人脸、微笑、口罩识别
一、人脸图像特征提取的方法
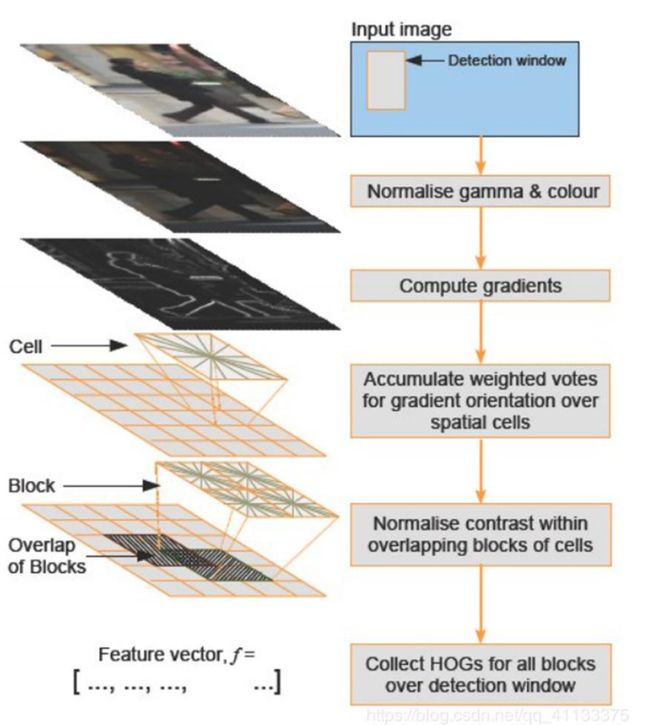
1.HOG 特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图 像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向 直方图来构成特征。Hog 特征结合 SVM 分类器已经被广泛应用于图像识别中,尤其在 行人检测中获得了极大的成功。需要提醒的是,HOG+SVM 进行行人检测的方法是法国 研究人员 Dalal 在 2005 的 CVPR 上提出的,而如今虽然有很多行人检测算法不断提出, 但基本都是以 HOG+SVM 的思路为主。
(1)主要思想: 在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的 方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
(2)具体的实现方法是: 首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的 梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。
(3)提高性能: 把这些局部直方图在图像的更大的范围内(我们把它叫区间或 block)进行对比度归一 化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中 的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能 对光照变化和阴影获得更好的效果。
(4)优点: 与其他的特征描述方法相比,HOG 有很多优点。首先,由于 HOG 是在图像的局部方格 单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只 会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部 光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微 的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此 HOG 特征是特别适 合于做图像中的人体检测的。
HOG 特征提取方法就是将一个 image(你要检测的目标或者扫描窗口):
1)灰度化(将图像看做一个 x,y,z(灰度)的三维图像);
2)采用 Gamma 校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图 像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进 一步弱化光照的干扰。
4)将图像划分成小 cells(例如 66 像素/cell);
5)统计每个 cell 的梯度直方图(不同梯度的个数),即可形成每个 cell 的 descriptor;
6)将每几个 cell 组成一个 block(例如 33 个 cell/block),一个 block 内所有 cell 的 特征 descriptor 串联起来便得到该 block 的 HOG 特征 descriptor。 7)将图像 image 内的所有 block 的 HOG 特征 descriptor 串联起来就可以得到该 image (你要检测的目标)的 HOG 特征 descriptor 了。这个就是最终的可供分类使用的特征 向量了。
2.Dlib
Dlib 是一个包含机器学习算法的 C++开源工具包。Dlib 可以帮助您创建很多复杂的机器 学习方面的软件来帮助解决实际问题。目前 Dlib 已经被广泛的用在行业和学术领域,包 括机器人,嵌入式设备,移动电话和大型高性能计算环境。 Dlib 的主要特点:
- 文档齐全 不像很多其他的开源库一样,Dlib 为每一个类和函数提供了完整的文档说明。同时,还提供了 debug 模式;打开 debug 模式后,用户可以调试代码,查看变量和对象的值,快速定位错误点。 另外,Dlib 还提供了大量的实例。
- 高质量的可移植代码 Dlib 不依赖第三方库,无须安装和配置,这部分可参照(官网左侧树形目录的 how to compile 的介绍)。Dlib 可用在 window、Mac OS、Linux 系统上。
- 提供大量的机器学习 / 图像处理算法
- 深度学习
基于 SVM 的分类和递归算法 针对大规模分类和递归的降维方法 相关向量机(relevance vector machine);是与支持向量机相同的函数形式稀疏概率模型,对未知函数进行 预测或分类。其训练是在贝叶斯框架下进行的,与 SVM 相比,不需要估计正则化参数,其核函数也不需 要满足 Mercer 条件,需要更少的相关向量,训练时间长,测试时间短。
聚类: linear or kernel k-means, Chinese Whispers, and Newman clustering. Radial Basis Function Networks 多层感知机
3.卷积神经网络
卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神 经网络的多层感知器,常用来分析视觉图像。卷积神经网络的创始人是着名的计算机科 学家 Yann LeCun,目前在 Facebook 工作,他是第一个通过卷积神经网络在 MNIST 数 据集上解决手写数字问题的人。 卷积神经网络 CNN 主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于 CNN 的特征检测层通过训练数据进行学习,所以在使用 CNN 时,避免了显式的特征抽 取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同, 所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积 神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性, 其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入 向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂 度。卷积神经网络中,第一步一般用卷积核去提取特征,这些初始化的卷积核会在反向传播 的过程中,在迭代中被一次又一次的更新,无限地逼近我们的真实解。其实本质没有对 图像矩阵求解,而是初始化了一个符合某种分布的特征向量集,然后在反向传播中无限 更新这个特征集,让它能无限逼近数学中的那个概念上的特征向量,以致于我们能用特 征向量的数学方法对矩阵进行特征提取。
Dlib笑脸检测
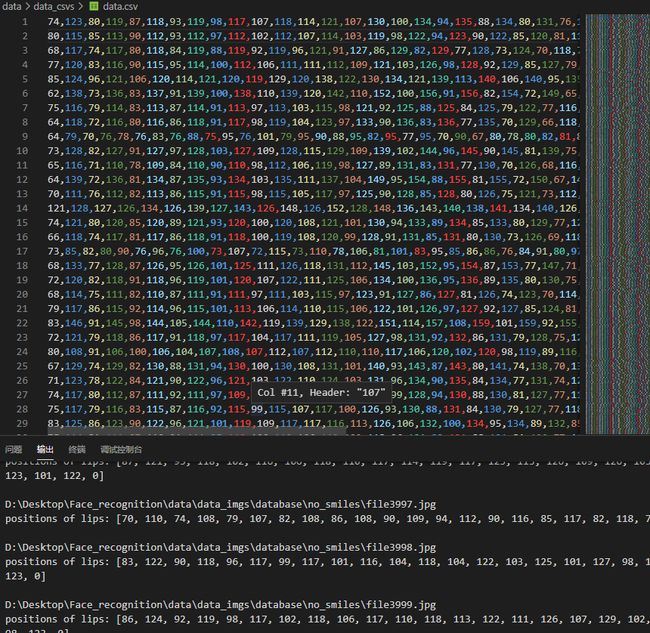
利用dilb提取嘴部特征并写入data.csv
筛选数据
# 筛选数据将无法提取特征点的图片提取出来
def select():
for i in imgs_smiles:
img_rd = path_images_with_smiles + i
