实例分割论文调研
目录
- 综述
- CVPR18
-
- Non-local Neural Networks
- Path Aggregation Network for Instance Segmentation
- CVPR19
-
- Mask Scoring R-CNN
- Hybrid Task Cascade for Instance Segmentation
- Pose2Seg: Detection Free Human Instance Segmentation
- S4Net: Single Stage Salient-Instance Segmentation
- Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations
- CVPR20
-
- Deep Snake for Real-Time Instance Segmentation
- PolarMask: Single Shot Instance Segmentation with Polar Representation
- BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
- CenterMask: Single Shot Instance Segmentation With Point Representation
- CenterMask: Real-Time Anchor-Free Instance Segmentation
- FGN: Fully Guided Network for Few-Shot Instance Segmentation
- Learning Saliency Propagation for Semi-Supervised Instance Segmentation
- Video Instance Segmentation Tracking With a Modified VAE Architecture
- FAPIS: A Few-shot Anchor-free Part-based Instance Segmenter
- End-to-End Video Instance Segmentation with Transformers(使用Transformer的端到端视频实例分割)
- ICCV2019YOLACT
-
- YOLACT++ Better Real-time Instance Segmentation
- ICCV2019 TensorMask
- ECCV2020 SOLO: Segmenting Objects by Locations
-
- SOLOv2
综述
A Survey on Instance Segmentation: State of the art
链接
解读https://zhuanlan.zhihu.com/p/165135767

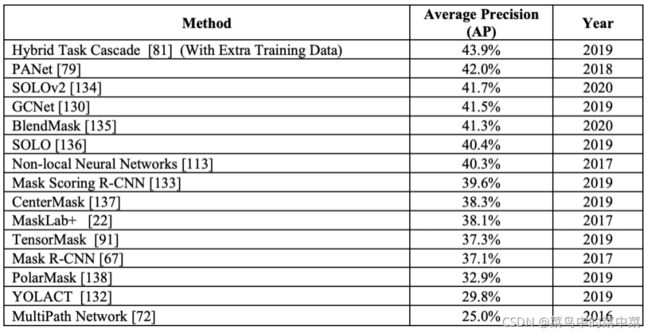
CVPR18
Non-local Neural Networks
卷积操作和循环操作都是一次处理一个局部邻居的构建块。在本文中,我们提出了非局部操作作为一个用来捕获远程依赖关系的通用构建块族。受计算机视觉中经典的非局部均值方法的启发,我们的非局部操作计算一个位置的响应作为所有位置特征的加权和。这个构建块可以插入到许多计算机视觉架构中。在视频分类的任务中,即使没有任何花哨子,我们的非本地模型也可以在动力学和字符串数据集上竞争或优于当前的竞争获胜者。在静态图像识别中,我们的非局部模型改进了COCO任务套件上的目标检测/分割和姿态估计。代码可在
Path Aggregation Network for Instance Segmentation
信息在神经网络中传播的方式非常重要。在本文中,我们提出了路径聚合网络(PANet),旨在促进基于提议的实例分割框架中的信息流。具体来说,我们通过自下而上的路径增强在较低层使用准确的定位信号增强整个特征层次结构,从而缩短了较低层和最顶层特征之间的信息路径。我们提出了自适应特征池,它将特征网格和所有特征级别联系起来,使每个特征级别中的有用信息直接传播到以下提议子网络。为每个提议创建一个捕获不同视图的补充分支,以进一步改进掩码预测。这些改进很容易实现,只是有一些额外的计算开销。我们的 PANet 在没有大批量训练的情况下在 COCO 2017 Challenge Instance Segmentation 任务中获得第一名,在对象检测任务中获得第二名。它在 MVD 和 Cityscapes 上也是最先进的
