FYD-Focus Your Distribution-关注你的分布:异常检测和定位的从粗到细的非对比性学习-FYD
论文翻译:
Focus Y our Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization
关注你的分布:异常检测和定位的从粗到细的非对比性学习
Abstract
无监督异常检测的本质是学习正态样本的紧凑分布,并在测试中检测异常值。同时,现实世界中的异常现象在高分辨率的图像中通常是细微的,特别是在工业应用中。为此,我们提出了一个新的无监督的异常检测和定位框架。我们的方法旨在通过一个从粗到细的排列过程从正常图像中学习密集和紧凑的分布。
粗配准阶段在图像和特征层面上对物体的像素位置进行标准化。然后,精细对齐阶段密集地使图像中所有相应位置的特征的相似性最大化。为了促进只用正常图像的学习,我们为精细对齐阶段提出了一个新的借口任务,即非对比性学习。
非对比性学习在不对异常样本进行假设的情况下,提取出稳健的、有鉴别力的正常图像表征,从而使我们的模型能够泛化到各种异常场景中。在MVTec AD和BenTech AD这两个典型的工业数据集上进行的广泛实验表明,我们的框架在检测各种真实世界的缺陷方面是有效的,在工业无监督异常检测方面达到了新的水平。
图像异常检测是对数据集中意外或异常图像模式的识别,在发现生产线缺陷、分析医学图像、监控视频流。不同于经典的监督学习任务假设在类之间均匀分布,异常在现实世界中很少发生,并且通常难以收集和标记。
此外,缺乏关于异常模式的先验知识给设计全面的异常检测算法带来了巨大的挑战。
由于异常图像的稀缺性和不确定性,现有的异常检测方法通常遵循无监督或单类分类设置。也就是说,模型在训练中只提供正常数据。在推断过程中,通过测试数据和学习到的正常特征之间的差异来发现异常。现有论文被证明在提取用于隔离缺陷图像的语义丰富的表示方面是成功的;尽管如此,他们缺乏探索异常的细粒度结构的能力。比如之前作品中常见的一个设定将CIFAR-10数据集中的一个类别设置为正常类别,其余类别设置为异常。然而,在实际的制造或医疗行业中,正常图像和异常之间的差异比这些对象类差异更细粒度和微妙。
因此,我们设计了一个新的框架,目标是实际工业环境中的细粒度异常模式,其中图像通常在干净的背景下拍摄,共享位置和缺陷通常很微妙。我们方法的直觉受到人类推理过程的启发。
当被要求玩现场差异游戏时,人类通常会首先粗略地对齐,或者找到两幅图像的全球背景之间的对应关系。然后,他们仔细检查了两种模式下的详细的局部差异。受此启发,我们设计了一个由粗到精的两阶段框架来学习正常图像的鲁棒特征分布。
Introduction
图像异常检测是对数据集中意外或异常图像模式的识别,例如生产线缺陷、分析医学图像、监控视频流。不同于经典的监督学习任务假设在类之间均匀分布,异常在现实世界中很少发生,并且通常难以收集和标记。此外,缺乏关于异常模式的先验知识给设计全面的异常检测算法带来了巨大的挑战。
由于异常图像的稀缺性和不确定性,现有的异常检测方法通常遵循无监督或单类分类设置。也就是说,模型在训练中只提供正常数据。在推断过程中,通过测试数据和学习到的正常特征之间的差异来发现异常。现有作品被证明在提取用于隔离缺陷图像的语义丰富的表示方面是成功的;尽管如此,他们缺乏探索异常的细粒度结构的能力。比如之前作品中常见的一个设定将CIFAR-10数据集中的一个类别设置为正常类别,其余类别设置为异常。然而,在实际的制造或医疗行业中,正常图像和异常之间的差异比这些对象类差异更细粒度和微妙。
因此,我们设计了一个新的框架,目标是实际工业环境中的细粒度异常模式,其中图像通常在干净的背景下拍摄,共享位置和缺陷通常很微妙。我们方法的直觉受到人类推理过程的启发。
当被要求玩现场差异游戏时,人类通常会首先粗略地对齐,或者在两幅图像的整体背景之间找对应关系。然后,他们仔细检查两图像的局部差异。受此启发,我们设计了一个由粗到精的两阶段框架来学习正常图像的鲁棒特征分布。
我们首先应用粗对齐模块来粗略地提取和对齐全局特征嵌入。该模块对输入图像的像素级和每个金字塔特征图的特征级进行操作。在精对准阶段,我们应用自监督学习,并提出一个新的借口任务学习正常的代表性。目前最先进的(CutPaste:
Self-Supervised Learning for Anomaly Detection and Localization.arXiv:2104.04015)自我监督异常检测设计的增强,通过混合正常图像补丁产生异常样本。然而,我们缺乏关于真实世界异常分布的足够先验知识,因此创建的缺陷不能模拟异常的众多真实可能性。因此,我们为自我监督学习定义了一个新的任务,称为非对比学习-不使用异常样本,只使用正常图像来训练一个鲁棒的特征编码器。通过加强来自小批的每个位置的特征之间的相似性,我们在图像的每个对齐位置捕获局部细粒度的对应。因此,正常图像的分布变得更紧凑,语义上更有意义,使得异常异常值更突出,更容易检测。
综上所述,本文的主要贡献在于:
- 提出了一种由粗到细的异常检测范式,用于检测和定位真实工业数据集中的细粒度缺陷;
- 我们提出了一种新的方法,称为密集非对比学习,用于在没有任何异常样本假设的情况下进行密集正常特征的自监督学习;
- 我们提供了大量的实验结果和消融研究,以突出我们方法的优势,在MvTec异常检测数据集中的结果表明,我们的方法优于以前最先进的异常检测方法。
Related Work
主流的无监督异常检测和定位方法或者是基于重构的或者是基于表示的。
基于重建的方法应用自动编码器或生成对抗网络对正常数据进行编码和重建。在推理过程中,当重建图像偏离原始图像时,就会发现异常。逐像素重建误差可用于定位异常,因此,图像水平异常分数通过聚合逐像素误差来确定。尽管重建和比较的可解释性很高,但像素差异未能编码图像的全局语义。此外,自动编码器有时也会为异常图像生成可比较的重建结果。