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(img_gray, 0)
try:
np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
except:
shutil.move(img_rd,select_smiles)
for i in imgs_no_smiles:
img_rd = path_images_no_smiles + i
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(img_gray, 0)
try:
np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
except:
shutil.move(img_rd,select_no_smiles)
提取特征点
# 输入图像文件所在路径,返回一个41维数组(包含提取到的40维特征和1维输出标记)
def get_features(img_rd):
# 输入: img_rd: 图像文件
# 输出: positions_lip_arr: feature point 49 to feature point 68, 20 feature points / 40D in all
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 计算68点坐标
positions_68_arr = []
faces = detector(img_gray, 0)
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
# except:
for point in enumerate(landmarks):
# 68点的坐标
pos = (point[0, 0], point[0, 1])
positions_68_arr.append(pos)
positions_lip_arr = []
# 将点 49-68 写入 CSV
# 即 positions_68_arr[48]-positions_68_arr[67]
for i in range(48, 68):
positions_lip_arr.append(positions_68_arr[i][0])
positions_lip_arr.append(positions_68_arr[i][1])
return positions_lip_arr
完整代码
import dlib # 人脸处理的库 Dlib
import numpy as np # 数据处理的库 numpy
from cv2 import cv2 # 图像处理的库 OpenCv
import os # 读取文件
import csv # CSV 操作
import shutil
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('D:\\Desktop\\Face_recognition\\shape_predictor_68_face_landmarks.dat')
# 输入图像文件所在路径,返回一个41维数组(包含提取到的40维特征和1维输出标记)
def get_features(img_rd):
# 输入: img_rd: 图像文件
# 输出: positions_lip_arr: feature point 49 to feature point 68, 20 feature points / 40D in all
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 计算68点坐标
positions_68_arr = []
faces = detector(img_gray, 0)
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
# except:
for idx, point in enumerate(landmarks):
# 68点的坐标
pos = (point[0, 0], point[0, 1])
positions_68_arr.append(pos)
positions_lip_arr = []
# 将点 49-68 写入 CSV
# 即 positions_68_arr[48]-positions_68_arr[67]
for i in range(48, 68):
positions_lip_arr.append(positions_68_arr[i][0])
positions_lip_arr.append(positions_68_arr[i][1])
return positions_lip_arr
# 读取图像所在的路径
path_images_with_smiles = "D:\\Desktop\\Face_recognition\\data\\data_imgs\\database\\smiles\\"
path_images_no_smiles = "D:\\Desktop\\Face_recognition\\data\\data_imgs\\database\\no_smiles\\"
# 获取路径下的图像文件
imgs_smiles = os.listdir(path_images_with_smiles)
imgs_no_smiles = os.listdir(path_images_no_smiles)
select_smiles = "D:\\Desktop\\Face_recognition\\data\\data_imgs\\database\\select\\1\\"
select_no_smiles = "D:\\Desktop\\Face_recognition\\data\\data_imgs\\database\\select\\2\\"
# 存储提取特征数据的 CSV 的路径
path_csv = "data\\data_csvs\\"
# 筛选数据将无法提取特征点的图片提取出来
def select():
for i in imgs_smiles:
img_rd = path_images_with_smiles + i
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(img_gray, 0)
try:
np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
except:
shutil.move(img_rd,select_smiles)
for i in imgs_no_smiles:
img_rd = path_images_no_smiles + i
# read img file
img = cv2.imread(img_rd)
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(img_gray, 0)
try:
np.matrix([[p.x, p.y] for p in predictor(img, faces[0]).parts()])
except:
shutil.move(img_rd,select_no_smiles)
# write the features into CSV
def write_into_CSV():
