Python数学建模 缺失值与异常值处理
文章目录
- 基于Python的数学建模
- 数据缺失值与异常值处理
-
- 缺失值的定义与原因
- 缺失值的处理
-
- 删除法
- 简单填充
- 插值法
- 异常值检测
基于Python的数学建模
- Github仓库:Mathematical-modeling
数据缺失值与异常值处理
缺失值的定义与原因
- 定义:缺失值,即存在特征或标签为空值的样本。包含空值的数据会使建模过程陷入混乱,导致不可靠输出。缺少过多的数据也将丢失大量有效信息,使数据模型难以把握数据规律。
- 缺失原因:
- 部分信息暂时无法获取
- 由于人为因素丢失部分信息
- 部分对象的某个或某些属性不可用
缺失值的处理
生成缺失数据
data = pd.DataFrame({'A':[None,2,3,4,None,6],'B':[4,None,7,10,15,21],'C':[3,6,18,7,10,13]})
data

删除法
- 特征删除法:当一个特征缺失“过多”的数据时,对其填充的数据可能是无价值的,因此直接将该指标删除。特征值缺失量的标准无硬性规定,正常缺失30%以上便可以删除变量。
- 样本删除法:当含缺失值的样本量在总数据量占比较小时,可以仅删除含缺失值的样本量。
data_1 = data.copy()
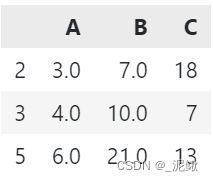
data_1 = data_1.dropna(axis=0,how='any') # 以行为参考,如果有空值,就删除该行
data_1
data_1 = data.copy()
data_1 = data_1.dropna(axis=1,how='any') # 以列为参考,如果有空值,就删除该列
data_1

简单填充
- 手动填充:填充效果最好,产生的数据偏离最小,当在处理大规模数据时不可行。
- 统计填充:若缺失值为数值数据,可以计算其他对象的均值、加权均值或中位数来填补缺失值。若缺失值为分类数据,可以使用众数,选择在其他对象中出现频率最高的值进行填充。
# 均值填充
data_3 = data.copy()
data_3 = data_3.fillna(data_3.mean())
# 中位数填充
data_3 = data.copy()
data_3 = data_3.fillna(data_3.median())
# 使用前一个数据进行填充
data_3 = data.copy()
data_3 = data_3.fillna(value=None, method='ffill',axis=0)
# 使用后一个数据进行填充
data_3 = data.copy()
data_3 = data_3.fillna(value=None, method='backfill',axis=0)
# Sklearn 插值工具
from sklearn.impute import SimpleImputer
# Strategy可以指定填充方式,mean均值填补,median中位数填补,most_frequent众数填补,constant常数填补
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
data_3 = data.copy()
data_3 = imp.fit_transform(data_3)
data_3

插值法
- 热卡填充法(就近补齐):对于一个包含空值的对象,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。通常会找到超出一个的相似对象,在所有匹配对象中没有最好的,而是从中随机的挑选一个作为填充值,不同的问题选用不同的标准来对相似进行判定。但不同的问题可能会选用不同的标准来对相似进行判定,难以定义相似标准,主观因素较多。
- KNN最近邻填充
- 先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
- 这个方法要求我们选择k的值(最近邻居的数量),以及距离度量。
- KNN既可以预测离散属性(加权投票)也可以预测连续属性(加权平均)。
from sklearn.impute import KNNImputer
imputer = KNNImputer(missing_values=np.nan,
n_neighbors=2, # 用于插补的相邻样本数。
weights='distance') # 用于预测的权重函数
data_4 = data.copy()
data_4 = imputer.fit_transform(data_4)
data_4

- 多重插补
- 在处理缺失值时,可以通过链式方程的多重插补(MICE,Multiple Imputation by Chained Equations)估算缺失值。从技术上讲,任何能够推理的预测模型都可以用于MICE。
miceforest库可以实现随机森林的链式方程式(MICE)多重插补,具有快速、内存利用率高的特征,无需太多设置即可插入缺失的分类和数值数据,并且具有一系列可用的诊断图。
import miceforest as mf
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = pd.concat(load_iris(as_frame=True,return_X_y=True),axis=1)
iris.rename({"target": "species"}, inplace=True, axis=1)
iris['species'] = iris['species'].astype('category')
# 引入缺失数据
iris_amp = mf.ampute_data(iris,perc=0.25,random_state=1991)
iris_amp
# 初始化插补模型
kernel = mf.ImputationKernel(
iris_amp,
datasets=5, # 将datasets设置为5,创建多个插补数据集
save_all_iterations=True,
random_state=666
)
# MICE算法进行2次迭代
kernel.mice(2)
# 直接从内核中获取已插值的数据集
completed_dataset = kernel.complete_data(dataset=0, inplace=False)
completed_dataset

异常值检测
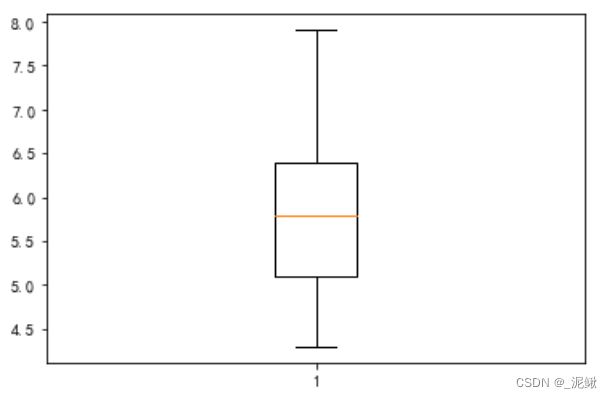
- 箱线图
from matplotlib import pyplot as plt
# 加载鸢尾花数据集
iris = pd.concat(load_iris(as_frame=True,return_X_y=True),axis=1).iloc[:,0]
_ = plt.boxplot(iris)
# 生成异常值
iris_1 = iris.copy()
iris_1[4]=14
_ = plt.boxplot(iris_1)

2. 3 σ \sigma σ原则(拉依达准则)
def three_sigma(data, n=3):
"""
data: DataFrame某一列
"""
rule = (data.mean() - n * data.std() > data) | (data.mean() + n * data.std() < data)
index = np.arange(data.shape[0])[rule]
outrange = data.iloc[index]
return outrange
# 异常值检测
print(three_sigma(iris,n=3))
![]()
# 生成异常值
iris_1 = iris.copy()
iris_1[4]=14
print(three_sigma(iris_1,n=3))