另一方面,基于表示的方法从正常图像中提取区别性特征向量或正常图像补片,并为异常检测产生更有希望的结果。通过测试图像的嵌入和正常图像表示的分布之间的距离来计算异常分数。正常图像分布通常由正常图像的非球面中心表征,正常图像的高斯分布,或用于整个正常图像嵌入的kNN。最近的一项工作是PaDiM从不同的CNN层学习多元高斯分布的参数。作为我们的并行工作,还使用非对比学习来实现特征适应,以进一步细化预训练的CNN主干。
我们的方法和PANDA的主要区别在于如何解决模型崩溃的问题。在PANDA中,它提出了三种选择:简单的早期停止、基于样本的早期停止和持续学习以避免模型崩溃。在我们的方法中,我们使用停止梯度策略来缓解这个问题,并且我们以密集像素方式调整该特征。
为了辅助图像的语义向量的学习,许多工作采用自我监督学习区分正常数据和异常值。一些方法是预测图像的旋转和使用常用图像增强策略的对比学习。虽然这些方法很好地捕捉了图像中的语义对象信息,但它们未能编码异常中的细粒度局部不规则性。于是,有学者就创建了一组新的数据扩充,复制异常中的局部缺陷。Cutout 方法从图像中随机移除一个小矩形区域,而CutPaste进一步修改了算法,从一幅图像中剪切一个补丁并将其粘贴到另一幅图像上。然而,创建的负不规则性的表示通常不与真实世界的异常重叠,这限制了这些方法在推理过程中的推广潜力。
在本文中,我们遵循异常检测中的自我监督方法,提出了一种新的由粗到精的任务。早期的自我监督方法通常采用负样本来学习不同类别的多样化表示。受最近创新的自监督方法SimSiam的启发,我们以密集的像素级自监督方式用我们的非对比学习替换产生的与现实不一致的异常样本。通过丢弃负样本的停止梯度运算,我们消除了关于训练中异常数据的任何先验假设,因此我们的模型可以推广到现实世界中的各种异常。此外,通过我们提出的图像粗对齐和逐像素特征学习的密集监督,我们减少了正常数据表示中的方差,使学习到的紧凑分布能够预测离群值的稳健距离估计。
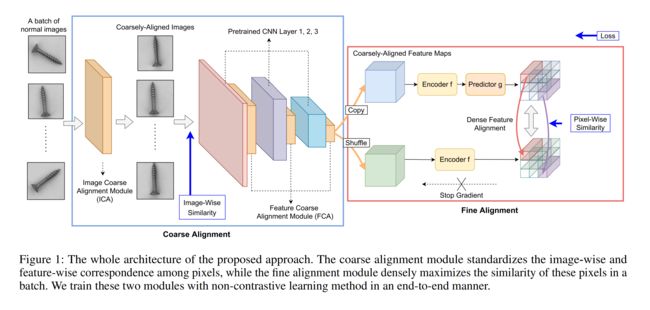
Coarse-to-Fine Non-Contrastive Learning
在这一节中,我们将展示我们检测和定位细粒度异常的新框架。如图1所示,我们的方法包括粗对准阶段和精对准阶段。粗略对准模块首先捕获并对准图像的全局上下文。然后,标准化的图像特征被传递到中的密集表示编码器,用于细粒度的自我监督学习。我们从密集的正态特征和作为异常的斑点分布异常值中构建紧凑的高斯分布。
Coarse Alignment Stage
Image-Level Coarse Alignment (ICA)
图像级粗对齐(ICA)旨在正则化正常图像的像素分布:它将一批中的所有图像定向到相似的方向和位置,以便进行密集比较。具体地,我们对输入图像 D i D_i Di使用 T θ ( D i ) \mathcal{T}_{\theta}\left(\mathcal{D}_{i}\right) Tθ(Di)进行仿射变换
[ x i t y i t ] = T θ ( D i ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] [ x i s y i s 1 ] (1) \left[\begin{array}{l} x_{i}^{t} \\ y_{i}^{t} \end{array}\right]=\mathcal{T}_{\theta}\left(\mathcal{D}_{i}\right)=\left[\begin{array}{lll} \theta_{11} & \theta_{12} & \theta_{13} \\ \theta_{21} & \theta_{22} & \theta_{23} \end{array}\right]\left[\begin{array}{c} x_{i}^{s} \\ y_{i}^{s} \\ 1 \end{array}\right] \tag{1} [xityit]=Tθ(Di)=[θ11θ21θ12θ22θ13θ23] xisyis1 (1)
受空间变形网络的启发我们采用了与ICA模块相似的架构,它使用了一个微型网络 h T θ h_{\mathcal{T}_{\theta}} hTθ去学习上面的仿射变换-由原图像 { ( x i s , y i s ) } \left\{\left(x_{i}^{s}, y_{i}^{s}\right)\right\} {(xis,yis)} 转换为全局对齐的表示形式 { ( x i t , y i t ) } \left\{\left(x_{i}^{t}, y_{i}^{t}\right)\right\} {(xit,yit)}。为了训练ICA模块,我们在一批中随机配对图像,然后最小化它们之间的距离:
L I C A ( D ; θ h , T θ ) = ∑ A , B ∈ D ∑ i = 0 H − 1 ∑ j = 0 W − 1 ∥ h T θ ( A i , j ) − h T θ ( B i , j ) ∥ 2 (2) \mathcal{L}_{I C A}\left(\mathcal{D} ; \theta_{h}, \mathcal{T}_{\theta}\right)=\sum_{A, B \in \mathcal{D}} \sum_{i=0}^{H-1} \sum_{j=0}^{W-1}\left\|h_{\mathcal{T}_{\theta}}\left(A_{i, j}\right)-h_{\mathcal{T}_{\theta}}\left(B_{i, j}\right)\right\|_{2} \tag{2} LICA(D;θh,Tθ)=A,B∈D∑i=0∑H−1j=0∑W−1∥hTθ(Ai,j)−hTθ(Bi,j)∥2(2)
请注意,我们没有为要回归的模块分配任何标准方向或对齐,因此它以自我监督的方式学习统一的位置。
每次我们随机选择两个图像 A , B ∈ D A,B \in D A,B∈D,等式2中的 L 2 \mathcal{L}_2 L2损失监督A和B朝向该系统中熵的减少的对准。因此,给定足够的迭代,系统在排列上达成共识,并且熵因此减小到局部最小值。图2展示了粗略统一位置的结果.
Feature-Level Coarse Alignment (FCA)
特征级粗对准(FCA)对于图2中的变换图像,它们的位置没有严格对准到统一的表示。因此,我们引入了特征级粗对准(FCA)模块来进一步调整高级图像表示。我们使用预训练的ResNet-18作为特征提取器。如图1所示,我们在连续的层之间插入FCA将嵌入分布与特征级仿射变换对齐。FCA的实现与ICA类似;尽管如此,该模块强制主干提取可概括的特征,以在全局高级嵌入中对齐位置。FCA模块仅由精细对准阶段的自监督损耗控制。图像级和特征级对准的实现细节在附录中。
Fine Alignment Stage: Pixel-wise Non-contrastive
非对比学习是对语义上有意义的正常图像表示的训练,而不利用其与异常的距离来检测细微的异常。我们提出了逐像素对齐模块,该模块最大化了所有正常图像的每个嵌入位置的特征相似度。

如算法1所示,我们首先随机打乱小批量并采样两个特征图。设 W , V ∈ R H ′ × W ′ × C ′ W,V\in R^{H'×W'×C'} W,V∈RH′×W′×C′ 表示属于来自最后一个FCA的两个不同图像的两个编码图像特征图。然后,对于这两个特征中的每个位置 0 ≤ i < H ′ , 0 ≤ j < W ′ 0≤i
L i j ( m i j , n i j ; θ g , θ f ) = − ⟨ g ( m i j ) , n i j ⟩ ∥ m i j ∥ 2 ⋅ ∥ n i j ∥ 2 (3) \begin{array}{c} \mathcal{L}_{i j}\left(m_{i j}, n_{i j} ; \theta_{g}, \theta_{f}\right)=-\frac{\left\langle g\left(m_{i j}\right), n_{i j}\right\rangle}{\left\|m_{i j}\right\|_{2} \cdot\left\|n_{i j}\right\|_{2}} \\ \end{array} \tag{3} Lij(mij,nij;θg,θf)=−∥mij∥2⋅∥nij∥2⟨g(mij),nij⟩(3)
其中 θ g θ_g θg和 θ f θ_f θf分别是编码器和预测器的参数。我们分别在所有位置 i 、 j i、j i、j处对w和v进行上述最小化,以密集地监督位置对齐的特征分布。
为了避免在仅使用正常数据进行训练时模型崩溃,我们引入了的停止梯度操作。也就是说, ▽ L i j \bigtriangledown \mathcal{L}_{i j} ▽Lij 只允许通过网络 w . r . t . m i j w.r.t.m_{ij} w.r.t.mij的上分支向后下降,并且它不向编码器f更新 n i j n_{ij} nij的信息。应用对称操作来进一步监督鲁棒和可推广特征的学习。
因此,每个位置的合计损失为:
L F A S ( m , n ; θ g , θ f ) = ∑ D ∑ i , j 1 2 L i j ( m i j , stop − grad ( n i j ) ) + 1 2 L i j ( n i j , stop − grad ( m i j ) ) . \mathcal{L}_{F A S}\left(m, n ; \theta_{g}, \theta_{f}\right)=\sum_{\mathcal{D}} \sum_{i, j} \frac{1}{2} \mathcal{L}_{i j}\left(m_{i j}, \operatorname{stop}_{-} \operatorname{grad}\left(n_{i j}\right)\right)+ \\ \frac{1}{2} \mathcal{L}_{i j}\left(n_{i j}, \operatorname{stop}_{-} \operatorname{grad}\left(m_{i j}\right)\right) . LFAS(m,n;θg,θf)=D∑i,j∑21Lij(mij,stop−grad(nij))+21Lij(nij,stop−grad(mij)).
它的实现详见算法1。我们以端到端的方式训练上述阶段,并通过 λ 1 λ1 λ1和 λ 2 λ2 λ2调整粗调和细调之间的权重。因此,我们框架中的最终损失是
L total ( ⋅ ; θ h , f , g , T θ ) = λ 1 ⋅ L I C A + λ 2 ⋅ L F A S . (5) \mathcal{L}_{\text {total }}\left(\cdot ; \theta_{h, f, g}, \mathcal{T}_{\theta}\right)=\lambda_{1} \cdot \mathcal{L}_{I C A}+\lambda_{2} \cdot \mathcal{L}_{F A S} . \tag{5} Ltotal (⋅;θh,f,g,Tθ)=λ1⋅LICA+λ2⋅LFAS.(5)
L F A S \mathcal{L}_{FAS} LFAS是监督所有参数的主导损失函数, I C A \mathcal{I C A} ICA是用于保证ICA收敛的辅助损失函数。通过集体优化粗调和细调模块,我们允许网络自我调整并学习正常图像嵌入的有意义的相关关系。
Anomaly Score Computation in Inference
有了密集提取的特征,我们按照(PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization. arXiv:2011.08785.)对特征图上的每个像素用高斯分布来模拟正常图像的表示。
我们通过串联CNN在 ( i , j ) (i,j) (i,j)处的三个金字塔层的特征来提取位置 ( i , j ) (i,j) (i,j)的正常图像表示。让 X i j ∈ R ( C 1 + C 2 + C 3 ) × N X_{i j} \in \mathbb{R}^{\left(C_{1}+C_{2}+C_{3}\right) \times N} Xij∈R(C1+C2+C3)×N表示来自CNN的训练集所有图像的聚合特征。我们为特征图上的每个像素 ( i , j ) (i,j) (i,j)建立一个独特的高斯分布 N ( μ i j , Σ i j ) \mathcal{N}\left(\mu_{i j}, \Sigma_{i j}\right) N(μij,Σij)的模型,即:
μ i j = 1 N ∑ k N x i j k ; Σ i j = 1 N − 1 ∑ k N ( x i j k − μ i j ) ( x i j k − μ i j ) T (6) \mu_{i j}=\frac{1}{N} \sum_{k}^{N} x_{i j}^{k} ; \Sigma_{i j}=\frac{1}{N-1} \sum_{k}^{N}\left(x_{i j}^{k}-\mu_{i j}\right)\left(x_{i j}^{k}-\mu_{i j}\right)^{T} \tag{6} μij=N1k∑Nxijk;Σij=N−11k∑N(xijk−μij)(xijk−μij)T(6)
在推理过程中,我们通过获取测试图像和正常分布之间每个像素的马哈拉诺比斯距离来计算异常得分。
D ( x i j ) = ( x i j − μ i j ) T Σ i j − 1 ( x i j − μ i j ) (7) \mathcal{D}\left(x_{i j}\right)=\sqrt{\left(x_{i j}-\mu_{i j}\right)^{T} \Sigma_{i j}^{-1}\left(x_{i j}-\mu_{i j}\right)} \\ \tag{7} D(xij)=(xij−μij)TΣij−1(xij−μij)(7)
距离矩阵D是一个具有密集的像素级异常得分的异常图。分数越大,表明异常信号越严重。因此,我们用最大的异常得分图来表示整个图像的异常得分。
Experiments
Datasets and Metrics
我们在两个工业异常检测数据集MVTec AD数据集和BeanTech AD数据集上进行了实验。MVTec AD数据集包括5354张真实世界的图像,有15个类别,其中10个是物体,其余5个是纹理类。BeanTech AD数据集有3个类别的2540张图像。在这两个数据集中,训练集只由正常图像组成,而测试集则由正常和异常图像混合组成。这些数据集同时提供了反常的类型和异常掩码作为测试图像标签进行评估。
如前所述,这些数据集的异常情况比学术数据集设置的异常情况更加细化,例如CIFAR-10数据集的异常情况被定义为不同的物体类别。在单类分类协议下,我们用每个类别的正常图像为其训练一个模型。
实施细节列在附录中。在推理过程中,我们用图像级AUC和像素级AUC来评估我们的方法。
Anomaly Detection and Localization for MVTec
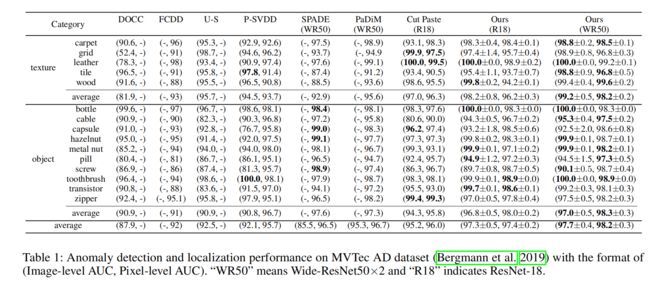
在表1中,我们比较我们的方法与先进的一类异常检测方法,包括deep one-class classifier(DOCC),FCDD,patch SVDD,SPADE,PaDiM, Cut Paste在图像级AUC和像素级AUC的指标下,我们给出了5个重复实验的平均值和标准差的结果。利用我们提出的从粗到细的非对比学习方法,我们在现有的所有作品中取得了最好的结果,并在纹理和对象缺陷方面都取得了显著的改进。我们的方法以2.1的优势超过了目前的先进技术,即97.7图像级AUC和98.2像素级AUC。在图3中可视化了该方法的异常定位的一些结果,并在附录中提供了更全面的缺陷定位结果。我们可以观察到,异常热图不仅突出了有缺陷的物体,而且对小的异常区域也表现出强烈而细粒度的关注。这证明了我们的框架是如何精确地定位这些异常现象的。
Anomaly Detection and Localization for BeanTech
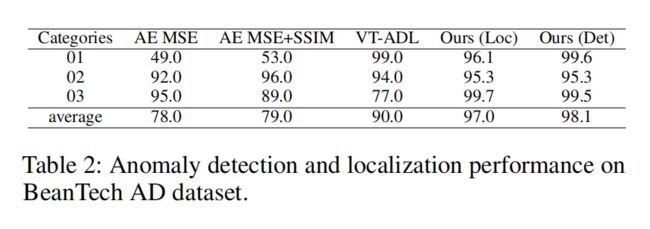
在表2中,我们在BeanTech AD数据集上将我们的方法与中报告的异常检测方法进行了比较。他们在异常定位中应用了具有MSE损失的自动编码器、具有MSE和SSIM损失的自动编码器以及VT-ADL。我们给出了ResNet-18的结果,并另外报告了图像级的结果。我们的方法在所有现有方法中取得了最好的结果,并超过当前最先进的方法7.0倍,产生98.1图像级AUC和97.0像素级AUC。这个结果显示了我们的方法推广到新的异常检测场景的潜力,其中异常数据具有变化的分布,并且需要仔细检查细节。
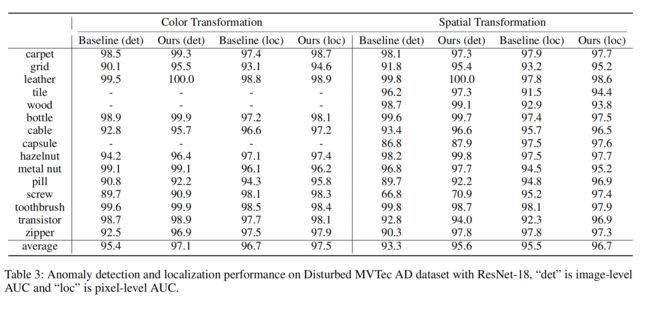
Performance for Disturbed MVTec
考虑到当前的MVTec AD数据集不包含具有多种外观的产品,而仅具有空间对齐的产品,我们通过各种扩充建立了一个称为扰动MVTec的新数据集。我们旨在模拟更具挑战性的真实生活检测情况,并验证我们的框架的鲁棒性和有效性。具体来说,我们建立了两个受干扰的场景,分别用颜色和空间变换。对于颜色转换,我们在MVTec的训练和测试图像中应用随机亮度对比度增强和有限自适应直方图均衡化。对于空间变换,我们在MVTec中的训练和测试图像中应用随机放大、缩小、旋转和翻转。这两个扰动数据集和增强细节的例子记录在我们的附录中。ResNet-18的相应实验结果见表3。应当注意,一些类别是合适的用于增色,尤其是纹理类。例如,不同颜色的区域将被视为瓷砖、木材和胶囊上的异常,因此我们没有对它们执行颜色增强。此外,某些类别可能不适合做某些特殊类型的空间增强。例如,我们不能在晶体管中应用垂直翻转或旋转。我们可以观察到,在这些颜色和空间变换下,我们的方法通常比基线执行得更好,这表明我们的框架对模拟工业图像中真实世界干扰的复杂设置的适应性。
Quantitative Analysis on Distribution
为了量化我们工作中分布紧凑性的改善,我们将我们方法的距离方差得分与基线(ImageNet预训练模型)进行比较。
给定一类总共N个法线图像表示 X ∈ R N × H × W × C X ∈ R^{N×H×W ×C} X∈RN×H×W×C,通过首先计算每个像素到其对准中心的距离来计算距离方差得分:
μ i j = ∑ n N x n i j N , ∀ 0 ≤ i < H , 0 ≤ j < W (8) \mu_{i j}=\frac{\sum_{n}^{N} x_{n i j}}{N}, \forall 0 \leq i
D n i j = ( x n i j − μ i j ) T Σ i j − 1 ( x n i j − μ i j ) (9) D_{n i j}=\sqrt{\left(x_{n i j}-\mu_{i j}\right)^{T} \Sigma_{i j}^{-1}\left(x_{n i j}-\mu_{i j}\right)} \\ \tag{9} Dnij=(xnij−μij)TΣij−1(xnij−μij)(9)
然后,我们得到所有正常图像在每个位置的距离图 D ∈ R N × H × W × C D \in R^{N×H×W ×C} D∈RN×H×W×C。我们将距离方差得分计算为所有距离嵌入的总方差:
S c l s = 1 H × W ∑ i , j ∑ n N ( D n i j − D ˉ i j ) 2 N (10) \mathcal{S}_{c l s}=\frac{1}{H \times W} \sum_{i, j} \sum_{n}^{N} \frac{\left(D_{n i j}-\bar{D}_{i j}\right)^{2}}{N} \\ \tag{10} Scls=H×W1i,j∑n∑NN(Dnij−Dˉij)2(10)
其中 D ˉ i j \bar{D}_{i j} Dˉij是位置 ( i , j ) (i,j) (i,j)处所有图像的平均距离。如果图像表示的分布变得更紧凑,那么Sclass将会减小,因为特征向量到它们中心的距离的变化应该更小。我们最终汇总了数据集中所有15个类别的距离得分:
S t o t a l = 1 N c l s ∑ c l s S c l s \mathcal{S}_{t o t a l}=\frac{1}{N_{c l s}} \sum_{c l s} \mathcal{S}_{c l s} Stotal=Ncls1cls∑Scls
S t o t a l \mathcal{S}_{t o t a l} Stotal的总得分为0.95,我们的方法得分为0.84,方差得分降低了11.6%。因此,它证明了我们的方法有效地缩小了特征分布,同时还保持了编码中有意义和有区别的变化。
Ablation Study
Component-wise Analysis
我们在表4中研究了主要组件对我们的方法的贡献。“Baseline”仅使用ImageNet预训练的ResNet-18在推理中对等式6中的高斯分布进行建模。“非对比学习”是用停止梯度操作密集地最大化一批中所有图像的相似性的精细对准阶段。“粗对准”是用于分布正则化的初始图像级和特征级对准模块。与U-S和PaDiM等其他方法相比,基线给出的AUC和PRO结果较少。

添加单个非对比学习块将图像级AUC提高到95.7,像素级AUC提高到96.8,超过了之前所有的作品。这证明了我们设计的非对比学习模块的有效性,因为它消除了训练中的异常样本,缩小了正常样本的分布。然后,添加粗略对准模块进一步增强了我们相对于当前技术水平的优势。这是非常直观的,因为没有首先对准图像的粗略位置,像素之间的密集最小化距离可能不会正确关联。因此,消融研究显示了每个模块的附加效应和我们框架的全面性。
Effects of Coarse Alignment Stage
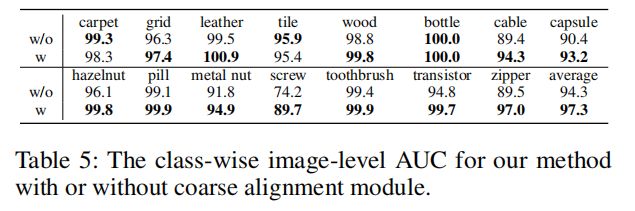
我们给出了一个特定类的定性结果,以显示表5中粗对齐阶段的效果。我们可以观察到,粗对齐阶段可以改善MVTec广告数据集中的大多数类别,尤其是“螺钉”,我们将在下面讨论这种改善是如何实现的。
Image-Level Coarse Alignment module
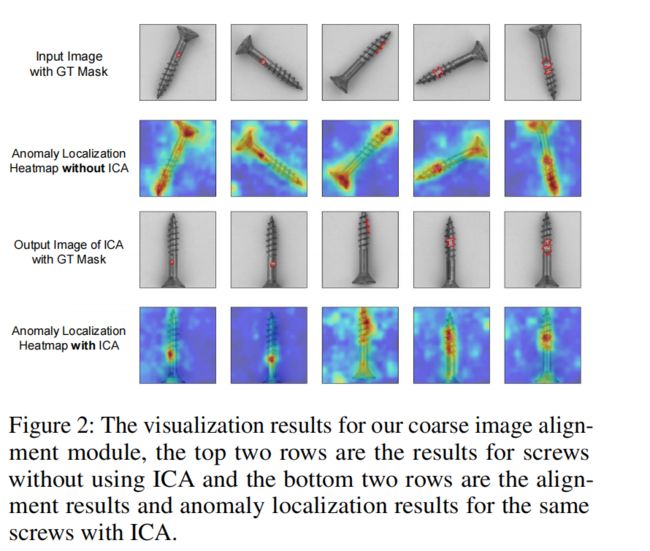
为了可视化图像级粗对准的结果,我们选择最无序的类别螺丝。如图2所示,数据集中的螺钉具有不同的方向和位置。定位热图对螺钉的关注稀疏且分散,无法准确定位缺陷。
通过ICA后,它们都大致与直线上升方向对齐。热图也变得更加集中于特定的缺陷位置,而不是在不同的方向和位置扩散。也就是说,ICA模块缩小了正态样本的分布,降低了特征学习的难度,从而提高了异常检测和定位性能。
Feature-Level Coarse Alignment Module

我们研究表6中特征级粗对准模块的位置的影响。基线是没有特征级对齐的干净主干。我们发现,在单一特征层后插入FCA对基线的改善有限,而在所有三层中插入FCA可彻底提高AUC和PRO。我们推测,虽然在单个层中添加FCA使网络能够调整特征的位置,但它将对准的灵活性和接收场限制在单个范围内。将它们连续地添加到所有三个层中加强了特征对准过程,并且允许等式4中的自监督信号向后下降而没有信息损失。
Conclusion
在本文中,我们提出了一个用于无监督异常检测的由粗到细的非对比学习框架。我们成功的关键是具有粗对齐和细对齐模块的密集非对比学习,它鼓励模型学习并缩小正常模式的分布。我们的方法在工业缺陷数据集上实现了高性能,并且在异常检测和定位任务上都超过了最先进的技术。
Details on Experiments
Implementation Details of two Coarse Alignment modules
两个粗对准模块的实现细节:我们的图像级粗对准模块(ICA)和特征级粗对准模块(FCA)的实现受到空间变形网络的启发。如图4所示,ICA包含两个3 × 3卷积层、两个max-pooling层和两个全连接层。最终的FC层输出输入图像的旋转变换矩阵的角度,然后将它们对齐到统一的方向。
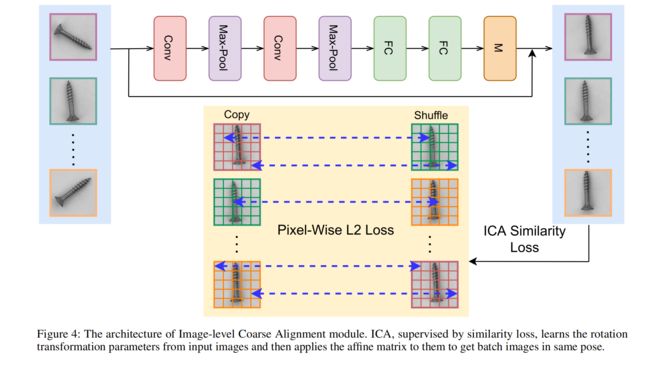
我们开发了一个自我监督的学习任务来训练ICA。具体来说,ICA损失以像素方式最小化一批图像中每对图像之间的距离。因此,像素被强制学习共享的、有代表性的位置对准信息。我们在算法2中给出了这种自我监督学习任务及其损失函数的细节。

FCA与ICA共享相同的基本结构,它们之间的唯一区别是变换矩阵M。在ICA中,矩阵M仅用于以单一旋转角度旋转图像,而FCA中的M包含用于仿射变换的6个参数,包括比例、旋转和平移。此外,与ICA具有明显的“2”相似性损失不同,FCA的监督信号来自于精对齐阶段的非对比学习损失。因此,基于特征的精细比对给出了完整的高级比对集,这有利于在其下游的非对比学习中特征的调整。
Implementation Details of Trainin
我们使用ImageNet预训练ResNet18 的前三个块作为我们的主干网络。我们用一个GPU在224 × 224的图像上训练我们的模型。我们更新了使用动量SGD的参数,ICA的学习率为0.01,其他为0.0001。动量设置为0.9,批量为32。此外,我们使用余弦学习率衰减时间表和系数为0.00001的L2权重正则化的单个周期。
Implementation Details of Disturbed MVTec
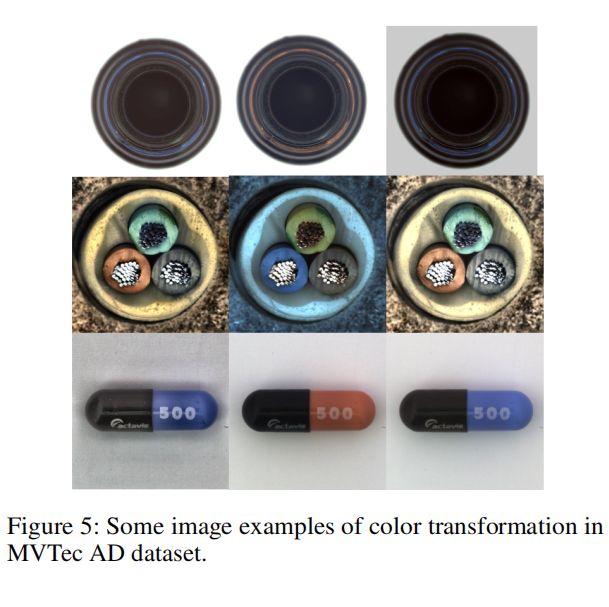
对于颜色变换,我们在MVTec的训练和测试图像中应用随机亮度对比度增强和有限自适应直方图均衡化。参见图5中的例子。我们在这个新的颜色转换的数据集中训练我们的模型,没有ICA和FCA,结果在下表中报告。应该注意的是,一些类别可能不适合进行颜色增强,尤其是纹理类别。例如,不同颜色的区域将被视为瓷砖、木材和胶囊上的异常,因此我们没有对它们进行实验。
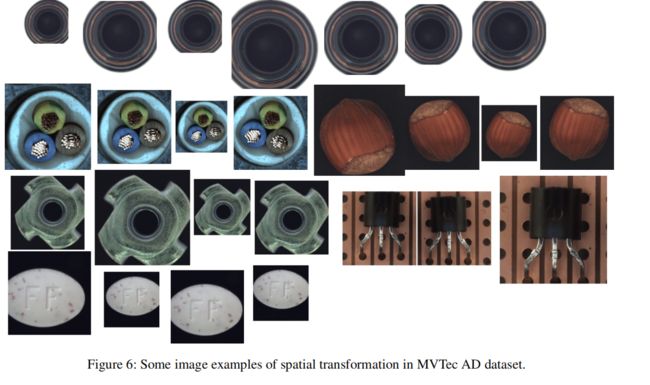
对于空间变换,我们在MVTec中的训练和测试图像中应用随机放大/缩小/旋转/翻转。参见图6中的例子。我们在这个新的空间转换的数据集中训练我们的模型,没有ICA和FCA,结果在下表中报告。应该注意的是,某些类别可能不适合做某些特殊类型的增强。例如,我们不能在晶体管中应用翻转或旋转,因为晶体管需要按照指定的方向和位置排列。
Optimization Hypothesis in Fine Alignment Stage
我们引入的停止梯度运算,以允许仅使用正常数据进行训练,并避免崩溃。我们现在为这个非对比学习框架中的机制提供一个假设,特别是它如何帮助我们的模型拟合和对齐正常图像的紧凑分布。
Optimization Problem Formulation
我们假设我们的非对比学习隐含地定义了一个非参数聚类算法,因此停止梯度操作成为优化步骤中的一个体面的过程。我们的非对比学习模块的目的是沿着像素维度回归一类正常图像的代表性嵌入。然后,这可以被看作是对所有正常数据的单模式搜索问题,我们从中识别最典型的特征作为模式。在最好的情况下,模式是A类中所有正常对象的地面真实表示A。
模式搜索的自然算法是由(Mean shift: A robust
approach toward feature space analysis.)提出的Mean shift 算法。即设 x i ∈ R D , i = 1 , 2 , . . . N x_i ∈ R^D,i = 1,2,...N xi∈RD,i=1,2,...N表示N个独立随机变量。Mean shift 通过定点迭代更新x
x i = m ( x i ) = ∑ j N x j K ( x i , x j ) ∑ j N K ( x i , x j ) x_{i}=\mathbf{m}\left(x_{i}\right)=\frac{\sum_{j}^{N} x_{j} K\left(x_{i}, x_{j}\right)}{\sum_{j}^{N} K\left(x_{i}, x_{j}\right)} xi=m(xi)=∑jNK(xi,xj)∑jNxjK(xi,xj)
其中 K ( x i , x j ) K\left(x_{i}, x_{j}\right) K(xi,xj)是加权 x i x_i xi和 x j x_j xj之间距离的核。随着 m ( x ) \mathbf{m}(x) m(x)收敛,更新继续进行。
在我们的设置中,让 m i j ∼ M ∈ R H × W × C m_{i j} \sim \mathcal{M} \in \mathbb{R}^{H \times W \times C} mij∼M∈RH×W×C 和 n i j ∼ N ∈ R H × W × C n_{i j} \sim \mathcal{N} \in \mathbb{R}^{H \times W \times C} nij∼N∈RH×W×C表示从特征图M和N采样的两个对应像素,对于每次迭代t,我们将损失定义为:
L = min θ D ( m i j , n i j ) = D ( g ( t ) ( f ( t ) ( m i j ) ) , f ( t ) ( n i j ) ) , \mathcal{L}=\min _{\theta} \mathcal{D}\left(m_{i j}, n_{i j}\right)=\mathcal{D}\left(g^{(t)}\left(f^{(t)}\left(m_{i j}\right)\right), f^{(t)}\left(n_{i j}\right)\right), L=θminD(mij,nij)=D(g(t)(f(t)(mij)),f(t)(nij)),
其中 θ \theta θ是预测器g和编码器f的参数。
在本文中,我们使用负余弦相似度作为 D ( m i j , n i j ) \mathcal{D}\left(m_{i j}, n_{i j}\right) D(mij,nij),但是它可以放宽到任何距离度量。为了回归所有 m i j , n i j m_{i j}, n_{i j} mij,nij的全局极小值,其中 g ∗ ( f ∗ ( m i j ) ) = f ∗ ( n i j ) g^{*}\left(f^{*}\left(m_{i j}\right)\right)=f^{*}\left(n_{i j}\right) g∗(f∗(mij))=f∗(nij),我们执行$\mathcal{L} $的梯度下降更新:
θ ( t + 1 ) = θ ( t ) + η ∂ L ∂ m i j \theta^{(t+1)}=\theta^{(t)}+\eta \frac{\partial \mathcal{L}}{\partial m_{i j}} θ(t+1)=θ(t)+η∂mij∂L
通过停止梯度运算, n i j n_{i j} nij被视为常数,不会将其梯度反向传播到 L \mathcal{L} L。因此,我们可以将 f ( t ) ( n i j ) f^{(t)}\left(n_{i j}\right) f(t)(nij)解释为 f f f和 g g g回归的优化目标。因此,在每次迭代 t t t,我们通过将先前的 f ( t ) ( n i j ) f^{(t)}\left(n_{i j}\right) f(t)(nij)视为基本事实表示A的近似来更新新的参数:
θ g ( t + 1 ) , θ f ( t + 1 ) ← min D ( ⋅ , f ( t ) ( n i j ) ) \theta_{g}^{(t+1)}, \theta_{f}^{(t+1)} \leftarrow \min \mathcal{D}\left(\cdot, f^{(t)}\left(n_{i j}\right)\right) θg(t+1),θf(t+1)←minD(⋅,f(t)(nij))
当我们聚集来自我们的随机混洗算法的一批图像的更新时,将每对 m i j m_{i j} mij和 n i j n_{i j} nij对准 f ( t ) ( ⋅ ) f^{(t)}(\cdot) f(t)(⋅)的过程等效于:
g ( t + 1 ) ( f ( t + 1 ) ( ⋅ ) ) ≃ E Z [ f ( t ) ( Z ) ] , g^{(t+1)}\left(f^{(t+1)}(\cdot)\right) \simeq \mathbb{E}_{Z}\left[f^{(t)}(Z)\right], g(t+1)(f(t+1)(⋅))≃EZ[f(t)(Z)],
其中 Z Z Z是一批正常图像特征图的随机变量。由于我们随机执行图像的配对,并给所有图像分配相等的权重,等式(16)变成:
g ( t + 1 ) ( f ( t + 1 ) ( ⋅ ) ) ≃ E Z [ f ( t ) ( Z ) ] = ∑ i f ( t ) ( z i ) ∣ B ∣ , g^{(t+1)}\left(f^{(t+1)}(\cdot)\right) \simeq \mathbb{E}_{Z}\left[f^{(t)}(Z)\right]=\frac{\sum_{i} f^{(t)}\left(z_{i}\right)}{|B|}, g(t+1)(f(t+1)(⋅))≃EZ[f(t)(Z)]=∣B∣∑if(t)(zi),
其中|B|表示批量大小。我们可以通过添加一个平坦内核将等式(17)放宽到等式(12):
K ( ⋅ , z i ) = { 1 , z i ∈ B 0 , otherwise , \mathcal{K}\left(\cdot, z_{i}\right)=\left\{\begin{array}{ll} 1, & z_{i} \in B \\ 0, & \text { otherwise } \end{array},\right. K(⋅,zi)={1,0,zi∈B otherwise ,
其中B代表一个批次中的所有特征图。那么
g ( t + 1 ) ( f ( t + 1 ) ( ⋅ ) ) ≃ E Z [ f ( t ) ( Z ) ] = ∑ i f ( t ) ( z i ) K ( ⋅ , z i ) ∑ i K ( ⋅ , z i ) g^{(t+1)}\left(f^{(t+1)}(\cdot)\right) \simeq \mathbb{E}_{Z}\left[f^{(t)}(Z)\right]=\frac{\sum_{i} f^{(t)}\left(z_{i}\right) \mathcal{K}\left(\cdot, z_{i}\right)}{\sum_{i} \mathcal{K}\left(\cdot, z_{i}\right)} g(t+1)(f(t+1)(⋅))≃EZ[f(t)(Z)]=∑iK(⋅,zi)∑if(t)(zi)K(⋅,zi)
因此,我们的非对比学习成为一种隐式的均值移位算法。在每次迭代中,在训练集中的所有正常图像中,嵌入的参数仅向来自单个批次的随机采样特征图的平均值移动。通过定点迭代的收敛,我们的方法回归到给定足够训练时间的所有正常图像的模式表示。因此,用于嵌入的分散特征向量收缩成紧凑分布,其中它们的特征编码被共享和对齐。
剩下的是说的是在语义分割上的应用以及结果展示。