【NLP基础理论】06 前馈网络(Feedforward Network)
注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
NLP中的深度学习 —— 前馈网络
目录
- NLP中的深度学习 —— 前馈网络
- 1 前馈神经网络基础
-
- 1.1 深度学习
- 1.2 前馈神经网络(Feed-forward NN)
- 1.3 神经元
- 1.4 矩阵向量表示
- 1.5 输出层
- 1.6 从数据中学习
- 1.7 规则化(Regularisattion)
- 1.8 Dropout
- 2 在NLP中的应用
-
- 2.1 主题分类
-
- 2.1.1 训练
- 2.1.2 预测
- 2.1.3 改进
- 2.2 重温语言模型
- 2.3 把语言模型作为分类器
- 2.4 前馈神经网络语言模型
- 2.5 Word Embeddings
- 2.6 神经网络语言模型架构
-
- 2.6.1 例子
- 2.6.2 优点
- 2.6.3 限制
- 3 卷积网络
-
- 3.1 卷积神经网络在NLP上的应用
- 3.2 总结
1 前馈神经网络基础
1.1 深度学习
- 机器学习的分支,对于神经网络的别称
- 之所以是深度,是因为在现代的深度网络模型中会有很多层链接在一起
- 神经网络:是被人脑处理信息的方法所启示的(组成计算的单元叫神经元 neurons)
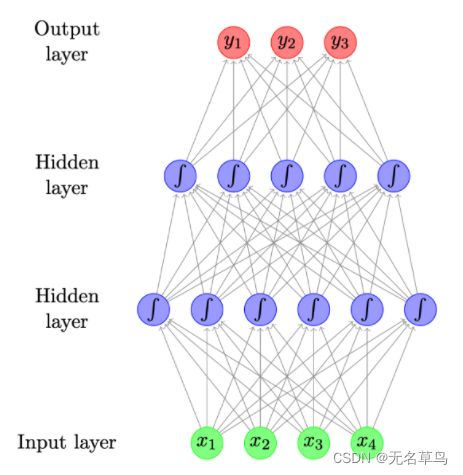
1.2 前馈神经网络(Feed-forward NN)
- 也称 多层感知器(multilayer perceptrons)
- 每一个箭头都带着权重,表示其输入变量的重要程度
- 下图是一个包含两层隐藏层的前馈神经网络,隐藏层中每个圆圈代表一个神经元,神经元对应着某个函数,通常都是一个非线性函数(sigmoid)。
- 隐藏层的结果会通过线性加权组合变成下一个层的输入
- 输出层神经的个数取决的任务的分类类别个数
- 一些层是没有线性激活函数的,比如sigmoid函数
1.3 神经元
每个神经元都是一个函数。
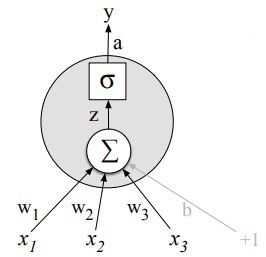
- 输入 x x x,计算实值(标量) h h h
h = t a n h ( ∑ j w j x j + b ) h = tanh(\sum_jw_jx_j+b) h=tanh(∑jwjxj+b) - 对输入进行缩放(通过权重 w w w),并加上偏移量(偏差, b b b)
- 可应用非线性函数,比如回归sigmoid,双曲sigmoid(tanh)或者整流的线性单元。
- w 和 b是模型的参数。
1.4 矩阵向量表示
- 通常会有很多个隐藏的神经元,即
h i = t a n h ( ∑ j w i j x j + b i ) h_i = tanh(\sum_jw_{ij}x_j+b_i) hi=tanh(j∑wijxj+bi) - 每一个神经元都有自己对应的权重( w i w_i wi)和偏差( b i b_i bi)。
- 上述式子可以通过举证和向量符号来表示
h ⃗ = t a n h ( W x ⃗ + b ⃗ ) \vec{h} = tanh(W\vec{x}+\vec{b}) h=tanh(Wx+b) - 其中, W W W是一个由权重向量组成的矩阵, b ⃗ \vec{b} b 是所有偏差项的向量。
- 非线性方程做的是 element-wise product,即矩阵中元素对应相乘。
1.5 输出层
- 二值分类问题
-
比如,判断一个推文的情感是正向还是负向
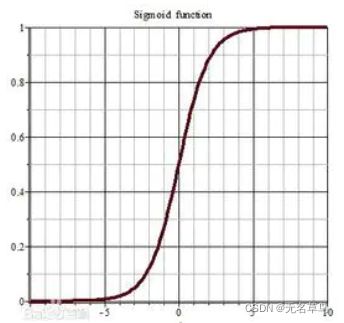
-
这里用sigmoid激活函数 σ ( z ) = 1 1 + e − z \sigma (z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1
-
-
这个函数的值在 [0, 1]之间满足概率要求,通常当输出满足某一概率条件的时候将其划分正类。
-
- 多分类问题
- 比如,原生语言辨别问题
- 通常会用 softmax 函数来保证每一分类概率大于 0 并且 和等于 1。
[ e x p ( v 1 ) ∑ i e x p ( v i ) , e x p ( v 2 ) ∑ i e x p ( v i ) , … , e x p ( v m ) ∑ i e x p ( v i ) ] [\frac{exp(v_1)}{\sum_iexp(v_i)},\frac{exp(v_2)}{\sum_iexp(v_i)},\dots,\frac{exp(v_m)}{\sum_iexp(v_i)}] [∑iexp(vi)exp(v1),∑iexp(vi)exp(v2),…,∑iexp(vi)exp(vm)]
这里用 e 为底数,原本一般用的都是 log probability
1.6 从数据中学习
- 如何从数据中学到每个参数?
