Adaboost
AdaBoost是一种迭代算法,用于提高弱分类器的准确性。
基本原理是,通过构建一系列弱分类器,并将这些弱分类器集成在一起,形成一个强分类器。
在每次迭代中,AdaBoost会根据上一次迭代的结果,调整各个样本的权重,
使得那些被错误分类的样本在下一次迭代中得到更多的关注。
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.feature_selection import mutual_info_classif
from imblearn.over_sampling import SMOTE
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from imblearn.over_sampling import RandomOverSampler
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from my_tools import *
import warnings
warnings.filterwarnings("ignore")
读数据
jibing_res = pd.read_excel("./jibing_feature_res_final.xlsx")
jibing = pd.read_excel("./jibing_feature_final.xlsx")
归一化
jibing = guiyihua(jibing)
标准化
jibing = biaozhunhua(jibing)
划分训练集测试集
解决样本不均衡的问题
smote = SMOTE(sampling_strategy=1, random_state=42)
Xtrain,Xtest,Ytrain,Ytest = train_test_split(jibing,jibing_res,test_size=0.3,random_state=42)
Xtrain, Ytrain = smote.fit_resample(Xtrain,Ytrain)
训练
clf= AdaBoostClassifier(algorithm='SAMME',random_state=42)
clf.fit(Xtrain, Ytrain)
y_pred = clf.predict(Xtest)
指标
metrics_ = res_metrics(Ytest,y_pred,"均衡后")
#######################均衡后########################
+--------------------+--------------------+--------------------+
| precision | recall | f1 |
+--------------------+--------------------+--------------------+
| 0.8095272489391253 | 0.3620689655172414 | 0.5003510423894826 |
+--------------------+--------------------+--------------------+
调参
分类器类型
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
clf_logi = LogisticRegression(random_state=42)
clf_svm = SVC(random_state=42)
clf_tree = tree.DecisionTreeClassifier(random_state=42)
clf_forest = RandomForestClassifier(random_state=42)
clf_bys = GaussianNB()
base_clf = [clf_logi,clf_svm,clf_tree,clf_forest,clf_bys]
f1_list = []
clf_type = ["logi","svm","tree","forest","bys"]
for clf in base_clf:
clf= AdaBoostClassifier(
clf,
algorithm='SAMME',
random_state=42
)
clf.fit(Xtrain, Ytrain)
y_pred = clf.predict(Xtest)
metrics_ = res_metrics(Ytest,y_pred,"调参")
f1_list.append(metrics_["f1-score"])
set_font()
plt.bar(clf_type, f1_list)
plt.xlabel('分类器')
plt.ylabel('F1_score')
plt.title("分类器 - F1-score")
plt.show()

f1_list
[0.5460720801111363,
0.6302692597399061,
0.39105045600682375,
0.0973709449103634,
0.8421934898402698]
clf= AdaBoostClassifier(
clf_bys,
algorithm='SAMME',
random_state=42
)
clf.fit(Xtrain, Ytrain)
y_pred = clf.predict(Xtest)
metrics_ = res_metrics(Ytest,y_pred,"bys - f1")
#####################bys - f1#####################
+--------------------+--------------------+--------------------+
| precision | recall | f1 |
+--------------------+--------------------+--------------------+
| 0.8232138405100259 | 0.8620689655172413 | 0.8421934898402698 |
+--------------------+--------------------+--------------------+
高斯朴素贝叶斯作为基分类器效果最好,f1 为 0.84
继续调参
f1_list = []
best_f1 = -1.1
best_clf = "N"
best_l_r = -1
best_n_es = -1
base_clf = [clf_bys]
for clf_ in base_clf:
for l_r in np.linspace(0.1,1,20):
for n_es in np.linspace(10,200,50,dtype=int):
clf = AdaBoostClassifier(
base_estimator = clf_,
n_estimators = n_es,
learning_rate = l_r,
algorithm = 'SAMME',
random_state = 42
)
clf.fit(Xtrain, Ytrain)
y_pre = clf.predict(Xtest)
metrics_ = res_metrics(Ytest,y_pre,"调参")
if best_f1 < metrics_["f1-score"]:
best_clf = clf_
best_l_r = l_r
best_n_es = n_es
best_f1 = metrics_["f1-score"]
f1_list.append(metrics_["f1-score"])
print("{}%".format(l_r * 100))
10.0%
14.73684210526316%
19.473684210526315%
24.210526315789473%
28.947368421052634%
33.684210526315795%
38.421052631578945%
43.15789473684211%
47.89473684210527%
52.63157894736842%
57.36842105263158%
62.10526315789474%
66.84210526315789%
71.57894736842105%
76.31578947368422%
81.05263157894737%
85.78947368421052%
90.52631578947368%
95.26315789473684%
100.0%
zhexiantu(np.linspace(1,1000,1000),f1_list,"params - F1")
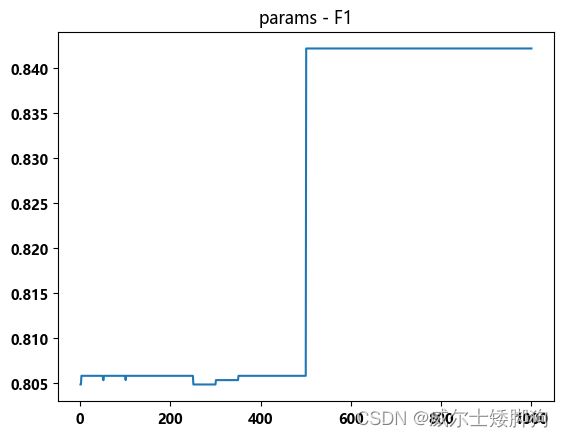
没有很明显的提升
clf= AdaBoostClassifier(
clf_bys,
algorithm='SAMME',
random_state=42
)
clf.fit(Xtrain, Ytrain)
y_pred = clf.predict(Xtest)
metrics_ = res_metrics(Ytest,y_pred,"Final - f1")
####################Final - f1####################
+--------------------+--------------------+--------------------+
| precision | recall | f1 |
+--------------------+--------------------+--------------------+
| 0.8232138405100259 | 0.8620689655172413 | 0.8421934898402698 |
+--------------------+--------------------+--------------------+