2021李宏毅机器学习笔记--12 attack ML models
2021李宏毅机器学习笔记--12 attack ML models
- 摘要
- 一、图像模型的攻击
-
- 1.1原理
- 1.2Constraint
- 1.3参数训练
- 1.4一个例子
- 1.5攻击方法
-
- 1.5.1FGSM(Fast Gradient Sign Method)
- 1.6黑盒攻击
- 1.7拓展研究
-
- 1.7.1普遍对抗攻击(Universal Adversarial Attack)
- 1.7.2对抗性重新编程(Adversarial Reprogramming)
- 1.8真实世界的攻击
- 二、声音模型的攻击
- 三、defense
-
- 3.1被动防御
-
- 3.1.1feature Squeeze(功能挤压)
- 3.1.2Randomization at Inference Phase(推理阶段的随机化)
- 3.2主动防御
- 总结
摘要
机器学习不仅要用在研究上,更多的肯定要在各种有意义的实际应用中。因此model仅仅是对杂讯(噪声)robust和大部分时间work是不够的,还要去对抗恶意攻击(注意,这里不是说仅仅是对抗杂讯,而是所谓的,不暴露出弱点)。因为在垃圾邮件识别,人脸识别这种最基础广泛的领域,也存在着大量的攻击对抗。因此,对这方面的研究是十分重要的。
一、图像模型的攻击
1.1原理
在一个训练好的模型上,对输入的图片加上特制的噪声,这个网络模型会得到一些不同的答案。
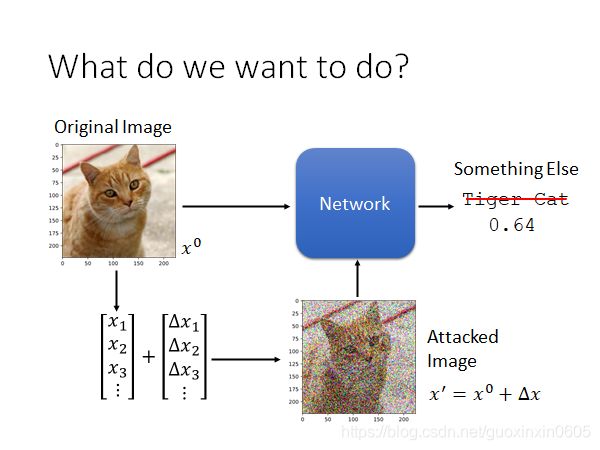 训练的时候,我们的x是不变的,从而获得我们的θ;而在训练攻击图片的时候,我们是不改变模型本身的参数的,我们是固定住了θ ,而训练的是x。
训练的时候,我们的x是不变的,从而获得我们的θ;而在训练攻击图片的时候,我们是不改变模型本身的参数的,我们是固定住了θ ,而训练的是x。
攻击达到的效果根据我们应用的不同也分两种:
1、Non-targeted Attack:只要求最后的结果越不对越好,不要求结果最后错成什么样子
2、 Targeted Attack:在最后的结果越不对越好的基础上,还要求结果最后机器很确信的把某个我们希望的错的误认为对的
如下图所示,第一种就是最后认为不是猫即可,而第二种就是最后认为尽量是鱼。
,而很难辨识出与右上角图片的差距;虽然其实它们做差的2-范数相同。总的来说,当图片不是这么简单的时候,其实道理也还是类似的,如果有几个像素有明显的变化,我们人眼还是能轻易捕捉到的(尤其是专门去检查的话),而整张图片每个像素都有很细微的变化,我们肉眼几乎是完全检查不出来的。

1.3参数训练
需要找出损失参数最小并且距离x0尽可能小的x*,可以用梯度下降的方法进行学习,但是会出现一个问题,那就是我们会出现到达的点在范围外的情况,因此我们需要进行额外的操作。
 而这个操作,反正就是一种把所谓的外面的点拉回来的方式。相对来说最靠谱的就是,拉到距离之前的点最近的边界上(连接两个点,与之交接处就是应该拉到的点)。下面的图片就是针对2-范数和无穷范数的情况。
而这个操作,反正就是一种把所谓的外面的点拉回来的方式。相对来说最靠谱的就是,拉到距离之前的点最近的边界上(连接两个点,与之交接处就是应该拉到的点)。下面的图片就是针对2-范数和无穷范数的情况。

