【ELT.ZIP】OpenHarmony啃论文俱乐部——计算机视觉数据压缩应用
- 本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。 - 成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
- 黑龙江大学大一在校生
- 山东大学大三在校生
- 华南理工大学大一在校生
- 我们是来自
7个地方的同学,我们在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究操作系统技术…
文章目录
-
-
- 【往期回顾】
- 【本期看点】
- 【技术DNA】
- 【智慧场景】
- 引言
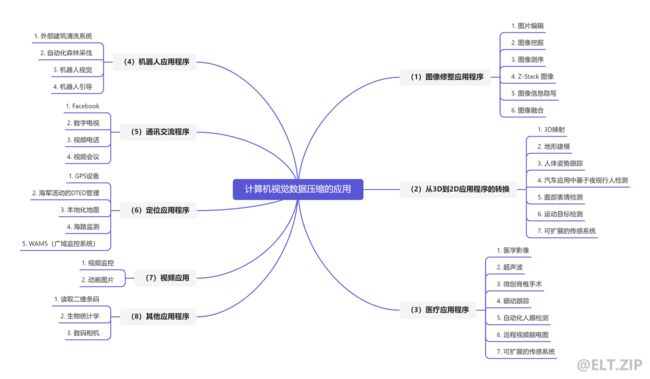
- 不同种计算机视觉应用程序与压缩算法
-
- 一、图像修整应用程序
- 二、从3D到2D转换的应用程序
- 三、医疗应用程序
- 四、机器人应用程序
- 五、基于通信的应用程序
- 六、定位应用程序
- 七、视频应用程序
- 八、其他应用程序
- Ⅰ. 轻量级时间压缩(LTC)
-
- 问题提出
- 入题
-
- 优缺点
- 场景一:TinyOS 的应用
- 场景二:可扩展传感系统
- 总结
- Ⅱ. 能够击败 MPEG-4 的图像压缩编码
-
- 背景
- 入题
- 实验
- 实验二
- HumanEva Dataset
-
- 人体姿态估计
- 介绍
- 参考文献
-
【往期回顾】
① 2月23日 《老子到此一游系列》之 老子为什么是老子 —— ++综述视角解读压缩编码++
② 3月11日 《老子到此一游系列》之 老子带你看懂这些风景 —— ++多维探秘通用无损压缩++
③ 3月25日 《老子到此一游系列》之 老子见证的沧海桑田 —— ++轻翻那些永垂不朽的诗篇++
④ 4月4日 《老子到此一游系列》之 老子游玩了一条河 —— ++细数生活中的压缩点滴++
⑤ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——一文穿透多媒体过往前沿++
⑥ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——这些小风景你不应该错过++
⑦ 4月18日 ++【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像++
【本期看点】
高速缓存与压缩算法会碰撞出什么火花呢?图像、医疗、机器人、通信都在这里了你可能少有听说的TinyOS操作系统揭秘 3D 网格压缩的三类方式殿堂级 WARP 寄存器压缩技术
【技术DNA】
【智慧场景】

引言
- 随着计算机需求的日益增长,致使计算机在各个领域都有应用,
计算机视觉就是其中之一。目前传感器的功能已经非常强大,能够通过使用各种传感器来模拟人眼,以获取周边环境的信息,比如物体的形状、大小等。这些特征能够让我们运用几何学、物理学、统计学等知识构造各种模型。 - 为了达到我们的目的,我们通常使用
相机、电缆、电脑以及各种接入设备来捕获我们需要的信息。当我们与他人分享这些信息时,我们可以考虑存储空间、速率等多种因素来确定合适的压缩算法来进行信息的传播。
不同种计算机视觉应用程序与压缩算法
一、图像修整应用程序
- 图片编辑
- 我们需要存储或传输真实的图像以及压缩后的图像来
再现真实的图像,这最终会增加带宽和存储空间。因此,我们利用 JPEG 变形算法将图像转换为压缩图像,并保护了重要的特性。
- 图像挖掘
- 图像数据挖掘是用来
挖掘大规模图像数据中隐含的知识、图像内或图像间的各种关系以及其他隐藏在图像数据中的各种模式的一种技术,应用于MRI、钻石眼、脑肿瘤分析等。一般先要进行 Run length 编码,然后是 Huffman 编码算法,以相对较低的成本存储大量的数据,并从给定的图像中提取越来越多的信息。
- 图像测序
- 随着医学图像和基因测序技术的提高,越来越多的医学图像和测序数据被检测和存储。这些海量数据的背后
隐藏了多种疾病的发病机制和有效治疗相关信息。我们需要无损压缩,因为我们不能冒序列和描述丢失的风险,因此,为了压缩这些数据,使用并行计算算法来压缩给定的数据,首先数据根据不同的模式进行分区,然后这些模式使用算术代码进行压缩。
- Z-Stack 图像
- Z-Stack其实就是在Z轴方向上连续拍很多张图,然后可以做一个叠加,拍摄的间隔距离或是切片(形象的说法)是可以自己设置的,然后拍出来的从上往下看可以想象成一个长方体,然后把这个长方体像拆开盒子一样将各个面铺开,展现出来的就是下面的图片。
- 图像信息隐写
-
隐写术是一种
将保密信息隐藏在公开信息中的技术,利用图像文件的特性,我们可以把一些想要刻意隐藏的信息或者证明身份、版权的信息隐藏在图像文件中。比如早期流行的将一些下载链接、种子文件隐藏在图片文件中进行传播,再比如某互联网公司内部论坛“月饼事件”中通过员工截图精准定位个人信息的技术,都可以归为图像隐写技术(Image Steganography)。