代码
CVPR19
Mask Scoring R-CNN
解读https://www.cnblogs.com/wemo/p/10505970.html
https://zhuanlan.zhihu.com/p/64322544
让深度网络意识到自己预测的质量是一个有趣但重要的问题。在实例分割的任务中,在大多数实例分割框架中,实例分类的置信度被用作掩码质量分数。然而,掩码质量,量化为实例掩码与其基本事实之间的 IoU,通常与分类分数没有很好的相关性。在本文中,我们研究了这个问题并提出了 Mask Scoring R-CNN,它包含一个网络块来学习预测实例掩码的质量。提议的网络块将实例特征和相应的预测掩码一起用于回归掩码 IoU。掩码评分策略校准掩码质量和掩码分数之间的错位,并通过在 COCO AP 评估期间优先考虑更准确的掩码预测来提高实例分割性能。通过对 COCO 数据集的广泛评估,Mask Scoring R-CNN 为不同模型带来了一致且显着的增益,并且优于最先进的 Mask R-CNN。我们希望我们简单有效的方法将为改进实例分割提供一个新的方向。我们方法的源代码
Hybrid Task Cascade for Instance Segmentation
解读https://mp.weixin.qq.com/s/xug0xKfc9RgJEUci1a_xog
https://arxiv.org/abs/1901.07518
Cascade 是一种经典而强大的架构,它提高了各种任务的性能。然而,如何将级联引入实例分割仍然是一个悬而未决的问题。Cascade R-CNN 和 Mask R-CNN 的简单组合只能带来有限的增益。在探索更有效的方法时,我们发现成功实例分割级联的关键是充分利用检测和分割之间的相互关系。在这项工作中,我们提出了一个新的框架,混合任务级联(HTC),它在两个重要方面有所不同:(1)不是分别对这两个任务进行级联细化,而是将它们交织在一起进行联合多阶段处理;(2)采用全卷积分支提供空间上下文,有助于区分硬前景和杂乱背景。总体,该框架可以逐步学习更多判别特征,同时在每个阶段将互补特征整合在一起。在没有花里胡哨的情况下,单个 HTC 在 MSCOCO 数据集上比强大的 Cascade Mask R-CNN 基线提高了 38.4 和 1.5。此外,我们的整个系统在测试挑战拆分上实现了 48.6 个掩码 AP,在 COCO 2018 挑战目标检测任务中排名第一。代码可在以下位置获得: 这个 https 网址。
Pose2Seg: Detection Free Human Instance Segmentation
https://arxiv.org/abs/1803.10683
图像实例分割的标准方法是先进行目标检测,然后将目标从检测边界框中分割出来。最近,像Mask R-CNN这样的深度学习方法联合执行它们。然而,很少有研究考虑到“人”类别的独特性,这可以很好地定义的姿势骨骼。此外,与使用边界框相比,人体姿态骨架可以更好地区分严重遮挡的实例。在本文中,我们提出了一个全新的基于姿势的人体实例分割框架
S4Net: Single Stage Salient-Instance Segmentation
https://mftp.mmcheng.net/Papers/19cvprS4Net.pdf
在本文中,我们考虑了一个有趣的问题—显著的实例分割。除了生成包围盒,我们的网络还输出高质量的实例级段。考虑到每个目标的类别独立性,设计了单阶段显著实例分割框架,并提出了新的分割分支。我们的新分支不仅考虑每个检测窗口内的局部上下文,还考虑它周围的上下文,使我们能够区分相同范围内的实例,即使有阻塞。我们的网络是端到端可训练的,运行速度很快
这篇文主要讲的是显著实例分割(salient instance segmentation),输入一张图不仅能获得bounding box,还可以获得高质量的分割。显著实例分割只针对图像中最“突出”、最“感兴趣”的目标,而不是所有目标。标题的single stage是指边框回归只有一次。
Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations
本文提出了一种以图像级类标签作为监督学习实例分割的新方法。我们的方法生成训练图像的伪实例分割标签,用于训练完全监督的模型。为了生成伪标签,我们首先从图像分类模型的注意力图中识别对象类的置信种子区域,并传播它们以发现具有准确边界的整个实例区域。为此,我们提出了 IRNet,它可以估计单个实例的粗糙区域并检测不同对象类之间的边界。因此,它能够为种子分配实例标签并在边界内传播它们,以便可以准确估计实例的整个区域。此外,IRNet 在注意力图上使用像素间关系进行训练,因此不需要额外的监督。我们使用 IRNet 的方法在 PASCAL VOC 2012 数据集上取得了出色的表现,不仅超越了之前以相同监督水平训练的最先进的模型,而且超越了一些依赖更强监督的先前模型。
CVPR20
Deep Snake for Real-Time Instance Segmentation
https://github.com/zju3dv/snake/
解读https://zhuanlan.zhihu.com/p/134111177
本文介绍了一种新的基于轮廓的方法,称为深蛇,用于实时实例分割。与最近一些直接从图像中回归对象边界点坐标的方法不同,深蛇使用神经网络迭代变形初始轮廓以匹配对象边界,它通过基于学习的方法实现了蛇算法的经典思想. 对于轮廓上的结构化特征学习,我们建议在深蛇中使用循环卷积,与通用图卷积相比,它更好地利用了轮廓的循环图结构。基于深蛇,我们开发了一个两阶段的管道进行实例分割:初始轮廓提议和轮廓变形,可以处理对象定位中的错误。\times 1080Ti GPU 上的 512 张图像。
PolarMask: Single Shot Instance Segmentation with Polar Representation
在本文中,我们介绍了一种无锚框和单镜头实例分割方法,该方法概念简单,完全卷积,可以用作实例分割的掩码预测模块,通过将其轻松嵌入到大多数现成的检测中方法。我们的方法称为 PolarMask,将实例分割问题表述为极坐标中的实例中心分类和密集距离回归。此外,我们分别提出了两种有效的方法来处理采样高质量中心样本和优化密集距离回归,这可以显着提高性能并简化训练过程。在没有任何花里胡哨的情况下,PolarMask 在具有挑战性的 COCO 数据集上通过单模型和单尺度训练/测试在 mask mAP 中达到了 32.9%。首次,我们展示了一个更简单和灵活的实例分割框架,可实现具有竞争力的准确性。我们希望所提出的 PolarMask 框架可以作为单镜头实例分割任务的基础和强大的基线。代码可在以下位置获得: 这个 http 网址。
BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
解读https://blog.csdn.net/qq_44666320/article/details/108112310
detectron2可以实现
实例分割是基本的视觉任务之一。最近,全卷积实例分割方法引起了很多关注,因为它们通常比 Mask R-CNN 等两阶段方法更简单、更有效。迄今为止,当模型具有相似的计算复杂度时,几乎所有这些方法在掩码精度方面都落后于两阶段掩码 R-CNN 方法,留下了很大的改进空间。
在这项工作中,我们通过将实例级信息与具有较低级细粒度的语义信息有效结合来实现改进的掩码预测。我们的主要贡献是一个混合器模块,它从自上而下和自下而上的实例分割方法中汲取灵感。提出的 BlendMask 可以用很少的通道有效地预测密集的每像素位置敏感的实例特征,并且只用一个卷积层为每个实例学习注意力图,因此推理速度快。BlendMask 可以很容易地与最先进的单阶段检测框架结合,并在相同的训练计划下优于 Mask R-CNN,同时速度提高 20%。BlendMask 的轻量级版本达到34.2%在单个 1080Ti GPU 卡上评估的 25 FPS 的 mAP。由于它的简单性和有效性,我们希望我们的 BlendMask 可以作为一个简单而强大的基线,用于广泛的实例预测任务。代码
