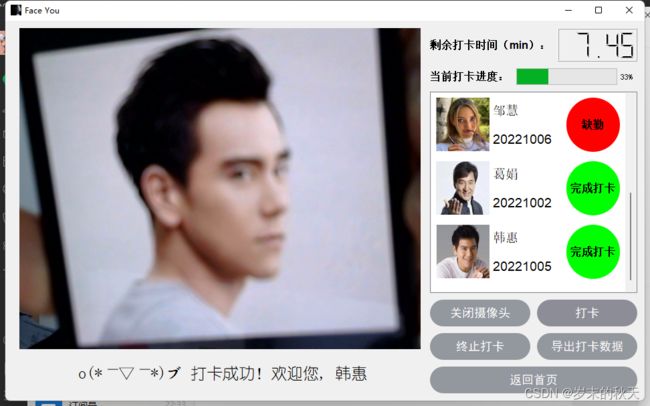
5.2 数据库导出和查看
六、代码获取和下载
完整项目代码放在了我的公众号:百年后封笔,
大家回复 “人脸打卡系统”,即可免费获取完整代码的下载链接!
创作不易,也欢迎大家批评指正,动动小手,评论,收藏一哈!
我也会继续不定期更新感兴趣的项目~