-
我们可以利用 GIF,因为它可以在任何硬件或软件上运行。使用 LZW- 无损技术对数据进行压缩,然后将这些数据嵌入到边缘设备中。
- 图像融合
- 图像融合是指将多源信道所采集到的关于同一目标的图像数据经过图像处理和计算机技术等,最大限度的提取各自信道中的有利信息,最后综合成高质量的图像,以
提高图像信息的利用率、改善计算机解译精度和可靠性、提升原始图像的空间分辨率和光谱分辨率,利于监测。
二、从3D到2D转换的应用程序
- 3D映射
- 它利用几何最小化之后的算术编码来压缩占用非常大的 OBJ 格式的数据,需要存储和传输。采用无损压缩的方式对其进行压缩是最合适的。
- 地形建模
- 地形建模的数据结构和结构的描述需要存储,需要使用 Shannon 算法对图进行无损压缩,描述使用 SZIP 压缩。它也有两个步骤:
-
第一步对结构进行二进制编码
-
第二步用算术编码器对第一步得到的编码进行压缩。我们不能承受信息的丢失,所以我们使用无损算法
-
人体姿势跟踪
- 由于每天创建和观看的视频数量巨大且分辨率不断提高,视频压缩仍然是一个正在进行的研究课题。最流行的视频压缩算法,如 MPEG 和 H.26x 家族,通过
计算像素块的运动来估计这些块在附近帧中的外观,文中提出了一种带有拓展剩余编码的基线视频压缩算法,该算法为 3D 姿态跟踪 + 基于 pde 的图像压缩 + 半色调的三种方法的结合,能够在背景所带来的噪声不大的情况下超过 MPEG-1与 MPEG-4,在背景噪声影响较大的情况下,优于 MPEG-1。
- 汽车应用中基于夜视行人检测
- 汽车应用中的行人检测主要使用 JPEG2000 和 H.264/AVC 进行压缩。我们需要在一个高流量通道上传输数据,一般通过使用 8位像素深度/颜色通道的编码器来进行有损压缩。
- 面部表情检测
-
“表情”是我们日常生活中提到很多的一个词语,在人际沟通中,人们通过控制自己的面部表情,可以加强沟通效果。人类的面部表情至少有21种,除了常见的高兴、吃惊、悲伤、愤怒、厌恶和恐惧6种,还有惊喜(高兴+吃惊)、悲愤(悲伤+愤怒)等15种可被区分的复合表情。
-
面部表情检测使用几何最小化和 JPEG 2000。一个面部表情中有大量的特征,所以我们需要适当的存储细节,对数据有很高的要求。
- 运动目标检测
- 运动目标检测是指
将图像序列或视频中发生空间位置变化的物体作为前景提出并标示的过程,它一直是一个十分热门的研究领域,广泛应用于智能监控、多媒体应用等领域。运动目标检测主要有以下几种方法:
- 光流法
- 帧间差分法
- 背景差分法
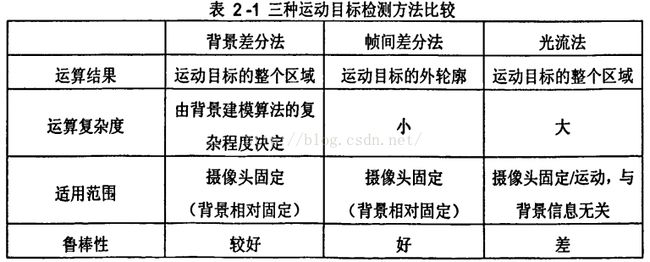
光流法计算复杂,不适用于实时监控系统;帧间差分法计算简单,但是检测结果不完整;背景差分效果较好,然而建立一个良好的背景模型需要花费很大计算量和存储量的开销。
- 可扩展传感系统
- 可扩展传感系统(ESS)是位于圣哈辛托山脉的一个正在开发中的系统。该项目主要是为科学家提供空间密集的环境、生理和生态信息,通过 LTC 压缩算法,具有了更好的性能。LTC 压缩算法的优点如下:
- 算法简单,存储空间小
- 通过使用 LTC,可以将数据压缩到 -20 到 -1。在这种压缩方案的帮助下,可以高速率进行采样。
- LTC 算法主要针对 8 位处理器的云母,没有处理浮点值的硬件。这将 LTC 的应用限制为仅压缩整数数据。像 LTC 这样的有损压缩方案通过识别和删除不必要的信息来减少比特数。在传输之前对数据进行压缩,可以显著减少资源使用,增加网络设备寿命。
三、医疗应用程序
- 医学影像
-
医学影像对疾病的识别和手术计划有非常重要的影响。然而,每个病人的成像设备仍然会产生大量的信息,通常为 1000 张或 500 MB。这些信息需要大的存储空间和经济的传输;尽管传输存储空间和通信技术有了更大的改进,医学图像压缩仍然发挥着要求很高的作用。
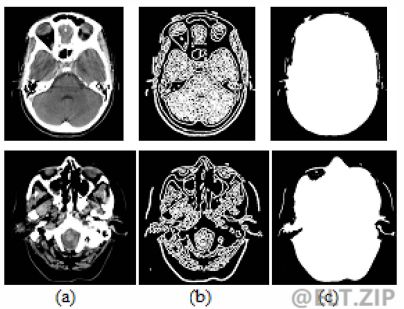
-
主成分分析(PCA)通常是一种有损压缩方案,通过将复杂的数据集转换为更小的维数来实现图像压缩。下图为 canny 边缘分割技术得到的 ROI,在非感兴趣区域要求最高的压缩,而感兴趣区域要求图像质量高。
- 超声波
-
超声波是一种波长极短的机械波,在空气中波长一般短于 2 厘米。它必须依靠介质进行传播,无法存在于真空(如太空)中。它在水中传播距离比空气中远,但因其波长短,
在空气中则极易损耗,容易散射,不如可听声和次声波传得远,不过波长短更易于获得各向异性的声能,可用于清洗、碎石、杀菌消毒等,在医学、工业上有很多的应用。
-
超声波图像存储和传输通过一个通道,需要使用 JPEG 压缩算法。将图像分割成数小块,利用 2D-DCT 变换对每个块进行编码,生成量化矩阵,然后采用熵编码进行编码,得到压缩后的图像。我们也可以使用 MPEG-1、MPEG-2 和 H.26x.
- 微创脊椎手术
-
微创脊柱外科技术意味着在一定医疗风险下避免大切口,采用微小切口或穿刺通道,运用特殊的器械和装置,在影像仪器监视下或导航技术引导下,从正常的解剖结构到达病变处,使用各种微型的手动或电动器械和器材,在可视条件下完成整个手术过程。
-
压缩时一般基于运动学和指数。数据处理采用最小二乘法,利用遗传算法选择一种生物方式来压缩数据,它不会压缩大容量的数据。
- 眼动跟踪
-
眼动追踪技术已成为
心理学、神经营销学、神经认知、用户体验、基础研究及市场研究等多个领域视觉行为和人类行为的技术手段之一。该技术还可以用于医学分析和筛查。从眼动的历史发展进程来看,早期的眼动追踪系统是侵入性的且不能移动,受限非常严重,仅在有限的实验中使用,并且在现在社会受到伦理方面的考验。随着眼动追踪系统的发展,现代的眼动追踪系统利用红外光进行捕捉眼球运动,该系统是非侵入的且更加方便易用。
-
眼动跟踪使用 JPEG 2000 进行压缩,因为它提供了眼睛运动的 2D 刻度上的各种深度信息,并存储信息,我们可以利用有损压缩的方式进行眼动跟踪。
- 自动化视觉检测
- 视觉检测就是用机器代替人眼来做测量和判断,是一般将被摄取目标转换成图像信号,传送给专用的图像处理系统,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
- 我们可以通过跟踪视频的有用部分,并根据其优先级编码,在压缩后最小化视频的大小,这是一个小的角度空间之间的 2-5° 围绕眼睛所望方向的中心,我们使用带有漏斗的 MPEG-4。
- 远程视频脑电图
- 远程视频脑电图就是远程、脑电图以及视频的结合。在脑电图设备基础上增加了视频设备(白天高清摄像头拍摄,晚间红外线照明),进而远程传输同步拍摄病人的临床表现。

它利用了波压缩。数据需要存储和传输,一般使用无损压缩技术,增加了 Cr ,可达 x50。
全国首例跨区域5G远程操控视频脑电图诊断在蚌埠成功实施
- 电有氧运动图
- 该技术所用的数据占用了大量数据存储空间,导致网络传输困难。采用离散小波变换和游程编码,通过小波变换来降低噪声,通过删除所有无用的系数来减少数据大小。
四、机器人应用程序
- 外部建筑清洗系统
- 外部建筑清洗系统通常需要小波变换和 VQ 来进行有损压缩。它使用字典和三级 DWT 对系统误差进行检测,数据空间小,需要通过信号传输清洗位置以及维护 PSNR。
- 自动化森林采伐
- 用于耕地,这里考虑浮动孔径算法,它用于发现一个通道是否需要在采样时间存储。
- 机器人视觉
-
机器人视觉,是指
不仅要把视觉信息作为输入,而且还要对这些信息进行处理,进而提取出有用的信息提供给机器人。今天的机器人已经能够完成识别人的手势和面部表情等多种功能了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SHtawWvc-1652207475923)(https://ycnx.online/wp-content/uploads/2022/04/image-1651155482415.png)] -
奇异值分解 (Singular Value Decomposition,简称SVD)是在机器学习领域广泛应用的算法。SVD算法主要用在降维算法中的
特征分解、推荐系统、自然语言处理计算机视觉等领域。它不光可以用于降维算法中的特征分解,通过 SVD,我们将图片矩阵分成正交矩阵、对角矩阵以及正交矩阵这三个矩阵的乘积。为了增加通道的使用,我们取多张图像,将重叠的图像拼接在一起,找出任何物体的运动。
- 机器人引导
-
随着工业生产中对自动化的要求越来越高,视觉技术已被广泛引入工业机器人行业,具备视觉的工业机器人能
更快、更准、更灵活地完成定位抓取、对位组装等。基于图像分析的视觉技术在机器人引导相关应用中的主要作用是精确获取对象物(待抓取物体)和目标物(待组装物体)的坐标位置和角度,并将图像坐标转换为机器人能识别的机器人坐标,指导机器人进行纠偏和组装。因此,对图片进行压缩并能使机器人精确完成相关任务是非常重要的。
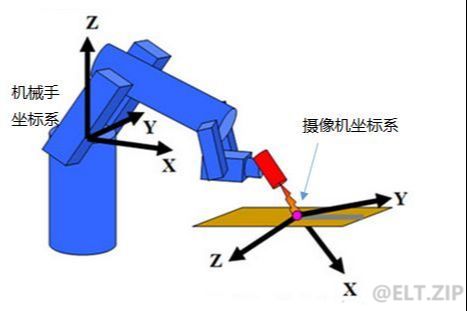
-
机器人引导压缩通常是在数据量大、传输困难的情况下进行的。一般使用小波变换和基于 VQ 的模糊 c 均值聚类。
五、基于通信的应用程序
-
Facebook 是有名的社交媒体网站,每个月的活跃用户数量超过20亿,所以有着高负荷的数据输入和输出。维护这么多的数据是一件很难的事,Facebook使用 Zstandard 压缩数据,以使信道不会受到流量堵塞。
-
Zstd 是一种快速无损压缩算法,针对 zlib 级别的实时压缩场景和更好的压缩比,它
由 Huff0 和 FSE 库提供的非常快的熵阶段提供支持。当需要时,它可以将压缩速度交换为更高的压缩比率(压缩速度与压缩比率的权衡可以通过小增量来配置),反之亦然。在运行 Ubuntu 20.04(Linux 5.11.0-41-generic)的桌面上测试和比较几种快速压缩算法,使用 lzench 在 Silesia 压缩语料库上编译,可以得到如下对比:
| 压缩方式 | 压缩比 | 压缩速度 | 解压缩速度 |
|---|---|---|---|
| zstd 1.5.1 -1 | 2.887 | 530 MB/s | 1700 MB/s |
| Zlib 1.2.11 -1 | 2.743 | 95 MB/s | 400 MB/s |
| brotli 1.0.9 -0 | 2.702 | 395 MB/s | 450 MB/s |
| zstd 1.5.1 --fast=1 | 2.437 | 600 MB/s | 2150 MB/s |
| zstd 1.5.1 --fast=3 | 2.239 | 670 MB/s | 2250 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 540 MB/s | 760 MB/s |
| zstd 1.5.1 --fast=4 | 2.148 | 710 MB/s | 2300 MB/s |
| lzo1x 2.10 -1 | 2.106 | 660 MB/s | 845 MB/s |
| lz4 1.9.3 | 2.101 | 740 MB/s | 4500 MB/s |
| lzf 3.6 -1 | 2.077 | 410 MB/s | 830 MB/s |
| snappy 1.1.9 | 2.073 | 550 MB/s | 1750 MB/s、 |
- 数字电视、视频电话
- 视频编解码技术有两套标准,国际电联(ITU-T)的标准
H.261、H.263、H.263+等;还有 ISO/IEC 的 MPEG 标准MPEG1、MPEG2、MPEG4等等。H.264/AVC 是 ISO/IEC 和 ITU-T 的团体联合开发,旨在提高压缩性能。H.264/MPEG-4 AVC(H.264)是 1995 年自 MPEG-2 视频压缩标准发布以后的最新、最有前途的视频压缩标准。通过该标准,在同等图像质量下的压缩效率比以前的标准提高了 2 倍以上。 - H.264 的编解码流程主要包括 5 个部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(Loop Filter)、熵编码(Entropy Coding),有如下优点:
- 低码率
- 高质量的图像
- 容错能力强
- 网络适应性强
- HDTV广播
- HDTV 即高清晰度电视(High Definition Television),与当前采用模拟信号传输的传统电视系统不同,HDTV 采用了数字信号传输。由于 HDTV 从电视节目的采集、制作到电视节目的传输,以及到用户终端的接收全部实现数字化,因此 HDTV 给我们带来了极高的清晰度,分辨率最高可 1920×1080,帧率高达 60fps。在 HDTV 中,我们使用 MPEG-4/AVC 也即 H.264,因为 MPEG-2 压缩算法无法为我们提供良好的比特率来制作单频道,这提供了 MPEG-2 所需压缩率的大约 50%。
- 高清视频光盘
-
因为高清视频光盘保存的信息应该使用无损压缩进行编码,所以采用内容自适应的游程编码(content-adaptive run length code)。四个具有内容自适应长度的游程压缩规则用于压缩每个位平面的二进制位流。 采用可逆无损变换作为可选编码过程,对内容进行预处理,以拟合大于 0 的内容特征。
下图表示的是一种基于子图的压缩编码的结构:
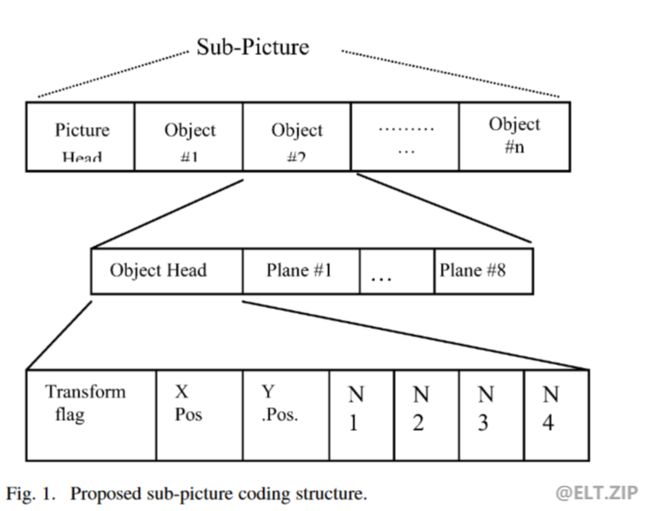
-
每个子图包括一个图头和若干子图对象。每个子图对象都有一个对象头来描述其在 x 和 y 方向的显示位置。子图对象可以包括一个或多个位平面。位平面编号、图像大小和对象大小记录在图头中。原始位平面数据包括多个二进制位 0 和 1,二进制位由四个游程编码规则压缩。
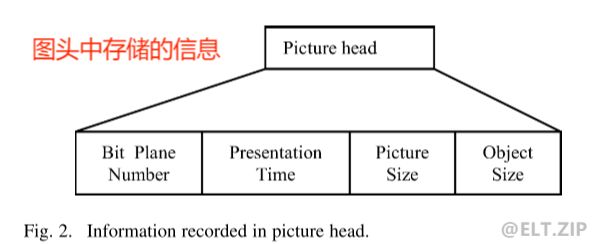
对子图中的每个位平面 N1, N2,都用下图所示的过程进行编码:

- 颜色匹配
- 颜色匹配应用使用的压缩技术是 JPEG,它维护一个字典,该字典具有与某些索引值匹配的真实颜色值,这在颜色匹配应用程序中非常有用。
六、定位应用程序
- GPS设备
-
移动对象的时空轨迹(Spatio-Temporal Trajectory)来源于对一定时间间隔的位置采用,依据采样点信息重建时空轨迹。
-
GPS传输的信息数据量大且包含特定的模式,《Data Compression System for LiDAR Based on Quad-tree Structure》中提出了一种用于压缩激光雷达数据的方法,由于 GPS 数据与激光雷达数据的相似性,所以也可用论文中提到的方式对 GPS 数据进行压缩。我们首先压缩关键数据项并制作四叉树,然后将叶子节点放入线性列表中,并获取每个节点并找到与节点边缘对应的邻居并找到高度差,如果我们获得的高度差小于预定值,则我们将位置坐标和高度值平均,最后得到一个压缩节点。
- 海军活动的DTED管理
-
DTED(Digital Terrain Elevation Data,数字地形高程数据)是数字数据集的标准,它由地形高程值矩阵(即数字高程模型)组成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-paYngMDU-1652207475927)(https://ycnx.online/wp-content/uploads/2022/04/image-1651161155127.png)] -
DTED 可以使用 ADCT 和平均残差矢量量化算法进行压缩,因为我们有灰度图像,需要对其进行压缩以获得更好的效率并降低存储和传输成本。在这种情况下,像素是通过使用经度和纬度来找到的,海拔代表像素的值。
- 本地化地图
- 要存储真实世界的地图,我们需要很大的空间。 所以我们在这种情况下使用汇总图。汇总地图仅包含主要地标,进而增强了传输。查询被分成多个片段,每个片段都描述了实际发现,然后使用基于 ILP 的压缩。
- WAMS(广域监控系统)
-
广域监控系统(Wide Area Measurement System,WAMS)是指基于同步相量技术构成的新一代电网动态监测和控制系统。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ygasVmHa-1652207475927)(https://ycnx.online/wp-content/uploads/2022/04/image-1651161475086.png)] -
WAMS数据采用 PMU(phasor measurement unit,相量测量单元) 的形式,我们需要使用无损压缩,此外还需要松弛交错。使用 PCA 查找空间重复性和 DCT 查找时间重复性并使用 LZMA 进行压缩。
七、视频应用程序
- 视频监控
- 视频监控占用大量空间存储,记录监控摄像头捕获的所有内容会消耗系统使用的存储设备。视频监控录制的视频时间长,从中提取有用的信息是一个耗时的过程,这些缺点限制了传统视频监控系统的有效性。
- 为了用更小的空间存储监控视频,有多种方法,比如消除环境冗余的仅模型编码(Exploiting global redundancy in big surveillance video data for efficient coding),基于对象的监控视频压缩技术(Object-based Surveillance Video Compression using Foreground Motion Compensation),基于事件的监控的开放框架(IBM smart surveillance system (S3): event based video surveillancesystem with an open and extensible framework)等等。利用监控视频可能持续很长时间而其监控的场景没有变化的事实,Islam Taj-Eddin 等人开发了一种基于帧之间相似性测量的有效压缩方法,可以有效减小视频大小(A New Compression Technique for Surveillance Videos: Evaluation Using New Dataset)。
- 由于监控视频通常包含大量连续帧,这些帧引用相同的场景而没有变化。所以我们可以丢弃相似的帧,只保留包含相当大变化的帧。具体的算法包含两个阶段:
- 通过删除相似的顺序帧来生成给定视频的摘要视频。
- 通过将每一帧表示为一组子帧的小窗口来对超细化视频进行编码。 对于每个子帧,重新应用相似性测量来删除每个相似的子帧。
实验结果表明:这种基于帧之间相似性测量的压缩技术在监控视频上的实现的压缩比 JPEG 有损、JPEG 无损和 MPEG-4 等其他标准压缩技术都要好。
- 动画图片
-
随着多媒体技术的进步,动态3D模型的使用逐渐增加,以在许多图形应用程序(如
视频游戏、电影、科学可视化和计算机动画)中提供逼真的视觉体验。对于图形渲染,3D 模型主要以三角形网格形式表示,该网格形式由顶点和描绘顶点之间连接的面组成。这种网格表示需要很大的存储空间来存储详细的 3D 模型,并且还需要占用很大的网络带宽来传输。因此,对 3D 模型的高效和紧凑表示的需求越来越大。使用各种类型的终端用户设备不同的异构网络上传输动画 3D 模型变得越来越重要。这带来了以适应网络传输速率和接收设备的可扩展方式压缩数据的额外要求。
-
动画几何压缩涉及压缩表示动画帧的动态三维三角形网格的几何数据。几何体压缩的可伸缩性问题解决了在单个尺度中压缩几何体,并在多个尺度中解压几何体的问题。假设一个动画有 F 帧,每一帧有 V 个顶点,每个顶点是三维空间中的一个点,所以需要存储 x, y, z 三个坐标值。因此,动画序列可以用 3V × F 的矩阵表示:
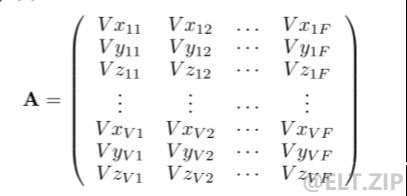
-
Sanjib Das 等人在《Temporally Scalable Compression of Animation Geometry》中提出了一个编码器和一个解码器结构,以实现时间可伸缩的实现中的一种算法的动画几何压缩。该算法使用在预测误差上遵循TWT(temporal wavelet transform,时间小波变换)的蒙皮模型进行顶点的运动预测。然后使用熵编码对顶点的仿射变换数据、每个顶点簇对应的权重和预测误差的小波系数进行量化和编码。
八、其他应用程序
- 读取二维码
-
QR 码是 Quick Response codes 的的缩写,意思是
快速响应码,最初是零售和生产中常用的标准 UPC 条形码的扩展。与一维条形码不同,QR 码是一种二维矩阵码,通过将黑白元素以矩阵形式排列在列和行中来传递信息,为给定数据生成二维条形码,从而隐藏了数据的可读性。

-
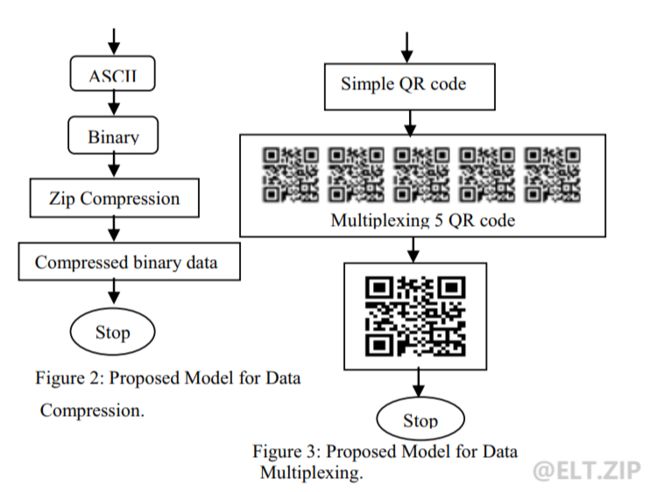
Mona M. Umaria 和 Gordhan Jethava 在《Enhancing the data storage Capacity in QR code using Compression Algorithm and achieving security and Further data storage capacity provement using Multiplexing》中提出压缩二维码表示的数据以增大二维码存储的信息,并且采用二维码复用的方式进一步提升数据存储容量。
-
先用 ASCII 将字符转换为0、1,然后用 ZIP 压缩比特数据,最后生成压缩数据对应的二维码,这样就可以使同样复杂的二维码存储更多的信息。除此之外,把 5 个二维码结合为一个二维码,在扫码的时候先将一个二维码转换为 5 个二维码,在分别读取二维码中的信息,
不仅可以存储更多的数据,而且增强了保密性:
- 生物识别
- 生物识别技术,是指用数理统计方法对生物进行分析,现在多指对生物体(一般特指人)本身的生物特征来区分生物体个体的计算机技术,包含电子护照使用的指纹和面部识别等。可以使用 JPEG 2000 和 SPIHT,其中 JPEG 2000 用于人脸识别;SPIHT 是一种基于 0-tree 的编解码器,它根据子带提取系数。
Ⅰ. 轻量级时间压缩(LTC)
问题提出
- 无线传感器网络(WSNs)对于
环境科学、水资源、生态系统、结构健康和医疗保健应用等领域的持续监测极为重要。在这种应用中,监测传感器网络中的大量观测数据需要传输到数据汇进行分析。 - 建设大规模的无线传感器网络与实用性的发展机制,使传感器设备仅仅依靠有限的能量来运行更长的时间,以便传输更多的信息。数据通信是消耗网络能量储备的主要因素,如何减少传感器节点传输的信息量是一个非常重要的问题。
入题
- 当传感器采样时,由于噪声,它会产生一系列的读数。传感器制造商指定传感器的操作范围以及精度,轻量级时间压缩(LTC)设计用于在传感器精度以余量表示且误差概率分布均匀或未知的情况下压缩数据。
- 在 LTC 中,利用时间线性用于压缩数据。下图描述了 LTC 算法,x 轴表示时间,y 轴表示值。
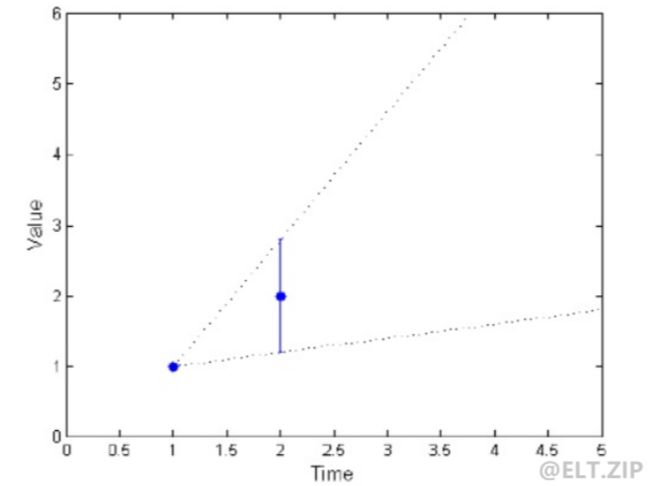
优缺点
优点:
- 可以高速率进行采样。即使我们发送少量的数据,高数据率的采样对检测任何环境变化都是有用的。
- LTC 的大部分增益发生在传感器制造商规定的工作误差范围内。对于 LTC,原始数据点与其对应的压缩后重构数据点之间的最大误差范围可以任意设置。这是一个调节旋钮,调节压缩数据大小和精度之间的权衡。
缺点:
- 当原始误差分布不均匀时,它可能会对原始误差分布进行卷积。环境数据如温度和湿度具有良好的性质,它们通常在时间维度上是连续的,在足够小的时间窗下近似线性。环境现象本身就非常复杂,很难建模。
场景一:TinyOS 的应用
- TinyOS是 UC Berkeley 开发的开放源代码操作系统,
专为嵌入式无线传感网络设计,操作系统基于构件的架构使得快速的更新成为可能,而这又减小了受传感网络存储器限制的代码长度。 - TinyOS是一个具备较高专业性,专门为低功耗无线设备设计的操作系统,主要应用于
传感器网络、普适计算、个人局域网、智能家居和智能测量等领域。
场景二:可扩展传感系统
-
可扩展传感系统(ESS)是位于圣哈辛托山脉的一个正在开发中的系统,该项目主要是为科学家提供空间密集的
环境、生理和生态信息。ESS 主要关注植物和动物栖息地的微气候等物理特征监测,包括地下根系观测和感知、根系附近土壤水分运动、地衣水化状况等,在 ESS 中,尘粒与气象感应板相连。

-
ESS体系结构由三个部分组成:
采样器、路由 网络内处理框架和查询处理器。采样器协调来自查询引擎的采样请求,并指派适当的传感器驱动程序收集数据。ESS 使用扩散公司的单相拉协议在微服务器之间进行传输,查询处理提供了大多数生态学家感兴趣的数据。目前,查询处理器支持五种查询类型。随着新的查询类型的开发,查询处理器将得到扩展以支持它们,为了增加节点的生存期,查询处理器中添加了轻量级的时间压缩。
总结
- 提出了一种可调轻量级时间压缩方案(LTC)
- 与其他压缩技术相比,该算法简单,存储空间小
- 通过使用 LTC,可以将数据压缩到 -20 到 -1,在这种压缩方案的帮助下,有可能以高速率进行采样
- LTC 算法主要针对 8 位处理器的云母,没有处理浮点值的硬件。这将 LTC 的应用限制为仅压缩整数数据。像 LTC 这样的有损压缩方案通过识别和删除不必要的信息来减少比特数。在传输之前对数据进行压缩,可以显著减少资源使用,增加网络寿命
- 长期目标是检查 LTC 的过滤能力噪音。对尘粒进行特征提取是很有用的
Ⅱ. 能够击败 MPEG-4 的图像压缩编码
背景
- 由于每天创建和观看的视频数量巨大且分辨率不断提高,视频压缩仍然是一个正在进行的研究课题。最流行的视频压缩算法,如 MPEG 和 H.26x 家族,通过
计算像素块的运动来估计这些块在附近帧中的外观。
入题
- 文中提出的基于模型的视频压缩编解码器与这些现有的方法有很大的不同,它结合了来自明显不相关领域的三种最先进的算法,即 3-D 姿态跟踪、基于 pde 的图像压缩和半色调。它们的组合使得击败 MPEG-1 甚至 MPEG-4,与许多其他基于模型的编码算法相比,该压缩方法不是专门针对人脸或其他特定对象的,因此适用于不同类型的视频。
实验
-
下图为使用MB、MPEG-1、MPEG-4 编码对 HumanEva-Ⅱ序列的压缩情况图示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1G7Jfg3H-1652207475934)(https://ycnx.online/wp-content/uploads/2022/04/image-1651194692977.png)] -
可以看到,我们的方法在物体和背景区域有明显的边界,简单的模型着色算法还远远不够完美。在算法 MB+DH 加上 400 个额外的点,试图减少这个问题,更好的结果如图所示:

-
我们可以看到 MB 编解码器创建了清晰的边界,而 MPEG-1 以及 MPEG- 4 产生了块状的结果。由于 MB 中简单的模型着色方法的性能相当差,通过附加存储信息改进了这一点,达到了更优的效果。不过,对象模型的更精确表示应该会显著提高算法的性能。
实验二
-
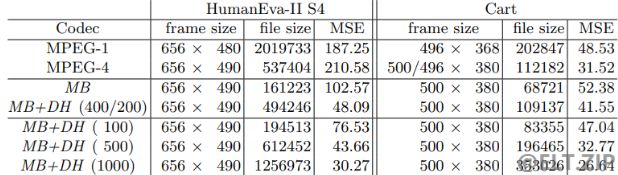
下图是使用“Cart”序列将 MB 与 MPEG-1 和 MPEG-4 进行的比较:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M5NHjVnW-1652207475935)(https://ycnx.online/wp-content/uploads/2022/04/image-1651194918887.png)] -
可以看到,该图片背景和人物模糊不清,背景所带来的噪声非常大,它恶化了基于扩散的图像压缩方法的结果。此外,对象模型往往不能代表图中人物执行的复杂运动,例如由于肌肉收缩或关节角度缺失。还有,脚的下侧在许多帧中都是可见的。由于脚不包括在物体模型中,人是部分从内部看到的,这导致了错误的颜色。最后,该序列比 HumanEva-II 序列短,导致对象模型和背景开销较大。由于这些原因,对于这个序列,MB 算法比 MPEG-4 算法差。然而,MB 算法仍然在大多数帧中击败了 MPEG-1。
HumanEva Dataset
- 官网链接:HumanEva Dataset
人体姿态估计
-
人体姿态估计(Human Pose Estimation)是计算机视觉领域中的一个重要研究方向,被广泛应用于
人体活动分析、人机交互以及视频监视等方面。人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点(如肩、肘、腕、髋膝、膝、踝等)。
-
姿态估计的作用:
- 利用人体姿态进行摔倒检测或用于增强安保和监控
- 用于健身、体育和舞蹈等教学
- 训练机器人,让机器人“学会”移动自己的关节
- 电影特效制作或交互游戏中追踪人体的运动。通过追踪人体姿态的变化,实现虚拟人物与现实人物动作的融合与同步
- 姿态估计数据集:
- 人体姿态估计数据集就是一堆用于训练人体姿态模型的数据。由于缺乏高质量的数据集,在人体姿势估计方面进展缓慢。在近几年中,一些具有挑战性的数据集已经发布,这使得研究人员进行研发工作。本文所使用的 HumanEva Dataset 就是一种
人体姿态估计数据集。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OV8bMuDa-1652207475936)(https://ycnx.online/wp-content/uploads/2022/04/2b55fe28-20f4-4f69-aa34-0a8cba7c92b5.gif)]
介绍
- HumanEva 数据集目前有 HumanEva_1 与 HumanEva_2 两个版本。
- HumanEva-I 数据集包含 7 个经过校准的视频序列(4个灰度和3个颜色),这些序列与从动作捕捉系统获得的 3D 身体姿势同步。该数据库包含4个执行6种常见动作(例如步行,慢跑,手势等)的受试者。向参与者提供用于
计算 2D 和 3D 姿势中的错误的误差指标,数据集包含训练、验证和测试(带有保留的基本实况)集。

参考文献
[1] Rana, K., & Thakur, S. (2017, May). Data compression algorithm for computer vision applications: A survey. In 2017 International Conference on Computing, Communication and Automation (ICCCA) (pp. 1214-1219). IEEE.
[2] GitHub - facebook/zstd: Zstandard - Fast real-time compression algorithm
[3] Van Der Schaar, M., & de With, P. H. N. (2000). Near-lossless complexity-scalable embedded compression algorithm for cost reduction in DTV receivers. IEEE Transactions on Consumer Electronics, 46 (4), 923-933.
[4] Khan, I. U., Ansari, M. A., Yadav, A., & Saeed, S. H. (2015, March). Performance analysis of H. 264 video decoder: Algorithm and applications. In 2015 International Conference on Energy Economics and Environment (ICEEE) (pp. 1-6). IEEE.
[5] Bodecek, K., & Novotny, V. (2007, March). From standard definition to high definition migration in current digital video broadcasting. In 2007 International Multi-Conference on Computing in the Global Information Technology (ICCGI’07) (pp. 15-15). IEEE.
[6] Dymczyk, M., Lynen, S., Bosse, M., & Siegwart, R. (2015, September). Keep it brief: Scalable creation of compressed localization maps. In 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 2536-2542). IEEE.
[7] Du, R., & Lee, H. J. (2012, December). Data compression system for LiDAR based on quad-tree structure. In 2012 7th International Conference on Computing and Convergence Technology (ICCCT) (pp. 1358-1363). IEEE.
[8] Jacobs, E. W., & Boss, R. D. (1992). Fractal Image Compression Using Iterated Transforms: Applications to DTED. NAVAL COMMAND CONTROL AND OCEAN SURVEILLANCE CENTER RDT AND E DIV SAN DIEGO CA.
[9] Gadde, P. H., Biswal, M., Brahma, S., & Cao, H. (2016). Efficient compression of PMU data in WAMS. IEEE Transactions on Smart Grid,7(5), 2406-2413.
[10] Taj-Eddin, I. A., Afifi, M., Korashy, M., Hamdy, D., Nasser, M., & Derbaz, S. (2016, July). A new compression technique for surveillance videos: evaluation using new dataset. In 2016 Sixth International Conference on Digital Information and Communication Technology and its Applications (DICTAP) (pp. 159-164). IEEE.
[11] Das, S., & Bora, P. K. (2013, December). Temporally scalable compression of animation geometry. In 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG)(pp. 1-4). IEEE.
[12] Umaria, M. M., & Jethava, G. B. (2015, December). Enhancing the data storage capacity in QR code using compression algorithm and achieving security and further data storage capacity improvement using multiplexing. In 2015 International Conference on Computational Intelligence and Communication Networks (CICN) (pp. 1094-1096). IEEE.