with open(path_csv+"data.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
# 处理带笑脸的图像
print("######## with smiles #########")
for i in imgs_smiles:
print(path_images_with_smiles + i)
features_csv_smiles = get_features(path_images_with_smiles+ i)
features_csv_smiles.append(1)
print("positions of lips:", features_csv_smiles, "\n")
# 写入CSV
writer.writerow(features_csv_smiles)
# 处理不带笑脸的图像
print("######## no smiles #########")
for i in imgs_no_smiles:
print(path_images_no_smiles + i)
features_csv_no_smiles = get_features(path_images_no_smiles + i)
features_csv_no_smiles.append(0)
print("positions of lips:", features_csv_no_smiles, "\n")
# 写入CSV
writer.writerow(features_csv_no_smiles)
# 数据筛选
# select()
# 写入CSV
# write_into_CSV()
利用sklearn提取训练集X_train和测试集X_test
完整代码
# pandas 读取 CSV
import pandas as pd
# 分割数据
from sklearn.model_selection import train_test_split
# 用于数据预加工标准化
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # 线性模型中的 Logistic 回归模型
from sklearn.neural_network import MLPClassifier # 神经网络模型中的多层网络模型
from sklearn.svm import LinearSVC # SVM 模型中的线性 SVC 模型
from sklearn.linear_model import SGDClassifier # 线性模型中的随机梯度下降模型
import joblib
# 从 csv 读取数据
def pre_data():
# 41 维表头
column_names = []
for i in range(0, 40):
column_names.append("feature_" + str(i + 1))
column_names.append("output")
# read csv
rd_csv = pd.read_csv("data/data_csvs/data.csv", names=column_names)
# 输出 csv 文件的维度
# print("shape:", rd_csv.shape)
X_train, X_test, y_train, y_test = train_test_split(
# input 0-40
# output 41
rd_csv[column_names[0:40]],
rd_csv[column_names[40]],
# 25% for testing, 75% for training
test_size=0.25,
random_state=33)
return X_train, X_test, y_train, y_test
path_models = "data/data_models/"
# LR, logistic regression, 逻辑斯特回归分类(线性模型)
def model_LR():
# get data
X_train_LR, X_test_LR, y_train_LR, y_test_LR = pre_data()
# 数据预加工
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导
ss_LR = StandardScaler()
X_train_LR = ss_LR.fit_transform(X_train_LR)
X_test_LR = ss_LR.transform(X_test_LR)
# 初始化 LogisticRegression
LR = LogisticRegression()
# 调用 LogisticRegression 中的 fit() 来训练模型参数
LR.fit(X_train_LR, y_train_LR)
# save LR model
joblib.dump(LR, path_models + "model_LR.m")
# 评分函数
score_LR = LR.score(X_test_LR, y_test_LR)
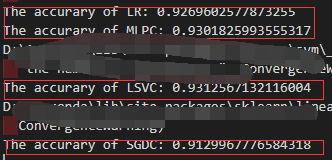
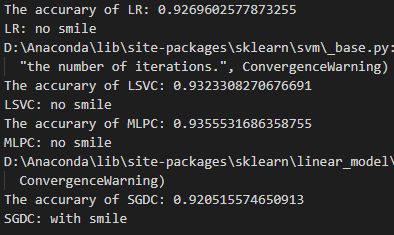
print("The accurary of LR:", score_LR)
# print(type(ss_LR))
return (ss_LR)
# model_LR()
# MLPC, Multi-layer Perceptron Classifier, 多层感知机分类(神经网络)
def model_MLPC():
# get data
X_train_MLPC, X_test_MLPC, y_train_MLPC, y_test_MLPC = pre_data()
# 数据预加工
ss_MLPC = StandardScaler()
X_train_MLPC = ss_MLPC.fit_transform(X_train_MLPC)
X_test_MLPC = ss_MLPC.transform(X_test_MLPC)
# 初始化 MLPC
MLPC = MLPClassifier(hidden_layer_sizes=(13, 13, 13), max_iter=500)
# 调用 MLPC 中的 fit() 来训练模型参数
MLPC.fit(X_train_MLPC, y_train_MLPC)
# save MLPC model
joblib.dump(MLPC, path_models + "model_MLPC.m")
# 评分函数
score_MLPC = MLPC.score(X_test_MLPC, y_test_MLPC)
print("The accurary of MLPC:", score_MLPC)
return (ss_MLPC)
# model_MLPC()
# Linear SVC, Linear Supported Vector Classifier, 线性支持向量分类(SVM支持向量机)
def model_LSVC():
# get data
X_train_LSVC, X_test_LSVC, y_train_LSVC, y_test_LSVC = pre_data()
