李宏毅机器学习笔记(十九)——对ML模型的攻击和防御
文章目录
- 一.背景
- 二.对图像模型进行攻击
-
- 1.基本思想
- 2.相似度限制
- 3.训练参数
- 4.攻击效果与出现的原因
- 5.更多的新型攻击方式
-
- (1).FGSM
- (2).One Pixel Attack
- 6.面向纯黑箱的攻击
- 三.对语音模型进行攻击
-
- 1.对ASR和ASV的攻击
- 2.隐藏语音攻击
-
- (1).TDI
- (2).RPG
- (3).HFA
- (4).TS
- 四.对模型进行防御
-
- 1.被动防御
- 2.主动防御
一.背景
神经网络不仅是要用在研究上,最后更多的肯定要在各种有意义的应用中。那么安全性就显得尤为重要,要去对抗恶意攻击(注意,这里不是说仅仅是对抗杂讯,而是所谓的,不暴露出弱点)。即使是垃圾邮件识别,人脸识别这种最基础广泛的领域,也存在着大量的攻击对抗。因此,对这方面的研究是十分重要的。
二.对图像模型进行攻击
1.基本思想
既然是恶意攻击,首先我们还是要保证,我们攻击所用的输入和原输入应该相对很接近,最起码人应该是不容易察觉的;其次,攻击达到的效果根据我们应用的不同也分两种:第一种就是,只要求最后的结果越不对越好,不要求结果最后错成什么样子(Non-targeted Attack);而第二种就是,在最后的结果越不对越好的基础上,还要求结果最后机器很确信的把某个我们希望的错的误认为对的(Targeted Attack)。如下图所示,第一种就是最后认为不是猫即可,而第二种就是最后认为尽量是鱼。

当然在训练攻击图片的时候,我们是不改变模型本身的参数的,我们是固定住了 θ \theta θ,而训练的是 x x x。
2.相似度限制
实际训练中我们首先要定义的就是“我们如何判断这是与原图片相似的图片”。我们设原输入是 x x x,攻击用的图像是 x ^ \hat x x^,一般我们用的是 ∣ ∣ x − x ^ ∣ ∣ ∞ ||x-\hat x||_{\infty} ∣∣x−x^∣∣∞,也就是我们看各个像素的最大差值。
使用无穷范数的原因如下图所示,对于我们人眼而言,我们一眼就能看出左面的图片和右下角图片有很大不同,而很难辨识出与右上角图片的差距;虽然其实它们做差的2-范数相同。总的来说,当图片不是这么简单的时候,其实道理也还是类似的,如果有几个像素有明显的变化,我们人眼还是能轻易捕捉到的(尤其是专门去检查的话),而整张图片每个像素都有很细微的变化,我们肉眼几乎是完全检查不出来的。

当然,这还是个见仁见智的问题,对不同的任务可能有更好的定义方式。
3.训练参数
这里我们可以用梯度下降的方法进行学习,但是会出现一个问题,那就是我们会出现到达的点在范围外的情况,因此我们需要进行额外的操作。

而这个操作,反正就是一种把所谓的外面的点拉回来的方式。相对来说最靠谱的就是,拉到距离之前的点最近的边界上。下面的图片就是针对2-范数和无穷范数的情况。

4.攻击效果与出现的原因
以下是视频中的攻击效果,可见不仅在理论上,而且在实际生活中攻击效果都可以十分的显著。


至于为什么会导致这种结果,我们其实可以这样来想:首先这是一个很复杂的神经网络,最后边界的情况是十分复杂扭曲的;而且输入的维度是十分十分大的,至少都有上千维。在一个置信度较高的点的邻域内,只要我们找到哪怕一个方向上出现了置信度变低很多的情况,那就会被这种方式攻击顺着这个方向从而找到弱点。因此可以说,相当于就类似,要想完全的防住这种攻击,那么就要求邻域内任何地点都要有足够的置信度,这要求显然太高了(越高维越困难)且本来也不一定正确。
5.更多的新型攻击方式
老师这里罗列了很多论文。然而实际上它们都是大同小异的,一般都只是因为它们的限制不相同以及优化方式不同而已。这里我们就是选几种进行介绍。

(1).FGSM
其实FGSM超级简单,就是相当于往梯度最大的下降方向走固定长的一步即可,也就是说只考虑梯度方向而不考虑梯度大小。当然,其实这样多走几步可能效果会更好,但那样就是进阶版本了,不只是FGSM了。

(2).One Pixel Attack
这种攻击思想基于,对于一张像素比较大的图片,我们把任意一个像素随意改变,其实人眼是无法辨别出来的,而对机器的判别效果可能会有比较大的影响。
如下图所示,其中0范数的意思是说非零元素的个数。当然,对于这种方式,Non-targeted Attack和Targeted Attack对效果好坏的定义其实也是都比较好办的。