CenterMask: Single Shot Instance Segmentation With Point Representation
美团的解读
在本文中,我们提出了一种简单、快速和准确的单镜头实例分割方法。单阶段实例分割有两个主要挑战:对象实例区分和逐像素特征对齐。因此,我们将实例分割分解为两个并行的子任务:即使在重叠条件下也能分离实例的局部形状预测,以及以像素到像素的方式分割整个图像的全局显着性生成。两个分支的输出被组合起来形成最终的实例掩码。为了实现这一点,从对象中心点的表示中采用了局部形状信息。完全从头开始训练,没有任何花里胡哨的东西,提议的 CenterMask 以 12.3 fps 的速度实现了 34.5 mask AP,在具有挑战性的 COCO 数据集上使用具有单一规模训练/测试的单一模型。除了慢 5 倍的 TensorMask 之外,准确率高于所有其他单阶段实例分割方法,这显示了 CenterMask 的有效性。此外,我们的方法可以轻松嵌入到其他单级目标检测器(如 FCOS)中并且表现良好,展示了 CenterMask 的泛化能力。
CenterMask: Real-Time Anchor-Free Instance Segmentation
韩国的,解读https://blog.csdn.net/shanglianlm/article/details/106482705
我们提出了一种简单而有效的无锚实例分割,称为 CenterMask,它在与 Mask R-CNN 相同的脉络中向无锚单阶段对象检测器 (FCOS) 添加了一个新的空间注意力引导掩码 (SAG-Mask) 分支. 插入 FCOS 对象检测器后,SAG-Mask 分支使用空间注意力图预测每个框上的分割掩码,有助于专注于信息像素并抑制噪声。我们还提出了具有两种有效策略的改进型 VoVNetV2:添加 (1) 残差连接以缓解较大 VoVNet 的饱和问题,以及 (2) 有效的 Squeeze-Excitation (eSE) 处理原始 SE 的信息丢失问题。使用 SAG-Mask 和 VoVNetV2,我们设计了分别针对大模型和小模型的 CenterMask 和 CenterMask-Lite。CenterMask 以更快的速度超越了所有以前的最先进模型。CenterMask-Lite 还实现了 33.4% mask AP / 38.0% box AP,在 Titan Xp 上以超过 35fps 的速度分别超过最先进的 2.6 / 7.0 AP 增益。我们希望 CenterMask 和 VoVNetV2 可以分别作为各种视觉任务的实时实例分割和骨干网络的可靠基线。代码。
FGN: Fully Guided Network for Few-Shot Instance Segmentation
小样本学习+实例分割
Learning Saliency Propagation for Semi-Supervised Instance Segmentation
半监督学习+实例分割
论文
实例分割对于建模和注释来说都是一项具有挑战性的任务。由于注释成本高,由于监督量有限,建模变得更加困难。我们旨在通过利用大量检测监督来提高现有实例分割模型的准确性。我们提出了 ShapeProp,它学习激活对象检测中的显着区域,并通过迭代可学习消息传递模块将这些区域传播到整个实例。ShapeProp 可以从更多的边界框监督中受益,以更准确地定位实例并利用来自大量实例的特征激活来实现更准确的分割。我们在三个数据集(MS COCO、PASCAL VOC、和 BDD100k)具有基于两阶段(Mask R-CNN)和单阶段(RetinaMask)模型的不同监督设置。结果表明,我们的方法为半监督实例分割建立了新的技术状态。
代码https://github.com/ucbdrive/ShapeProp
Video Instance Segmentation Tracking With a Modified VAE Architecture
视频实例分割跟踪