# 数据预加工
ss_LSVC = StandardScaler()
X_train_LSVC = ss_LSVC.fit_transform(X_train_LSVC)
X_test_LSVC = ss_LSVC.transform(X_test_LSVC)
# 初始化 LSVC
LSVC = LinearSVC()
# 调用 LSVC 中的 fit() 来训练模型参数
LSVC.fit(X_train_LSVC, y_train_LSVC)
# save LSVC model
joblib.dump(LSVC, path_models + "model_LSVC.m")
# 评分函数
score_LSVC = LSVC.score(X_test_LSVC, y_test_LSVC)
print("The accurary of LSVC:", score_LSVC)
return ss_LSVC
# model_LSVC()
# SGDC, Stochastic Gradient Decent Classifier, 随机梯度下降法求解(线性模型)
def model_SGDC():
# get data
X_train_SGDC, X_test_SGDC, y_train_SGDC, y_test_SGDC = pre_data()
# 数据预加工
ss_SGDC = StandardScaler()
X_train_SGDC = ss_SGDC.fit_transform(X_train_SGDC)
X_test_SGDC = ss_SGDC.transform(X_test_SGDC)
# 初始化 SGDC
SGDC = SGDClassifier(max_iter=5)
# 调用 SGDC 中的 fit() 来训练模型参数
SGDC.fit(X_train_SGDC, y_train_SGDC)
# save SGDC model
joblib.dump(SGDC, path_models + "model_SGDC.m")
# 评分函数
score_SGDC = SGDC.score(X_test_SGDC, y_test_SGDC)
print("The accurary of SGDC:", score_SGDC)
return ss_SGDC
# model_SGDC()
模型测试
完整代码
# use the saved model
from sklearn.externals import joblib
from get_features import get_features
import ML_ways_sklearn
from cv2 import cv2
# path of test img
path_test_img = "data/data_imgs/test_imgs/sunxiaoc.jpg"
# 提取单张40维度特征
positions_lip_test = get_features(path_test_img)
# path of models
path_models = "data/data_models/"
print("The result of"+path_test_img+":")
print('\n')
# ######### LR ###########
LR = joblib.load(path_models+"model_LR.m")
ss_LR = ML_ways_sklearn.model_LR()
X_test_LR = ss_LR.transform([positions_lip_test])
y_predict_LR = str(LR.predict(X_test_LR)[0]).replace('0', "no smile").replace('1', "with smile")
print("LR:", y_predict_LR)
# ######### LSVC ###########
LSVC = joblib.load(path_models+"model_LSVC.m")
ss_LSVC = ML_ways_sklearn.model_LSVC()
X_test_LSVC = ss_LSVC.transform([positions_lip_test])
y_predict_LSVC = str(LSVC.predict(X_test_LSVC)[0]).replace('0', "no smile").replace('1', "with smile")
print("LSVC:", y_predict_LSVC)
# ######### MLPC ###########
MLPC = joblib.load(path_models+"model_MLPC.m")
ss_MLPC = ML_ways_sklearn.model_MLPC()
X_test_MLPC = ss_MLPC.transform([positions_lip_test])
y_predict_MLPC = str(MLPC.predict(X_test_MLPC)[0]).replace('0', "no smile").replace('1', "with smile")
print("MLPC:", y_predict_MLPC)
# ######### SGDC ###########
SGDC = joblib.load(path_models+"model_SGDC.m")
ss_SGDC = ML_ways_sklearn.model_SGDC()
X_test_SGDC = ss_SGDC.transform([positions_lip_test])
y_predict_SGDC = str(SGDC.predict(X_test_SGDC)[0]).replace('0', "no smile").replace('1', "with smile")
print("SGDC:", y_predict_SGDC)
img_test = cv2.imread(path_test_img)
img_height = int(img_test.shape[0])
img_width = int(img_test.shape[1])
# show the results on the image
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img_test, "LR: "+y_predict_LR, (int(img_height/10), int(img_width/10)), font, 0.5, (84, 255, 159), 1, cv2.LINE_AA)
cv2.putText(img_test, "LSVC: "+y_predict_LSVC, (int(img_height/10), int(img_width/10*2)), font, 0.5, (84, 255, 159), 1, cv2.LINE_AA)
cv2.putText(img_test, "MLPC: "+y_predict_MLPC, (int(img_height/10), int(img_width/10)*3), font, 0.5, (84, 255, 159), 1, cv2.LINE_AA)
cv2.putText(img_test, "SGDC: "+y_predict_SGDC, (int(img_height/10), int(img_width/10)*4), font, 0.5, (84, 255, 159), 1, cv2.LINE_AA)
cv2.namedWindow("img", 2)
cv2.imshow("img", img_test)
cv2.waitKey(0)
显示嘴部特征点
完整代码
# 显示嘴部特征点
# Draw the positions of someone's lip
import dlib # 人脸识别的库 Dlib
from cv2 import cv2 # 图像处理的库 OpenCv
from get_features import get_features # return the positions of feature points
path_test_img = "data/data_imgs/test_imgs/test1.jpg"
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# Get lip's positions of features points
positions_lip = get_features(path_test_img)
img_rd = cv2.imread(path_test_img)
# Draw on the lip points
for i in range(0, len(positions_lip), 2):
print(positions_lip[i], positions_lip[i+1])
cv2.circle(img_rd, tuple([positions_lip[i], positions_lip[i+1]]), radius=1, color=(0, 255, 0))
cv2.namedWindow("img_read", 2)
cv2.imshow("img_read", img_rd)
cv2.waitKey(0)

视频检测
完整代码
# use the saved model
from sklearn.externals import joblib
import ML_ways_sklearn
import dlib # 人脸处理的库 Dlib
import numpy as np # 数据处理的库 numpy
from cv2 import cv2 # 图像处理的库 OpenCv
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# OpenCv 调用摄像头
cap = cv2.VideoCapture(0)
# 设置视频参数
cap.set(3, 480)
def get_features(img_rd):
# 输入: img_rd: 图像文件
# 输出: positions_lip_arr: feature point 49 to feature point 68, 20 feature points / 40D in all
# 取灰度
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 计算68点坐标
positions_68_arr = []
faces = detector(img_gray, 0)
landmarks = np.matrix([[p.x, p.y] for p in predictor(img_rd, faces[0]).parts()])
for idx, point in enumerate(landmarks):
# 68点的坐标
pos = (point[0, 0], point[0, 1])
positions_68_arr.append(pos)
positions_lip_arr = []
# 将点 49-68 写入 CSV
# 即 positions_68_arr[48]-positions_68_arr[67]
for i in range(48, 68):
positions_lip_arr.append(positions_68_arr[i][0])
positions_lip_arr.append(positions_68_arr[i][1])
return positions_lip_arr
while cap.isOpened():
# 480 height * 640 width
flag, img_rd = cap.read()
kk = cv2.waitKey(1)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 人脸数 faces
faces = detector(img_gray, 0)
# 检测到人脸
if len(faces) != 0:
# 提取单张40维度特征
positions_lip_test = get_features(img_rd)
# path of models
path_models = "data/data_models/"
# ######### LR ###########
LR = joblib.load(path_models+"model_LR.m")
ss_LR = ML_ways_sklearn.model_LR()
X_test_LR = ss_LR.transform([positions_lip_test])
y_predict_LR = str(LR.predict(X_test_LR)[0]).replace('0', "no smile").replace('1', "with smile")
print("LR:", y_predict_LR)
# ######### LSVC ###########
LSVC = joblib.load(path_models+"model_LSVC.m")
ss_LSVC = ML_ways_sklearn.model_LSVC()
X_test_LSVC = ss_LSVC.transform([positions_lip_test])
y_predict_LSVC = str(LSVC.predict(X_test_LSVC)[0]).replace('0', "no smile").replace('1', "with smile")
print("LSVC:", y_predict_LSVC)
# ######### MLPC ###########
MLPC = joblib.load(path_models+"model_MLPC.m")
ss_MLPC = ML_ways_sklearn.model_MLPC()
X_test_MLPC = ss_MLPC.transform([positions_lip_test])
y_predict_MLPC = str(MLPC.predict(X_test_MLPC)[0]).replace('0', "no smile").replace('1', "with smile")
print("MLPC:", y_predict_MLPC)
# ######### SGDC ###########
SGDC = joblib.load(path_models+"model_SGDC.m")
ss_SGDC = ML_ways_sklearn.model_SGDC()
X_test_SGDC = ss_SGDC.transform([positions_lip_test])
y_predict_SGDC = str(SGDC.predict(X_test_SGDC)[0]).replace('0', "no smile").replace('1', "with smile")
print("SGDC:", y_predict_SGDC)
print('\n')
# 按下 'q' 键退出
if kk == ord('q'):
break
# 窗口显示
# cv2.namedWindow("camera", 0) # 如果需要摄像头窗口大小可调
cv2.imshow("camera", img_rd)
# 释放摄像头
cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()

安装TensorFlow(python3.7)
## 创建Anaconda虚拟环境Python3.6
conda create -n `你的命名` python=3.6

进入虚拟环境

python3.7安装TensorFlow

安装Keras
pip install keras
划分数据集
mkdir.py
import tensorflow as tf
import os,shutil
# The path to the directory where the original
# dataset was uncompressed
original_dataset_dir = 'D:\\Desktop\\Face_recognition\\tensorflow\\genki4k '
# The directory where we will
# store our smaller dataset
base_dir = 'D:\\Desktop\\Face_recognition\\tensorflow\\smile_data'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training smile pictures
train_smile_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_smile_dir)
# Directory with our training unsmile pictures
train_unsmile_dir = os.path.join(train_dir, 'unsmile')
os.mkdir(train_unsmile_dir)
# Directory with our validation smile pictures
validation_smile_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_smile_dir)
# Directory with our validation unsmile pictures
validation_unsmile_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_unsmile_dir)
# Directory with our validation smile pictures
test_smile_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_smile_dir)
# Directory with our validation unsmile pictures
test_unsmile_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_unsmile_dir)
运行结果:
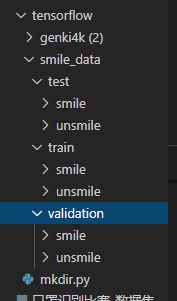
将笑脸和非笑脸放入相应的文件夹
查看一下图片数量:
lenpic.py
import keras
import os, shutil
train_smile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\train\\smile\\"
train_umsmile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\train\\unsmile\\"
test_smile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\test\\smile\\"
test_umsmile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\test/unsmile\\"
validation_smile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\validation\\smile\\"
validation_unsmile_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\validation\\unsmile\\"
train_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\train\\"
test_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\test\\"
validation_dir="D:\\Desktop\\Face_recognition\\tensorflow\\smile_data\\validation\\"
print('total training smile images:', len(os.listdir(train_smile_dir)))
print('total training unsmile images:', len(os.listdir(train_umsmile_dir)))
print('total testing smile images:', len(os.listdir(test_smile_dir)))
print('total testing unsmile images:', len(os.listdir(test_umsmile_dir)))
print('total validation smile images:', len(os.listdir(validation_smile_dir)))
print('total validation unsmile images:', len(os.listdir(validation_unsmile_dir)))

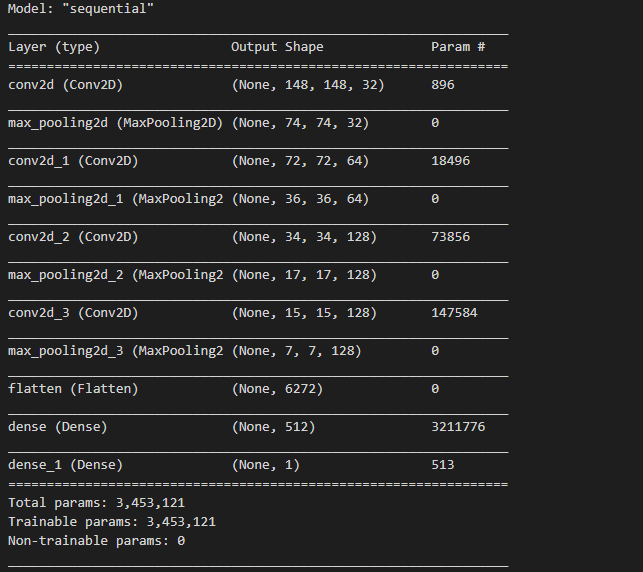
创建模型
Cmodle.py
'''
创建模型
'''
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
对图片归一化:
normalize.py
'''
对图片进行归一化处理
'''
from keras import optimizers
from Cmodel import model
from lenpic import train_dir,validation_dir,test_dir
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 目标文件目录
train_dir,
#所有图片的size必须是150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch)
break
print(train_generator.class_indices)

模型训练
Tmodle.py
'''
模型训练
'''
from Cmodel import model
from normalize import train_generator,validation_generator
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=10,
validation_data=validation_generator,
validation_steps=50)
model.save('model.save('D:\\Desktop\\Face_recognition\\tensorflow\\smileAndUnsmile_1.h5')')
'''
画出训练集与验证集的精确度与损失度的图形
'''
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


数据增强
endata.py
'''
数据增强
'''
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
'''
查看数据增强后的图片变化
'''
import matplotlib.pyplot as plt
from lenpic import train_smile_dir
import os
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
img_path = fnames[8]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()

创建网络
Cnet.py
'''
创建网络
'''
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
再次进行训练模型
T2modle.py
'''
再次训练模型
'''
#归一化处理
from keras.preprocessing.image import ImageDataGenerator
from lenpic import train_dir, validation_dir
from Cnet import model
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100, # 训练次数
validation_data=validation_generator,
validation_steps=50)
# 保存训练模型
model.save('D:\\Desktop\\Face_recognition\\tensorflow\\smileAndUnsmile_2.h5')
训练50次:
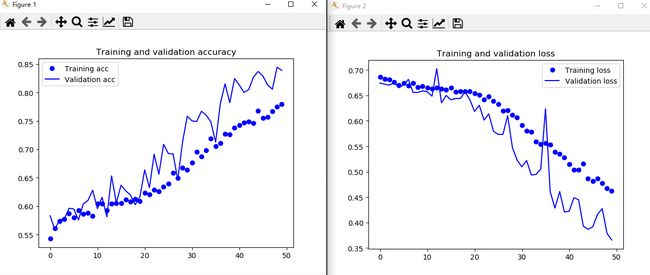
训练100次:
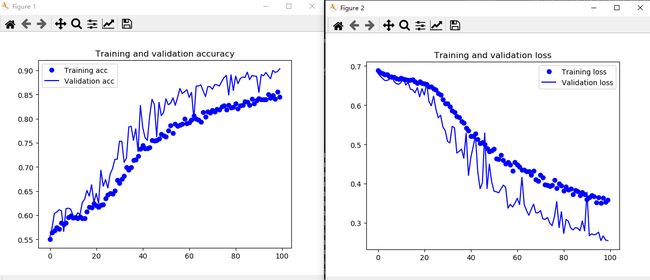
使用模型进行视频实时检测
'''
检测视频或者摄像头中的人脸
'''
from cv2 import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('D:\\Desktop\\Face_recognition\\tensorflow\\smileAndUnsmile_2.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()

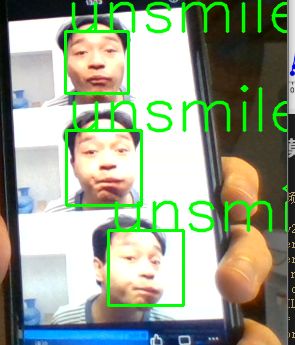

口罩识别
划分数据集
mkdir.py
# The path to the directory where the original
# dataset was uncompressed
# The directory where we will
# store our smaller dataset
base_dir = 'D:\\Desktop\\Face_recognition\\Mask\\mask_data'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training mask pictures
train_mask_dir = os.path.join(train_dir, 'have_mask')
os.mkdir(train_mask_dir)
# Directory with our training no_mask pictures
train_no_mask_dir = os.path.join(train_dir, 'no_mask')
os.mkdir(train_no_mask_dir)
# Directory with our validation mask pictures
validation_mask_dir = os.path.join(validation_dir, 'have_mask')
os.mkdir(validation_mask_dir)
# Directory with our validation no_mask pictures
validation_no_mask_dir = os.path.join(validation_dir, 'no_mask')
os.mkdir(validation_no_mask_dir)
# Directory with our validation mask pictures
test_mask_dir = os.path.join(test_dir, 'have_mask')
os.mkdir(test_mask_dir)
# Directory with our validation no_mask pictures
test_no_mask_dir = os.path.join(test_dir, 'no_mask')
os.mkdir(test_no_mask_dir)
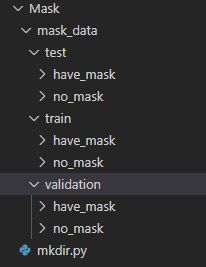
添加口罩图片到相应文件夹
下载口罩数据集
下载地址
由于它是多个文件存储的,所以要将图片合并到一个文件夹
move.py
import os
outer_path = 'D:\\Desktop\\Face_recognition\\Mask\\have_mask\\RWMFD_part_1'
folderlist = os.listdir(outer_path)
print(folderlist) #列举文件夹
i = 0
for folder in folderlist:
inner_path = os.path.join(outer_path, folder)
total_num_folder = len(folderlist) #文件夹的总数
print('total have %d folders' % (total_num_folder)) #打印文件夹的总数
