Tensorflow中预处理图像的方法
1.方法一:ImageDataGenerator(数据增强)
(1)ImageDataGenerator
数据增强
mydata=ImageDataGenerator(
rescale=所有数据集将乘以该数值,
rotation_range=随即旋转角度数范围,
width_shift_range=随即宽度偏移量,
height_shift_range=随即高度偏移量,
horizontal_flip=是否随机水平翻转,
zoom_range=随机缩放的范围
该函数可以增强图片数据,需要fit函数来对指定的数据进行增强,这里要求是四维数据(图片张数,图片长度,图片宽度,灰度),先reshape为四维数据然后调用fit函数e(2).flow,.flow_from_directory
推荐这位博主:"https://blog.csdn.net/qq_31119155/article/details/90170755
(3)实例
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#图片的大小
img_h,img_w=128,128
#batch_size的大小
batch_size=4
#训练图片数据的路径
train_data_dir='../images/train'
#验证图片数据集的路径
validation_data_dir='../images/valid'
#数据增强
train_datagen=ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
#加载给定路径下的图片数据集并进行处理
train_generate=train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_h,img_w),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
validation_generate=validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_h,img_w),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)2.方法二:tf.keras.utils
(1)get_file
tf.keras.utils.get_file(
fname=None, # 文件的名称。 若指定了绝对路径 /path/to/file.txt,则文件将保存在该位置。 若没有,将使用原始文件的名称。
origin=None, # 文件的原始 URL。
untar=False, # 已弃用,取而代之的是 extract 参数。 布尔值,文件是否应该被解压
md5_hash=None, # 已弃用,取而代之的是 file_hash 参数。 用于验证的文件的 md5 哈希
file_hash=None, # 下载后文件的预期哈希字符串。 同时支持 sha256 和 md5 哈希算法。
cache_subdir='datasets', # 保存文件的 Keras 缓存目录下的子目录。 如果指定了绝对路径 /path/to/folder,则文件将保存在该位置。
hash_algorithm='auto', # 选择哈希算法来验证文件。 有“md5”、“sha256”和“auto”。 默认的“自动”检测正在使用的哈希算法。
extract=False, # True 尝试将文件解压缩为存档,例如 tar 或 zip。
archive_format='auto', # 尝试提取文件的存档格式。 有“auto”、“tar”、“zip”和“无”。 'tar' 包括 tar、tar.gz 和 tar.bz 文件。默认的 'auto' 对应于 ['tar', 'zip']。 None 或空列表将返回找不到匹配项。
cache_dir=None # 存储缓存文件的位置,当 None 默认为默认目录 ~/.keras/。
)(2)image_dataset_from_directory
从目录中读取数据并进行预处理
tf.keras.utils.image_dataset_from_directory(
directory, #数据存放目录
labels='inferred', #标签由目录结构推断
label_mode='int', #标签编码方式:int、categorical、binary;分别为标签编码为整数、类别向量、二分类编码为0或1
class_names=None, #用于labels='inferred'时,类名的显式列表(必须匹配子目录的名称)。用于控制类的顺序(否则使用字母数字顺序)。
color_mode='rgb', #“grayscale”、“rgb,默认值:“rgb”,将图像转为 1、3、4通道
batch_size=32, #一次处理图像的数量
image_size=(256, 256), #指定读取图像后,调整图像大小
shuffle=True, #是否打乱原数据的顺序
seed=None, #随机种子
validation_split=None, #验证集分割比例
subset=None, #要返回的数据的子集为training或者validation或者both(训练集和验证集组成的元组)
interpolation='bilinear',#调整图像大小时用的插值方法,默认bilinear,
follow_links=False, #是否访问符号链接指向的子目录
crop_to_aspect_ratio=False, #调整图像大小时是否保留纵横比
**kwargs
)
(3)pathlib.Path 与 os.path
pathlib.Path 与 os.path
(4)实例
import numpy as np
from PIL import Image
import tensorflow as tf
import pathlib
# dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
#数据集路径的位置
dataset_url=r'E:\myDataset\flower_photos'
#从给定路径下加载数据集
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
print(len(list(data_dir.glob('*/*.jpg'))))
roses=list(data_dir.glob('roses/*'))
rose_img=Image.open(str(roses[0]))
rose_img.show('roseImage')
#图片的大小
img_h,img_w=180,180
#batch_size的大小
batch_size=4
#将使用 80% 的图像进行训练,20% 的图像进行验证。
train_data=tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='training',
seed=123,
image_size=(img_h,img_w),
batch_size=batch_size
)
val_data=tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='validation',
seed=123,
image_size=(img_h,img_w),
batch_size=batch_size
)

3.方法三:tf.keras.Sequential和tf.image
(1)tf.keras.Sequential使用方法
#进随机的翻转和旋转
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])(2)示例:以CIFAR10数据集为例
import os
import cv2
import keras
import torch
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import layers
#加载数据集
(img_train,label_train),(img_test,label_test)=tf.keras.datasets.cifar10.load_data()
#查看数据集情况
print('img_train.shape: {}'.format(img_train.shape))
print('label_train.shape: {}'.format(label_train.shape))
print('img_test.shape: {}'.format(img_test.shape))
print('label_test.shape: {}'.format(label_test.shape))
#查看数据集类型
print('dtype: {}'.format(type(img_train[0])))
print('dtype: {}'.format(type(label_train[0])))
#img_train[0].shape:[32,32,3]显示图片
print(img_train[0].shape)
cv2.imshow('',img_train[0])
cv2.waitKey(0)
cv2.destroyAllWindows()
#数据增强
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
img_train=data_augmentation(img_train)
#查看数据类型和维度
print(type(img_train[0]))
print(img_train[0].shape)
#对图像进行升维[32,32,3]=>[1,32,32,3]
print(tf.expand_dims(img_train[0], 0))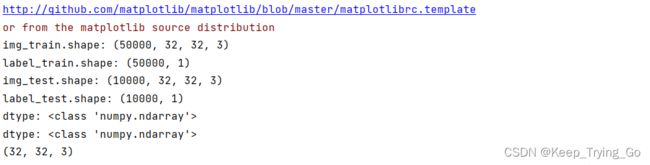
#显示数据增强之后的图片
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(img_train[0], 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')
plt.show()

(3)tf.image数据增强
推荐这位博主:
https://blog.csdn.net/akadiao/article/details/78541763
例如:进行左右变换:(其他的tf.image.数据增强方法也是一样的操作)
原图:

import os
import cv2
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import img_to_array
#读取图像
img=Image.open(r'myDataset/flower_photos/daisy/5547758_eea9edfd54_n.jpg')
img.show()
#转换为array类型
imgToArray=img_to_array(img)
randImg=tf.image.random_flip_left_right(image=imgToArray,seed=7)
print(randImg)
print(randImg.shape)
#显示图片方式一
plt.imshow(img_to_array(randImg)/255)
plt.show()
#显示图片方式二
cv2.imshow('img',img_to_array(randImg)/255)
cv2.waitKey(0)
cv2.destroyAllWindows()左右变换之后的图:

4.方法四:
自己写一个函数对图像进行预处理:
import os
import cv2
import numpy as np
from PIL import Image
#使用Image对图像进行预处理
def preprocess_image(img_path,target_size):
"""
:param img_path: 图片路径
:param target_size: 图片大小
:return:
"""
#读取图像
image=Image.open(img_path)
#判断图像的通道是否为RGB
if image.mode!='RGB':
image=image.convert('RGB')
#对图像的大小进行缩放
image=image.resize(target_size)
#将图像的类型转换为向量
image=img_to_array(image)
#对图像进行归一化
image=image/255.0
#对图像的第一维度进行升维
image=np.expand_dims(image,axis=0)
return image