- 考虑模型对训练数据的拟合程度,即它赋予正确输出的概率。
L = ∏ i = 0 m P ( y i ∣ x i ) L=\prod_{i=0}^mP(y_i|x_i) L=i=0∏mP(yi∣xi)- 想要最大化所有概率 L
- 等同于使参数的 − l o g L -log L −logL 最小化
- 通过梯度下降来训练
- 像TensorFlow,pytorch,dynet这样的工具,会用 autodiff 来自动计算梯度。
1.7 规则化(Regularisattion)
- 规则化主要是为了解决模型过拟合的情况,过拟合指的是低偏差、高方差,
- 规则化对于神经网络来说非常重要,因为一般神经网络很容易造成过拟合的情况。
- 规则化简单地说就是通过给模型参数附加一些规则,也就是约束,具体就是在原有损失函数的基础上加入规则化项实现约束。(具体的后面或会在有关统计学相关的总结文章中提及)
- L-1范数:所有参数的绝对值之和
- L-2范数:所有参数的平方之和
- Dropout:随机将某一层的某些神经元归零
1.8 Dropout
- 如果dropout 率为 0.1,那么会有百分之十的神经元会随机地变成 0
- 可以对任意层实施dropout,但实际上一般都是对隐藏层中的神经元进行隐藏。
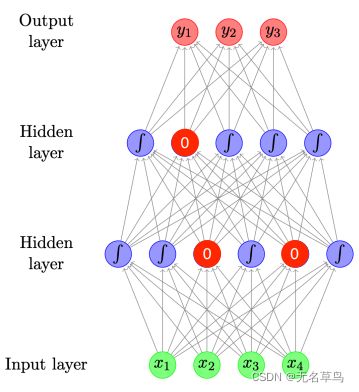
为什么dropout行得通 - 它可以防止模型过度依赖某些神经元
- 它对大的参数权重进行惩罚
- 它在网络中引入了噪声
2 在NLP中的应用
2.1 主题分类
- 给一个文档,将它归类到预先设定好的一组主题(比如,经济类、政治类、体育类)
- 输入:bag of words (统计每个doc中出现的单词的次数)
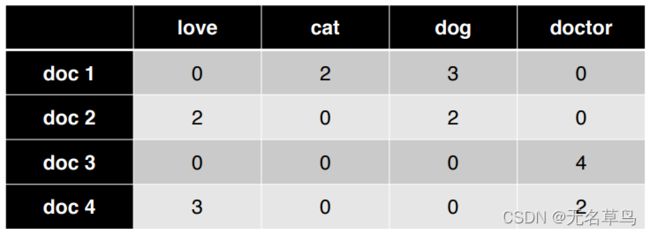
2.1.1 训练
以一下的前馈神经网络为例:
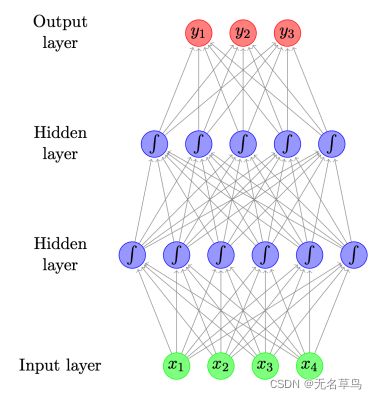
有两层隐藏层,以矩阵形式表示如下:
h 1 ⃗ = t a n h ( W 1 x ⃗ + b 1 ⃗ ) \vec{h_1} = tanh(W_1\vec{x}+\vec{b_1}) h1=tanh(W1x+b1)
h 2 ⃗ = t a n h ( W 2 h 1 ⃗ + b 2 ⃗ ) \vec{h_2} = tanh(W_2\vec{h_1}+\vec{b_2}) h2=tanh(W2h1+b2)
最后输出层就是根据第二个隐藏层输出的数据作为输入:
y ⃗ = s o f t m a x ( W 3 h 2 ⃗ ) \vec{y}=softmax(W_3\vec{h_2}) y=softmax(W3h2)
- 最开始随机初始 W W W和 b b b
- 现在输入doc1的bow进去 x ⃗ = [ 0 , 2 , 3 , 0 ] \vec{x} = [0,2,3,0] x=[0,2,3,0]
- 经过两层之后输出 y ⃗ = [ 0.1 , 0.6 , 0.3 ] \vec{y}=[0.1,0.6,0.3] y=[0.1,0.6,0.3],这也就是在分类 C 1 , C 2 , C 3 C_1, C_2, C_3 C1,C2,C3上的概率分布。
- 假设这里我们规定 C 1 C_1 C1是真标签,那么 L L L在这里就是 L = − l o g ( 0.1 ) L=-log(0.1) L=−log(0.1)
2.1.2 预测
得到了每个参数之后,用这个模型对测试数据进行预测:
x ⃗ = [ 1 , 3 , 5 , 0 ] \vec{x} = [1,3,5,0] x=[1,3,5,0](test document)
得到 y ⃗ = [ 0.2 , 0.1 , 0.7 ] \vec{y} = [0.2,0.1,0.7] y=[0.2,0.1,0.7],那预测的类别是 C 3 C_3 C3
2.1.3 改进
- 使用 bag of n-grams作为输入
- 对文本进行预处理,以便对单词进行词法处理并删除停用词
- 我们可以用TF-IDF或指标(0或1,视情况而定)来代替原始计数,给单词加权。
2.2 重温语言模型
- 为一连串的词语分配一个概率
- 框定句子上 “滑动一个窗口”。从有限的上下文中预测每个词
- 比如说 n=3,一个trigram 模型
P ( w 1 , w 2 , . . . , w m ) = ∏ i = 1 m P ( w i ∣ w i − 2 , w i − 1 ) P(w_1,w_2,...,w_m)=\prod_{i=1}^mP(w_i|w_{i-2},w_{i-1}) P(w1,w2,...,wm)=∏i=1mP(wi∣wi−2,wi−1) - 训练包括收集单词出现的频次,但这对于很少出现的事件来说会比较困难(这个时候要用smoothing)
2.3 把语言模型作为分类器
语言模型可以被当做简单的分类器,举一个trigram模型的例子:
P ( w i ∣ w i − 2 = s a l t , w i − 1 = a n d ) P(w_i|w_{i-2}=salt,w_{i-1}=and) P(wi∣wi−2=salt,wi−1=and)
根据已有的“salt”和“and”我们对于下一个可能会出现的词进行分类。
2.4 前馈神经网络语言模型
- 利用神经网络作为分类器,用trigram来搭建模型
P ( w i ∣ w i − 2 = s a l t , w i − 1 = a n d ) P(w_i|w_{i-2}=salt,w_{i-1}=and) P(wi∣wi−2=salt,wi−1=and) - 输入特征 = 前两个单词
- 输出类别 = 下一个单词
- 如何表示单词: Embeddings(简单说就是将单词变成向量,其中最有名的是Word2vec)
2.5 Word Embeddings
- 将离散的单词符号映射为相对低维空间的连续向量
- word embeddings允许该模型捕捉词之间的相似性。比如说,dog 和 cat,walking 和 running
- 一旦清楚了相似性之后,如果语料库中有“dog is walking”这句话,那么模型就会比较容易判断“cat is running”这句话的语序就是正确的。
- 回到前文讲的文本分类,最开始输入时一个稀疏的词袋(并没有做word embedding),但经过一系列计算(乘上权重并与其他处理过的词袋进行相加)得到了第一层隐藏层的结果,实现了从稀疏矩阵到稠密矩阵的变化,这是神经网络中隐藏的word embedding过程。
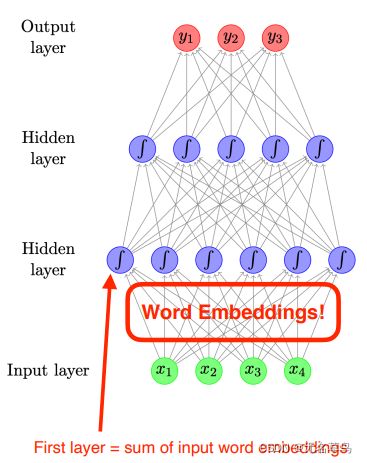
2.6 神经网络语言模型架构
怎么用前馈神经网络去构建语言模型?
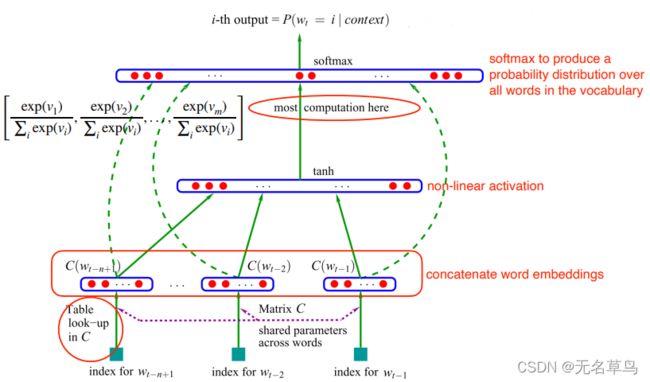
图中,我们采用 n-gram 语言模型,即判断第n个词时,我们需要判断前 n - 1 个单词:
w t − n + 1 , … , w t − 2 , w t − 1 w_{t-n+1},\dots,w_{t-2},w_{t-1} wt−n+1,…,wt−2,wt−1
然后通过矩阵 C C C 实现单词之间的参数共享(相当于输入层到隐藏层中间的 W W W 权重矩阵),从而进行word embedding得到:
C ( w t − n + 1 ) , C ( … , w t − 2 ) , C ( w t − 1 ) C(w_{t-n+1}),C(\dots,w_{t-2}),C(w_{t-1}) C(wt−n+1),C(…,wt−2),C(wt−1)
将word embedding全部合在一起,作为一个完整的数据输入一个非线性激活函数,在图中为 tanh 函数。
之后,对 word embedding进行解除或者通过线性函数转换成输出层前面的数据。
因为我们要预测的是第 n 个单词,所以最后的类别大小等于词汇表的大小(即最后输出层的单元个数等于词汇表中不重复单词个数)。因此多值分类问题我们这里需要 softmax 激活函数,得到所有单词概率的向量。然后,当我们要根据上下文预测下一个单词时,我们只需要选择概率向量中值最大的那个单词作为预测单词。
2.6.1 例子
- 假设现在我们有一句话 a cow eats,我们希望知道后面一个词是什么的概率,trigram的表现公式如下:
P ( w i = g r a s s ∣ w i − 3 = a , w i − 2 = c o w , w i − 1 = e a t s ) P(w_i=grass|w_{i-3}=a,w_{i-2}=cow,w_{i-1}=eats) P(wi=grass∣wi−3=a,wi−2=cow,wi−1=eats) - 这里我们给出几个单词的word embedding(相当于一个word embedding查找表):
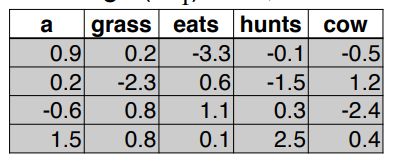
- 然后我们从上面的表中,找到 a cow eats 三个单词的word embedding,并且把他们连在一起,然后喂给网络:
x ⃗ = v a ⃗ ⨁ v c o w ⃗ ⨁ v e a t s ⃗ \vec{x} = \vec{v_a} \bigoplus \vec{v_{cow}}\bigoplus \vec{v_{eats}} x=va⨁vcow⨁veats
h ⃗ = t a n h ( W 2 x ⃗ + b 1 ⃗ ) \vec{h} = tanh(W_2\vec{x}+\vec{b_1}) h=tanh(W2x+b1)
y ⃗ = s o f t m a x ( W 3 h ⃗ ) \vec{y} = softmax(W_3\vec{h}) y=softmax(W3h) - y ⃗ \vec{y} y 给出了词汇表中所有单词的概率分布,其中 grass 的概率最大。
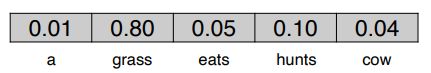
即 P ( w i = g r a s s ∣ w i − 3 = a , w i − 2 = c o w , w i − 1 = e a t s ) = 0.8 P(w_i=grass|w_{i-3}=a,w_{i-2}=cow,w_{i-1}=eats)=0.8 P(wi=grass∣wi−3=a,wi−2=cow,wi−1=eats)=0.8 - 此时 L = − l o g ( 0.8 ) L = -log(0.8) L=−log(0.8)
- 大部分参数都在 word embedding W 1 W_1 W1处(共 d 1 ∗ ∣ V ∣ d_1 * |V| d1∗∣V∣ 个, d d d是单个向量的长度),以及输出层embedding W 3 W_3 W3( d 3 ∗ ∣ V ∣ d_3 * |V| d3∗∣V∣)
2.6.2 优点
对比:
- 基于计数的 N-gram 模型
- 训练低成本(只要数数就行)
- 稀疏性问题和缩放到更大的文本
- 没法适当的提取到单词的属性(语法和语义相似度)比如说 film 和 moive
- FFNN N-gram 模型
- 自动提取单词属性,可以带来更高鲁棒性的预测。
2.6.3 限制
- 训练非常慢
- 只能提取到有限的上下文
- 仍然不能解决 没见过的词 问题
3 卷积网络
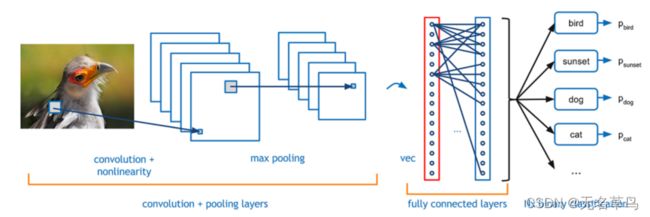
- 通常在计算机视觉中使用。
“在 CV 任务中,输入为一张图片,它由很多 像素(pixel)组成。卷积神经网络的工作机制是:每次观察图片中的一小块区域,然后用 卷积核(convolution kernel)产生一个特征方阵。对于图片中的每一个小的区域,我们都可以进行这样的操作,这样我们得到了该图片的另一种表示。如果我们采用不同的卷积核,那么将得到不同的图片表示。为什么要使用不同的卷积核呢?因为这样我们可以从不同的潜在角度(例如:颜色、边缘锐度等)来捕获图片特征。之后,我们可以进行 最大池化(max pooling)操作,同样,我们观察图片表示中的一小块区域,取其中的最大值作为该区域的表示,对其他图片表示的每个小区域都进行同样的操作,这样我们得到一些新的特征表示。最后,将得到的特征表示喂给一个全连接层,然后我们将得到分类预测的结果。” - 识别有代表性特征的局部预测器。
简单来说就是将一张图片,拆成了很多小片,然后分析得出这些小片中最明显的特征,从而通过特征再去预测别的图片。 - 将这些局部预测器进行结合,生成一个固定大小的表示。
3.1 卷积神经网络在NLP上的应用
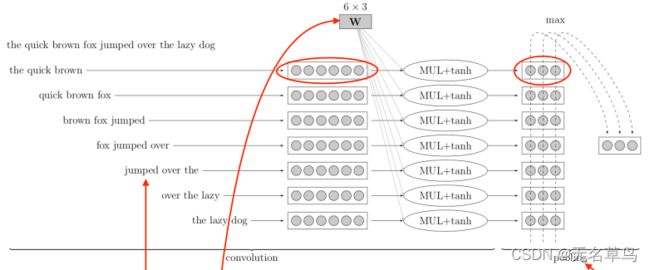
- 通过在一句话上做一个滑动窗口(比如这里是三个单词)
- W W W相当于卷积核(线性变换 + tanh函数)
- 最大池化则变成生成一个固定大小的函数(因为句子长度是有变化的,因此特征向量数量也是不一样的,因此需要通过最大池化来保证大小一样;同时最大池化会帮助我们找到句子中最具代表性的隐性特征。)
3.2 总结
- 优点
- 很好的表现效果
- 减少手工特征提取工程
- 灵活:不同任务可以自定义模型结构
- 缺点
- 比经典机器学习模型慢很多,需要gpu
- 根据词汇表大小会有很多参数
- 需要大量数据支持(data hungry),当训练数据集很小时,结果往往都不太好(所以在大型语料库中做的预训练模型很有用)