但是所谓的训练过程会发现一个问题,那就是这里我们完全无法使用梯度下降的方法去找到我们想要的解。因为我们是对其中一个像素可以任意改变,在当前的位置梯度大(对结果更敏感)的像素不一定在改变很多之后效果比另外的像素改变带来的效果好。所以说,我们无法使用梯度来进行寻找。
当然,我们可以暴力枚举,但是这样相当于我们可能要实验上千万次,显然要用大量的时间,不太科学,因此我们需要一些启发式算法,这里我们采用的是差分进化算法,是遗传算法的一种改进算法,其实就是在遗传算法的基础上,从之前的随机变异变成了一种有特点的变异方式,这里笔者推荐一篇文章:https://www.cnblogs.com/tsingke/p/5809453.html
6.面向纯黑箱的攻击
之前的攻击方式中,我们都是针对于一个白箱神经网络进行攻击,也就是说我们对神经网络中的参数都已经是了如指掌了。而这里,我们主要是介绍如何去攻击一个内部结构完全未知,我们只知道用了哪些数据训练出来的一个神经网络。
我们攻击的方式其实也比较容易想到,那就是使用这些数据,自己去训练一个神经网络,然后对我们自己的神经网络进行攻击,得到攻击用的输入,然后直接把这个输入作为攻击这个黑箱神经网络的输入即可。
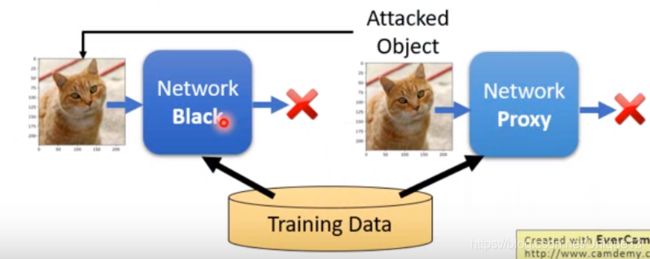
最终的效果是,这样的效果是十分不错的。至于原因,其实就是对于不同的问题,最后大致效果应该是类似的,既然效果类似,那弱点也很可能类似(当然这些还并没有太多严格的理论)。
三.对语音模型进行攻击
首先对于一个处理语音信号系统的模型如下图所示。

1.对ASR和ASV的攻击
ASR就是语音转文字,ASV就是语音识别(识别是谁说的,中心词等等)。这种攻击方式其实和对图片的攻击很像,我们就是加入人不太能听出来的一些杂讯,也就是微小的改变,然后让输出有不同的结果,总得来说是针对于最后的神经网络模型进行的攻击。
2.隐藏语音攻击
这种攻击方式与前文不相同,这里我们是希望播出一段对正常语音修改后,大家谁也听不懂的杂音,但是这段杂音对机器来说还有和之前相同的效果。当然在这里,我们不能奢求让神经网络去做这件事情,因为这完全没有普适性(这就相当于对任意的一个解,再去找一个局部最优解,这和重训练没有什么区别);因此我们主要是针对于前面的信号处理部分进行攻击。
总的来说,攻击方式如下图所示,可以同时使用这四种方式。

(1).TDI
主要利用信号处理中mFFT的漏洞:如果把一段信号完全反转,那么mFFT的结果不会有变化。那我们就分段的把一些信号段直接反转,这样这步后的结果与以前相同,但是我们人听起来结果就有了很大的变化。
(2).RPG
还是利用FFT中求振幅的漏洞:对于信号 a + b i a+bi a+bi,振幅为 a 2 + b 2 \sqrt{a^2+b^2} a2+b2,那么我们就可以在保证振幅不变的情况下修改a和b的值,从而得到不同的信号,却让他们FFT之后振幅值还和之前相同。
(3).HFA
主要针对于我们的信号预处理过程中有过滤器吸收高频信号,那我们就可以在最开始加上很多乱七八糟的高频信号,这样对机器辨识影响不大,但是我们人听起来就会十分的尖锐刺耳,极大影响辨识能力。
(4).TS
这种方法就比较显而易见了,就是将声音调快,对于机器来说,其实影响并不大,因为我们的方法中挖掘的是频域信息;而对于我们人类而言,倍速会极大影响辨识能力。
四种分别的效果如下图所示。

当然,我们可以直接把四种方法融合,这样最终得到我们想要的结果——人根本听不懂,但是不太影响机器识别。

四.对模型进行防御
总得来说,有两大种防御方式,第一种是被动防御,主要是去处理被攻击的图片使得攻击效果失效;第二种是主动防御,精华就在于要自己找到漏洞并补起来。
1.被动防御
被动防御的形式有很多,例如将输入的图片平滑化,加入一点点随机杂讯,做一点点平移旋转等等。总之宗旨是,既然攻击是只有那几个特殊方向有效,那么我就随机再换个方向,那攻击就极大可能的被抵消了。
这样做的弱点就是,一旦我们这些内部的操作被泄露,我们的这些操作就相当于是一个更大的神经网络的一部分,从而再可以重新设计更新的攻击方式。
2.主动防御
方法上其实也不难,主要就是,我们去做一个T轮的循环,每次对每个输入都找出对应的弱点,之后针对这个弱点进行修补(修改对应的标签)即可。

当然无论如何修补,总是有一个新的方向可能会出漏洞,但是这样最起码对最初的训练数据的神经网络的攻击会失效。但是问题还是,如果我们知道了用这种方式进行防御,针对这种防御机制进行攻击,攻击还是会很有效果的;另外还有一个大问题,那就是如果攻击时用的方法和自我检测时不相同的话,我们依旧是防守不住的。
因此可见,对模型的防御确实一直是一个难点。