视频实例分割(VIS)旨在为视频中的每一帧分割和关联所有预定义类的实例。先前的方法通常首先对帧或剪辑进行分割,然后通过跟踪或匹配来合并不完整的结果。这些方法可能会导致合并步骤中的错误累积。相反,我们提出了一种新的范式——Propose-Reduce,通过一个步骤为输入视频生成完整的序列。我们在现有的图像级实例分割网络上进一步构建了一个序列传播头,用于长期传播。为了确保我们提出的框架的鲁棒性和高召回率,提出了多个序列,其中减少了同一实例的冗余序列。我们在两个有代表性的基准数据集上实现了最先进的性能——我们获得了 47。YouTube-VIS 验证集上的 AP 为 6%,DAVIS-UVOS 验证集上的 J&F 为 70.4%。代码
FAPIS: A Few-shot Anchor-free Part-based Instance Segmenter
小样本+实例分割,无代码
本文是关于少镜头实例分割,其中训练和测试图像集不共享相同的对象类。我们指定并评估了一个新的无锚点的新的基于部分的实例分割器 FAPIS。我们的主要新颖之处在于对跨训练对象类共享的潜在对象部分进行显式建模,这有望促进我们在测试中对新类的少量学习。我们指定了一个新的无锚物体检测器,旨在对前景边界框的位置进行评分和回归,以及估计每个框内潜在部分的相对重要性。此外,我们指定了一个新网络,用于为每个检测到的边界框内的最终实例分割描绘和加权潜在部分。我们对基准 COCO-20i 数据集的评估表明,我们的表现明显优于现有技术。
End-to-End Video Instance Segmentation with Transformers(使用Transformer的端到端视频实例分割)
代码
视频实例分割 (VIS) 是一项需要同时对视频中感兴趣的对象实例进行分类、分割和跟踪的任务。最近的方法通常会开发复杂的管道来解决此任务。在这里,我们提出了一种基于 Transformers 的新视频实例分割框架,称为 VisTR,它将 VIS 任务视为直接的端到端并行序列解码/预测问题。给定一个由多个图像帧组成的视频剪辑作为输入,VisTR 直接输出视频中每个实例的掩码序列。其核心是一种新的、有效的实例序列匹配和分割策略,它在序列级别作为一个整体来监督和分割实例。VisTR 以相似性学习的相同视角构建实例分割和跟踪,因此大大简化了整个管道,并且与现有方法有很大不同。没有花里胡哨,VisTR 在所有现有 VIS 模型中实现了最高的速度,在 YouTube-VIS 数据集上使用单一模型的方法中取得了最好的结果。我们首次展示了一个基于 Transformers 的更简单、更快的视频实例分割框架,从而实现了具有竞争力的准确性。我们希望 VisTR 可以激发未来对更多视频理解任务的研究。我们展示了一个基于 Transformers 的更简单、更快的视频实例分割框架,实现了具有竞争力的准确性。我们希望 VisTR 可以激发未来对更多视频理解任务的研究。我们展示了一个基于 Transformers 的更简单、更快的视频实例分割框架,实现了具有竞争力的准确性。我们希望 VisTR 可以激发未来对更多视频理解任务的研究。
ICCV2019YOLACT
解读https://blog.csdn.net/wh8514/article/details/105520870/
我们提出了一个简单的、全卷积的实时实例分割模型,在单个 Titan Xp 上以 33.5 fps 的速度在 MS COCO 上实现了 29.8 mAP,这比任何以前的竞争方法都要快得多。此外,我们仅在一个 GPU 上训练后获得了这个结果。我们通过将实例分割分解为两个并行子任务来实现这一点:(1)生成一组原型掩码和(2)预测每个实例的掩码系数。然后我们通过将原型与掩码系数线性组合来生成实例掩码。我们发现,由于此过程不依赖于重新池化,因此此方法可生成非常高质量的掩码并免费展示时间稳定性。此外,我们分析了我们原型的紧急行为,并表明它们学会了以翻译变体的方式自行定位实例,尽管它们是完全卷积的。最后,我们还提出了 Fast NMS,这是标准 NMS 的替代品,速度快 12 毫秒,性能损失很小。代码
YOLACT++ Better Real-time Instance Segmentation
解读https://zhuanlan.zhihu.com/p/97684893
