2021-04-28 YOLO实验记录
YOLOv3-Tiny+vs2019+opencv训练
- 1.环境的配置
- 2.基本用法
- 3.YOLOv3-Tiny
-
- 3.1 使用摄像头或视频
- 3.2 训练自己的YOLO
- 4.数据准备
- 5.准备模型
-
- 5.1准备权重文件
- 5.2修改配置文件
- 6.训练模型
1.环境的配置
建议环境:Win10、支持CUDA的Nvidia显卡、Python3、CUDA>=9.0、CUDNN>=7.0、VS2015(或其他)、OPENCV<4.0
详细操作步骤参考:
- Yolov3+windows10+VS2015部署安装
- Windows安装+配置Yolov3(vs2019+NVIDIA+CUDA+cuDNN+OPENCV)
- YOLOv3/YOLOv4(GPU)+Win10+VS2019的配置(从0开始)
- how-to-compile-on-windows
编译时可能遇到形如compute_75的错误,解决方法:用文本的方式打开darknet.vcxproj文件,将所有的compute_75替换为compute_50,将所有的sm_75替换为sm_50,具体替换成什么,请参考Compatibility。
2.基本用法
这一步我们尝试使用下刚刚编译好的YOLO。由于可能缺少模型的权重文件,我们从这里下载YOLO-V3权重文件(236MB)。然后将目录切换到D:\darknet-master\build\darknet\x64,在该文件夹下,按住Shift+鼠标右键,选择“在此处打开Powershell窗口选项”,打开命令行,输入以下语句:
./darknet.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg

正常情况下会得到以下效果:
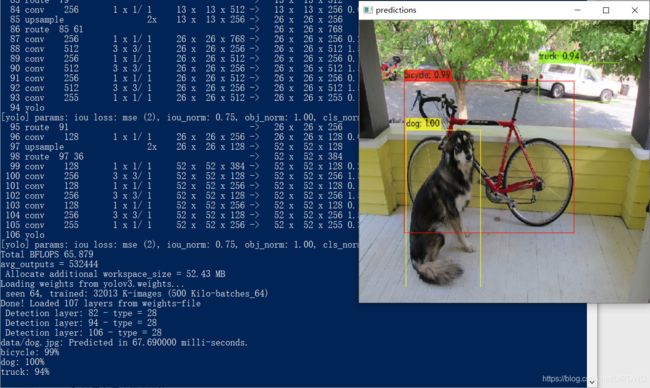
同时也会得到predictions.jpg保存在相同目录下。
运行一次模型需要:
- 配置文件(.cfg)
- 权重文件(.weights)
- 被测图片
同时尝试将上述语句最后的data/dog.jpg分别替换为data/eagle.jpg, data/dog.jpg, data/person.jpg, or data/horses.jpg,查看效果吧。
上述语句中的detect是一种缩写,上述语句也等同于
./darknet.exe detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
当然也可以载入一次模型进行多次预测,输入以下指令(就是去掉图片选项):
./darknet.exe detect cfg/yolov3.cfg yolov3.weights
然后它会提示你输入图片路径:

输入路径后回车,按Ctrl+C退出输入状态。
除此之外,YOLO还提供设定阈值方法来剔除置信度过低的结果。例如若想显示所有结果则使用以下代码(此处阈值设置为0):
./darknet.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
默认的阈值是0.25。
3.YOLOv3-Tiny
首先下载Tiny YOLOv3的权重文件(34MB),丢到与darknet.exe同级的目录下。
使用以下命令运行:
./darknet.exe detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg

可以看到tiny版本的精度略低,但是速度快。
3.1 使用摄像头或视频
使用以下命令在摄像头0(OPENCV默认使用摄像头0)运行Tiny YOLOv3
./darknet.exe detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights
使用参数-c 指定使用哪一只摄像头。
或者使用以下命令实现YOLOv3对视频的目标检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 3.2 训练自己的YOLO
这里我们我们使用Pascal VOC2007数据集训练YOLOv3-tiny模型。关于该数据集的介绍,可以查看这篇文章。
具体步骤详情:
-
How to train to detect your custom objects
-
How to train tiny-yolo to detect your custom objects
4.数据准备
为了训练YOLO我们需要2007年的VOC数据集,可以从这里下载。下载完后解压,解压完训练数据都在VOCdevkit/文件夹下。
训练YOLO需要使用特别格式的标签数据文件,它是一个.txt文本文件。这个.txt文件的每一行是一个标签,一个文件对应一张图片,它看起来像这样:
注意: 此处的中心
x、中心y、框width和框height是相对于图片宽度和高度的值,都是不大于1的小数。
转换公式:

为了得到这些.txt文件,我们可以方便地通过运行一个叫voc_annotation_2.py的脚本来生成。
将脚本保存到与VOC2007文件夹同级的目录,命名为voc_annotation_2.py,然后在此目录下打开命令行,执行:
python voc_annotation_2.py
很快,这个脚本会生成一些必要的文件。它生成了很多标签文件,位于VOCdevkit/VOC2007/labels/路径下。并且在与VOC2007同级的目录下,你应该会看到如下的文件:
2007_train.txt
2007_val.txt
2007_test.txt
train.txt
train.all.txt
如果是自己采集的数据,需要标注,请使用LabelImg或Yolo_mark工具,以生成YOLO格式的文本文件。然后将图片的路径汇总到一个文本文件,如train.txt、val.txt和test.txt里,一行一个图片路径。
5.准备模型
新建个文件夹,我们用来保存与模型有关的数据。我这里路径为:D:/model/voc_model/
我这里VOC2007文件夹位于:D:/dataset/VOCdevkit/,Darknet.exe位于D:/darknet-master/build/darknet/x64/
5.1准备权重文件
首先下载默认的权重文件到你刚刚新建的模型文件夹(我这里是D:/model/voc_model/):
在模型文件夹运行如下指令,获取预训练的权重文件yolov3-tiny.conv.15,使用如下命令:
D:/darknet-master/build/darknet/x64/darknet.exe partial D:/darknet-master/build/darknet/x64/cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
其他预训练权重可以从这里下载
5.2修改配置文件
1.在模型文件夹创建一份VOC2007.names文本文件,其中该文件的每一行都是种类的名字,应该使得行数等于种类数classes的值。
2.在模型文件夹创建一份VOC2007.data文本文件,填入以下内容。classes是种类的个数、train是训练图片路径的文本文件,valid是验证图片路径的文本文件,names是种类名字的文件,backup路径则用于保存备份的权重文件(每迭代100次保存一次文件(带_last后缀),每1000次保存一次文件(带_xxxx后缀))。
如果没有验证集,则设置valid为与train相同的值即可,那么将测试在训练集上的精度。
classes = 20
train = D:/dataset/VOCdevkit/train.txt
valid = D:/dataset/VOCdevkit/2007_test.txt
names = VOC2007.names
backup = backup/
3.复制D:/darknet-master/build/darknet/x64/cfg/yolov3-tiny_obj.cfg文件,在模型文件夹另存为yolov3-tiny-obj.cfg,然后按照下述规则修改该文件:
- 修改使得
batch=64 - 修改使得
subdivisions=8 - 修改所有的
classes值为20(这里classes是目标检测物体的种类个数) - 修改所有位于行
[yolo]之上的[convolutional]层的filters值为: f i l t e r s = ( c l a s s e s + 5 ) ∗ 3 filters = (classes + 5) * 3 filters=(classes+5)∗3filters的值需要计算出来再填入。注意,这不是修改所有filters的值,仅仅是修改恰好位于[yolo]这行之上该层的filters的值,可能需要修改多处。 - 如果你要修改输入图像的
width和height值,请注意这两个值必须能被32整除。
6.训练模型
在模型文件夹运行命令:
D:/darknet-master/build/darknet/x64/darknet.exe detector train VOC2007.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15
-
如果你在
avg loss里看到nan,意味着训练失败;在其他地方出现nan则是正常的。 -
如果出错并显示
Out of memory,尝试将.cfg文件的subdivisions值增大(建议为 2 n 2^n 2n)。 -
使用附加选项
-dont_show来关闭训练时默认显示的损失曲线窗口 -
使用附加选项
-map来显示mAP值 -
训练完成后的权重将保存于你在
.data文件中设置的backup值路径下 -
你可以从
backup值的路径下找到你的备份权重文件,并以此接着训练模型 -
多GPU训练:How to train with multi-GPU
-
训练完成后使用命令
./darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights针对输入的图片查看识别结果。