NLP自然语言处理工具小结
20220630
比较jieba包和companyparser包关键词提取效果
可以对公司名称,工厂名称直接提取关键字
20220331
https://zhuanlan.zhihu.com/p/79202151
BM25
https://github.com/v1shwa/document-similarity
word2vec计算文本相似度 需要的资料需要很全去训练
https://mp.weixin.qq.com/s/x6c1f_LxCOQWnvinaKk69w
使用bertopic来提取文档的主题
https://mp.weixin.qq.com/s/skRml7a5CUvm4LMB2meJ_g
NLP关键词提取必备:从TFIDF到KeyBert范式原理优缺点与开源实现
关键词抽取 目的是减少一篇文章的分词关键词数量
https://www.jianshu.com/p/4a2f7e5d45da
摘要抽取算法——最大边界相关算法MMR(Maximal Marginal Relevance) 实践
20210625
https://zhuanlan.zhihu.com/p/268625650
介绍几个专门面向中文的命名实体识别和关系抽取工具
20210617
from fastNLP import AccuracyMetric, SpanFPreRecMetric, Vocabulary
fastNLP
用途
HarvestText是一个专注无(弱)监督方法,能够整合领域知识(如类型,别名)对特定领域文本进行简单高效地处理和分析的库。适用于许多文本预处理和初步探索性分析任务,在小说分析,网络文本,专业文献等领域都有潜在应用价值。
使用案例:

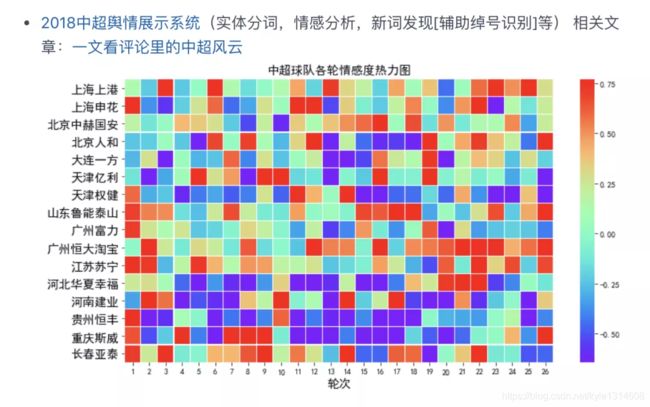
【注:本库仅完成实体分词和情感分析,可视化使用matplotlib】
近代史纲要信息抽取及问答系统(命名实体识别,依存句法分析,简易问答系统)
本README包含各个功能的典型例子,部分函数的详细用法可在文档中找到:
文档
具体功能如下:
目录:
基本处理
本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持
可以本地保存模型再读取复用,也可以消除当前模型的记录。
使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段
把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。
利用统计规律(或规则)发现语料中可能会被传统分词遗漏的特殊词汇。也便于从文本中快速筛选出关键词。
统计特定实体出现的位置,次数等。
通用停用词,通用情感词,IT、财经、饮食、法律等领域词典。可直接用于以上任务。
分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,
从大量文本中自动识别出实体及其可能别名,直接用于实体链接。例子见这里
找到一句句子中的人名,地名,机构名等命名实体。
把别名,缩写与他们的标准名联系起来。
处理URL, email, 微博等文本中的特殊符号和格式,去除所有标点等
可包含指定词和类别的分词。充分考虑省略号,双引号等特殊标点的分句。
精细分词分句
文本清洗
实体链接
命名实体识别
实体别名自动识别(更新!)
依存句法分析
内置资源
信息检索
新词发现
字符拼音纠错(调整)
自动分段
存取消除
英语支持
高层应用
从三元组中建立知识图谱并应用于问答,可以定制一些问题模板。效果有待提升,仅作为示例。
利用句法分析,提取可能表示事件的三元组。
基于Textrank, tfidf等算法,获得一段文本中的关键词
基于Textrank算法,得到一系列句子中的代表性句子。
利用共现关系,获得关键词之间的网络。或者以一个给定词语为中心,探索与其相关的词语网络。
给出少量种子词(通用的褒贬义词语),得到语料中各个词语和语段的褒贬度。
情感分析
关系网络
文本摘要
关键词抽取
事实抽取
简易问答系统
项目 获取方式
关注微信公众号 datayx 然后回复 HT 即可获取。
AI项目体验地址 https://loveai.tech
用法
首先安装, 使用pip
pip install --upgrade harvesttext
或进入setup.py所在目录,然后命令行:
python setup.py install
随后在代码中:
from harvesttext import HarvestText
ht = HarvestText()
即可调用本库的功能接口。
实体链接
给定某些实体及其可能的代称,以及实体对应类型。将其登录到词典中,在分词时优先切分出来,并且以对应类型作为词性。也可以单独获得语料中的所有实体及其位置:

采用传统的分词工具很容易把“武球王”拆分为“武 球王”
词性标注,包括指定的特殊类型。

这里把“武球王”转化为了标准指称“武磊”,可以便于标准统一的统计工作。
分句:
print(ht.cut_sentences(para))
[‘上港的武磊和恒大的郜林,谁是中国最好的前锋?’, ‘那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步’]
如果手头暂时没有可用的词典,不妨看看本库内置资源中的领域词典是否适合你的需要。
如果同一个名字有多个可能对应的实体(“打球的李娜和唱歌的李娜不是一个人”),可以设置keep_all=True来保留多个候选,后面可以再采用别的策略消歧,见el_keep_all()
如果连接到的实体过多,其中有一些明显不合理,可以采用一些策略来过滤,这里给出了一个例子filter_el_with_rule()
本库能够也用一些基本策略来处理复杂的实体消歧任务(比如一词多义【“老师"是指"A老师"还是"B老师”?】、候选词重叠【xx市长/江yy?、xx市长/江yy?】)。具体可见linking_strategy()
文本清洗
可以处理文本中的特殊字符,或者去掉文本中不希望出现的一些特殊格式。
包括:微博的@,表情符;网址;email;html代码中的 一类的特殊字符;网址内的%20一类的特殊字符;繁体字转简体字
例子如下:



情感分析
本库采用情感词典方法进行情感分析,通过提供少量标准的褒贬义词语(“种子词”),从语料中自动学习其他词语的情感倾向,形成情感词典。对句中情感词的加总平均则用于判断句子的情感倾向:

如果没想好选择哪些词语作为“种子词”,本库中也内置了一个通用情感词典内置资源,在不指定情感词时作为默认的选择,也可以根据需要从中挑选。
默认使用的SO-PMI算法对于情感值没有上下界约束,如果需要限制在[0,1]或者[-1,1]这样的区间的话,可以调整scale参数,例子如下:

信息检索
可以从文档列表中查找出包含对应实体(及其别称)的文档,以及统计包含某实体的文档数。使用倒排索引的数据结构完成快速检索。

关系网络
(使用networkx实现) 利用词共现关系,建立其实体间图结构的网络关系(返回networkx.Graph类型)。可以用来建立人物之间的社交网络等。


刘关张之情谊,刘备投奔的靠山,以及刘备讨贼之经历尽在于此。
文本摘要
(使用networkx实现) 使用Textrank算法,得到从文档集合中抽取代表句作为摘要信息,可以设置惩罚重复的句子,也可以设置字数限制(maxlen参数):

关键词抽取
目前提供包括textrank和HarvestText封装jieba并配置好参数和停用词的jieba_tfidf(默认)两种算法。
示例(完整见example):

新词发现
从比较大量的文本中利用一些统计指标发现新词。(可选)通过提供一些种子词语来确定怎样程度质量的词语可以被发现。(即至少所有的种子词会被发现,在满足一定的基础要求的前提下。)

自动分段
使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段。

与原始论文中不同,这里以分句结果作为基本单元,而使用不是固定数目的字符,语义上更加清晰,且省去了设置参数的麻烦。因此,默认设定下的算法不支持没有标点的文本。但是可以通过把seq_chars设置为一正整数,来使用原始论文的设置,为没有标点的文本来进行分段,如果也没有段落换行,请设置align_boundary=False。例见examples/basic.py中的cut_paragraph():

存取消除
可以本地保存模型再读取复用,也可以消除当前模型的记录。

简易问答系统
具体实现及例子在naiveKGQA.py中,下面给出部分示意:

阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程