我们提出了一个简单的全卷积模型,用于实时 (>30 fps) 实例分割,该模型在单个 Titan Xp 上评估的 MS COCO 上取得了有竞争力的结果,这比以前任何最先进的方法都要快得多。此外,我们仅在一个 GPU 上训练后获得了这个结果。我们通过将实例分割分解为两个并行子任务来实现这一点:(1)生成一组原型掩码和(2)预测每个实例的掩码系数。然后我们通过将原型与掩码系数线性组合来生成实例掩码。我们发现,由于此过程不依赖于重新池化,因此此方法可生成非常高质量的掩码并免费展示时间稳定性。此外,我们分析了我们原型的紧急行为,并表明它们学会了以翻译变体的方式自行定位实例,尽管它们是完全卷积的。我们还提出了 Fast NMS,这是标准 NMS 的替代品,速度快 12 毫秒,性能损失很小。最后,通过在骨干网络中加入可变形卷积,优化具有更好锚定尺度和纵横比的预测头,并添加一个新的快速掩码重新评分分支,我们的 YOLACT++ 模型可以在 33.5 fps 的情况下在 MS COCO 上实现 34.1 mAP,即相当接近最先进的方法,同时仍然实时运行。
ICCV2019 TensorMask
解读https://zhuanlan.zhihu.com/p/61769213
在密集的规则网格上生成边界框对象预测的滑动窗口对象检测器发展迅速并被证明很受欢迎。相比之下,现代实例分割方法主要是首先检测对象边界框,然后裁剪和分割这些区域的方法,如 Mask R-CNN 所流行的那样。在这项工作中,我们研究了密集滑动窗口实例分割的范式,这是令人惊讶的探索不足。我们的核心观察是,该任务与其他密集预测任务(例如语义分割或边界框对象检测)有着根本的不同,因为每个空间位置的输出本身都是具有自己空间维度的几何结构。为了正式化,我们将密集实例分割视为 4D 张量的预测任务,并提出了一个称为 TensorMask 的通用框架,该框架明确地捕获了这种几何形状并启用了 4D 张量上的新算子。我们证明了张量视图在忽略这种结构的基线上带来了巨大的收益,并导致了与 Mask R-CNN 相当的结果。这些有希望的结果表明 TensorMask 可以作为密集掩码预测和更完整理解任务的新进展的基础。将提供代码。这些有希望的结果表明 TensorMask 可以作为密集掩码预测和更完整理解任务的新进展的基础。将提供代码。这些有希望的结果表明 TensorMask 可以作为密集掩码预测和更完整理解任务的新进展的基础。将提供代码。
ECCV2020 SOLO: Segmenting Objects by Locations
我们提出了一种新的、非常简单的图像实例分割方法。与许多其他密集预测任务(例如语义分割)相比,任意数量的实例使实例分割更具挑战性。为了预测每个实例的掩码,主流方法要么遵循 Mask R-CNN 使用的“检测然后分割”策略,要么首先预测类别掩码,然后使用聚类技术将像素分组为单个实例。我们通过引入“实例类别”的概念从全新的角度看待实例分割的任务,该概念根据实例的位置和大小为实例内的每个像素分配类别,从而很好地将实例掩码分割转换为分类可解决的问题。现在实例分割被分解为两个分类任务。我们展示了一个更简单、灵活的实例分割框架,具有强大的性能,与 Mask R-CNN 实现了同等准确度,并在准确度上优于最近的单发实例分割器。我们希望这个非常简单而强大的框架可以作为除实例分割之外的许多实例级识别任务的基线。
SOLOv2
在这项工作中,我们的目标是构建一个简单、直接、快速且性能强大的实例分割框架。我们遵循Wang等人的SOLO方法的原则。“独奏:按位置分割对象”。重要的是,我们通过动态学习对象分割器的掩码头,使掩码头以位置为条件,从而更进一步。具体来说,将掩码分支解耦为掩码核分支和掩码特征分支,分别负责学习卷积核和卷积特征。此外,我们提出了矩阵 NMS(非最大抑制)来显着减少由于掩码 NMS 引起的推理时间开销。我们的矩阵 NMS 一次执行具有并行矩阵运算的 NMS,并产生更好的结果。我们展示了一个简单的直接实例分割系统,在速度和准确性方面都优于一些最先进的方法。SOLOv2 的轻量级版本以 31.3 FPS 的速度执行并产生 37.1% 的 AP。此外,我们在对象检测(来自我们的掩码副产品)和全景分割方面的最先进结果表明,除了实例分割外,还可以作为许多实例级识别任务的新的强大基线。代码可在以下位置获得:我们在对象检测(来自我们的掩码副产品)和全景分割方面的最先进结果表明,除了实例分割之外,还可以作为许多实例级识别任务的新的强基线。代码可在以下位置获得:我们在对象检测(来自我们的掩码副产品)和全景分割方面的最先进结果表明,除了实例分割之外,还可以作为许多实例级识别任务的新的强基线。代码可在以下位置获得: