Python 中的 Dropout 神经网络
介绍

术语“丢弃”用于丢弃网络的某些节点的技术。退出可以被视为暂时停用或忽略网络的神经元。该技术应用于训练阶段以减少过拟合效应。过拟合是一种错误,当网络与有限的输入样本集过于接近时会发生这种错误。
dropout 神经网络背后的基本思想是 dropout 节点,以便网络可以专注于其他特征。像这样想。你看了很多你最喜欢的演员的电影。在某些时候你会听广播,这里有人在接受采访。你不认识你最喜欢的演员,因为你只看过电影,而且你是视觉型的。现在,想象一下你只能听电影的音轨。在这种情况下,您必须学会区分女演员和演员的声音。因此,通过删除视觉部分,您将被迫专注于声音功能!
该技术首先在 Nitish Srivastava、Geoffrey Hinton、Alex Krizhevsky、Ilya Sutskever 和 Ruslan Salakhutdinov 于 2014 年在论文“Dropout:一种防止神经网络过度拟合的简单方法”中提出
我们将在 Python 机器学习教程中实现一个能够 dropout 的 Python 类。
修改权重数组
如果我们停用一个节点,我们必须相应地修改权重数组。为了演示如何实现这一点,我们将使用具有三个输入节点、四个隐藏节点和两个输出节点的网络:

首先,我们将看看输入和隐藏层之间的权重数组。我们称这个数组为“wih”(输入层和隐藏层之间的权重)。
让我们停用(退出)节点 一世2. 我们可以在下图中看到发生了什么:

这意味着我们必须取出求和的每第二个乘积,这意味着我们必须删除矩阵的整个第二列。输入向量中的第二个元素也必须被删除。

现在我们将检查如果我们取出一个隐藏节点会发生什么。我们取出第一个隐藏节点,即H1.
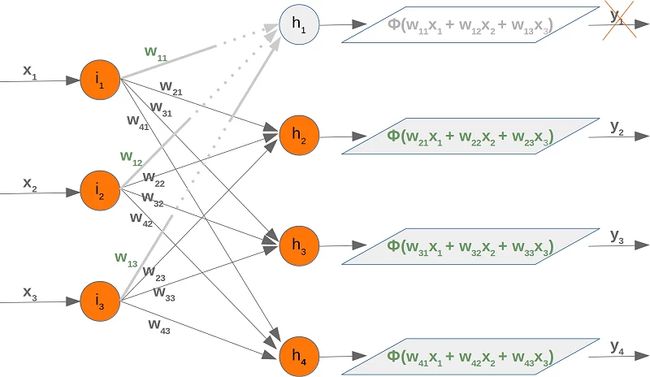
在这种情况下,我们可以删除权重矩阵的完整第一行:

取出一个隐藏节点也会影响下一个权重矩阵。让我们看看网络图中发生了什么:
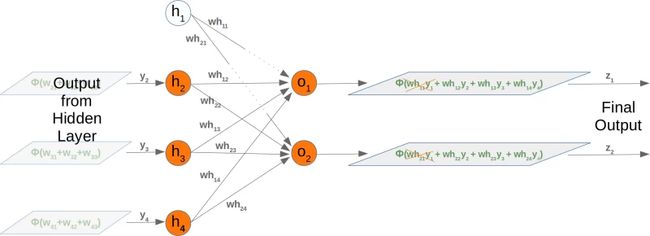
很容易看出,who 权重矩阵的第一列又要去掉了:

到目前为止,我们已经任意选择了一个节点来停用。dropout 方法意味着我们从输入层和隐藏层中随机选择一定数量的节点,这些节点保持活动状态并关闭这些层的其他节点。在此之后,我们可以用这个网络训练我们学习集的一部分。下一步包括再次激活所有节点并随机选择其他节点。也可以使用随机创建的 dropout 网络来训练整个训练集。
我们在以下三个图中展示了三种可能的随机选择的 dropout 网络:



现在是时候考虑可能的 Python 实现了。
我们将从输入层和隐藏层之间的权重矩阵开始。我们将为 10 个输入节点和 5 个隐藏节点随机创建一个权重矩阵。我们用 -10 到 10 之间的随机数填充我们的矩阵,这不是正确的权重值,但这样我们可以更好地看到发生了什么:
将 numpy 导入为 np
导入 随机
input_nodes = 10
hidden_nodes = 5
output_nodes = 7
wih = np 。随机的。randint ( - 10 , 10 , ( hidden_nodes , input_nodes ))
wih
输出:
数组([[ -6, -8, -3, -7, 2, -9, -3, -5, -6, 4],
[ 5, 3, 7, -4, 4, 8, -2, -4, 7, 7],
[ 9, -7, 4, 0, 4, 0, -3, -6, -2, 7],
[ -8, -9, -4, -5, -9, 8, -8, -8, -2, -3],
[ 3, -10, 0, -3, 4, 0, 0, 2, -7, -9]])
我们现在将为输入层选择活动节点。我们计算活动节点的随机指数:
active_input_percentage = 0.7
active_input_nodes = int ( input_nodes * active_input_percentage )
active_input_indices = sorted ( random . sample ( range ( 0 , input_nodes ),
active_input_nodes ))
active_input_indices
输出:
[0, 1, 2, 5, 7, 8, 9]
我们在上面了解到我们必须删除列 j,如果节点 一世j已移除。通过对活动节点使用切片运算符,我们可以轻松地为所有非活动节点完成此操作:
wih_old = wih 。copy ()
wih = wih [:, active_input_indices ]
wih
输出:
数组([[ -6, -8, -3, -9, -5, -6, 4],
[ 5, 3, 7, 8, -4, 7, 7],
[ 9, -7, 4, 0, -6, -2, 7],
[ -8, -9, -4, 8, -8, -2, -3],
[ 3, -10, 0, 0, 2, -7, -9]])
正如我们之前提到的,我们将不得不修改 'wih' 和 'who' 矩阵:
谁 = np 。随机的。randint ( - 10 , 10 , ( output_nodes , hidden_nodes ))
print ( who )
active_hidden_percentage = 0.7
active_hidden_nodes = int ( hidden_nodes * active_hidden_percentage )
active_hidden_indices = sorted ( random . sample ( range ( 0 , hidden_nodes ),
active_hidden_nodes ))
print ( active_hidden_indices )
who_old = 谁。copy ()
who = who [:, active_hidden_indices ]
打印( who )
输出:
[[ 3 6 -3 -9 4]
[-10 1 2 5 7]
[ -8 1 -3 6 3]
[ -3 -3 6 -5 -3]
[ -4 -9 8 -3 5]
[ 8 4 -8 2 7]
[ -2 2 3 -8 -5]]
[0, 2, 3]
[[ 3 -3 -9]
[-10 2 5]
[ -8 -3 6]
[ -3 6 -5]
[ -4 8 -3]
[ 8 -8 2]
[ -2 3 -8]]
我们必须相应地改变:
wih = wih [ active_hidden_indices ]
wih
输出:
数组([[-6, -8, -3, -9, -5, -6, 4],
[ 9, -7, 4, 0, -6, -2, 7],
[-8, -9, -4, 8, -8, -2, -3]])
以下 Python 代码总结了上面的片段:
将 numpy 导入为 np
导入 随机
input_nodes = 10
hidden_nodes = 5
output_nodes = 7
wih = np 。随机的。randint ( - 10 , 10 , ( hidden_nodes , input_nodes ))
打印( "wih: \n " , wih )
who = np 。随机的。randint ( - 10 , 10 , ( output_nodes , hidden_nodes ))
打印( "who: \n " , who )
active_input_percentage = 0.7
active_hidden_percentage = 0.7
active_input_nodes = INT (input_nodes * active_input_percentage )
active_input_indices = 排序(随机。样品(范围(0 , input_nodes ),
active_input_nodes ))
打印(“ \ n有源输入索引:” , active_input_indices )
active_hidden_nodes = INT (hidden_nodes * active_hidden_percentage )
active_hidden_indices = 排序(随机的。样本(范围(0 , hidden_nodes ),
active_hidden_nodes ))
打印(“活动隐藏索引:” , active_hidden_indices )
wih_old = wih 。copy ()
wih = wih [:, active_input_indices ]
print ( " \n停用输入节点后:\n " , wih )
wih = wih [ active_hidden_indices ]
print ( " \n停用隐藏节点后:\n " , wih )
who_old = 谁。copy ()
who = who [:, active_hidden_indices ]
print ( " \n停用隐藏节点后:\n " , who )
输出:
与:
[[ -4 9 3 5 -9 5 -3 0 9 1]
[ 4 7 -7 3 -4 7 4 -5 6 2]
[ 5 8 1 -10 -8 -6 7 -4 -6 8]
[ 6 -3 7 4 -7 -4 0 8 9 1]
[ 6 -1 4 -3 5 -5 -5 5 4 -7]]
谁:
[[ -6 2 -2 4 0]
[ -5 -3 3 -4 -10]
[ 4 6 -7 -7 -1]
[ -4 -1 -10 0 -8]
[ 8 -2 9 -8 -9]
[ -6 0 -2 1 -8]
[ 1 -4 -2 -6 -5]]
活动输入索引:[1, 3, 4, 5, 7, 8, 9]
活动隐藏索引:[0, 1, 2]
停用输入节点后:
[[ 9 5 -9 5 0 9 1]
[ 7 3 -4 7 -5 6 2]
[ 8 -10 -8 -6 -4 -6 8]
[ -3 4 -7 -4 8 9 1]
[ -1 -3 5 -5 5 4 -7]]
停用隐藏节点后:
[[ 9 5 -9 5 0 9 1]
[ 7 3 -4 7 -5 6 2]
[ 8 -10 -8 -6 -4 -6 8]]
停用隐藏节点后:
[[ -6 2 -2]
[ -5 -3 3]
[ 4 6 -7]
[ -4 -1 -10]
[ 8 -2 9]
[ -6 0 -2]
[ 1 -4 -2]]
import numpy as np
import random
from scipy.special import expit as activation_function
from scipy.stats import truncnorm
def truncated_normal ( mean = 0 , sd = 1 , low = 0 , upp = 10 ):
return truncnorm (
( low - mean ) / sd , ( upp - mean ) / sd , loc = mean , scale = sd )
类 神经网络:
def __init__ ( self ,
no_of_in_nodes ,
no_of_out_nodes ,
no_of_hidden_nodes ,
learning_rate ,
bias = None
):
自我。no_of_in_nodes = no_of_in_nodes
self 。no_of_out_nodes = no_of_out_nodes
self 。no_of_hidden_nodes = no_of_hidden_nodes
self 。learning_rate = learning_rate
self . 偏见 = 偏见
自我。create_weight_matrices ()
def create_weight_matrices ( self ):
X = truncated_normal ( mean = 2 , sd = 1 , low =- 0.5 , upp = 0.5 )
如果self ,则bias_node = 1 。偏差其他0
n = ( self . no_of_in_nodes + bias_node ) * self 。no_of_hidden_nodes
X = truncated_normal ( mean = 2 , sd = 1 , low =- 0.5 , upp = 0.5 )
self . 与 = X 。房车(n )。重塑((自我。no_of_hidden_nodes ,
自我。no_of_in_nodes + bias_node ))
n = ( self . no_of_hidden_nodes + bias_node ) * self 。no_of_out_nodes
X = truncated_normal ( mean = 2 , sd = 1 , low =- 0.5 , upp = 0.5 )
self . 谁 = X 。房车(n )。重塑((自我。no_of_out_nodes ,
(自我。no_of_hidden_nodes + bias_node )))
def dropout_weight_matrices ( self ,
active_input_percentage = 0.70 ,
active_hidden_percentage = 0.70 ):
# 恢复数组,如果它已经被用于
dropout self 。wih_orig = self 。与. 复制()
自我。no_of_in_nodes_orig = self 。no_of_in_nodes
自我。no_of_hidden_nodes_orig = self 。no_of_hidden_nodes
自我。who_orig = 自我。谁。复制()
active_input_nodes = INT (自我。no_of_in_nodes * active_input_percentage )
active_input_indices = 排序(随机。样品(范围(0 , 自我。no_of_in_nodes ),
active_input_nodes ))
active_hidden_nodes = INT (自我。no_of_hidden_nodes * active_hidden_percentage )
active_hidden_indices = 排序(随机。样品(范围( 0 , self . no_of_hidden_nodes ),
active_hidden_nodes ))
自我。与 = 自我。与[:, active_input_indices ][ active_hidden_indices ]
self 。谁 = 自我。谁[:, active_hidden_indices ]
自我。no_of_hidden_nodes = active_hidden_nodes
self 。no_of_in_nodes = active_input_nodes
返回 active_input_indices , active_hidden_indices
def weight_matrices_reset ( self ,
active_input_indices ,
active_hidden_indices ):
"""
self.wih 和 self.who 包含来自活动节点的新适应值。
我们必须通过
从活动节点
"""分配新值来重建原始权重矩阵
温度 = 自我。wh_orig 。copy ()[:, active_input_indices ]
temp [ active_hidden_indices ] = self 。与
自我。wih_orig [:, active_input_indices ] = temp
self 。与 = 自我。wh_orig 。复制()
自我。who_orig [:, active_hidden_indices ] = self 。谁
自。谁 = 自我。who_orig 。复制()
自我。no_of_in_nodes = self 。no_of_in_nodes_orig
self 。no_of_hidden_nodes = self 。no_of_hidden_nodes_orig
def train_single ( self , input_vector , target_vector ):
"""
input_vector 和 target_vector 可以是元组、列表或 ndarray
"""
如果 自. 偏置:
# 在 input_vector 的末尾添加偏置节点
input_vector = np . 串连( (input_vector , [自。偏压]) )
输入向量 = np 。数组(input_vector , ndmin = 2 )。T
target_vector = np 。阵列(target_vector , ndmin = 2 )。吨
output_vector1 = np 。点(自我。王氏, input_vector )
output_vector_hidden = activation_function (output_vector1 )
如果 自. 偏差:
output_vector_hidden = np 。串连( (output_vector_hidden , [[自我。偏压]]) )
output_vector2 = np 。点(自我。谁, 输出向量隐藏)
输出向量网络 = 激活函数(输出向量2 )
output_errors = target_vector - output_vector_network
# 更新权重:
tmp = output_errors * output_vector_network * ( 1.0 - output_vector_network )
tmp = self . 学习率 * np . 点(TMP , output_vector_hidden 。Ť )
自我。谁 += tmp
# 计算隐藏错误:
hidden_errors = np . dot ( self . who . T , output_errors )
# 更新权重:
tmp = hidden_errors * output_vector_hidden * ( 1.0 - output_vector_hidden )
if self . 偏差:
x = np 。点( tmp , input_vector . T )[: - 1 ,:]
否则:
x = np 。点(TMP , input_vector 。Ť )
自我。与 += self 。学习率 * x
DEF 列车(自, data_array中,
labels_one_hot_array ,
历元= 1 ,
active_input_percentage = 0.70 ,
active_hidden_percentage = 0.70 ,
no_of_dropout_tests = 10 ):
partition_length = int ( len ( data_array ) / no_of_dropout_tests )
对于 历元 在 范围(信号出现时间):
打印(“时代” , 历元)
为 开始 在 范围(0 , len个(data_array中), partition_length ):
active_in_indices , active_hidden_indices = \
自我。dropout_weight_matrices ( active_input_percentage ,
active_hidden_percentage )
for i in range ( start, start + partition_length ):
self 。train_single ( data_array [ i ][ active_in_indices ],
labels_one_hot_array [ i ])
自我。weight_matrices_reset ( active_in_indices , active_hidden_indices )
def 混淆_矩阵(self , data_array , labels ):
cm = {}
for i in range (len (data_array )):
res = self 。运行( data_array [ i ])
res_max = res 。argmax ()
target = labels [ i ][ 0 ]
if ( target , res_max ) in cm:
cm [( target , res_max )] += 1
else :
cm [( target , res_max )] = 1
return cm
def run ( self , input_vector ):
# input_vector 可以是元组、列表或 ndarray
如果 自. 偏置:
# 在 input_vector 的末尾添加偏置节点
input_vector = np . 串连( (input_vector , [自。偏压]) )
input_vector = NP 。数组(input_vector , ndmin = 2 )。吨
输出向量 = np 。点(自我。王氏, input_vector )
output_vector = activation_function (output_vector )
如果 自. 偏差:
output_vector = np 。串连( (output_vector , [[自我。偏压]]) )
输出向量 = np 。点(自我。谁, 输出向量)
输出向量 = 激活函数(输出向量)
返回 输出向量
DEF 评估(自, 数据, 标签):
校正, 过错 = 0 , 0
为 我 在 范围(len个(数据)):
RES = 自我。运行(数据[ i ])
res_max = res 。argmax ()
如果 res_max == 标签[ i ]:
更正 += 1
否则:
错误 += 1
返回 更正, 错误
进口 泡菜
使用 open ( "data/mnist/pickled_mnist.pkl" , "br" ) 作为 fh :
data = pickle 。负载( fh )
train_imgs = data [ 0 ]
test_imgs = data [ 1 ]
train_labels = data [ 2 ]
test_labels = data [ 3 ]
train_labels_one_hot = data [ 4 ]
test_labels_one_hot = data [ 5 ]
image_size = 28 # 宽度和长度
no_of_different_labels = 10 # 即 0, 1, 2, 3, ..., 9
image_pixels = image_size * image_size
部分 = 10
partition_length = int (len (train_imgs ) / 部分)
打印(partition_length )
start = 0
for start in range ( 0 , len ( train_imgs ), partition_length ):
print ( start , start + partition_length )
输出:
6000
0 6000
6000 12000
12000 18000
18000 24000
24000 30000
30000 36000
36000 42000
42000 48000
48000 54000
54000 60000
时代 = 3
simple_network = NeuralNetwork (no_of_in_nodes = image_pixels ,
no_of_out_nodes = 10 ,
no_of_hidden_nodes = 100 ,
learning_rate = 0.1 )
simple_network 。列车(train_imgs ,
train_labels_one_hot ,
active_input_percentage = 1 ,
active_hidden_percentage = 1 ,
no_of_dropout_tests = 100 ,
历元=历元)
输出:
时代:0
时代:1
时代:2
更正, 错误 = simple_network 。评估(train_imgs , train_labels )
打印(“准确度火车:” , 更正 / ( 更正 + 错误))
更正, 错误 = simple_network 。评估(test_imgs , test_labels )
打印(“准确度:测试” , 更正 / ( 更正 + 错误))
输出:
准确率训练:0.93178333333333333
准确度:测试 0.9296