恒源云(GpuShare)_PRGC:基于潜在关系和全局对应的联合关系三元组抽取
文章来源 | 恒源云社区
原文地址 | PRGC:基于潜在关系和全局对应的联合关系三元组抽取
原文作者 | Mathor
Abstract
本文讲关系抽取任务分解为关系判断、实体提取和subject-object对齐三个子任务,提出了一种基于潜在关系和全局对应的联合关系三元组抽取框架(PRGC)。具体而言,首先设计一个预测潜在关系的组件,将后续实体提取限制在预测的关系子集上,而不是所有的关系;然后用特定于关系的序列标记组件处理subject-object之间的重叠问题;最后设计一个全局对应组件来以较低的复杂度将主客体对齐成三元组。在两个公共数据集上达到了新的SOTA。
1 Introduction
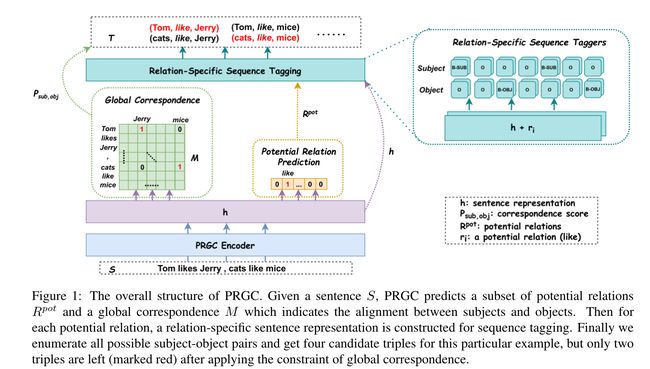
关系抽取是从非结构化文本中识别(subject,relation,object)三元组。本文将其分解为三个子任务:1.关系判断:识别句子中的关系;2.实体提取:识别句子中的subject和object;3.subject-object对齐:将subject-object对齐成一个三元组
对于关系判断:本文通过 P o t e n t i a l R e l a t i o n P r e d i c t i o n Potential\ Relation\ Prediction Potential Relation Prediction组件来预测潜在关系,而不是保留所有的冗余关系,这降低了计算复杂度,取得了更好的性能,特别是在实体提取方面。在实体提取方面:本文使用了一个更健壮的 R e l a t i o n S p e c i f i c S e q u e n c e T a g Relation\ Specific\ Sequence\ Tag Relation Specific Sequence Tag组件(简称Rel-Spec Sequence Tag)来分别提取subject和object,以自然地处理subject和object之间的重叠。对于subject-object对齐:本文设计了与一个关系无关的全局对应矩阵来判断特定的subject-object对在三元组中是否有效。
在给定句子的情况下,PRGC首先预测潜在关系的子集和包含所有subject-object之间对应分数的全局矩阵;然后进行序列标注,并行地提取每个潜在关系的主客体;最后枚举所有预测的实体对,然后通过全局对应矩阵进行剪枝。
2 Method
2.1 PROBLEM DEFINITION
输入是具有n个token的句子 S = x 1 , x 2 , … , x n S={x_1,x_2,…,x_n} S=x1,x2,…,xn,期望的输出是关系三元组 T ( S ) = ( s , r , o ) ∣ s , o ∈ E , r ∈ R T(S)={(s,r,o)|s,o \in E, r\in R} T(S)=(s,r,o)∣s,o∈E,r∈R,其中 E E E、 R R R分别表示实体集和关系集。
2.1.1 Relation Judgement
对于给定句子 S S S,该子任务是预测它句子 S S S包含的潜在关系,输出为: Y r ( s ) = r 1 , r 2 , … , r m ∣ r i ∈ R Y_r(s)={r_1,r_2,…,r_m|r_i\in R} Yr(s)=r1,r2,…,rm∣ri∈R,其中m为潜在关系子集的大小。
2.1.2 Entity Extraction
对于给定句子 S S S和预测的潜在关系 r i r_i ri,该子任务是使用BIO标记方案识别每个token的tag,其中 t j t_j tj表示tag。输出为: Y e ( S , r i ∣ r i ∈ R ) = t 1 , t 2 , … , t n Y_e(S,r_i|r_i\in R)={t_1,t_2,…,t_n} Ye(S,ri∣ri∈R)=t1,t2,…,tn。
2.1.3 Subject-object Alignment
对于给定句子 S S S,该子任务预测主语和宾语的起始tokens之间的对应分数。即真正的三元组中的subject-object对的得分较高。输出为: Y s ( S ) = M ∈ R n × n Y_s(S)=M \in R^{n\times n} Ys(S)=M∈Rn×n,其中 M M M表示全局对应矩阵。
2.2 PRGC ENCODER
通过BERT对句子S进行编码。encoder的输出: Y e n c ( S ) = h 1 , h 2 , … , h n Y_{enc}(S)={h_1,h_2,…,h_n} Yenc(S)=h1,h2,…,hn,其中n表示tokens数。
2.3 PRGC DECODER
2.3.1 Potential Relation Prediction
图中 R p o t R^{pot} Rpot表示潜在关系
给定句子 S S S,首先预测句子中可能存在的潜在关系的子集,然后只需要提取用到这些潜在关系的实体。给定n个tokens的句子嵌入 h ∈ R n × d h\in \mathbb{R}^{n\times d} h∈Rn×d,该潜在关系预测的每个元素为:
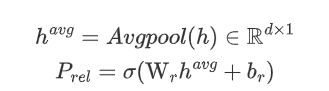
其中 A v g p o l l Avgpoll Avgpoll是平均池化操作, W r ∈ R d × 1 \mathrm{W}_r\in \mathbb{R}^{d\times 1} Wr∈Rd×1是可训练权重, σ \sigma σ是sigmod函数。
本文将其潜在关系预测建模为一个多标签二进制分类任务,如果概率超过某个阈值 λ 1 \lambda _1 λ1,则为对应关系分配标签1,否则将对应的关系标签置为0;接下来只需要将特定于关系的序列标签应用于预测关系,而不要预测全部关系。
2.3.2 Relation-Specific Sequence Tagging
如图1所示,通过2.3.1节中的组件获得了描述的潜在关系的几个特定于关系的句子表示。然后,模型执行两个序列标注操作来分别提取主体和客体。
作者之所以将主语和宾语分开提取,是为了处理一种特殊的重叠模式,即主语宾语重叠(SOO)。作者放弃了传统的LSTM-CRF网络,而采用了简单的全连接神经网络进行实体关系识别。该组件对每个token的具体操作如下:

其中 u j ∈ R d × 1 u_j\in \mathbb{R}^{d\times 1} uj∈Rd×1是训练嵌入矩阵 U ∈ R d × n r U\in \mathbb{R}^{d\times n_r} U∈Rd×nr中第j个关系表示, n r n_r nr是全部关系集合的大小, h i ∈ R d × 1 h_i\in \mathbb{R}^{d\times 1} hi∈Rd×1是第i个token的编码表示, W s u b , W o b j ∈ R d × 3 W_{sub},W_{obj}\in \mathbb{R}^{d\times 3} Wsub,Wobj∈Rd×3是训练权重
2.3.3 Global Correspondence
在序列标注之后,分别获得关于句子关系的所有可能的主语和宾语,然后使用全局对应矩阵来确定正确的主语和宾语对。应该注意的是,全局对应矩阵可以与潜在关系预测同时学习,因为它独立于关系。
具体过程如下:首先枚举所有可能的subject-object对;然后在全局矩阵中检查每对subject-object对的对应分数,如果该值超过某个阈值 λ 2 \lambda _2 λ2,则保留该分数,否则将其过滤掉。图1中的绿色矩阵 M ∈ R n × n M\in \mathbb{R}^{n\times n} M∈Rn×n即是全局对应矩阵,由n个token组成的句子。矩阵中的每个元素都与subject-object对的起始位置有1关,位置代表主客体对的置信度,值越高属于三元组的置信度就越高,矩阵中每个元素的值如下所示:
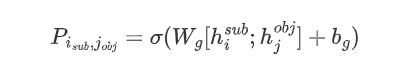
其中 h i s u b , h j o b j ∈ R d × 1 h_i^{sub},h_j^{obj}\in \mathbb{R}^{d\times 1} hisub,hjobj∈Rd×1是形成潜在subject-object对的输入语句中的第i个token和第j个token的编码表示, W g ∈ R 2 d × 1 W_g\in \mathbb{R}^{2d\times 1} Wg∈R2d×1是可训练权重, σ \sigma σ是sigmod函数。
2.4 TRAINING STRATEGY

其中 n r n_r nr表示关系集的大小, n r p o t n_r^{pot} nrpot表示潜在关系子集的大小,总的损失是:
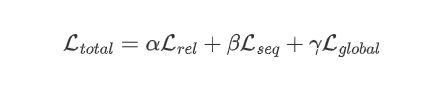
3 Experiments

本文通过了 P R G C R a n d o m PRGC_{Random} PRGCRandom来验证的PRGC解码器的有效性,其中编码器BERT的所有参数都是随机初始化的。 P R G C R a n d o m PRGC_{Random} PRGCRandom的性能表明,即使不利用预先训练的BERT语言模型,本文的解码器框架仍然比其他解码器框架更具竞争力和健壮性。
模型的具体参数:使用BERT-base作为编码器、句子长度设为100,V100GPU,100个epochs
4 启示
- 先抽取潜在关系再抽取与潜在关系有关的实体最后进行subject-object的对齐会提高模型的解码速度和算力资源。
- 潜在关系预测阈值 λ 1 \lambda _1 λ1越高,模型的性能越好
- 三个损失函数的调参是一个工作量问题。
- 如果句子长度太长最后subject-object的对齐工作消耗的空间资源会很大。