# coding: utf-8
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import pathlib
import tensorflow as tf
import cv2
import argparse
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
parser = argparse.ArgumentParser()
parser.add_argument('--model', help='Folder that the Saved Model is Located In',
default='eval')
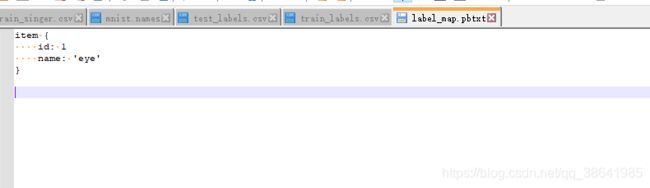
parser.add_argument('--labels', help='Where the Labelmap is Located',
default='label_map.pbtxt')
parser.add_argument('--image', help='Name of the single image to perform detection on',
default='video/0072.png')
parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects',
default=0.50)
args = parser.parse_args()
# Enable GPU dynamic memory allocation
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# PROVIDE PATH TO IMAGE DIRECTORY
IMAGE_PATHS = args.image
# PROVIDE PATH TO MODEL DIRECTORY
PATH_TO_MODEL_DIR = args.model
# PROVIDE PATH TO LABEL MAP
PATH_TO_LABELS = args.labels
# PROVIDE THE MINIMUM CONFIDENCE THRESHOLD
MIN_CONF_THRESH = float(args.threshold)
# LOAD THE MODEL
import time
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
PATH_TO_SAVED_MODEL = PATH_TO_MODEL_DIR + "/saved_model"
print('Loading model...', end='')
start_time = time.time()
# LOAD SAVED MODEL AND BUILD DETECTION FUNCTION
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
# LOAD LABEL MAP DATA FOR PLOTTING
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
print('Running inference for {}... '.format(IMAGE_PATHS), end='')
image = cv2.imread(IMAGE_PATHS)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_expanded = np.expand_dims(image_rgb, axis=0)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
# input_tensor = np.expand_dims(image_np, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_with_detections = image.copy()
# SET MIN_SCORE_THRESH BASED ON YOU MINIMUM THRESHOLD FOR DETECTIONS
viz_utils.visualize_boxes_and_labels_on_image_array(
image_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=100,
min_score_thresh=MIN_CONF_THRESH,
agnostic_mode=False)
print('\n' + 'Done')
# DISPLAYS OUTPUT IMAGE
#if image_with_detections.shape[0]>1000:
#image_with_detections = cv2.resize(image_with_detections,[int(0.5*image_with_detections.shape[0]),[int(0.5*image_with_detections.shape[1]]))
cv2.imwrite("pic/"+IMAGE_PATHS.split("/")[-1],image_with_detections)
cv2.imshow('Object Detector', image_with_detections)
#cv2.resizeWindow("Object Detector", 720,1280)
# CLOSES WINDOW ONCE KEY IS PRESSED
cv2.waitKey(0)
# CLEANUP
cv2.destroyAllWindows()
执行视频检测
Video_Dectction.py
# coding: utf-8
"""
Object Detection (On Video) From TF2 Saved Model
=====================================
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import pathlib
import tensorflow as tf
import cv2
import argparse
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
parser = argparse.ArgumentParser()
parser.add_argument('--model', help='Folder that the Saved Model is Located In',
default='eval')
parser.add_argument('--labels', help='Where the Labelmap is Located',
default='label_map.pbtxt')
parser.add_argument('--video', help='Name of the video to perform detection on. To run detection on multiple images, use --imagedir',
default='video/eye.mp4')
parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects',
default=0.75)
args = parser.parse_args()
# Enable GPU dynamic memory allocation
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# PROVIDE PATH TO IMAGE DIRECTORY
VIDEO_PATHS = args.video
# PROVIDE PATH TO MODEL DIRECTORY
PATH_TO_MODEL_DIR = args.model
# PROVIDE PATH TO LABEL MAP
PATH_TO_LABELS = args.labels
# PROVIDE THE MINIMUM CONFIDENCE THRESHOLD
MIN_CONF_THRESH = float(args.threshold)
# Load the model
# ~~~~~~~~~~~~~~
import time
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
PATH_TO_SAVED_MODEL = PATH_TO_MODEL_DIR + "/saved_model"
print('Loading model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
# Load label map data (for plotting)
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
print('Running inference for {}... '.format(VIDEO_PATHS), end='')
video = cv2.VideoCapture(VIDEO_PATHS)
while(video.isOpened()):
# Acquire frame and expand frame dimensions to have shape: [1, None, None, 3]
# i.e. a single-column array, where each item in the column has the pixel RGB value
ret, frame = video.read()
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
frame_expanded = np.expand_dims(frame_rgb, axis=0)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(frame)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
# input_tensor = np.expand_dims(image_np, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
frame_with_detections = frame.copy()
# SET MIN SCORE THRESH TO MINIMUM THRESHOLD FOR DETECTIONS
viz_utils.visualize_boxes_and_labels_on_image_array(
frame_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=MIN_CONF_THRESH,
agnostic_mode=False)
cv2.imshow('Object Detector', frame_with_detections)
if cv2.waitKey(1) == ord('q'):
break
cv2.destroyAllWindows()
print("Done")
eclipse中使用maven插件的时候,运行run as maven build的时候报错
-Dmaven.multiModuleProjectDirectory system propery is not set. Check $M2_HOME environment variable and mvn script match.
可以设一个环境变量M2_HOME指
1.建好一个专门放置MySQL的目录
/mysql/db数据库目录
/mysql/data数据库数据文件目录
2.配置用户,添加专门的MySQL管理用户
>groupadd mysql ----添加用户组
>useradd -g mysql mysql ----在mysql用户组中添加一个mysql用户
3.配置,生成并安装MySQL
>cmake -D
好久没有去安装过MYSQL,今天自己在安装完MYSQL过后用navicat for mysql去厕测试链接的时候出现了10061的问题,因为的的MYSQL是最新版本为5.6.24,所以下载的文件夹里没有my.ini文件,所以在网上找了很多方法还是没有找到怎么解决问题,最后看到了一篇百度经验里有这个的介绍,按照其步骤也完成了安装,在这里给大家分享下这个链接的地址
import java.io.UnsupportedEncodingException;
/**
* 转换字符串的编码
*/
public class ChangeCharset {
/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */
public static final Strin
其实这个没啥技术含量,大湿们不要操笑哦,只是做一个简单的记录,简单用了一下递归算法。
import java.io.File;
/**
* @author Perlin
* @date 2014-6-30
*/
public class PrintDirectory {
public static void printDirectory(File f
linux安装mysql出现libs报冲突解决
安装mysql出现
file /usr/share/mysql/ukrainian/errmsg.sys from install of MySQL-server-5.5.33-1.linux2.6.i386 conflicts with file from package mysql-libs-5.1.61-4.el6.i686
Dear,
I'm pleased to announce that ktap release v0.1, this is the first official
release of ktap project, it is expected that this release is not fully
functional or very stable and we welcome bu