filelist = os.listdir(inner_path) #列举图片
for item in filelist:
total_num_file = len(filelist) #单个文件夹内图片的总数
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(inner_path), item) #原图的地址
dst = os.path.join(os.path.abspath(inner_path), str('D:\\Desktop\\Face_recognition\\Mask\\have_mask\\RWMFD_part_1\\MASK') + '_' + str(i) + '.jpg') #新图的地址(这里可以把str(folder) + '_' + str(i) + '.jpg'改成你想改的名称)
try:
os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i += 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num_file, i))
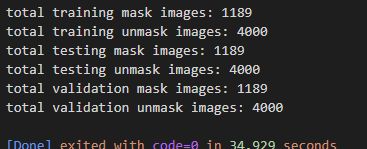
查看图片数量
lenpic.py
import keras
import os, shutil
train_mask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\train\\have_mask\\"
train_ummask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\train\\no_mask\\"
test_mask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\test\\have_mask\\"
test_ummask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\test\\no_mask\\"
validation_mask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\validation\\have_mask\\"
validation_unmask_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\validation\\no_mask\\"
train_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\train\\"
test_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\test\\"
validation_dir="D:\\Desktop\\Face_recognition\\Mask\\mask_data\\validation\\"
print('total training mask images:', len(os.listdir(train_mask_dir)))
print('total training unmask images:', len(os.listdir(train_ummask_dir)))
print('total testing mask images:', len(os.listdir(test_mask_dir)))
print('total testing unmask images:', len(os.listdir(test_ummask_dir)))
print('total validation mask images:', len(os.listdir(validation_mask_dir)))
print('total validation unmask images:', len(os.listdir(validation_unmask_dir)))
数据增强
endata.py
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
'''
查看数据增强后的图片变化
'''
import matplotlib.pyplot as plt
from lenpic import train_mask_dir
import os
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_mask_dir, fname) for fname in os.listdir(train_mask_dir)]
img_path = fnames[8]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
创建网络
Cnet.py
'''
创建网络
'''
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
模型训练 并画出训练集与验证集的精确度与损失度的图形
Tmodle.py
#归一化处理
from keras.preprocessing.image import ImageDataGenerator
from lenpic import train_dir, validation_dir
from Cnet import model
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100, # 训练次数
validation_data=validation_generator,
validation_steps=50)
# 保存训练模型
model.save('D:\\Desktop\\Face_recognition\\Mask\\maskAndUnmask_1.h5')
'''
画出训练集与验证集的精确度与损失度的图形
'''
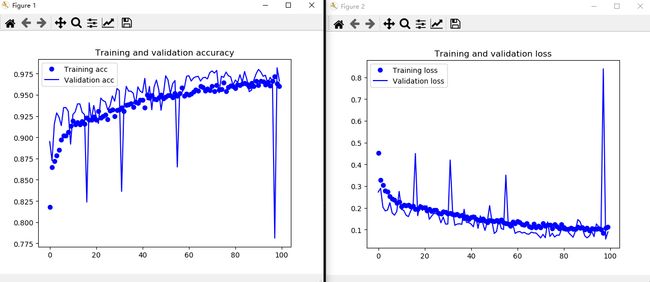
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

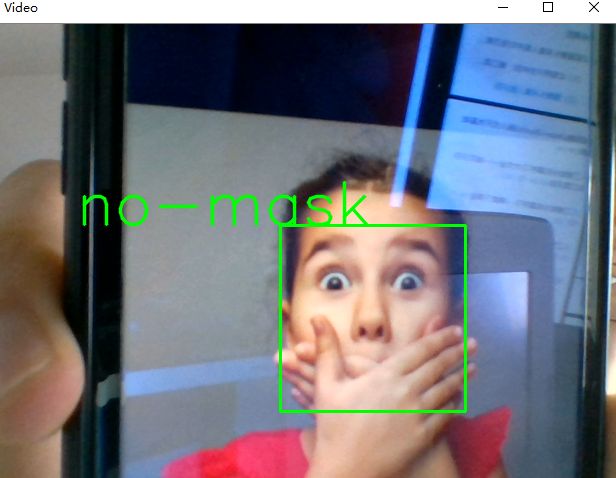
摄像头检测
camera.py
'''
检测视频或者摄像头中的人脸
'''
from cv2 import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('D:\\Desktop\\Face_recognition\\Mask\\maskAndUnmask_1.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result='unmask'
else:
result='mask'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('mask', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()


参考文献
人工智能与机器学习
Dlib模型人脸特征检测原理及demo
cungudafa的博客