1.4一个例子
输入一张猫的图片,让他认为是海星。
 但是肉眼观察不出任何差别,所以做一个减法,可能差别非常小,所以乘以50,因为这个网络是50层的。可见这两张图片确实有微小的差异,这个微小的差异足以骗过网络,让他认为右边的图片是海星。
但是肉眼观察不出任何差别,所以做一个减法,可能差别非常小,所以乘以50,因为这个网络是50层的。可见这两张图片确实有微小的差异,这个微小的差异足以骗过网络,让他认为右边的图片是海星。
 如果说猫和海星有一些相似之处,都是生物。那么也可以让猫变成键盘。
如果说猫和海星有一些相似之处,都是生物。那么也可以让猫变成键盘。
 如果不加入特制的杂讯,而是随机加入一些,网络可能不会被骗。
如果不加入特制的杂讯,而是随机加入一些,网络可能不会被骗。
 那么到底为什么出现这种结果呢?
那么到底为什么出现这种结果呢?
x0随机移动,多数时候,在该点附近,网络判断为tiger cat的confidence很高
首先这是一个很复杂的神经网络,最后边界的情况是十分复杂扭曲的;而且输入的维度是十分十分大的,至少都有上千维。有某些神奇的方向会出现这种现象:只要稍微推一点,预测为某个不相干的东西的confidence就会很高。在一个置信度较高的点的邻域内,只要我们找到哪怕一个方向上出现了置信度变低很多的情况,那就会被这种方式攻击顺着这个方向从而找到弱点。
因此可以说,相当于就类似,要想完全的防住这种攻击,那么就要求邻域内任何地点都要有足够的置信度,这要求显然太高了(越高维越困难)且本来也不一定正确。

1.5攻击方法
有多种的攻击方法,它们的区别只是在于限制不相同以及优化方式。

1.5.1FGSM(Fast Gradient Sign Method)
就是相当于往梯度最大的下降方向走固定长的一步即可,也就是说只考虑梯度方向而不考虑梯度大小,并且给一个非常大的learning rate,一次update就会跑出范围,然后把它拉回对应的角。

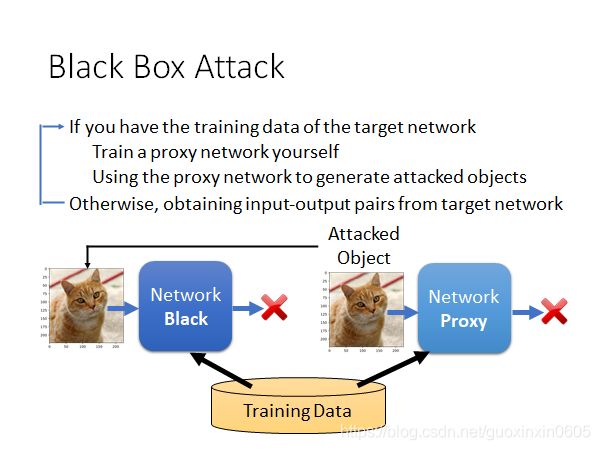
1.6黑盒攻击
黑盒和白盒的区别在于,白盒是指我们对神经网络中的参数都已经是了如指掌,那么黑盒就是一个内部结构完全未知的网络,我们仅仅知道用了哪些数据训练。
 我们攻击的方式其实也比较容易想到,那就是使用这些数据,自己去训练一个神经网络,然后对我们自己的神经网络进行攻击,得到攻击用的输入,然后直接把这个输入作为攻击这个黑箱神经网络的输入即可。黑箱攻击也有可能会成功。
我们攻击的方式其实也比较容易想到,那就是使用这些数据,自己去训练一个神经网络,然后对我们自己的神经网络进行攻击,得到攻击用的输入,然后直接把这个输入作为攻击这个黑箱神经网络的输入即可。黑箱攻击也有可能会成功。
1.7拓展研究
1.7.1普遍对抗攻击(Universal Adversarial Attack)
之前提到的攻击,对于每个图片x,会有不同的噪声x’进行攻击,有人提出了通用的噪声,可以让所有图片的辨识结果都出错。这个也可以做黑箱

1.7.2对抗性重新编程(Adversarial Reprogramming)
有一个辨识鱼的网络,可以将它改造成数方块的网络,根据方块的不同进行输出。
加一噪声,就能变成别的网络.

1.8真实世界的攻击
有人做实验,把攻击的图像打印出来,然后用图片放在摄像头上进行攻击。证明这种攻击时可以在现实生活中做到的。
可以对人脸识别上进行攻击,把噪声变成眼镜,带着眼镜就可以实现攻击。
 在现实生活中需要做的以下几点
在现实生活中需要做的以下几点
1、要保证多角度都是成功的
2、 噪声不要有非常大的变化(比如只有1像素与其他不同),要以色块方式呈现,这样方便摄像头能看清
3、不要用打印机打不出来的颜色
4、不要在交通符号上加噪声。
二、声音模型的攻击
对模型的攻击不仅仅限制于图片模型,还可以对声音模型进行攻击,或者对文本进行攻击。

三、defense
总得来说,有两大种防御方式,第一种是被动防御,主要是去处理被攻击的图片使得攻击效果失效;第二种是主动防御,精华就在于要自己找到漏洞并补起来。
3.1被动防御
被动防御的形式有很多,例如将输入的图片平滑化,使用一个filter,加入一点点随机杂讯,做一点点平移旋转等等。总之宗旨是,既然攻击是只有那几个特殊方向有效,那么我就随机再换个方向,那攻击就极大可能的被抵消了。(以毒攻毒)
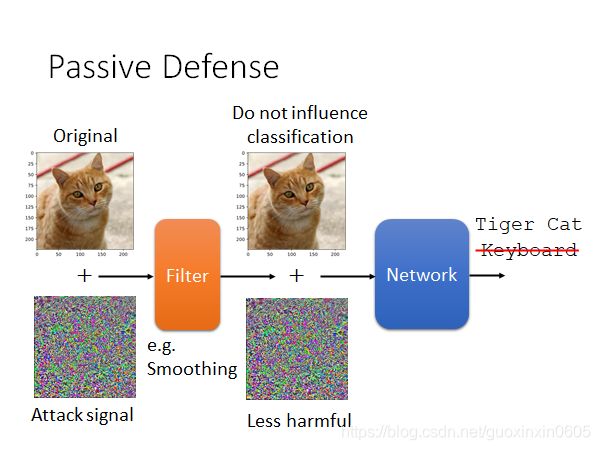
这样做的弱点就是,一旦我们这些内部的操作被泄露,我们的这些操作就相当于是一个更大的神经网络的一部分,从而再可以重新设计更新的攻击方式。
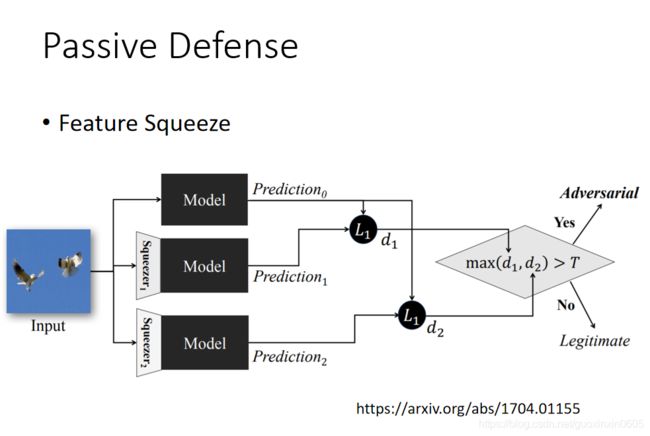
3.1.1feature Squeeze(功能挤压)
squeezer(挤压器)指的是不同的filter,比较这些输出,如果区别很大就有问题。
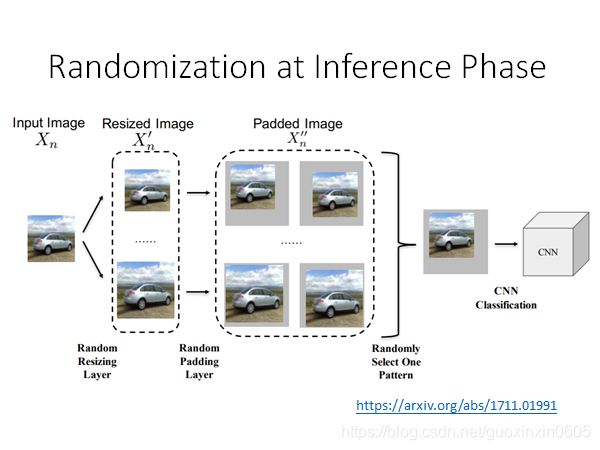
3.1.2Randomization at Inference Phase(推理阶段的随机化)
稍微做些改变,看输出是否会有变化
3.2主动防御
方法上其实也不难,主要就是,我们去做一个T轮的循环,每次对每个输入都找出对应的弱点,之后针对这个弱点进行修补(修改对应的标签)即可。
 当然无论如何修补,总是有一个新的方向可能会出漏洞,但是这样最起码对最初的训练数据的神经网络的攻击会失效。但是问题还是,如果我们知道了用这种方式进行防御,针对这种防御机制进行攻击,攻击还是会很有效果的;另外还有一个大问题,那就是如果攻击时用的方法和自我检测时不相同的话,我们依旧是防守不住的。
当然无论如何修补,总是有一个新的方向可能会出漏洞,但是这样最起码对最初的训练数据的神经网络的攻击会失效。但是问题还是,如果我们知道了用这种方式进行防御,针对这种防御机制进行攻击,攻击还是会很有效果的;另外还有一个大问题,那就是如果攻击时用的方法和自我检测时不相同的话,我们依旧是防守不住的。
总结
神经网络不仅仅用在实验上,更要用在各种实际应用中,因此模型要有对抗恶意攻击的能力,但是目前大多数的操作是对模型进行攻击,反而模型的防御一直是一个难点,对这方面的研究是十分重要。